
تُعد Grok Imagine Video Generation نظام الذكاء الاصطناعي متعدد الوسائط لتوليد الفيديو الرائد من شركة xAI، وقد نجحت بالفعل في إعادة صياغة توقعات المبدعين من مجرد طلب واجهة برمجة تطبيقات (API) واحد. تم بناء هذا النموذج على محرك xAI Aurora، ويستخدم شبكة خبير-مزيج (Mixture-of-Experts) ذاتية الانحدار، حيث يقوم بمعالجة رموز النصوص والصور والفيديو والصوت معاً. يلغي هذا النهج تماماً طرق "محولات الانتشار" (Diffusion-Transformer) الموجودة في أنظمة مثل Sora و Veo.
تكمن الميزة الرئيسية في التزامن الطبيعي بين الصوت والفيديو الذي يتم إنشاؤه في خطوة توليد واحدة، مما يلغي الحاجة إلى أدوات دبلجة خارجية لاحقاً.
نظرة سريعة: المواصفات الرئيسية
| الميزة | التفاصيل |
| المدة | 1–15 ثانية |
| معدل الإطارات | 24 إطاراً في الثانية |
| الدقة | 480p / 720p |
| الصوت | مزامنة شفاه أصلية، مؤثرات صوتية، حوار، موسيقى محيطة |
| لوحة الصدارة | المركز الأول في Artificial Analysis Video Arena (بتقييم Elo 1404 ±6) |
بعد إطلاقه في أواخر مايو 2026، ظهر Grok imagine video generation في صدارة لوحة صدارة "Image-to-Video" في Artificial Analysis Video Arena، متفوقاً على Seedance 2.0 من ByteDance. بالنسبة لأي سير عمل رقمي حديث يتطلب فيديو سريعاً وجاهزاً للإنتاج مع صوت مدمج، يعد هذا النموذج هو المعيار الذي يجب التفوق عليه.
فهم بنية Grok Imagine Video Generation من xAI
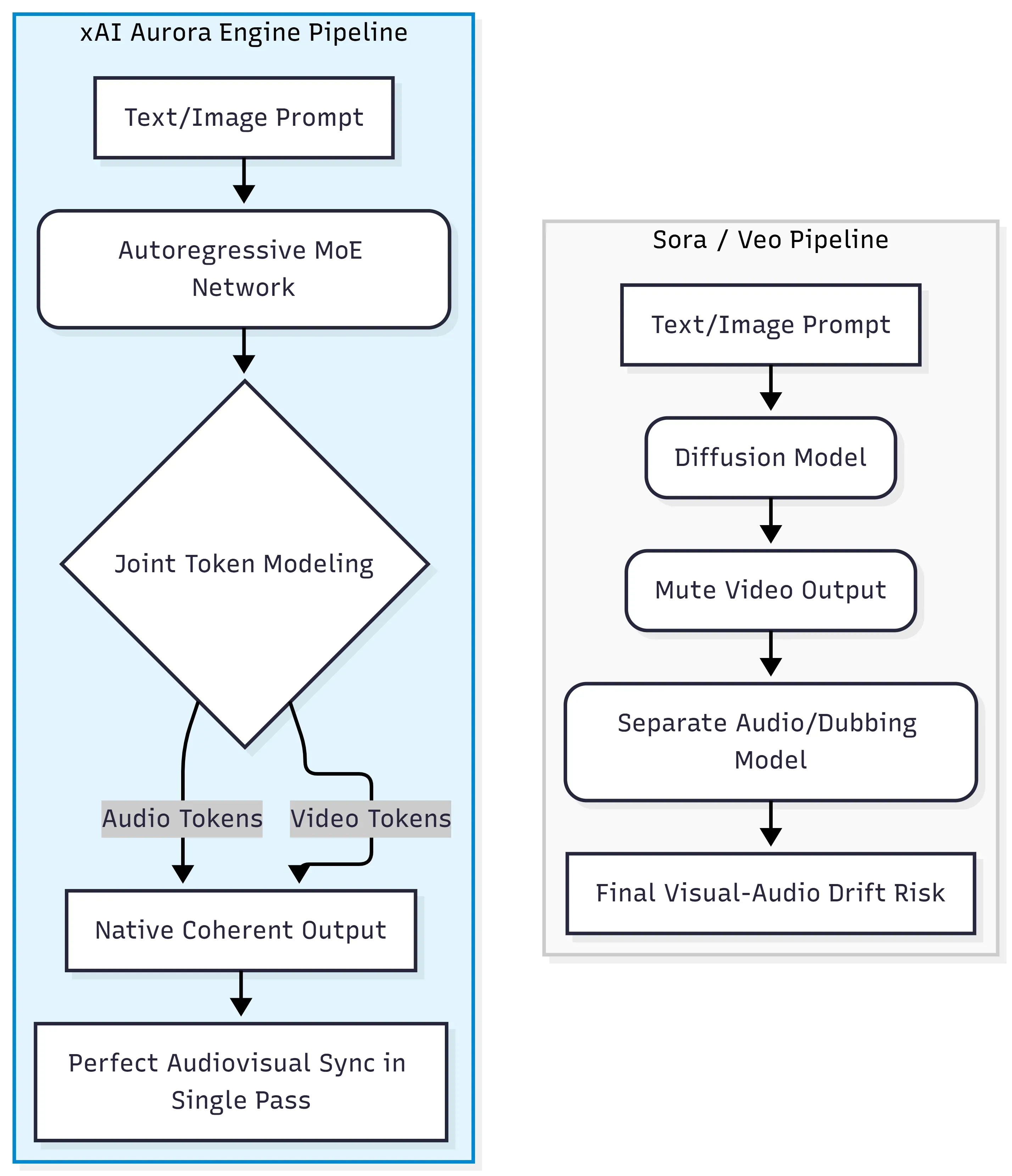
للاستفادة الكاملة من ميزات Grok، يجب أن نلقي نظرة تحت الغطاء. على عكس نماذج الفيديو التقليدية التي تدمج الصوت والصورة بعد الانتهاء، يتعامل Grok معهما ككيان واحد. إن فهم هذا التحول الجوهري يفسر لماذا يختلف سلوك المطالبات (Prompts) وسرعات العرض بشكل جذري عن بدائل السوق.
ما هو Grok Imagine وكيف يعمل؟
في جوهره، يعمل Grok Imagine Video Generation على محرك xAI Aurora، وهو شبكة خبير-مزيج ذاتية الانحدار (MoE network) تتنبأ بالرمز التالي عبر تدفق موحد لبيانات النصوص والصور والفيديو والصوت. هذا يختلف معمارياً عن نموذج محولات الانتشار الذي تستخدمه OpenAI في Sora وGoogle في Veo، حيث يتم توليد الفيديو والصوت أو محاذاتهما عادةً في مراحل منفصلة.
التحول بعيداً عن محولات الانتشار (Diffusion-Transformers)
تعمل نماذج الانتشار التقليدية عن طريق إزالة الضوضاء تدريجياً من الصور العشوائية لتحويلها إلى إطارات متماسكة. هي تتفوق في الجودة البصرية لكنها تتعامل مع الصوت كأمر ثانوي، مما يتطلب أدوات خارجية أو عمليات ما بعد الإنتاج لإضافة الصوت. يتخذ Aurora مساراً مختلفاً تماماً.
| النهج | البنية | طريقة الصوت |
| Sora / Veo | محولات الانتشار | ما بعد الإنتاج / نموذج منفصل |
| Grok Imagine Video | MoE ذاتية الانحدار | توليد أصلي في تمريرة واحدة |
معالجة الرموز متعددة الوسائط المتداخلة
بدلاً من التعامل مع الوسائط بشكل تسلسلي، يعالج Aurora بيانات متعددة الوسائط متداخلة — مما يعني أن رموز الصوت والصورة (الحوار، المؤثرات الصوتية، الموسيقى المحيطة) يتم توليدها جنباً إلى جنب مع إطارات الفيديو في نفس تمريرة المعالجة. هذه النمذجة المشتركة هي التي تسمح بمزامنة الشفاه والمؤثرات الصوتية المتوافقة مع الأحداث بأن تنبثق من النموذج نفسه، وليس من أنظمة محاذاة منفصلة.
نموذج إنتاج يوضح تنفيذ Aurora في تمريرة واحدة، حيث يتطابق التردد الصوتي لمحرك السيارة مع تسارع الصورة وفيزياء احتكاك الإطارات بشكل مثالي.
التدريب على نطاق واسع: Colossus
قامت الشركة بتدريب هذا النموذج على الحاسوب العملاق Colossus من xAI. يستخدم هذا الموقع الضخم حوالي 555,000 وحدة معالجة رسوميات (GPU) من NVIDIA ويستهلك حوالي 2 جيجاوات من الطاقة. إنه رسمياً أكبر مجمع تدريب ذكاء اصطناعي في موقع واحد في أي مكان. هذا الإعداد الضخم هو السر وراء قدرة Aurora على مزج أربعة أنواع مختلفة من الوسائط دون خفض الجودة.
القدرات الرئيسية: التحويل من صورة إلى فيديو، إعدادات التنسيق، وأنماط الجودة
بينما يدعم Grok تحويل النص إلى فيديو، فإن فائدته الحقيقية للمؤسسات تظهر في عمليات "من صورة إلى فيديو" (I2V). من خلال تزويد النموذج بصورة مرجعية ثابتة، يمكنك تثبيت ميزات الشخصية فوراً، مما ينقل العبء من النص الوصفي إلى أدوات تحكم ميكانيكية دقيقة. قبل الغوص في أنماط التصميم، يجب عليك تكوين قيود المسار الأساسي.
ما هي حدود الفيديو، نسب العرض، والدقة لـ Grok Imagine؟
تحويل الصور إلى فيديوهات هو أحد أكثر الميزات فائدة في Grok Imagine. يمكنك ببساطة تحميل صورة ثابتة وكتابة مطالبة بسيطة لوصف الحركة. يقوم النموذج بعد ذلك بتحريك الصورة وإضافة صوت مطابق في نفس الوقت. يمكنك التحكم الكامل في التنسيق النهائي باستخدام أربعة إعدادات: المدة، معدل الإطارات، الدقة، والشكل.
المدة ومعدل الإطارات
التحكم الدقيق في المدة يسمح لك بطلب أي عدد صحيح من الثواني من 1 إلى 15. هذا يوسع الحد السابق البالغ 10 ثوانٍ بنسبة 50% مع الحفاظ على التناسق الزمني عبر النافذة الأطول. جميع المخرجات يتم عرضها بمعدل أساسي ثابت يبلغ 24 إطاراً في الثانية.
خيارات الدقة
| الدقة | الجودة | سرعة المعالجة |
| 480p | دقة قياسية | أسرع (افتراضي) |
| 720p | عالية الدقة (HD) | أبطأ |
للمخرجات النهائية أو التوزيع على وسائل التواصل الاجتماعي، تعد 720p الخيار العملي. استخدم 480p للتكرار السريع واختبار المطالبات.
تباينات نسبة العرض إلى الارتفاع
يتم دعم سبع تباينات لنسبة العرض إلى الارتفاع:
| النسبة | أفضل حالة استخدام |
| 16:09 | شاشة عريضة / يوتيوب (افتراضي) |
| 9:16 | تيك توك / إنستغرام ريلز / ستوري |
| 1:01 | صور مصغرة اجتماعية |
| 4:3 / 3:4 | عروض تقديمية / صور شخصية |
| 3:2 / 2:3 | تنسيقات التصوير الفوتوغرافي |
بالنسبة لـ توليد الفيديو من صورة، يتم تعيين الإخراج افتراضياً على نسبة العرض إلى الارتفاع الأصلية للصورة المدخلة ما لم يتم تعديل ذلك.
إرشادات هندسة المطالبات للحركة السينمائية وهوية Zero-Shot
لأن محرك xAI Aurora يعتمد على النمذجة المشتركة للرموز، يجب أن تتغير استراتيجيتك في كتابة المطالبات. لم تعد بحاجة لقضاء الرموز في وصف المظهر الجسدي للشخصية—حيث تتولى الصورة المدخلة ذلك عبر الحفاظ على الهوية (zero-shot identity preservation). بدلاً من ذلك، يجب أن تركز مطالبتك بدقة على الحركة الاتجاهية، سلوك الكاميرا، وبشكل حاسم، البيئة الصوتية التي تريد أن يولدها المحرك بالتزامن.
كيف تكتب مطالبات Grok Imagine Video للحصول على أفضل النتائج؟
المبدأ الأهم: نظراً لأن Grok Imagine يدعم الحفاظ على الهوية (zero-shot)، فإن النموذج ينقل مظهر الموضوع مباشرة من الصورة المدخلة. لا تحتاج لإعادة وصف لون الشعر، الملابس، أو ملامح الوجه. اقضِ كل كلمة بدلاً من ذلك على ديناميكيات الحركة، البيئة، واتجاه الكاميرا.
بناء جملة المطالبة الأمثل
امزج وطابق كتل الرموز المحسنة هذه لبناء بيئات سينمائية خاضعة للتحكم بشكل كبير:
| الحركة والأكشن | ديناميكيات الكاميرا | الصوت والبيئة |
| ...يخطو بثقة للأمام، مع تطاير المعطف | زوم (Dolly) يتراجع ببطء | ...انعكاسات نيون متموجة على الرصيف المبلل. مؤثرات صوتية: مطر غزير يتساقط على الأسفلت |
| ...يركض وسط حشد كثيف، ملتفتاً للخلف | لقطة تتبع من زاوية منخفضة، سرعة عالية | ...تحت أضواء فلورسنت متذبذبة. مؤثرات صوتية: همس حشود مكتوم ولهث |
| ...يستدير ببطء، ويفتح عينيه | لقطة ماكرو تتبع من اليسار إلى اليمين | ...عمق مجال ضحل، ذرات غبار عائمة. مؤثرات صوتية: صوت باس سينمائي عميق |
السيناريو أ: تسلسل مطاردة سايبربانك - ديناميكية عالية، مزامنة صوتية ثقيلة
المطالبة:
الحركة والموضوع: رجل يركض بسرعة في زقاق مبلل مضاء بلافتات النيون.
ديناميكيات الكاميرا: تبقى الكاميرا منخفضة وتتبعه عن كثب. الخلفية تتلاشى بسرعة، وتومض الأضواء الساطعة عبر الشاشة.
المؤثرات الصوتية: موسيقى إلكترونية سريعة تمتزج مع خطى الأقدام في البرك وصفارات إنذار بعيدة. تتطابق الإيقاعات مع أضواء النيون الوامضة بشكل مثالي.
هدف الاختبار: يتحقق هذا الاختبار من مدى قدرة محرك Aurora على التعامل مع الأشكال أثناء الحركة السريعة. كما يقيم مدى تزامن الأصوات مع المرئيات بشكل مثالي، مثل مطابقة إيقاعات الـ "سينث" مع أضواء النيون الوامضة.
النجاحات (ما أتقنه Grok):
- الحفاظ على الهوية (Zero-Shot): الانتقال من الصورة الثابتة كان لا تشوبه شائبة. نسيج الجلد المجعد لمعطف المطر والشعر الداكن الفوضوي للشخصية ظلا مستقرين تماماً دون أي تشوه في الهوية.
- التماسك الفيزيائي: تعامل Grok مع الركض عالي السرعة دون أي تكرار في الأطراف أو تداخل في الملابس — وهي نقطة فشل معروفة لمنافسي الانتشار.
- فيزياء الإضاءة الديناميكية: تحولت الانعكاسات النيون الوردية والزرقاء على الرصيف المبلل بدقة بالتزامن مع زاوية تتبع الكاميرا للأمام.
العيوب (حيث توجد اختناقات):
- تحيز رموز الصوت: على الرغم من أن مزامنة الصوت الأصلية في تمريرة واحدة مثيرة للإعجاب، إلا أن المحرك أعطى أولوية كبيرة لرمز "موسيقى السنث-ويف"، مما طغى تماماً على المؤثرات الصوتية المحلية "لترشيش البرك".
- ضغط الحركة: بدقة 720p، تسببت حركة الكاميرا السريعة في ضبابية طفيفة عند الحواف وتشوهات رقمية حول النص البعيد في الخلفية مثل "MIDNIGHT DINER".
السيناريو ب: حوار سينمائي وتدفق عاطفي
المطالبة:
الحركة والموضوع: تلقي خطاباً سينمائياً متوتراً، تهمس "ينتهي الأمر الليلة" بكل قناعة.
ديناميكيات الكاميرا: تتقدم الكاميرا ببطء نحو وجهها تماماً مع هبوب رياح قوية تفسد شعرها.
المؤثرات الصوتية: صوتها الهادئ يطابق حركات شفتيها بشكل مثالي، ممتزجاً بهبة رياح قوية ومفاجئة تهب في الميكروفون وتجعل ملابسها تصدر صوتاً.
هدف الاختبار: يعمل هذا كاختبار ضغط نهائي لدمج الرموز المتعددة في محرك xAI Aurora. إنه يجبر النموذج على تنفيذ مزامنة شفاه أصلية لا تشوبها شائبة وآليات عضلات وجه ديناميكية مع حساب التفاعل الفيزيائي الفوضوي لحركة الشعر/الملابس في نفس الوقت، وكل ذلك مطابق لمؤثرات صوتية بيئية واقعية في تمريرة استنتاج واحدة.
النجاحات (ما أتقنه Grok):
- مزامنة شفاه أصلية خالية من العيوب: الكلمات المنطوقة "ينتهي الأمر الليلة" تطابق حركات الشفاه والفك للشخصية بشكل مثالي. يحدث هذا بشكل طبيعي دون أي تعديل إضافي.
- الحفاظ على التعبيرات الدقيقة: النمش على وجهها، رمشات العين الصغيرة، والنظرة الحادة بقيت ثابتة تماماً. يظهر هذا أن المحرك يحافظ على هوية ثابتة حتى أثناء لقطات الماكرو القريبة.
- محاكاة فيزياء الرياح: بمجرد انتهائها من الكلام، تهب نسمة مفاجئة عبر شعرها الداكن. تتحرك الخصلات بشكل واقعي وتحافظ على كثافتها الطبيعية.
العيوب (حيث توجد اختناقات):
- تشوه الصوت: الصوت المولد، على الرغم من توقيته الجيد، يُظهر طابعاً روبوتياً اصطناعياً مضغوطاً قليلاً، ويفتقر إلى الملمس الخام والمهموس المطلوب في المطالبة.
- التشوه الزمني الدقيق: خلال تسلسل هبوب الرياح، يحدث بعض التداخل البسيط في النسيج حول الأذن وخط الشعر، حيث يواجه المحرك صعوبة طفيفة في فصل الشعر المتحرك عن خلفية الجلد الثابتة.
تقليل الأخطاء: مصفوفة الأمثلة المضادة
نظراً لأن Grok Imagine لا يدعم معامل مطالبة سلبية (negative prompt) مخصص في نقطة النهاية العامة الحالية، يجب على مهندسي المسارات التحول عن الاستدلالات التقليدية المعتمدة على الانتشار:
- ❌ النهج غير الصحيح (عقلية الانتشار): "رجل يركض، مفصل للغاية، 4k، بدون ضبابية، بدون تشوه، إضاءة سينمائية."
- تحليل التحرير: هذا يملأ نافذة السياق برموز زائدة ويقدم عبارات سلبية مثل "بدون ضبابية". يمكن لشبكة MoE ذاتية الانحدار مثل Aurora أن تسيء تفسير هذه المصطلحات كمرتكزات دلالية، مما يؤدي عن غير قصد إلى توليد التشويه الذي تحاول تجنبه.
- ✅ النهج الصحيح (عقلية Aurora الأصلية): "يخطو للأمام ديناميكياً. تركيز حاد في كل مكان، أنسجة سينمائية نقية، أشعة ضوئية متطورة تخترق الغبار."
- تحليل التحرير: هذا يستبدل الاستثناءات بأوصاف مكانية وفيزيائية إيجابية ومحددة، مما يوجه مسار تنبؤ الرموز في المحرك بشكل نظيف نحو عرض حاد.
نصائح احترافية:
التناسق الزمني يتدهور عندما تقدم المطالبات تعليمات مكانية متضاربة، مثل أوامر التكبير والتحريك لليمين في وقت واحد. حافظ على حركات الكاميرا مفردة واتجاهية. للمقاطع التي تزيد عن 8 ثوانٍ، اربط المطالبة حول قوس حركة واحد مستمر بدلاً من قطع المشاهد المتعددة.
دمج واجهة برمجة تطبيقات Grok Imagine: بداية سريعة مع Python وREST
الانتقال من التصور الإبداعي إلى توسيع الإنتاج يتطلب دفع هذه المعايير عبر بوابة API الرسمية لـ xAI. اعتماداً على بنيتك التحتية الحالية وما إذا كنت تفضل الرفع التلقائي في الخلفية أو حلقة مخصصة خفيفة الوزن، توفر xAI مسارين متميزين للتنفيذ.
كيف أتصل بـ Grok Imagine API للفيديو؟
هناك مساران مدعومان للاتصال بـ Grok Imagine API: عميل xai_sdk الأصلي (الذي يتعامل مع الاقتراع تلقائياً) ونهج REST المتوافق مع OpenAI عبر https://api.x.ai/v1. كلاهما يتطلب مصادقة مفتاح API مضبوط كمتغير بيئة.
المتطلبات الأساسية
قبل كتابة أي كود، أكمل هذه الخطوات:
- أنشئ مفتاح API على console.x.ai
- قم بتصديره في بيئة التشغيل الخاصة بك: export XAI_API_KEY="your-key-here"
- قم بتثبيت SDK: pip install xai-sdk
المسار 1: xai_sdk الأصلي (موصى به)
يقوم عميل xai_sdk بتغليف حلقة الاقتراع غير المتزامنة بالكامل داخلياً، لذا ستحصل على كائن فيديو مكتمل بطلب واحد فقط لنقطة نهاية video.generate:
plaintext1import os 2import xai_sdk 3 4client = xai_sdk.Client(api_key=os.getenv("XAI_API_KEY")) 5 6# تأكد من تمرير الصورة المرجعية لسير عمل "من صورة إلى فيديو" 7response = client.video.generate( 8 model="grok-imagine-video", 9 image="your image", # رابط أو base64 مطلوب 10 prompt="your prompt", 11 duration=5, 12 aspect_ratio="16:9", 13 resolution="720p", 14) 15 16# تم الإصلاح: متوافق مع مخطط استجابة xai_sdk القياسي 17print(f"تم التوليد بنجاح. رابط الفيديو: {response.video.url}")
لا حاجة للاقتراع اليدوي. يرسل الـ SDK الطلب، وينتظر الاكتمال، ويعيد الرابط.
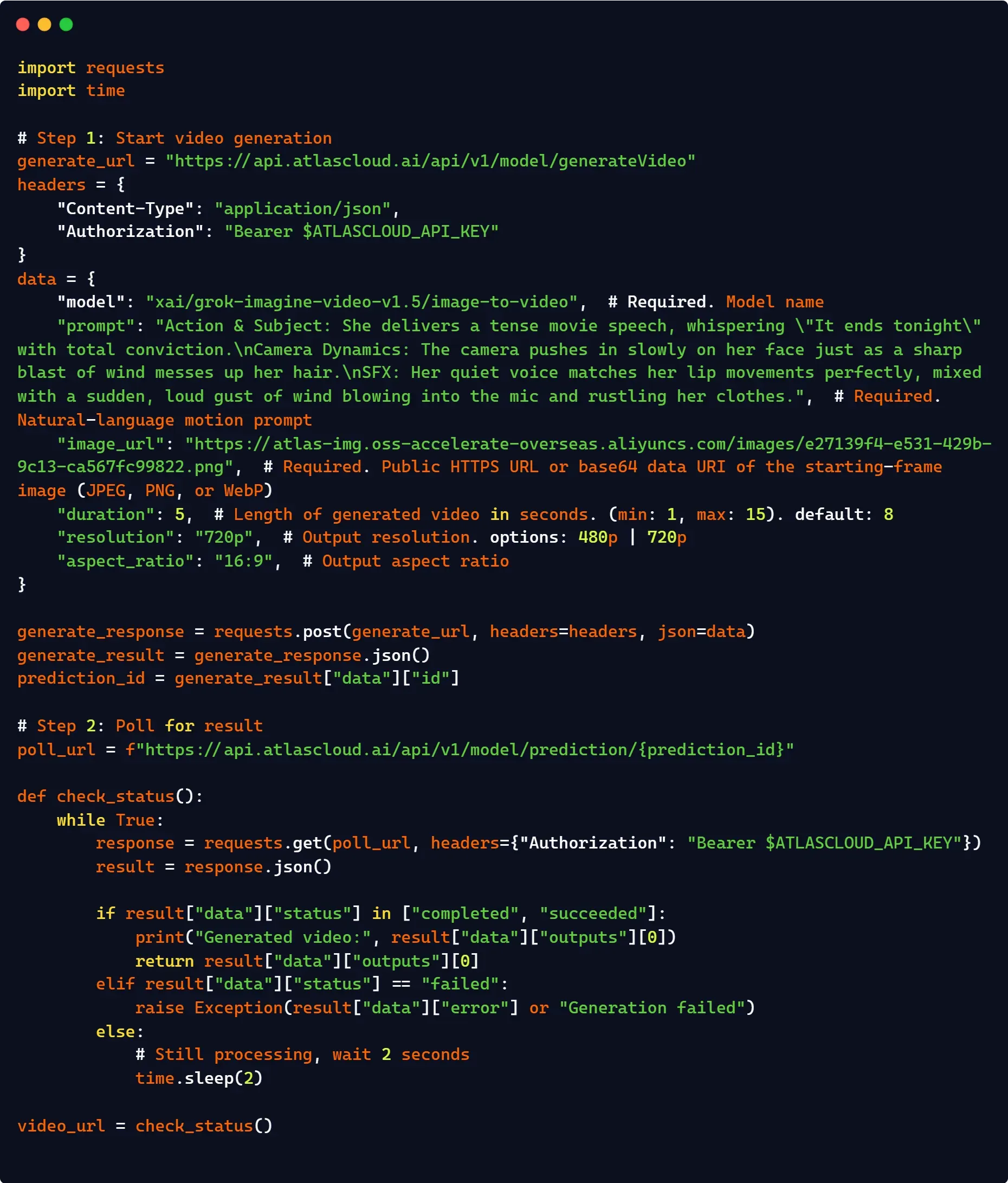
المسار 2: واجهة برمجة تطبيقات REST القياسية (حلقة غير متزامنة مخصصة)
للبيئات التي لا يتوفر فيها الـ SDK الأصلي، استخدم نقاط نهاية HTTP الأساسية. نظراً لأن توليد الفيديو غير متزامن، يجب عليك تنفيذ تسلسل اقتراع يدوياً لتتبع حالة التنفيذ:
plaintext1import os 2import time 3import requests 4 5headers = { 6 "Authorization": f"Bearer {os.environ['XAI_API_KEY']}", 7 "Content-Type": "application/json", 8} 9 10payload = { 11 "model": "grok-imagine-video", 12 "image": "your image", 13 "prompt": "prompt", 14 "duration": 5, 15 "aspect_ratio": "16:9", 16 "resolution": "720p" 17} 18 19# 1. إرسال طلب توليد الفيديو 20res = requests.post("https://api.x.ai/v1/videos/generations", headers=headers, json=payload) 21res.raise_for_status() 22request_id = res.json()["request_id"] 23 24# 2. اقتراع نقطة نهاية الحالة حتى يصبح جاهزاً 25while True: 26 poll = requests.get(f"https://api.x.ai/v1/videos/{request_id}", headers=headers) 27 data = poll.json() 28 29 if data["status"] == "done": 30 # تم الإصلاح: متوافق مع مخطط إرجاع JSON الرسمي لـ xAI 31 print(f"نجاح! الأصل متاح في: {data['video']['url']}") 32 break 33 elif data["status"] in ["expired", "failed"]: 34 print(f"فشل التوليد بحالة: {data['status']}") 35 break 36 37 time.sleep(5) # فاصل زمني آمن لتحديد المعدل
مرجع حالة الاقتراع
ترجع واجهة برمجة التطبيقات واحدة من أربع قيم حالة أثناء التوليد:
| الحالة | المعنى |
| pending | لا يزال قيد المعالجة |
| done | الفيديو جاهز، الرابط متاح |
| expired | انتهت مهلة الطلب |
| failed | خطأ في التوليد |
قم بالاقتراع كل 5 ثوانٍ للبقاء ضمن حدود معدل معقولة. الافتراضي في SDK هو فترات 100 مللي ثانية، لكن 5 ثوانٍ عملية لسير عمل الإنتاج.
بديل الإنتاج: التبسيط عبر بوابة Atlas Cloud API
بالنسبة لمسارات عمل المؤسسات التي تتطلب توازياً متقدماً، أو فوترة موحدة، أو توجيهاً عالي التوفر، يعد الدمج عبر بوابة مدارة من طرف ثالث مثل Atlas Cloud بديلاً قابلاً للتطبيق للإنتاج. بدلاً من إدارة حلقات الاقتراع غير المتزامنة المعقدة وفحوصات الحالة محلياً، تتعامل واجهة Atlas Cloud الموحدة مع الانتظار من جانب الخادم واستمرارية الحالة تلقائياً.
علاوة على ذلك، فهي توفر بديلاً سهلاً عبر توجيه الطلبات من خلال عنوان URL أساسي موحد، مما يقلل من تغييرات الكود مع فتح حدود معدل على مستوى المؤسسات التي تتجاوز عادةً عتبات مستوى xAI العام.
أداء المعايير: التكلفة، الكمون، ومقارنات المنافسين
لا تكون مخرجات الصوت والصورة عالية الدقة مجدية لمسارات عمل المؤسسات إلا إذا توافقت مع ميزانيات الحوسبة الصارمة ومتطلبات الكمون. لمعرفة مكانة Grok في السوق، تقوم اختبارات الطرف الثالث بتعيين سرعات توليده وتكاليفه لكل ثانية مباشرة مقابل عمالقة الصناعة الراسخين.
هل Grok Imagine Video أسرع وأرخص من أدوات فيديو الذكاء الاصطناعي الأخرى؟
في المعايير المستقلة، الإجابة هي نعم إلى حد كبير. ظهر Grok Imagine Video في المركز الأول في لوحة صدارة Image-to-Video لـ Artificial Analysis Video Arena بـ تقييم Elo يبلغ 1404 ±6، متفوقاً على Seedance 2.0 من ByteDance من المركز الأول.
مقارنة المنافسين وجهاً لوجه
| النموذج | المطور | المدة القصوى | الدقة القصوى | صوت أصلي |
| Grok Imagine V1.5 | xAI | 15 ثانية | 720p | نعم |
| Seedance 2.0 | ByteDance | 4–12 ثانية | 720p | نعم |
| Veo 3.1 | 8 ثوانٍ | 1080p | نعم | |
| Sora 2 | OpenAI | 20 ثانية | 1080p | نعم |
| Runway Gen-4 | Runway | 10 ثوانٍ | 1080p | جزئي |
سرعة الاستنتاج والكمون
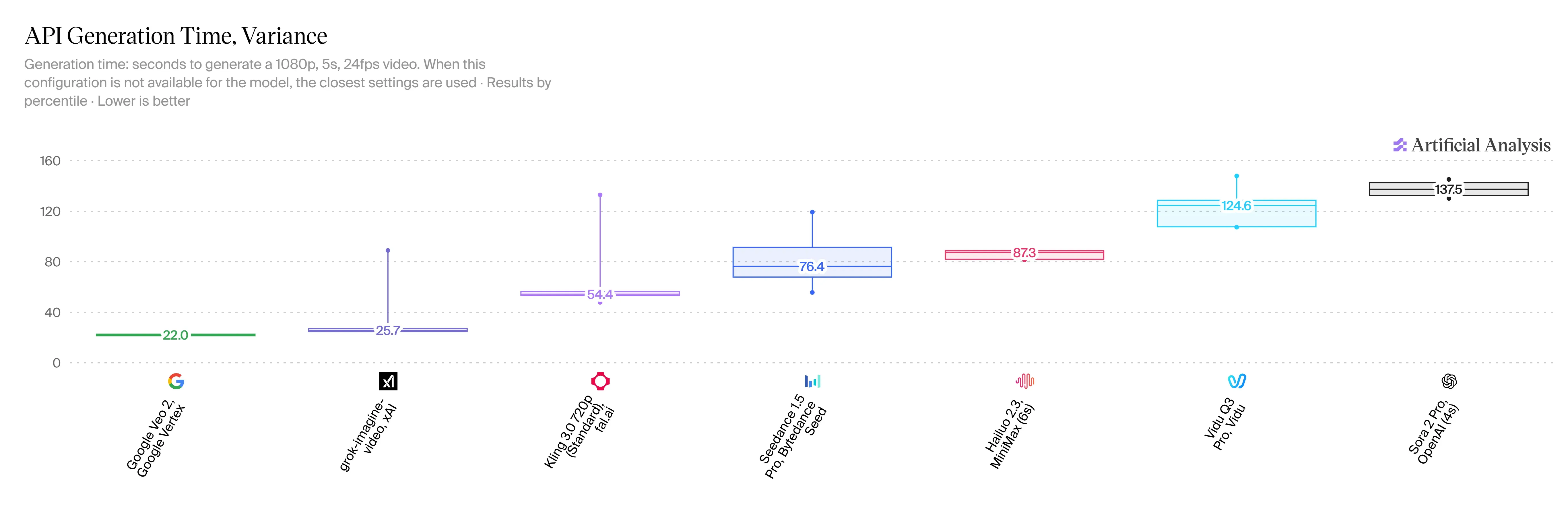
V1.5 سريع بشكل لا يصدق، وهذا فوز كبير للمستخدمين. يمكنك صنع مقطع مدته 5 ثوانٍ بدقة 720p في غضون 20 إلى 30 ثانية فقط. بالمقارنة مع HappyHorse 2.3، هذا يقلل وقت الانتظار بمقدار مرتين أو ثلاث مرات. لا نملك حتى الآن إحصائيات سرعة رسمية لـ Veo 3.1، لكن الناس عبر الإنترنت يقولون إن الأمر يستغرق أكثر من دقيقة كاملة لمقطع مماثل.
هيكل التسعير
يبدأ هيكل التسعير لكل ثانية عبر بوابات API الخاصة بطرف ثالث مثل Atlas Cloud بحوالي USD0.096 لكل ثانية من الفيديو المولد. بهذا السعر، تكلف المقطع مدته 10 ثوانٍ حوالي USD0.96، مما يجعل التجريب الفعال من حيث التكلفة متاحاً حقاً للمبدعين المستقلين والفرق الصغيرة التي تكرر تجربة متغيرات مطالبة متعددة قبل الالتزام بجولة الإنتاج النهائية.
أمن المؤسسات، خصوصية البيانات، وامتثال المحتوى
إن نشر أصول وسائط مملوكة أو محتوى موجه للعملاء في أي نظام ذكاء اصطناعي قائم على السحابة يطرح أسئلة قانونية ضرورية. بالنسبة لشركات الإنتاج التجاري، معرفة أين تنتهي مدخلاتك التوليدية — وكيف يتم عزلها — لا يقل أهمية عن جودة المخرجات النهائية.
هل تستخدم xAI بيانات API الخاصة بي أو الفيديوهات المولدة لتدريب نماذجها؟
هذا هو أحد أكثر الأسئلة شيوعاً من المتبنين في المؤسسات، وهو يستحق إجابة مباشرة. وفقاً لشروط مطوري xAI، تخضع مدخلات ومخرجات API المعالجة عبر المنصة لـ مراجعة سياسة المحتوى لتصفية السلامة، ولكن يتم التعامل معها بموجب مبادئ خصوصية البيانات بالتصميم التي تفصل بيانات الاستنتاج عن مسارات التدريب العامة.
نظرة عامة على إطار الامتثال
تنشر بوابات API التابعة لجهات خارجية التي توفر الوصول إلى Grok Imagine، مثل Atlas Cloud، شهادات الامتثال المستقلة الخاصة بها:
| معيار الامتثال | الحالة |
| امتثال SOC 2 Type II | معتمد |
| إقامة بيانات GDPR | متوافق |
| HIPAA | مؤهل |
حدود الخصوصية الرئيسية للمحترفين
يجب على المحترفين الذين يقيمون Grok Imagine لسير عمل تجاري ملاحظة ما يلي:
- يتم إرجاع مخرجات الفيديو كروابط مستضافة مؤقتة ولا يتم تخزينها بشكل دائم افتراضياً.
- تقوم مراجعة سياسة المحتوى بتصفية المخرجات بحثاً عن انتهاكات السلامة قبل التسليم، ولكنها لا تحتفظ بالمحتوى لإعادة الاستخدام.
- تنطبق استثناءات تدريب النماذج على مستخدمي API: لا يتم تغذية مطالباتك والوسائط المولدة في مسارات تدريب النماذج العامة.
- يعني توافق إقامة بيانات GDPR أن ممارسات التعامل مع البيانات تلبي المعايير الأوروبية للفرق التي تعمل عبر ولايات قضائية مختلفة.
بالنسبة لعمليات النشر في المؤسسات التي تتطلب اتفاقيات معالجة بيانات رسمية أو سياسات احتفاظ مخصصة، فإن التواصل المباشر مع فريق المؤسسات في xAI عبر x.ai هو الخطوة التالية المناسبة.






