ملخص
في منتصف شهر مايو 2026، ظهر كل من Qwen3.7-Max وQwen3.7-Plus بهدوء على منصة LM Arena. وقد حدد حساب @Alibaba_Qwen توقعات المجتمع بعبارة: "Alibaba في المرتبة السادسة في النصوص، والخامسة في الرؤية". في 2 يونيو، أطلق فريق Tongyi Qianwen التابع لـ Alibaba Cloud رسمياً نموذج الوكيل متعدد الوسائط هذا. وهو متاح بالفعل على Alibaba Cloud Model Studio وQwen Chat، مع توفر وصول عبر واجهة برمجة التطبيقات (API) تحت اسم alibaba/qwen3.7-plus بسعر مدرج يبلغ حوالي USD0.40 / USD1.60 لكل مليون رمز (token) للإدخال/الإخراج.
التمركز الرسمي واضح: Plus هو النموذج متعدد الوسائط الفعال من حيث التكلفة، وMax هو الرائد في معالجة النصوص.
لقد أمضينا فترة بعد الظهيرة في إجراء مجموعة اختبارات صارمة عبر نماذج Qwen3.6-plus، وQwen3.7-plus، وQwen3.7-Max، شملت: الإصلاح التلقائي لـ 10 أخطاء برمجية حقيقية، و15 مسألة من مسابقة الرياضيات AIME 2025، بالإضافة إلى مقارنة أوسع حول تعدد الوسائط، والسرعة، والتكلفة.
يُفضل قراءة النتائج كـ 5 ملاحظات على مستوى المهام، وليس كترتيب عام للنماذج:
- اختبار BugFind-10 (تشغيل فردي): نجح Plus في جميع اختبارات pytest الخارجية. ضمن هذه المجموعة المكونة من 10 مهام، ومع هيكل Stirrup الرسمي وإعداد التشغيل الفردي، سجل Plus نتيجة 10/10 بينما سجل Max و3.6-Plus نتيجة 9/10. هذا يشير إلى مدى ملاءمة النموذج لهذه المهام؛ ولا ينبغي تعميم ذلك ليصبح تصنيفاً عاماً للبرمجة.
- الرياضيات: وصل Plus مع تفعيل التفكير إلى نفس نتيجة Max في التشغيل الفردي. في 15 مسألة رياضيات مسابقاتية، أجاب كل من Plus وMax بشكل صحيح على 14 مسألة؛ وفي هذا الاختبار، استغرق Qwen3.7-plus وقتاً أقل بكثير من Qwen3.7-Max (113 ثانية مقابل 303 ثوانٍ لكل مسألة).
- قفزة جيلية في السرعة: في مهام الوكيل، وصلت الإنتاجية الشاملة لـ Qwen3.7-plus إلى 147.5 رمز/ثانية، بينما وصل Qwen3.6-plus إلى 41.5 رمز/ثانية فقط، وهو تحسن بمقدار 3.55 ضعف. أصبحت مهام الرياضيات التي لم يتمكن الجيل السابق من إنهائها سهلة الإكمال.
- تعدد الوسائط لا يزال به عيوب: في اختباراتنا الموجهة لتعدد الوسائط، أجاب Qwen3.7-plus على أسئلة الصور البسيطة بشكل صحيح، لكن صورة المثال الرسمية dog_and_girl.jpeg وُصفت بأنها "قطار وحشد من الناس".
- بعض القدرات كانت قريبة من Max، مع ميزة في زمن الاستجابة: عبر العديد من الاختبارات في هذه الجولة، حقق Qwen3.7-plus نتائج قريبة من Qwen3.7-Max مع إظهار زمن استجابة أقل. هذا ليس ادعاءً بترتيب عام.
فيما يلي بيانات الاختبار الكاملة، والمنهجية، وتوصيات اختيار النموذج لقادة الهندسة. جميع المقارنات مقصورة على هذه العينة الصغيرة، والتشغيل الفردي، والهيكل الثابت.
0. سياق قدرات النموذج ولوحة الصدارة
لقد استقرت خطوط إنتاج Alibaba Qwen بالفعل على نمط معين في جيل 3.6: Max = الرائد في النصوص، Plus = نموذج متعدد الوسائط مع سياق طويل. يتبع الإصدار 3.7 هذا المنطق:
| البعد | Qwen3.7-Max | Qwen3.7-Plus |
|---|---|---|
| وسائط الإدخال | نصوص بشكل أساسي | نصوص + صور |
| نقطة البيع النموذجية | سقف الاستنتاج، الوكلاء ذوو المدى الطويل | سياق 1 مليون، رؤية، تفكير هجين، سعر وحدة أقل |
| لوحة الصدارة (2026-05) | حوالي #13 في لوحة صدارة النصوص العامة | حوالي #16 في الرؤية |
| سعر البوابة (06-01) | USD1.25 / USD3.75 لكل مليون | USD0.40 / USD1.60 لكل مليون |
1. كيف يضع المنشور الرسمي نموذج Plus؟
يختصر منشور إطلاق Alibaba Qwen الرسالة في جملة واحدة:
"نموذج واحد. يرى، يفكر، يبرمج، وينفذ."
نقاط البيع الأساسية هي: وكيل هجين تفاعلي متعدد الوسائط مع تشغيل موحد لواجهة المستخدم الرسومية (GUI) وواجهة سطر الأوامر (CLI)، ووكيل برمجة متعدد الاستخدامات، وتعميم عبر أطر عمل الوكلاء. وقد أوضح مطور Qwen الأساسي shuai bai_ ذلك بشكل أكبر:
هدفنا هو تحويل الذكاء الاصطناعي متعدد الوسائط من مجرد التعليق السلبي على الصور إلى حل نشط للمشكلات: ذكاء يمكنه الرؤية، والاستنتاج، وكتابة الكود، وتشغيل الواجهات، والتحقق من النتائج. إنها خطوة نحو ذكاء متعدد الوسائط وكيل حقاً.
تعطي منشورات الأداء من الموضوع الرسمي التموضع الرئيسي:
- أداء النصوص "قريب من مستوى Max" (ادعاء البائع)
- تركز تحسينات تعدد الوسائط على قدرات الوكيل الأساسية: الفهم البصري المعقد، الاستنتاج البصري، استخدام الأدوات، وتنفيذ الكود/الواجهات الرسومية.
| الادعاء الشائع على X | المصدر | نتيجتنا | الاستنتاج |
|---|---|---|---|
| نصوص Plus "قريبة من Max" | رسمي | AIME مع التفكير: نفس النتيجة، 14/15؛ Plus كان أسرع بـ 2.68 ضعف | نفس نتيجة الرياضيات في التشغيل الفردي؛ زمن استجابة أقل في هذه الجولة |
| Max أفضل للبرمجة / العمل طويل الأمد | وثائق Vercel | BugFind: Plus 10/10, Max 9/10; Plus 147.5 t/s | هذه المهمة لا تدعم تطبيق هذا الافتراض بشكل أعمى |
| لوحة صدارة الرؤية قوية | Arena | فشلت صورة المثال الرسمية؛ الصورة الموجهة ✓ | يمكن أن تتعايش درجة عالية في لوحة الصدارة مع فشل في صورة واحدة |
2. منهجية التقييم لدينا: أربعة أنواع من المهام وقاعدة صارمة واحدة
للحفاظ على عدالة الاختبار، نستخدم مجموعة صغيرة تسمى BugFind-10: 10 أخطاء برمجية في العالم الحقيقي تغطي حسابات الأسعار، حدود المصفوفات، معالجة المسارات، التزامن، JSON، SQL، سلوك التخزين المؤقت، Unicode، التكوين، والمزيد. يأتي كل خطأ مع اختبارات pytest. يجب أن يعمل النموذج داخل إطار عمل الوكيل الرسمي Stirrup مع أدوات تنفيذ الكود المحلية وأن يكمل الحلقة الكاملة بنفسه: "إعادة الإنتاج ← التحديد ← تعديل كود الإنتاج ← تشغيل الاختبارات".
لماذا قمنا ببناء مجموعة الاختبار الخاصة بنا؟
تواجه لوحات الصدارة العامة ثلاثة أنماط شائعة للفشل:
- الحفظ والتسريب: النماذج الرائدة مشبعة بالفعل بالمسائل القديمة. اخترنا AIME 2025، وهي مسابقة نُشرت بعد تواريخ التدريب المرجحة للنماذج.
- إبلاغ البائع الذاتي: يمكن أن ينحرف عن إعادة الاختبار المستقلة بشكل كبير اعتماداً على إصدار مجموعة البيانات، وما إذا كان التفكير مفعلاً، وما إذا كانت الأدوات مسموحاً بها.
- معايير الوكيل تعتمد على الهيكلية: يمكن لأطر عمل الوكلاء المختلفة تغيير النتائج بمقدار 2-3 نقاط مئوية. قمنا بتثبيت الإطار على Stirrup الرسمي وأضفنا التحقق الخارجي.
مهام الاختبار الأربعة
| المهمة | ماذا تقيس | المقياس الأساسي |
|---|---|---|
| فحص البوابة | تأكيد الهوية، دعم التفكير، قدرة الرؤية | نجاح / فشل |
| BugFind-10 | الإصلاح التلقائي لـ 10 أخطاء برمجية حقيقية | معدل نجاح pytest الخارجي، عدد استدعاءات النموذج، الوقت الفعلي |
| AIME 2025 I | 15 مسألة رياضيات مسابقة | الدقة، الوقت لكل مسألة، استئصال التفكير |
| تقييم سريع | 8 مسائل لغوية للمرحلة الابتدائية | أساس السرعة، TTFT، فائدة التفكير في المهام البسيطة |
قاعدتنا الصارمة: نتائج الكود تُحتسب فقط تحت pytest خارجي
هذا هو أساس المراجعة بأكملها. وهو يعالج أيضاً مباشرة مخاوف Hacker News من أن قول الوكيل "نجحت الاختبارات" لا يكفي.
العملية:
- يقوم الوكيل بتعديل الكود في مساحة العمل، ويشغل pytest بنفسه، ويكتب CHANGELOG.
- نقوم بنسخ كود الإنتاج المعدل إلى بيئة معزولة ونشغل pytest بشكل مستقل.
- ننشر فقط كود الخروج وسجل الفشل من الخطوة 2.
تشبيه: الوكيل هو الذي يخضع للامتحان. نحن لا نقرأ فقط الإجابة التي يسلمها؛ بل نأخذ الإجابة إلى غرفة أخرى ونصححها مرة أخرى، حتى لا نثق بإيمانه الخاص بأنه نجح.
3. قدرات الكود والوكيل
نظرة عامة على النماذج الثلاثة
| النموذج | نتيجة pytest | معدل الإصلاح | استدعاءات LLM | الوقت الفعلي | الإنتاجية الشاملة (رمز/ثانية) |
|---|---|---|---|---|---|
| Qwen3.6-Plus | فشل 1، نجاح 26 | 9/10 | 63 | 334ثانية | 41.5 |
| Qwen3.7-Plus | نجاح 27 | 10/10 | 52 | 205ثانية | 147.5 |
| Qwen3.7-Max | فشل 1، نجاح 26 | 9/10 | 20 | 249ثانية | 51.8 |
كان حصول Plus على نتيجة BugFind أفضل في التشغيل الفردي أمراً غير متوقع:
- كان Plus هو التشغيل الوحيد بنتيجة 10/10 في هذا الاختبار.
- استخدم Max أقل عدد من الاستدعاءات لكنه لم يحصل على الدرجة الكاملة. توقف 3.7-Max بعد 20 استدعاء فقط، وهو الأقل بين الثلاثة. كان يميل إلى "التفكير لفترة طويلة وإجراء تغيير واحد كبير"، مع تكرارات أقل. في المقابل، استخدم 3.7-Plus 52 استدعاءً وكان مستعداً للتعديل، والتشغيل، وفحص التعليقات، ثم التعديل مرة أخرى.
- كان لدى Plus أقصر وقت فعلي وأعلى إنتاجية. بالنسبة لتجربة وكيل IDE، هذا يهم أكثر بكثير من بضع نقاط Elo على لوحة الصدارة.
مهمة واحدة، ثلاث فلسفات إصلاح: تحليل عميق لـ task05
تختبر هذه المهمة القاعدة التي تنص على عدم تمرير ملفات JSON غير الصالحة بصمت. عندما يرى التحليل بيانات سيئة، يجب ألا يتظاهر بالنجاح ويعيد كائناً فارغاً؛ بل يجب أن يبلغ عن الخطأ بوضوح. الخطأ الأصلي:
plaintext1def safe_parse(data: str): 2 try: 3 return json.loads(data) 4 except Exception: 5 return {} # الخطأ: يبتلع الاستثناء
تتطلب الاختبارات:
- بالنسبة للإدخال مثل "this is not json {"، يجب ألا تعيد الدالة قاموساً فارغاً {}.
- بالنسبة للإدخال غير الصالح بدون أقواس، مثل "bad"، يجب أن يطرح استثناءً.
نهج Max (اختبار خارجي ✗): طرح خطأ مخصص JSONParseError.
يبدو هذا حلاً نظيفاً، ولكن بالنسبة لـ "this is not json {" طرح الخطأ فوراً، ففشل الاختبار قبل أن تبدأ التأكيدات. ومع ذلك، قال CHANGELOG الخاص بـ Max بثقة "تم النجاح في 27". هذا بالضبط هو سبب إلزامية التحقق الخارجي: غالباً ما تتباعد التقييمات الذاتية للوكيل والتدقيق الخارجي.
3.6-Plus (خارجي ✗): فشل في نفس العقبة الأولى.
3.7-Plus (خارجي ✓):
plaintext1if re.search(r'[\{\[\]\}]', data): 2 return {"error": str(e), "raw": data} 3raise ValueError(f"Invalid JSON: {e}") from e
بالنسبة للمدخلات المشوهة التي تحتوي على أقواس، فإنه يعيد كائن خطأ يمكن تمييزه عن {}. بالنسبة للمدخلات التي لا تحتوي على أقواس على الإطلاق، فإنه يطرح الخطأ. لقد أصاب جانبي عقد الاختبار بدقة.
لماذا لم يحصل Max على العلامة الكاملة في هذه المهمة؟ ابدأ بعدد الاستدعاءات:

توقف 3.7-Max بعد 20 استدعاء نموذج فقط، وهو الأقل بين الثلاثة. كان يميل إلى "التفكير لفترة طويلة وإجراء تغيير واحد كبير"، مع تكرار أقل. استخدم 3.7-Plus 52 استدعاءً وكان مستعداً للتعديل، والتشغيل، وفحص التعليقات، ثم التعديل مرة أخرى. في مهام برمجة الوكيل التي تتطلب تفاعلاً متكرراً مع البيئة، قد يساعد التكرار الأكبر في تغطية الحالات الحدية التي فوتها Max في هذه الجولة. هذا يشير إلى حقيقة غالباً ما يتم التغاضي عنها: في مهام الوكيل، "الاستنتاج الأعمق" لا يعني بالضرورة تقديماً أكثر استقراراً. الاستخدام الجيد لتعليقات الأدوات مهم بنفس القدر.
في جودة الإصلاح، أبلى الثلاثة بلاءً حسناً في task03. هذه المهمة تربط user_id مباشرة بمسار ملف، لذا يمكن لـ ".." إنشاء اجتياز مسار ويمكن لـ "user;rm -rf" حمل أحرف تعريف شل (shell metacharacters). أضاف الإصلاح منظفاً للقائمة البيضاء، محدداً عيباً أمنياً حقيقياً بدلاً من التصحيح الأعمى لاختبارات خضراء:
plaintext1user_id = re.sub(r'[^a-zA-Z0-9_-]', '', user_id) or "unknown"
استنتاجات هندسية:
- لمهام الوكيل، الرغبة في التعامل مع البيئة (كان لدى Plus 52 دور حوار و98 تنفيذ كود) أهم من التكرار الأدنى.
- توقف Max بعد 20 دوراً واعتقد قبل الأوان أن task05 تم حلها.
- في إصلاح الأخطاء التفاعلي، ليس دائماً حلاً "طرح استثناء" أكثر فائدة من إعادة بيانات متسخة في شكل قابل للتمييز.
4. الاستنتاج والرياضيات: وضع التفكير هو قرار تكلفة
تؤكد سلسلة Qwen3.7 على "التفكير الهجين"، الذي يتم التحكم فيه من خلال مفتاح enable_thinking. هل يستحق هذا المفتاح التفعيل؟ قمنا بإجراء استئصال عبر مجموعتين من المهام ذات صعوبة مختلفة جداً. كانت المجموعة الصعبة هي AIME 2025 I، وهي مسابقة نُشرت بعد تواريخ التدريب المرجحة للنماذج وبالتالي كانت أكثر مقاومة للتلوث. قمنا بفحص كل مسألة وإجابة مقابل مصدرين مستقلين، AoPS وAreteem، ثم قمنا بالتصحيح تلقائياً.
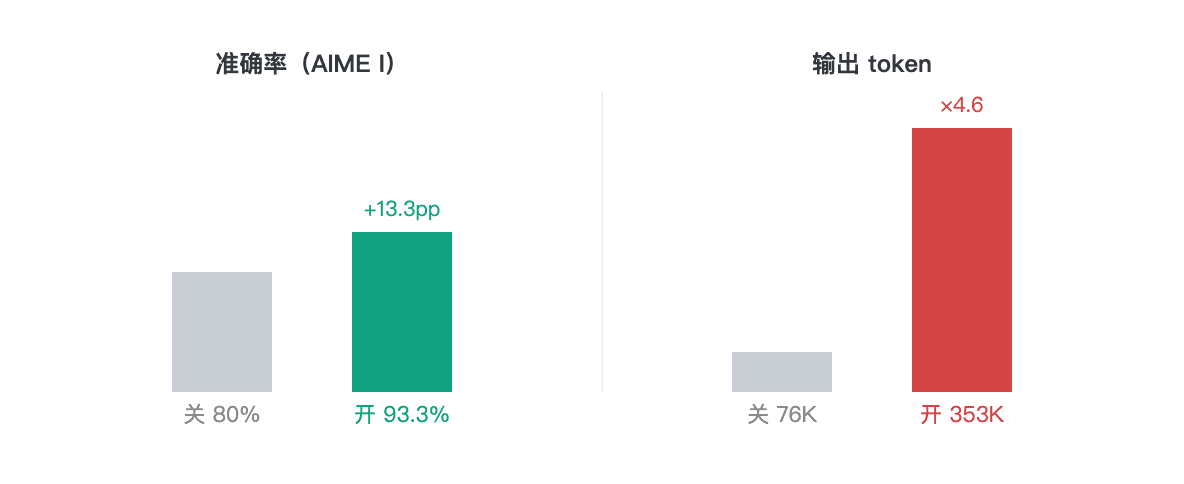
| النموذج / الوضع | الدقة | متوسط الوقت/مسألة | رموز الإخراج |
|---|---|---|---|
| 3.7-Plus · تفكير معطل | 12/15 (80%) | 24.7ثانية | 76,502 |
| 3.7-Plus · تفكير مفعل | 14/15 (93.3%) | 113.4ثانية | 353,424 |
| 3.7-Max · تفكير مفعل | 14/15 (93.3%) | 303.1ثانية | 307,801 |
| 3.6-Plus · تفكير | أول 6 مسائل: 6/6 | 464ثانية | 25.7ألف/مسألة |
مقارنة التكلفة:
| الإعداد | صحيح | الدقة | متوسط الوقت/مسألة | إجمالي رموز الإخراج | متوسط رموز/ثانية | تكلفة تقريبية |
|---|---|---|---|---|---|---|
| Plus تفكير معطل | 12/15 | 80.0% | 24.7ثانية | 76,502 | 204.0 | USD0.15 |
| Plus تفكير مفعل | 14/15 | 93.3% | 113.4ثانية | 353,424 | 205.4 | USD0.69 |
| Max تفكير مفعل | 14/15 | 93.3% | 303.1ثانية | 307,801 | 68.3 | USD0.60 |
ملاحظة: تم تقدير أسعار البدائل مع 3.6-Plus عند USD0.325/USD1.95 للمليون. سعر البوابة الرسمي USD0.40/USD1.60 أقرب لأسعار الإنتاج.
الفائدة الهامشية لمفتاح التفكير
مع تفعيل الاستنتاج، وصل Plus إلى نفس نتيجة AIME في التشغيل الفردي مثل Max. سجل كل من 3.7-Plus مع تفعيل التفكير و3.7-Max نتيجة 14/15، لكن Plus استغرق 113 ثانية لكل مسألة بينما استغرق Max 303 ثوانٍ. في هذه الجولة، لم ينتج زمن استجابة Max الأطول نتيجة أعلى؛ ولا يزال هذا التشغيل الفردي لا يثبت أن Max ليس لديه ميزة في مسائل الرياضيات الأخرى.
في 8 مسائل لغوية للمرحلة الابتدائية، كان كلا الوضعين صحيحين بنسبة 100%. أدى تفعيل التفكير إلى استهلاك 24% فقط من الرموز الإضافية. ضع المجموعتين معاً والاستنتاج واضح:
عطل التفكير للمهام البسيطة لتوفير المال؛ فعله للمهام الصعبة لشراء الدقة. ترك الاستنتاج مفعلاً عالمياً يعني دفع أكثر من 4 أضعاف التكلفة باستمرار في الطلبات البسيطة دون أي مكسب في الدقة. قيمة المفتاح هي أنه يتيح لك التوجيه ديناميكياً حسب صعوبة المهمة.
Max مقابل Plus: من أين جاء زمن الاستجابة في هذه الجولة
سجل Max أيضاً 14/15 وفشل أيضاً في I-14 (توقع 69، الإجابة الصحيحة 60). نفس الاختبار، نفس المسألة الفاشلة، نفس نمط الفشل، وليس "كان Max أذكى وفشل في حالة صعبة مختلفة". حل Max المسألة I-15 بينما فوتها Plus، لذا هناك تباين في المسائل الصعبة جداً، ولا يمكن لتشغيل واحد إعلان نموذج أقوى عالمياً.
لكن فجوة السرعة كانت مذهلة. في المسألة I-2، استغرق Max 261 ثانية؛ استغرق Plus 108 ثوانٍ فقط. عبر المجموعة الكاملة، بلغ متوسط Max 68.3 رمز/ثانية بينما بلغ متوسط Plus 205.4، أسرع بحوالي 3 أضعاف.
الخلاصة: بمجرد تفعيل التفكير، وصل Plus إلى نفس نتيجة التشغيل الفردي مثل Max في مجموعة رياضيات المسابقات هذه مع الحفاظ على ميزة واضحة في زمن الاستجابة والتكلفة. بالنسبة للسيناريوهات التفاعلية في الوقت الفعلي، هذا الاختلاف مهم.
مراقبة المهام البسيطة
استخدمنا 8 مسائل لغوية للمرحلة الابتدائية كاختبار حمل بسيط:
| الوضع | الدقة | متوسط الوقت | إجمالي رموز الإخراج |
|---|---|---|---|
| تفكير معطل | 8/8 | 2.17ثانية | 2,314 |
| تفكير مفعل | 8/8 | 2.48ثانية | 2,881 |
أدى تفعيل التفكير إلى استهلاك 24% من الرموز الإضافية بدون مكسب في الدقة. الصعوبة هي المعيار المنطقي الوحيد لتفعيل وضع التفكير.
5. السرعة، الفجوة الجيلية، ومهمة واحدة اضطررنا لإنهاؤها
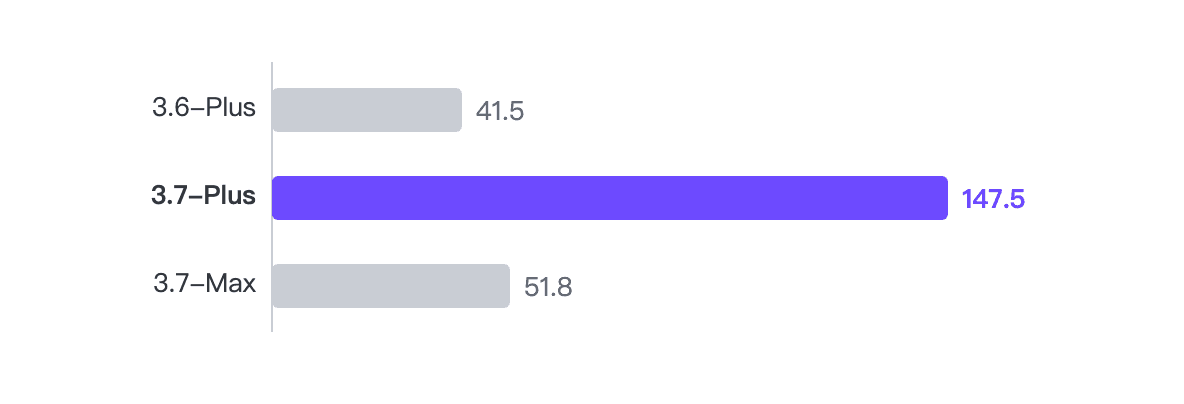
مقارنة إنتاجية الوكيل
السرعة الحقيقية من البداية إلى النهاية المستخرجة من BugFind runner_summary.json:
- 3.7-Plus: 147.5 رمز/ثانية (52 استدعاء، 204.8ثانية)
- 3.7-Max: 51.8 رمز/ثانية (20 استدعاء، 249.0ثانية)
- 3.6-Plus: 41.5 رمز/ثانية (63 استدعاء، 334.5ثانية)
كان التحسن الجيلي (3.6 → 3.7 Plus) حوالي 3.55 ضعف. Plus مقابل Max من نفس الجيل كان حوالي 2.85 ضعف.
جاء المثال الأكثر دراماتيكية للفجوة الجيلية من تشغيل الرياضيات على 3.6-Plus. أردنا إضافة نتيجة AIME لها أيضاً، لكنها كانت بطيئة جداً بحيث لم تستطع الإنهاء: استمر الاستنتاج حتى الوصول إلى الحد الأقصى في كل مسألة، وصل إخراج المسألة الواحدة إلى 16ألف-52ألف رمز، واستغرقت كل مسألة 297-932 ثانية. استغرقت المسائل الست الأولى وحدها 46 دقيقة. لم يكن تشغيل كامل لـ 15 مسألة ممكناً ضمن أي ميزانية زمنية معقولة، فتوقفنا.
حاولنا "تحديد الوقت" بتقليل max_tokens من 16000 إلى 4096. لم ينجح ذلك. هذا فخ هندسي يستحق التسجيل:
- في وضع التفكير، لا يتم تقييد رموز الاستنتاج بواسطة max_tokens؛ لا يزال بإمكان النموذج إصدار عشرات الآلاف من رموز الاستنتاج.
- مهلة الطلب (Request timeout) ليست كافية أيضاً. مهلة OpenAI/httpx هي "مهلة قراءة" بين أجزاء البيانات. طالما أن الاستجابة المتدفقة مستمرة في إصدار الرموز، فإن تلك المهلة لا تعمل أبداً.
تم حظر مساري المهلة، لذا قضينا على العملية وأبلغنا عن المسائل الست الأولى المسترجعة: 6/6 صحيحة. هذا يعني أن قدرة الرياضيات في 3.6-Plus لم تكن المشكلة. كان بإمكانها حل المسائل. لكن "يمكن الحل" و"يمكن الإنهاء ضمن وقت يتحمله المستخدمون" هما ادعاءان مختلفان. بالنسبة لنموذج إنتاج يجب أن يستجيب للمستخدمين، غالباً ما يكون الأخير أكثر أهمية. هذا هو بالضبط البعد الذي تخفيه لوحات الصدارة غالباً ولكن تفضحه تجربة المستخدم.
نصيحة لفرق الهندسة: بالنسبة لنماذج التفكير، يمكن أن تفشل استراتيجيات المهلة وmax_tokens التقليدية. أنت بحاجة إلى إجمالي ميزانية الرموز، سقف إجمالي للوقت الفعلي، أو سقف لرموز الاستنتاج.
6. النتيجة الرئيسية الرابعة: تعدد الوسائط - الصورة الموجهة نجحت، والمثال الرسمي فشل
| عينة الاختبار | الإدخال | إخراج النموذج | الحكم |
|---|---|---|---|
| صورة موجهة | PNG كتلة حمراء/زرقاء (محلي) | "أزرق، برتقالي" | ✓ صحيح |
| مثال رسمي | dog_and_girl.jpeg (OSS) | "مجموعة من الأشخاص يقفون بجانب قطار..." | ✗ خاطئ تماماً |
تصنف Arena Vision نموذج Plus في المرتبة #16 (معاينة). يقيس هذا المعيار حوار الصورة والنصوص تحت تفضيل بشري. يُظهر اختبارنا أن درجة عالية في لوحة الصدارة وفشل في صورة واحدة يمكن أن يتعايشا.
نصيحة لمختاري النماذج: لم نقم بتشغيل معايير رؤية موحدة مثل MMMU أو ChartQA، لذا نحن لا ندعي ادعاءً واسعاً حول ما إذا كانت رؤية Plus جاهزة للإنتاج. لكن النتيجة واضحة: تشغيل 20-50 صورة من نطاق عملك الخاص (OCR، مخططات، لقطات واجهة المستخدم، إيصالات) أكثر موثوقية بكثير من قراءة لوحة صدارة.
اختبر بعض مستخدمي Hacker News النموذج أيضاً واستنتجوا أن "رؤية Qwen أقوى من Gemma". تلك التعليقات من المستخدمين ليست متناقضة؛ كانت تلك مهام خاصة. فشل صورة المثال الرسمية هو تذكير بأن النجاح الخاص والفشل الرسمي يمكن أن يتعايشا. يجب أن يكون اختيار النموذج مدفوعاً ببياناتك الخاصة.
7. التكلفة: ما كلفته هذه الجولة بأكملها
هذه المقالة نفسها عبارة عن عينة تكلفة. بعد تشغيل ثلاثة نماذج عبر أربعة أنواع من المهام، كان استخدام API الخاص بـ Qwen حوالي 2 مليون رمز (جزء 3.6-Plus المتوقف لم يُحسب بالكامل)، بتكلفة بديلة تبلغ حوالي USD2-3.
فاتورة جولة الاختبار هذه
| العنصر | مقياس الرموز | تكلفة بديلة |
|---|---|---|
| AIME Plus مفعل | 353ألف إخراج | ~USD0.69 |
| AIME Plus معطل | 76ألف إخراج | ~USD0.15 |
| AIME Max مفعل | 308ألف إخراج | ~USD0.60 |
| BugFind × ثلاثة نماذج | إدخال تراكمي مرتفع جداً | متضمن في الإجمالي |
| الإجمالي | ~2 مليون | USD2-3 |
الرؤية 1: تكلف جولة تقييم جادة بقدر تكلفة وجبة. يجب على الفرق إنفاق ذلك المال على إعادة تشغيل مهامهم الخاصة، وليس على نصوص التسويق.
الرؤية 2: تكلفة الوكيل ليست بشكل أساسي سعر الوحدة. إنها عدد الأدوار × طول التاريخ لكل دور. استخدم BugFind 52-63 استدعاءً لكل نموذج، ويمكن لإدخال الدور الواحد أن يتجاوز 11ألف رمز. يجب أن يستهدف التحسين ضغط التاريخ، وتفكيك الوكيل الفرعي، والتخزين المؤقت، وليس فقط تسعير النموذج الأرخص.
مقارنة سعر البوابة (2026-06-01)
| النموذج | الإدخال / الإخراج للمليون |
|---|---|
| qwen3.7-plus | USD0.40 / USD1.60 |
| qwen3.7-max | USD1.25 / USD3.75 |
Max أغلى بحوالي 3 أضعاف من Plus (حوالي 2.3 ضعف في الإخراج)، بينما أظهرت هذه الجولة نفس نتيجة AIME ودرجة أقل بنقطة واحدة في BugFind. عادة ما تكون تكلفة الوقت أغلى من تكلفة الرموز: وقت انتظار المهندس وفتحات الوكيل المشغولة هي مال أيضاً.
8. نصيحة اختيار النموذج للمطورين
| السيناريو | التوصية |
|---|---|
| بناء وكلاء / برمجة / إصلاح أخطاء | ضع 3.7-Plus في مجموعة المرشحين الافتراضية. كان هذا التشغيل الفردي 10/10، مع إنتاجية عالية وتكرار أكبر؛ احتفظ بـ Max كخيار رائد للنصوص / احتياطي للصعوبة العالية، ولا تختر حسب تسمية الرائد فقط. |
| استنتاج أو رياضيات متوسطة الصعوبة، مع حساسية لزمن الاستجابة | 3.7-Plus مع تفعيل التفكير. في هذه الجولة طابق دقة Max بزمن استجابة أقل. |
| أسئلة وأجوبة بسيطة / تصنيف / استخراج | 3.7-Plus مع تعطيل التفكير. وفر تكلفة الاستنتاج الإضافية. |
| لا يزال يستخدم 3.6-Plus | قم بالترقية. الفجوة الجيلية الرئيسية هي السرعة، وإنتاجية 3.5 ضعف تغير تجربة المستخدم. |
9. القيود والإفصاحات الصادقة
هذه المقالة هي لقطة عميقة من فترة بعد الظهيرة، وليست ورقة أكاديمية. القيود التالية مهمة:
- تشغيل فردي: لم يستخدم BugFind ولا AIME الـ pass@k. حالات التباين العالي مثل task05 وI-15 تحتاج إلى تحقق متكرر.
- لا توجد مقارنة منافسين أفقيين: لم يتم اختبار Claude وGPT وGemini وDeepSeek. هذا يصف فقط الاختلافات الداخلية داخل عائلة Qwen.
- أكمل 3.6-Plus 6 مسائل AIME فقط: لا يمكن مقارنة دقته مباشرة مع تشغيلات Plus/Max لـ 15 مسألة.
- استخدم التسعير تقديرات بديلة: تحقق من أحدث أسعار البوابة للأرقام الرسمية؛ قد يكون لأسعار DashScope المحلية خصومات منفصلة.
- استُخدم إطار عمل وكيل واحد فقط (Stirrup): قد يؤدي التبديل إلى SWE-agent إلى تغيير الترتيب.
- حجم عينة تعدد الوسائط كان n=2: لا يمكن أن يمثل قدرة رؤية واسعة.
- النموذج المختبر كان نسخة بيتا للمدعوين: قد يكون لدى SKU الرسمية تغييرات طفيفة في السلوك.
- بيانات X كانت لقطة ليوم واحد: التقطت مشاعر المجتمع في وقت الكتابة وقد تكون تغيرت بعد النشر.
ملاحظة أخيرة
في السرد الرسمي لشهر يونيو 2026، Qwen3.7-Plus هو الفئة الرائدة الصينية في لوحة صدارة الرؤية، والخيار الفعال من حيث التكلفة على البوابة، وعضو عائلة Qwen الجديد الذي يصفه المجتمع بأنه يتحرك بسرعة تكرار مخيفة.
في كوننا القابل للتكرار لفترة بعد الظهيرة، هو:
- النموذج الذي كان الوحيد الذي سجل 10/10 في جولة إصلاح أخطاء الكود الحقيقي هذه.
- النموذج الذي وصل إلى نفس نتيجة Max في جولة رياضيات المسابقات هذه مع تفعيل التفكير، مع إظهار زمن استجابة أقل.
- النموذج الذي قدم تحسناً في الإنتاجية بمقدار 3.55 ضعف عن الجيل السابق، مما جعل "عدم القدرة على الإنهاء" شيئاً من الماضي.
- النموذج الذي لا يزال يهذو في صورة المثال الرسمية بينما يجتاز اختبار الصورة الموجهة الخاص بنا، ليذكرك بعدم اختيار نموذج رؤية من لقطة شاشة واحدة.
هذه الاستنتاجات مقصورة على هذه العينة الصغيرة، والتشغيل الفردي، والهيكل الثابت. إنها تدعم وضع Plus في مجموعة المرشحين الافتراضية للهندسة؛ وهي لا تدعم ترتيباً عاماً للنموذج.
للمهندسين، السرد الرسمي مسؤول عن الرؤية؛ الدليل مسؤول عن مخرجات الـ directory. إذا كنت تختار نموذجاً للإنتاج، فاقرأ هذه المراجعة مع نسخة تصور البيانات المصاحبة ([13_Qwen3.7-Plus_Eval.html](13_Qwen3.7-Plus_Eval.html)): ثق بالأرقام أولاً، ثم اقرأ لماذا نحن مستعدون لتسمية هذا "تقييماً" بدلاً من إعادة نشر.
في فيضان نماذج الذكاء الاصطناعي لعام 2026، فقط الأدلة القابلة للتكرار بدرجة التدقيق هي العملة الصعبة للقرارات التقنية.






