
Les balises de genre ID3 rigides nuisent à votre collection de musique locale. En associant l'analyse sonore avancée d'AudioMuse-AI à l'API évolutive d'AtlasCloud, vous pouvez transformer un répertoire statique de fichiers multimédias en un moteur de découverte sémantique hautement intuitif, capable d'envoyer directement des playlists basées sur l'émotion vers votre serveur auto-hébergé.
![]()
Retrouver la chaleur de la musique : créez une bibliothèque locale vraiment intuitive avec AudioMuse-AI
Vous êtes à votre bureau, tard le soir. Vous n'avez pas envie d'écouter une playlist électronique énergique, et vous n'êtes pas non plus d'humeur pour de la musique classique pure et stérile. Ce que vous voulez réellement, c'est une ambiance très spécifique : « De l'indie folk calme et atmosphérique, avec de subtiles nuances acoustiques de jour de pluie pour m'aider à me détendre. »
Si vous ouvrez votre instance auto-hébergée de Navidrome ou Jellyfin et que vous tapez cette phrase exacte dans la barre de recherche, vous n'obtiendrez aucun résultat.
Pendant des décennies, nous, les accros à la musique numérique, avons passé d'innombrables heures à organiser méticuleusement les balises ID3, à nettoyer les pochettes d'albums et à faire entrer de force des formes d'art fluides dans des catégories de genres rigides comme « Rock », « Jazz » ou « Pop ». Mais soyons honnêtes : les étiquettes de genre sont des reliques du marketing des disquaires du XXe siècle. Elles ne comprennent pas ce que la musique exprime réellement.
L'avenir de la gestion d'une collection musicale privée n'appartient pas aux métadonnées statiques. Il appartient à l'analyse audio sémantique. Les grands modèles de langage (LLM) sont bien plus que de simples interfaces de chat ; ils sont la clé ultime pour décoder le poids émotionnel inquantifiable de votre musique. En déployant l'outil open-source AudioMuse-AI aux côtés d'un routeur LLM intelligent comme AtlasCloud, vous pouvez redonner vie à vos fichiers locaux et générer des playlists basées sur l'ambiance pure, la texture sonore et la signification des paroles.
Qu'est-ce qu'AudioMuse-AI ?
AudioMuse-AI est un moteur d'intelligence audio open-source auto-hébergé, conçu pour s'intégrer directement à votre configuration multimédia existante. Il agit comme un cerveau propulsé par l'IA qui se connecte directement aux plateformes musicales auto-hébergées populaires comme Jellyfin, Navidrome, LMS/Lyrion et Emby.
Au lieu d'analyser des balises textuelles, AudioMuse-AI traite les fichiers audio bruts. Il exécute des modèles de réseaux neuronaux localisés pour extraire des vecteurs acoustiques mathématiques complexes (en utilisant le pré-entraînement contraste langue-audio ou CLAP) et cartographie les thèmes lyriques dans 72 langues prises en charge.
Une fois l'analyse initiale terminée, vous débloquez des fonctionnalités qui font paraître les algorithmes de streaming commerciaux bien superficiels :
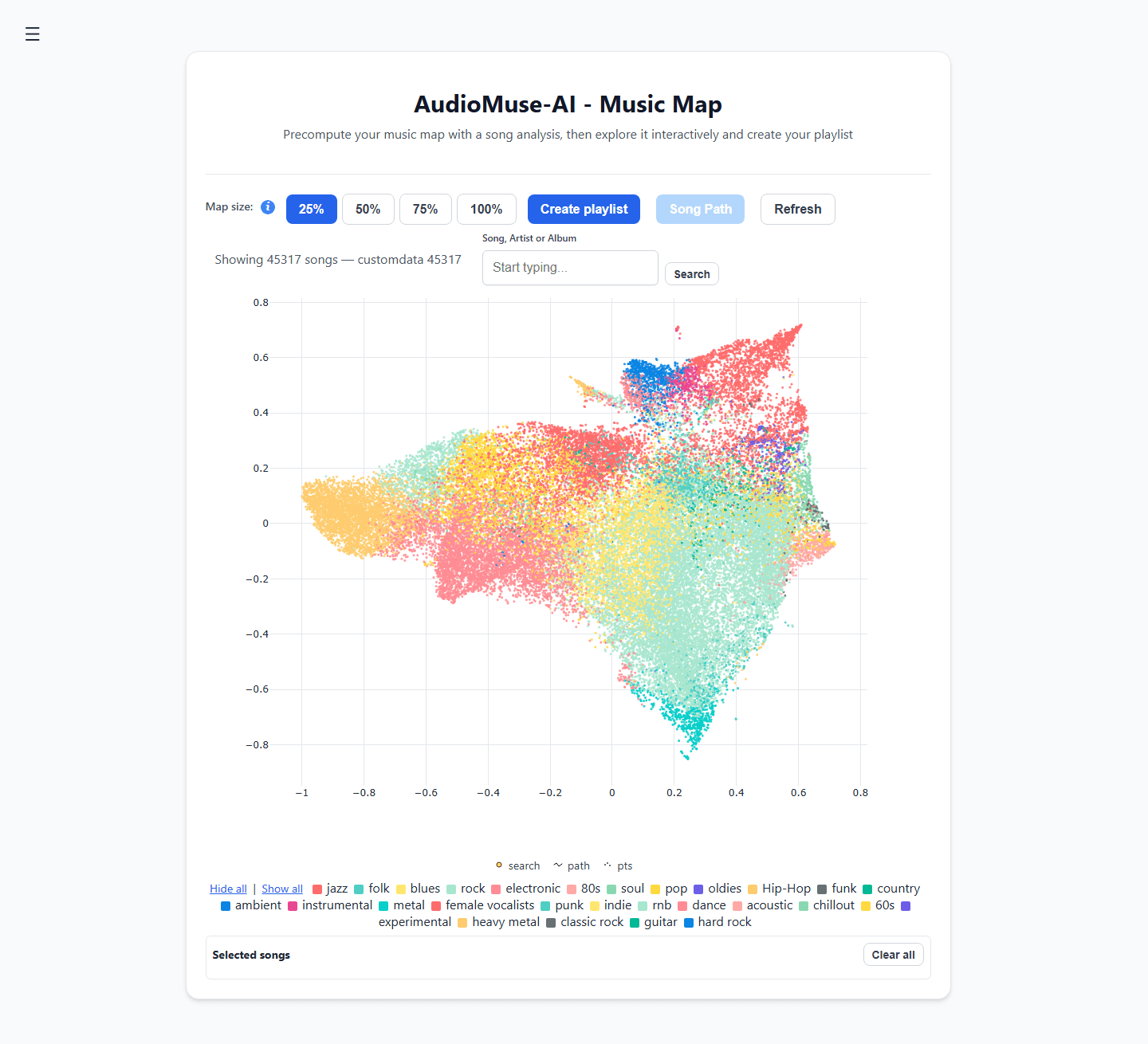
- Regroupement acoustique (Clustering) : Trace automatiquement votre bibliothèque musicale sur une « carte musicale » interactive en 2D, regroupant les morceaux par leurs ondes sonores réelles plutôt que par des genres arbitraires.
- Chemins musicaux (Song Paths) : Choisissez un morceau funk entraînant comme point de départ et une pièce ambiante mélancolique comme destination. Le moteur calculera automatiquement le pont sonore entre les deux, générant une playlist qui change d'ambiance progressivement et parfaitement.
- Recherche sémantique de paroles : Recherchez dans votre bibliothèque par thème narratif ou concepts émotionnels (par exemple, « chansons sur le fait de grandir dans une petite ville »), plutôt que de simplement chercher des correspondances textuelles exactes.
Guide étape par étape : construire votre moteur de découverte musicale sémantique
Voyons comment mettre en place une pipeline complète de playlist sémantique sans métadonnées.
Étape 1 : Préparation de l'environnement et déploiement
AudioMuse-AI peut être exécuté nativement sur macOS, Linux et Windows, mais pour un serveur domestique standard ou un NAS, Docker Compose est la solution la plus propre.
Créez un répertoire sur votre serveur, récupérez le
1docker-compose.yamlYAML
plaintext1version: '3.8'services:audiomuse:image: neptunehub/audiomuse-ai:latestcontainer_name: audiomuse-aiports:- "8000:8000"volumes:- /path/to/your/music:/music:ro- ./data:/app/dataenvironment:- POSTGRES_PASSWORD=your_secure_password- REDIS_PASSWORD=your_secure_passwordrestart: unless-stopped
⚠️ Contrainte matérielle : Les modèles d'IA sous-jacents reposent largement sur les jeux d'instructions CPU modernes. Si vous exécutez cela dans un environnement virtualisé comme Proxmox, assurez-vous que votre type de CPU est réglé sur "Host" pour transmettre le support AVX2. Si vous l'exécutez sur un CPU virtuel QEMU générique, le conteneur plantera immédiatement au démarrage.
Lancez-le en exécutant :
Bash
plaintext1docker compose up -d
Étape 2 : Lancement de l'analyse du framework audio
Ouvrez votre navigateur et accédez à http://VOTRE-IP-SERVEUR:8000. Vous serez accueilli par l'assistant de configuration initial. Liez votre serveur multimédia (par exemple, en entrant votre URL Navidrome et votre jeton API personnel).
Une fois lié, accédez au tableau de bord Analysis and Clustering et cliquez sur "Start Analysis".
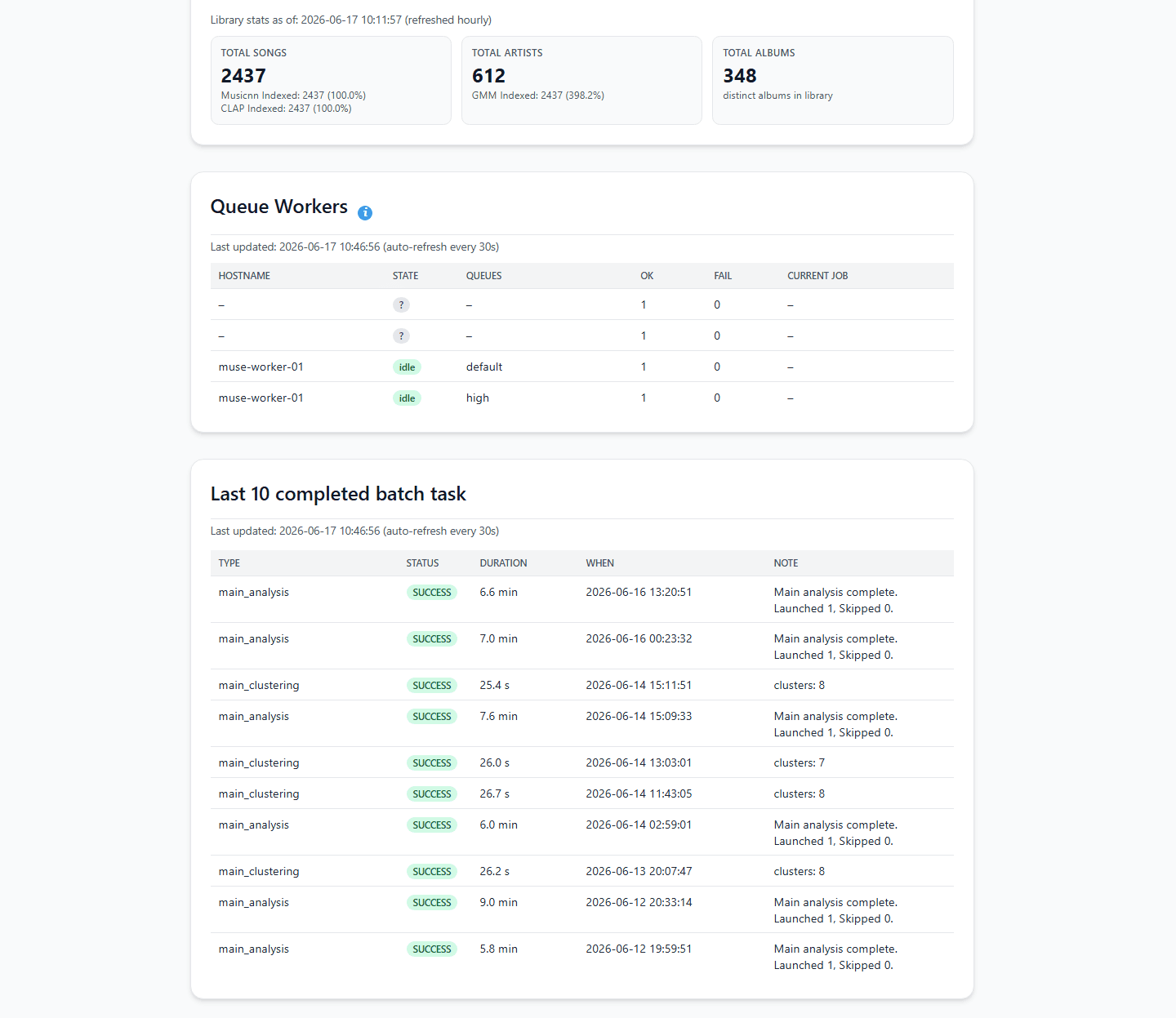
Le moteur commencera à calculer les empreintes acoustiques. Selon la taille de votre bibliothèque et le matériel utilisé (mini PC Intel i5 ou Raspberry Pi 5), cette phase d'analyse initiale peut prendre de quelques minutes à plusieurs heures.
Étape 3 : Alimenter le cerveau de l'IA via AtlasCloud
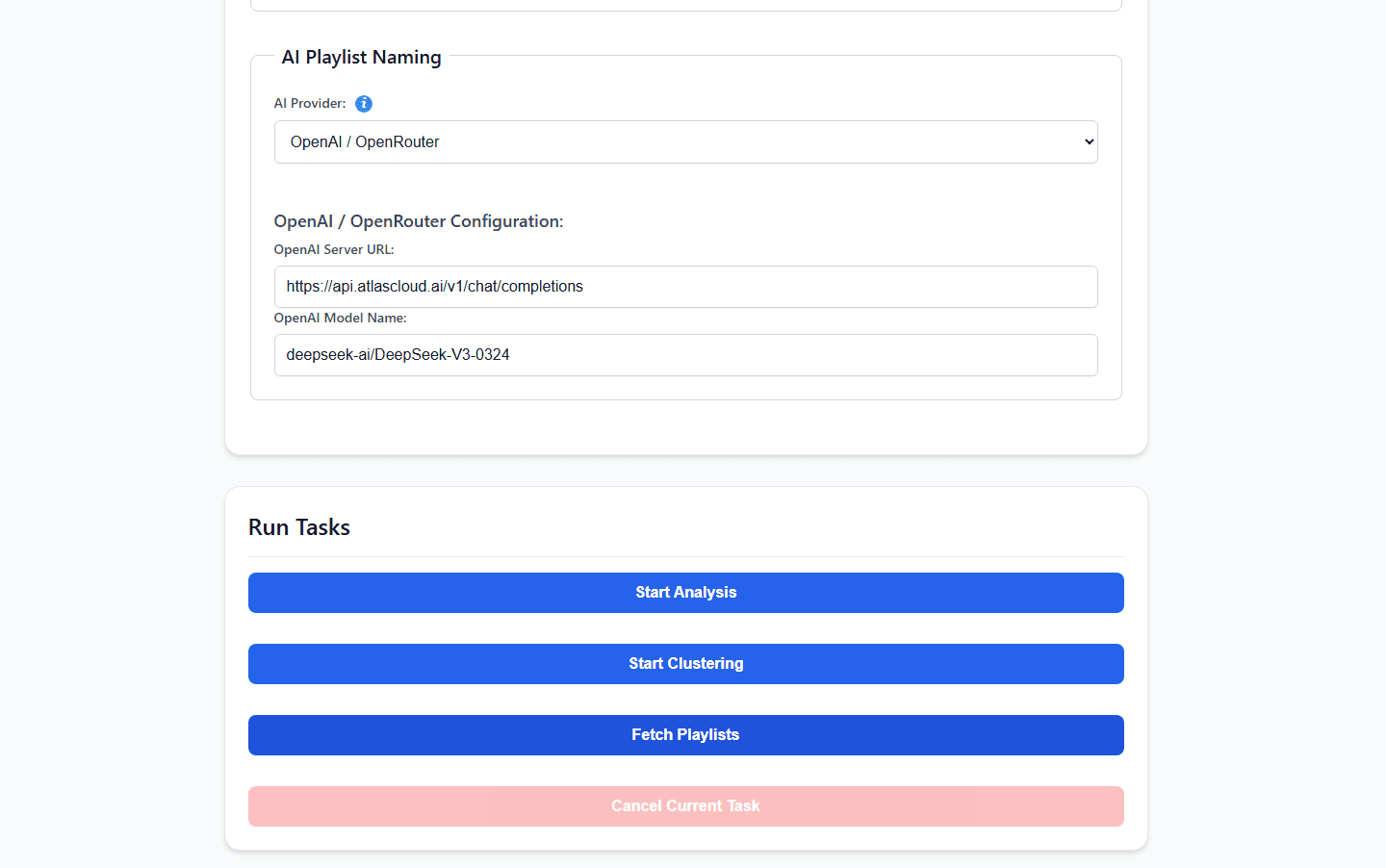
C'est ici que nous rencontrons un goulot d'étranglement classique de l'auto-hébergement. AudioMuse-AI propose une interface de chat interactive pour les playlists (app_chat.py) et un moteur d'intégration de paroles approfondi. Exécuter localement des modèles de langage massifs et complexes pour gérer ces requêtes sémantiques peut facilement saturer le CPU de votre NAS à 100 %, causant des délais d'expiration API et des générations de playlists lentes.
Pour garder votre matériel local léger, frais et silencieux, nous pouvons décharger le raisonnement sémantique complexe vers une API externe. Comme indiqué officiellement dans le Guide du fournisseur d'IA compatible OpenAI du projet, vous pouvez acheminer vos requêtes via AtlasCloud de manière transparente en utilisant le fournisseur principal OPENAI.
Ajoutez simplement ces variables dans la configuration de l'environnement de déploiement de votre serveur :
Bash
plaintext1AI_MODEL_PROVIDER=OPENAI 2OPENAI_SERVER_URL=https://api.atlascloud.ai/v1/chat/completions 3OPENAI_MODEL_NAME=qwen3.5:9b 4OPENAI_API_KEY=your_secure_atlas_cloud_key
En tirant parti d'AtlasCloud, vous évitez d'avoir à gérer des modèles massifs de plusieurs gigaoctets sur votre disque dur local. Une seule clé donne à AudioMuse-AI un accès instantané à des modèles de raisonnement haute performance pour analyser vos requêtes en langage naturel à la volée, avec des latences de traitement inférieures à la seconde.
Étape 4 : Générez votre première playlist d'ambiance
Avec AtlasCloud gérant le mappage sémantique, accédez à l'onglet Instant Playlists. Testons la capacité du système à franchir les frontières traditionnelles. Tapez une requête très abstraite :
"Donne-moi une ambiance de conduite sous la pluie tard le soir. Commence par quelque chose d'acoustique et lent, mais fais la transition vers quelque chose avec une impulsion électronique entraînante vers la fin."
AtlasCloud traite l'intention émotionnelle principale de votre requête, renvoie le plan structurel à l'index vectoriel local d'AudioMuse-AI et renvoie instantanément une sélection magnifiquement organisée. Cliquez sur "Export to Media Server", et la playlist personnalisée est instantanément envoyée à l'application musicale de votre téléphone via Jellyfin ou Navidrome.
Comparaison : IA audio locale vs concurrence
| Fonctionnalité | AudioMuse-AI + AtlasCloud | Plex / Plexamp | Spotify / Apple Music |
| Confidentialité & Contrôle | Propriété totale. Les données restent locales ; les requêtes LLM sont proxyfiées de manière sécurisée. | Semi-privé. Nécessite un compte propriétaire et un Plex Pass actif. | Aucune confidentialité. Vos logs d'écoute sont monétisés pour le suivi publicitaire. |
| Dépendance aux métadonnées | Aucune. Analyse directement les formes d'onde audio brutes et les thèmes des paroles. | Élevée. Dépend fortement de balises de base précises avant que l'analyse ne commence. | Absolue. Repose entièrement sur les étiquettes des labels commerciaux et les ID de base de données. |
| Performance "Cold-Start" | Parfaite. Peut analyser un morceau indie local obscur et le cartographier instantanément. | Faible. Ne parvient pas à contextualiser les morceaux s'ils ne correspondent pas à la base de données Plex. | Terrible. Si une chanson manque de millions de lectures mondiales, l'algorithme l'ignore. |
| Recherche sémantique | Avancée. Comprend des requêtes en langage naturel complexes via LLM. | Inexistante. Limitée aux filtres de base (année, genre, balises d'humeur). | Modérée. Bonne analyse de texte, mais strictement limitée aux éléments du catalogue. |
Mises en garde techniques et dépannage de production
- Le bug de ré-analyse des paroles VNNI : Si vous avez récemment mis à jour votre pile de conteneurs vers les dernières versions d'AudioMuse-AI, faites très attention à l'architecture de votre CPU. Les anciennes révisions du modèle d'intégration multilingue GTE pouvaient produire des mappages vectoriels dégradés sur d'anciens CPU dépourvus de jeux d'instructions VNNI (matériel pré-2019). Si vous exécutez sur votre hôte Linux et que vous n'obtenez aucun résultat, vous devriez supprimer vos tables de base de données héritées via le CLI PostgreSQL et relancer une analyse complète des paroles pour obtenir des résultats de recherche sémantique propres et précis.text
1grep -oE 'avx512_vnni\|avx_vnni' /proc/cpuinfo - Réglages de timeout du serveur multimédia : Lors de la synchronisation de vastes playlists contenant plus de 500 titres vers Navidrome, les poignées de main de synchronisation initiale peuvent dépasser les limites par défaut du proxy. Si vous voyez des pertes de connexion dans vos journaux, vérifiez le guide des paramètres officiels pour ajuster les indicateurs de timeout de votre serveur.
Questions fréquentes
Pourquoi mon test de connexion Jellyfin échoue-t-il lors de la configuration ?
C'est généralement dû à un formatage incorrect de l'URL de base ou à une portée de jeton API invalide. Assurez-vous d'utiliser l'adresse HTTP/HTTPS complète, y compris le port (par exemple,
1http://192.168.1.50:8096Puis-je exécuter AudioMuse-AI sur un vieux serveur sans jeux d'instructions AVX2 ?
Oui, mais vous ne pouvez pas utiliser les images Docker standard. Vous devrez explicitement tirer l'image docker spécialisée étiquetée avec le suffixe
1-noavx21neptunehub/audiomuse-ai:latest-noavx2Comment l'API AtlasCloud améliore-t-elle la vitesse de réponse d'app_chat.py ?
Lorsque vous interagissez avec l'assistant de playlist conversationnel, le système doit transformer vos commentaires en schémas JSON structurés. Le traitement de ce texte sur le CPU d'un serveur local peut prendre de 10 à 30 secondes par message. L'acheminement de ces requêtes spécifiques via un partenaire cloud optimisé comme AtlasCloud délivre des réponses en quelques millisecondes, garantissant que la mémoire de votre serveur local reste libre pour diffuser des fichiers FLAC à haut débit sans saccades.






