
Sie kennen das Gefühl.
Es ist spät. Sie haben eine Markenkampagne bereits zum vierten Mal überarbeitet. Die KI hat die Beleuchtung für die Heldenaufnahme gerade perfekt hinbekommen – aber das Gesicht Ihres Models hat sich zum dritten Mal heute Nacht subtil verändert. Gleiches Outfit. Andere Person. Sie können es nicht veröffentlichen. Sie können es nicht reparieren. Sie fangen von vorne an.
Um Mitternacht bearbeiten Sie kein Video mehr. Sie spielen Roulette.
Für jeden, der versucht, eine narrative Kontinuität aufzubauen – eine Produktdemo mit demselben Model in verschiedenen Einstellungen, ein Tutorial mit demselben Lehrer über mehrere Szenen hinweg, ein Musikvideo mit demselben Sänger über mehrere Schnitte – war das sogenannte "Character Drift" (Charakter-Abweichung) der stille Killer jedes KI-Videotools. Das ist der Grund, warum KI-Video bisher in der Purgatory der „netten Demos“ feststeckte, anstatt kommerziell erfolgreich zu sein.

Am 19. Mai auf der I/O 2026 untermauerte Googles Gemini Omni, dass diese Ära zu Ende geht.
Das gesamte Versprechen lässt sich auf einer Zeile der DeepMind-Produktseite von Google zusammenfassen: "Jede Bearbeitung, die Sie vornehmen, baut auf der vorherigen auf – und bewahrt so eine konsistente, kohärente Szene."
Die drei-stufige Violinisten-Demo, die still und leise Geschichte schrieb
Der bedeutendste Moment der I/O-Ankündigung war nicht die rollende Murmel. Auch nicht die Blasenskulptur. Es war ein Violinist.
Hier ist die exakte Sequenz, die Google auf der Bühne präsentierte und in seinem Blog veröffentlichte:
- Schritt eins: Ein Basisvideo eines Violinisten, der ein Lied auf einer Bühne spielt.
- Schritt zwei: Prompt – "Versetze den Violinisten in die Bildumgebung." Ergebnis: Der Spieler wird in einen neuen Hintergrund versetzt, aber Gesicht, Körperhaltung, Bogenhaltung und sogar der Winkel des Handgelenks bleiben identisch.
- Schritt drei: Ein weiterer Prompt – "Ändere den Kamerawinkel auf eine Perspektive über die Schulter des Violinisten." Ergebnis: Neuer Bildausschnitt. Derselbe Violinist. Dieselbe Identität. Dieselbe Performance.
Drei Durchgänge. Ein Subjekt. Null Abweichung.
Wenn Sie bereits nennenswerte Zeit mit aktuellen KI-Videotools verbracht haben, sieht das nach Schummelei aus. Ist es aber nicht. Es ist der erste öffentliche Beweis dafür, dass Multi-Turn-Refinement (mehrstufige Verfeinerung) – der Workflow, auf den Filmemacher, Werbetreibende und Pädagogen gewartet haben – technisch real und marktreif ist.
Warum Multi-Turn-Konsistenz die offene Wunde der KI-Videoerstellung war
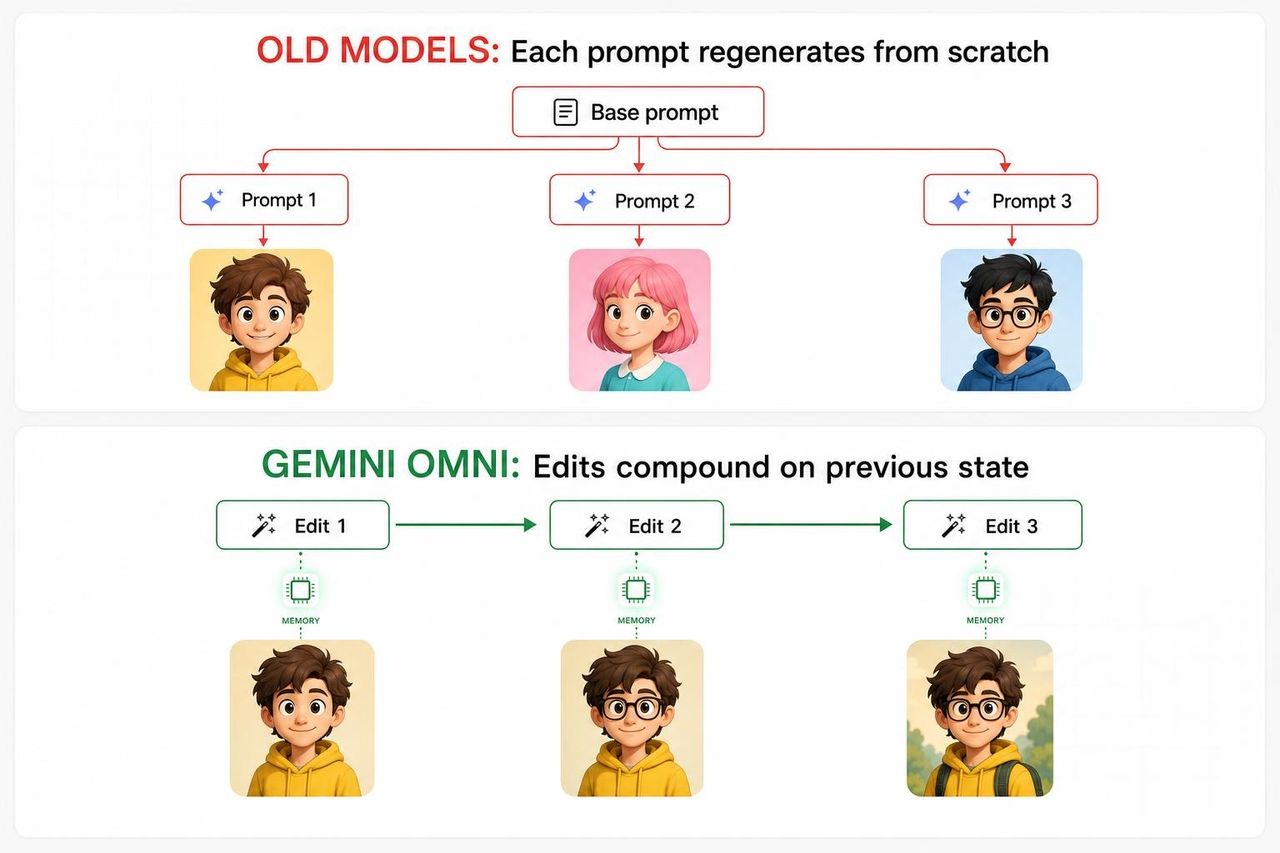
Um zu verstehen, warum die Violinisten-Demo so wichtig ist, muss man wissen, woran jedes andere KI-Videomodell bisher gescheitert ist.
Bei traditionellen generativen Videopipelines generiert jeder neue Prompt die Szene im Grunde von Grund auf neu – unter Verwendung des ursprünglichen Prompts plus des neuen Prompts als kombinierte Eingabewerte. Das Modell hat keine echte interne Kontinuität zwischen den Bearbeitungsschritten. Gesichter verändern sich. Requisiten im Hintergrund verschwinden. Die Beleuchtung ändert sich. Bis zum dritten Schritt ist das Ergebnis so weit von der ursprünglichen Vision abgewichen, dass die Ersteller aufgeben und neu starten.
Die Ursache liegt in der Architektur. Die meisten Videomodelle wurden als One-Shot-Generatoren trainiert, nicht als Multi-Turn-Agenten. Sie wurden darauf optimiert, aus einem Prompt ein einziges bestmögliches Ergebnis zu produzieren – nicht sich zu merken, was sie beim letzten Mal produziert haben, um darauf aufzubauen. Sie zur "Bearbeitung" aufzufordern, war faktisch gleichbedeutend damit, mit zusätzlichem Kontext neu zu beginnen, was mathematisch zu akkumulierter Abweichung statt zu akkumulierter Verfeinerung führte.
Omnis Ansatz ist anders. Es wurde als zustandsbasierter Editor (Stateful Editor) entwickelt – was bedeutet, dass jeder Schritt eine persistente Repräsentation der Szene aktualisiert, anstatt sie jedes Mal neu zu generieren.
Was "Die Szene erinnert sich" tatsächlich bedeutet
Die englischsprachige Tech-Presse kam zu der gleichen Erkenntnis, in ihren eigenen Worten.
Decrypt beschrieb den Durchbruch am präzisesten: "Google sagt, dass Omni dieselben Charaktere, Hintergründe und Bewegungen konsistent halten kann, selbst nachdem Benutzer Änderungen an einem Video vornehmen – etwas, womit viele KI-Videomodelle zu kämpfen haben."
Android Central hob das entscheidende technische Detail hervor: "Das Unternehmen gibt zudem an, dass sich das Modell während mehrstufiger Überarbeitungen an frühere Befehle erinnert, was die iterative Bearbeitung deutlich weniger chaotisch machen könnte."
TechRadar beschrieb es filmisch: "Charaktere bleiben erkennbar. Szenen wahren die Kontinuität. Bewegungen bleiben kohärent, anstatt sich bei jeder Prompt-Änderung zurückzusetzen."
Und Phandroid komprimierte die gesamte Leistungsfähigkeit in fünf Worte: "Die Szene erinnert sich an das, was vorher war."
Das ist die Pointe. Die Szene erinnert sich. Genau diese Eigenschaft ist der Unterschied zwischen KI-Video als Spielzeug und KI-Video als Werkzeug.
Wie Omni im Vergleich zu Sora, Veo und Seedance bei der Konsistenz abschneidet
Hier ist der direkte Vergleich der führenden KI-Videomodelle hinsichtlich der Multi-Turn-Konsistenz (Stand: Mai 2026):
| Modell | Multi-Turn-Bearbeitung | Konversationelle Verfeinerung | Charakterkonsistenz (Medium-Test) | Aktueller Status |
| Gemini Omni Flash | Zustandsbasiert, Multi-Turn | Native Chat-basiert | (3/5) | Live seit 19. Mai 2026 |
| Sora 2 (OpenAI) | One-Shot-Regenerierung | Begrenzt | Eingestellt | Sora-App abgeschaltet; API-Ende Sept. 2026 |
| Veo 3.1 (Google) | Partiell | Nur Text + Bild | Niedriger als Omni | Live, wird durch Omni ersetzt |
| Seedance 2.0 (ByteDance) | Referenzbasiert, nicht iterativ | Begrenzt | (4/5) | Live; #1 bei Artificial Analysis Video Arena |
Die ehrliche Einschätzung: Omni ist das einzige Modell mit einer wirklich zustandsbasierten Multi-Turn-Bearbeitung. Seedance erzielt bei der reinen Charakterkonsistenz (laut Medium-Rezensent) bessere Ergebnisse, indem es bis zu 9 Referenzbilder pro Generierung nutzt – aber es kann diese Konsistenz nicht über eine gesamte Bearbeitungssitzung hinweg aufrechterhalten. Sora verschwindet vom Endkundenmarkt. Veo wird integriert.
Von "Reroll" zu "Refine" – Was dieser Workflow-Wandel ermöglicht

Der eigentliche Wert liegt nicht in der Demo, sondern in der Transformation des Workflows.
Blockchain.news fasste die kommerzielle Bedeutung am besten zusammen: "Stapel-Bearbeitung ermöglicht gleichzeitige Modifikationen über mehrere Videosegmente hinweg, um die Produktion zu beschleunigen und gleichzeitig Qualitätsstandards bei KI-generierten Inhalten zu wahren. Filmemacher, Werbetreibende und Ersteller von Bildungsinhalten profitieren erheblich durch reduzierte Kosten und verbesserte narrative Zuverlässigkeit."
Dieser letzte Begriff – narrative Zuverlässigkeit – ist der Teil, der für jeden, der mit Inhalten arbeitet, von Bedeutung sein sollte.
Bisher konnte KI-Video einen guten Clip liefern. Es konnte keine Kampagne liefern – eine Reihe von Clips mit demselben Protagonisten, denselben Markenelementen, derselben visuellen Sprache über mehrere Ergebnisse hinweg. Jede Bearbeitung war ein Glücksspiel. Jetzt bauen Bearbeitungen aufeinander auf.
TechTimes fasste die öffentlich demonstrierten Fähigkeiten zusammen als "Bearbeitung von Aktionen und Objekten in benutzerdefiniertem Filmmaterial, Stilübertragung zwischen realistischen und animierten Looks, mehrstufige Verfeinerung und Generierung von Erklärvideos."
Und DataCamps Hands-on-Test bestätigte, dass das Multi-Turn-Verhalten in der Praxis Bestand hat: "Omni unterstützt Multi-Turn-Bearbeitung, sodass Sie Details, Umgebungen und Kamerawinkel Schritt für Schritt verfeinern können, während die Szene konsistent bleibt."
Der Wandel im Workflow sieht auf dem Papier klein aus. In der Praxis ist er enorm: Generieren → Neu generieren → Neu generieren → Aufgeben wird zu Generieren → Verfeinern → Verfeinern → Veröffentlichen.
Entwickler bemerken dies. Auf dem chinesischen Entwicklerforum V2EX schrieb ein Ingenieur, der Omni am Tag der Veröffentlichung testete: "Generierungsgeschwindigkeit und Konsistenz haben meine Erwartungen übertroffen."
Wenn KI-Ingenieure und Kreative an vorderster Front innerhalb weniger Stunden nach dem Start zur gleichen Beobachtung gelangen, sieht man eine echte Verschiebung der Fähigkeiten – nicht nur Marketing.
Die ehrliche Skepsis – Omni ist noch nicht perfekt
Bevor jemand verkündet, das Konsistenzproblem sei gelöst, hier die nüchterne Betrachtung.
Ein Rezensent bei AI Analytics Diaries auf Medium testete Omni gegen Seedance 2.0 von ByteDance und gab Omnis Charakterkonsistenz eine 3 von 5.
Der Satz, den man an den Monitor jedes KI-Video-Produktmanagers heften sollte: "Beide Modelle kämpfen mit der Charakterkonsistenz über mehrere Schnitte hinweg – das bleibt die offene Wunde von KI-Video."
Übersetzung: Omni ist bei der Multi-Turn-Verfeinerung innerhalb einer einzelnen Bearbeitungssitzung materiell besser als jedes andere öffentliche Modell. Es ist jedoch noch kein vollständig gelöstes Problem für die gesamte Kategorie.
Wo liegt die verbleibende Lücke?
- Einzelne Szenen: Die Multi-Turn-Konsistenz funktioniert extrem gut (die Violinisten-Demo).
- Cross-Cut-Konsistenz (derselbe Charakter, verschiedene Szenen, verschiedene Lichtverhältnisse, verschiedene Bildausschnitte) ist noch unvollkommen.
- Subtile Merkmale – feine Gesichtsdetails, Handartikulation, spezifische Kleidungsstrukturen – können über viele Bearbeitungen hinweg immer noch abweichen.
- Das aktuelle 10-Sekunden-Clip-Limit bei Omni Flash bedeutet, dass die Multi-Turn-Konsistenz bei narrativen Langform-Inhalten noch nicht öffentlich stresstestsicher ist.
Für 80 % der Anwendungsfälle – Verfeinerung einzelner Szenen, Inhalte in Social-Media-Länge, Marketing-Assets – ist Omni bereits gut genug für die Veröffentlichung. Für die restlichen 20 % – filmreife Arbeiten, bei denen die Charakterkontinuität eine 30-teilige Sequenz überdauern muss – ist immer noch eine redaktionelle Nachbearbeitung erforderlich.
Was sich tatsächlich ändert – Branche für Branche
Wenn die Multi-Turn-Konsistenz jetzt gelöst (oder innerhalb einer Sitzung nahezu gelöst) ist, erschließen sich folgende Möglichkeiten:
Für Markenwerber: Kampagnenkontinuität. Eine Modemarke kann endlich zehn Variationen desselben Model-Helden in zehn Umgebungen generieren – ohne erneuten Dreh, ohne neues Talent zu suchen, ohne für zehn manuelle Retuschen zu zahlen. Die Kalkulation bei der kreativen Social-First-Produktion ändert sich um eine Größenordnung.
Für Pädagogen und Tutorial-Ersteller: Serienkonsistenz. Ein einzelner KI-generierter Moderator kann einen ganzen Kurs moderieren – von Episode eins bis zwölf –, ohne dass das Publikum merkt, dass er synthetisch ist. Das Problem „konsistentes Gesicht über Inhalte hinweg“ hat KI-Pädagogen zwei Jahre lang ausgebremst. Es wurde gerade behoben.
Für Filmemacher: Previsualization in großem Maßstab. Derselbe Schauspieler über mehrere Szenenvorschläge, mehrere Lichtsetups, mehrere Kamerawinkel hinweg – alles in einer Sitzung generiert und iterativ verfeinerbar. Die Lücke zwischen "Ich habe eine Idee" und "Ich kann sie dem Regisseur zeigen" verkürzt sich von Tagen auf Minuten.
Für E-Commerce-Teams: Produkt-Heldenaufnahmen, die über Listenvariationen hinweg übereinstimmen. Dasselbe Model, sechs Outfits, Lifestyle-Aufnahmen, Studioaufnahmen, Lifestyle-Fotos – alles konsistent, alles veröffentlichungsfähig, alles aus derselben Multi-Turn-Sitzung generiert.
Für Spieleentwickler: NPCs, die über Zwischensequenzen hinweg wie dieselbe Person aussehen. Die Achillesferse von In-Game-KI-Cinematics war bisher, dass der Protagonist zwischen den Szenen subtil mutierte. Omnis zustandsbasierte Bearbeitung macht die Charakterfixierung kommerziell machbar.
Die Spannung um die Herkunft – Konsistente Fakes werden schwerer zu erkennen
Es gibt eine dunklere Implikation dieses Durchbruchs, die direkt benannt werden muss.
Eine bessere Multi-Turn-Konsistenz bedeutet schwerer zu erkennende Fakes. Die klassischen "Indikatoren", dass etwas KI-generiert war – ein Gesicht, das sich über Schnitte hinweg verändert, Hände, die die Form ändern, Haarfarben, die abweichen – sind genau das, was Konsistenz behebt. Während Omni und seine Nachfolger besser in der internen Kontinuität werden, schließt sich die Lücke zwischen "offensichtlich synthetisch" und "von der Realität nicht zu unterscheiden" schnell.
Genau deshalb wird jeder Omni-generierte Clip bei der Generierung mit Googles unsichtbarem SynthID-Wasserzeichen und C2PA Content Credentials versehen. Überprüfbar innerhalb der Gemini-App, Chrome und der Suche. Nicht optional. Keine Funktion, die man deaktivieren kann.
Das ist auch der Grund, warum Google Sprach- und Audiobearbeitung in bestehenden Videos bewusst zurückgehalten hat: "Wir arbeiten noch daran, dies zu testen und besser zu verstehen, wie wir diese Funktion verantwortungsbewusst bereitstellen können." Übersetzung: Das Deepfake-Risiko eines konsistenten Gesichts in Kombination mit einer modifizierten Stimme ist zu hoch, um es ohne Sicherheitsvorkehrungen zu veröffentlichen.
Für Marken und Kreative verschiebt sich das Kalkül. Da die Erkennung von "gefälschten" Inhalten durch das menschliche Auge unzuverlässig wird, wird kryptografische Herkunft der neue Standard für Authentizität. Jeder Gewinn an Konsistenz ist mit einer Verpflichtung zur Herkunftsnachweisung verbunden.
Der neue Engpass ist nicht Qualität, sondern Modell-Wildwuchs
Strategisch bedeutet das für jeden, der Produkte auf Basis von KI-Video aufbaut, Folgendes:
Die Leistungslücke zwischen führenden Modellen schließt sich schnell – und fragmentiert gleichzeitig ebenso schnell. Stand Mitte 2026:
- Gemini Omni führt bei Multi-Turn-Konsistenz und konversationeller Bearbeitung.
- Seedance 2.0 führt bei filmischer Bewegung und stilisierter Animation mit stärkerer referenzbasierter Charakterkonsistenz.
- Andere Spezialisten führen bei Langform-Generierung, feinkörniger Charaktersteuerung, Audio-Synchronisation oder kostengünstiger Stapelverarbeitung.
Das Modell, das in diesem Quartal bei der Konsistenz am besten ist, ist wahrscheinlich nicht das Modell, das bei der filmischen Bewegung am besten ist. Das Modell mit der stärksten Physik heute ist nicht dasjenige mit der besten Audio-Synchronisation in sechs Monaten. Und jedes einzelne liefert sein eigenes SDK, Auth-Flow, Preismodell, Rate-Limit-Eigenheiten und Vertragsbedingungen mit. Ihr Team kann leicht einen Engineering-Sprint pro Integration verbrennen – und einen weiteren Sprint pro Deprecation.
Genau dieses Fragmentierungsproblem wurde von Atlas Cloud gelöst. Wir bieten Entwicklern einen einzigen, einheitlichen Endpunkt für den Zugriff auf 300+ Modelle – jedes bedeutende Basismodell, führende Open-Source-Releases und die schnelllebigen Spezialisten für Bild, Video, Audio und Reasoning. Der Zugriff auf Gemini Omni kommt in den nächsten Wochen zu Atlas Cloud, sodass die Integration bereits für Sie erledigt ist, sobald Sie bereit sind, Ihren Stack zu testen.
Was das für Ihr Team in der Praxis bedeutet:
- Modellwechsel mit nur einer Zeile Code – kein Umschreiben von SDK-Integrationen, wenn ein neues SOTA erscheint.
- Side-by-Side-Evaluierungen mit identischen Prompts – finden Sie heraus, welches Modell für Ihren spezifischen Anwendungsfall tatsächlich gewinnt, bevor Sie Budget binden.
- Das stärkste Modell für jede Fähigkeit nutzen – den heutigen Spitzenreiter bei der Multi-Turn-Konsistenz, den Spitzenreiter bei filmischer Bewegung von morgen, den Kosteneffizienz-Spitzenreiter im nächsten Quartal.
- Ein Dashboard für Abrechnung, Observability und Rate-Limits – anstatt zwölf separate Konten verwalten zu müssen.
Für Ersteller, die 2026 KI-Videoprodukte auf den Markt bringen, ist die kluge architektonische Entscheidung nicht "auf Omni wetten", sondern "auf einer Abstraktionsschicht aufbauen, die es ermöglicht, zu wechseln, sobald jemand anderes gewinnt." Wenn Gemini Omni bei Atlas Cloud landet, können Sie es gegen Seedance, gegen das nächste Durchbruchsmodell und gegen alles, was danach kommt, testen – ohne eine einzige Zeile Integrationscode zu ändern.
In einem Markt, in dem Konsistenz, Physik, filmische Bewegung und Audiotreue jeweils von einem anderen Modell angeführt werden, ist die Bindung an eines dieser Modelle die schlimmste technische Schuld, die man auf sich nehmen kann. Atlas Cloud ist die Abstraktionsschicht, die diese Fragmentierung von einer Steuer in einen Rückenwind verwandelt.
Eine einheitliche API für die professionelle Videogenerierung
Während Google Gemini Omni Flash in der Gemini-App und Google Flow für Endanwender ausrollt, benötigen Entwickler und Produktteams, die dieselbe multimodale Video-Engine in ihre eigenen Workflows einbetten möchten, eine stabile, vorhersehbare API-Schicht.
Atlas Cloud stellt Gemini Omni Flash über eine einheitliche, OpenAI-kompatible API bereit, zusammen mit über 300 anderen Bild-, Video- und LLM-Modellen. So können Sie das native multimodale Modell von Google integrieren, ohne verschiedene Anbieterkonten, Abrechnungsportale oder SDKs jonglieren zu müssen.
Beide Gemini Omni Flash-Varianten sind live auf Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Bestens geeignet für | Inputs | Auflösung | Dauer | Startpreis |
| Gemini Omni Flash Text-to-Video (Developer) | Reine prompt-gesteuerte filmische Generierung | Text (bis 20.000 Zeichen) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/Sek. |
| Gemini Omni Flash Image-to-Video (Developer) | Subjekt-konsistentes Video aus echten Referenzen | Text + bis zu 7 Referenzbilder | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/Sek. |
Quick Start — Generieren Sie ein Gemini Omni Flash-Video in 5 Zeilen:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "Ein nebliger Wald zur goldenen Stunde, filmischer Dolly-Shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
Die API gibt sofort eine Prediction-ID zurück – rufen Sie /api/v1/model/prediction/{id} ab, um die gerenderte MP4-URL zu erhalten. Das vollständige Schema, Code-Beispiele in 7 Sprachen und ein No-Code-Playground sind auf den oben verlinkten Modellseiten verfügbar.
Zentrale Erkenntnisse
Der Grund, warum Multi-Turn-Konsistenz wichtig ist, ist nicht die Demo. Es ist der Durchbruch.
Fünf Jahre lang stieß jede Diskussion darüber, "wann KI-Video kommerziell wird?", an dieselbe Mauer: der Moment, in dem Modelle einen Charakter über Schnitte hinweg konsistent halten können. Diese Mauer hat sich gerade verschoben.
Die Violinisten-Demo ist kein Stunt. Es ist das erste Mal, dass ein bedeutendes Labor einen echten, funktionierenden Multi-Turn-Bearbeitungs-Workflow auf die Bühne gebracht hat. Wenn ein Marketingteam das nächste Mal ein KI-Videotool bittet, sechs Clips desselben Produkthelden in sechs Szenarien zu produzieren, sollten sie sechs verwertbare Ergebnisse erwarten – nicht sechs unzusammenhängende Gesichter.






