Google hat auf der I/O 2026 Gemini Omni vorgestellt – ein multimodales Modell, das Videos durch einfache Konversation in natürlicher Sprache bearbeitet, ganz ohne Timelines oder Keyframes. Die viralen Demos (Skulptur aus Seifenblasen, Flüssigspiegel, Geiger) belegen den entscheidenden Wandel: Es geht nicht mehr nur um Text-zu-Video, sondern um Text-zur-Bearbeitung-von-bereits-existierendem-Video. Dies ist der „iPhone-Kamera-Moment“ für die Videoproduktion. Sprachausgabe, Audiobearbeitung und ein Pro-Tarif fehlen auffälligerweise – und das ist Absicht.
Es ist 1 Uhr morgens. Du bearbeitest seit vier Stunden einen 30-sekündigen Clip. Deine Projektdatei hat 47 Ebenen. Du hast Keyframes verschoben, bis dein Handgelenk schmerzt. Dann schreibt der Kunde: „Können wir die Beleuchtung etwas wärmer machen?“ Und du, der Profi, fängst wieder von vorn an.
Das war der Job. Das war der Job.
Am 19. Mai 2026 hat Google ihn in den Ruhestand geschickt.
Auf der I/O 2026 kündigte das Unternehmen Gemini Omni an – ein multimodales Modell, das Videobearbeitung in etwas verwandelt, von dem die meisten von uns dachten, es läge noch ein Jahrzehnt in der Zukunft: eine normale Unterhaltung.
Das Kernversprechen: Video nicht mehr bedienen. Mit ihm sprechen.
Das gesamte Konzept lässt sich in einem Satz zusammenfassen: Du bedienst Video nicht mehr – du sagst ihm, was du willst.
Googles Ankündigung bringt es auf den Punkt: „Jede Anweisung baut auf der vorherigen auf. Deine Charaktere bleiben konsistent, die Physik stimmt, und die Szene erinnert sich an das, was zuvor geschah.“
Dies ist kein Veo-Update. Die Produktseite von Google DeepMind formuliert es treffender: „Stell dir Gemini Omni wie Nano Banana vor, nur für Videos.“ Letztes Jahr machte Nano Banana die Fotobearbeitung so einfach wie das Eintippen von Wünschen. Jetzt erledigt Omni das für bewegte Bilder.
Das erste Modell der Familie – Gemini Omni Flash – ist bereits in der Gemini-App, in Google Flow und bei YouTube Shorts verfügbar.
Und hier ist der Satz, der dein Verständnis für diese gesamte Kategorie neu definieren sollte: Im Interview von TechCrunch mit dem DeepMind-Team beschrieb Research Engineer Gabe Barth-Maron das, was Leute mit Omni erstellen, als „personalisierte Memes“.
Das ist die Kernthese. Die Videoproduktion hat sich gerade vom Handwerk zur reinen Ausdrucksform gewandelt – genau wie die Fotografie, als das iPhone den Markt für DSLRs ablöste.
Die Demos, die Twitter erobern
Man kann den ganzen Tag Marketing-Texte lesen. Was diesen Launch so erfolgreich gemacht hat, sind die Demos. Drei davon sind aktuell überall zu sehen:
- Die Seifenblasen-Skulptur. Füttere Omni mit einem Clip einer Steinskulptur, tippe „Mach die Skulptur aus Seifenblasen“ – und das nächste Rendering behält die Komposition, die Beleuchtung und die Schatten bei, aber die Skulptur besteht nun aus lichtdurchlässiger Seife, die das Umgebungslicht reflektiert.
- Der Flüssigspiegel. Eine Hand berührt einen Spiegel; der Prompt weist Omni an: „Lass den Spiegel wunderschön wie Flüssigkeit wellen, und der Arm der Person verwandelt sich in reflektierendes Spiegelmaterial.“Wie Windows Report dokumentierte, breiten sich die Wellen physikalisch korrekt aus und das Chrom am Arm spiegelt den tatsächlichen Raum.
- Die verketteten Bearbeitungen. Googles Geiger-Demo zeigt ein und dasselbe Motiv in drei Runden: Bühne → neue Umgebung → Kameraansicht über die Schulter. Drei Bearbeitungen. Eine Person. Gesicht, Haltung, Griff des Instruments – alles bleibt konsistent.

Das ist kein Text-zu-Video. Es ist Text-zur-Bearbeitung-von-bereits-existierendem-Video. Der Unterschied erscheint gering. Er verändert alles.
Warum Kreative aus dem Häuschen sind
Der Grund, warum dies einschlägt wie kaum ein anderer Launch, ist simpel: Omni beendet den schlimmsten Kreislauf bei generativen Videos.
Alter Kreislauf: Generieren → hassen → den gesamten Prompt umschreiben → 90 Sekunden warten → immer noch schlecht → wiederholen.
Neuer Kreislauf: Generieren → „Ändere die Beleuchtung in die goldene Stunde“ → fertig → „Verlangsame jetzt den Kamera-Zoom“ → fertig.
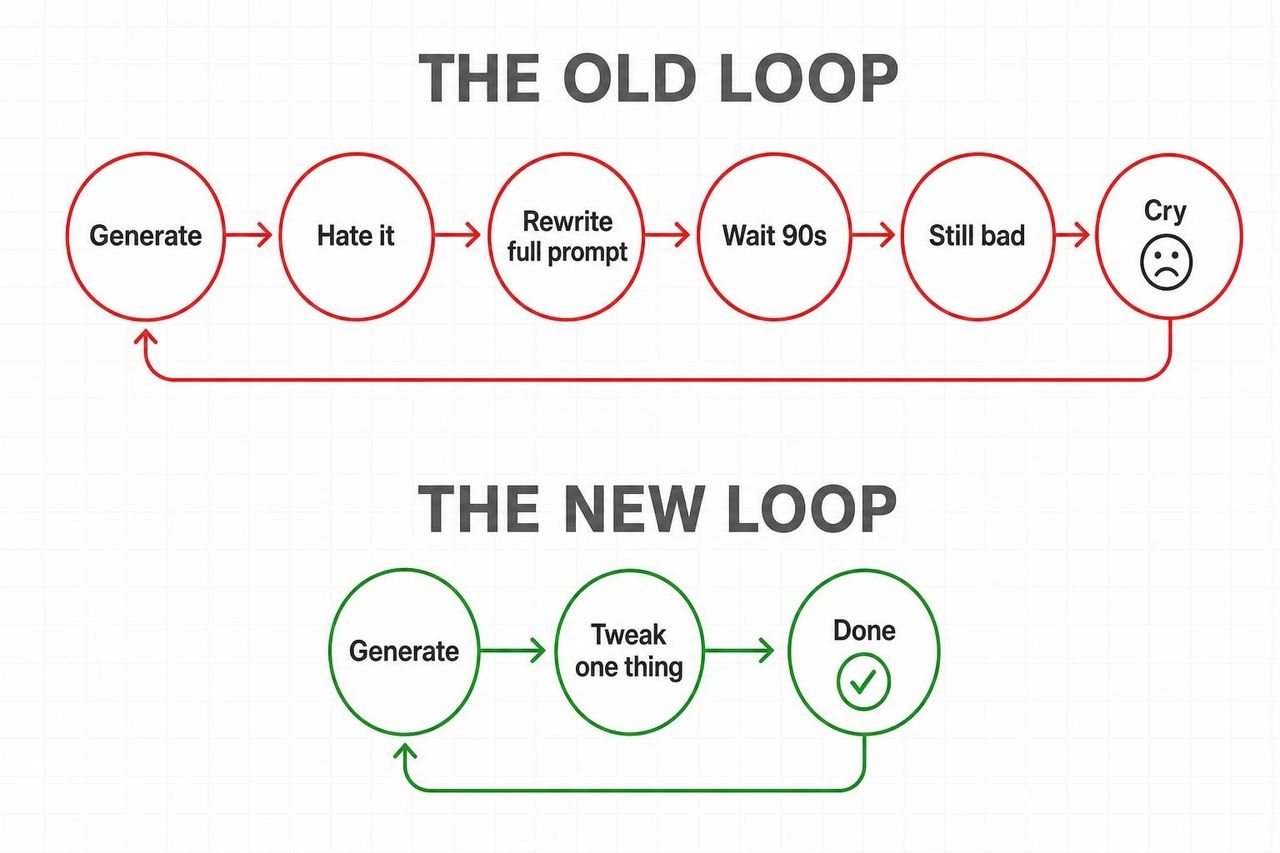
Android Central wurde deutlich: „Gemini Omni könnte traditionelle Videobearbeitungs-Apps wie Relikte aus einer anderen Zeit aussehen lassen.“ TechRadar äußerte sich differenzierter und merkte an, dass die Bewegung nun über Bearbeitungen hinweg kohärent bleibt, anstatt bei jedem Prompt neu generiert zu werden.
Entwickler sind bereits aktiv. Auf dem Entwickler-Forum V2EX testete ein chinesischer Entwickler das Tool am Launch-Tag und postete: „Chat-basierte Bearbeitung von Objekten innerhalb eines Videos – diese Art der Interaktion ist eindeutig die Richtung der Zukunft. Geschwindigkeit und Konsistenz haben meine Erwartungen übertroffen.“ Auf X twitterte der Immunologe und KI-Kommentator Dr. Derya Unutmaz kurz nach der Keynote: „Wow! Google DeepMind hat gerade ein erstaunliches neues multimodales KI-Modell namens Gemini Omni veröffentlicht. Die Videos sehen super gut aus! Muss ich unbedingt ausprobieren!“
Wenn die KI-Intelligenzszene auf Twitter und chinesische Entwicklerforen innerhalb weniger Stunden denselben Ton anschlagen, stehst du vor einem echten Wendepunkt.
Wo Google sich noch zurückhält
Es wäre unseriös, ein Loblied ohne Einschränkungen zu schreiben.

Engadget wies auf das offensichtliche Problem hin: „Das Hauptproblem bei Veo 3.1 und anderen Videogeneratoren ist der ‚Uncanny Valley‘-Effekt, der oft auf Ablehnung bei Endnutzern stößt. Es wird spannend zu sehen, ob die Ausgabequalität Googles vollmundigen Versprechen gerecht wird.“
Und die Hands-on-Tests von DataCamp deckten bereits einen echten physikalischen Bug auf – ein Trebuchet, das sein Geschoss rückwärts abfeuerte. Der Tester merkte zudem an, dass es noch keine veröffentlichten Benchmark-Ergebnisse gibt, eine unabhängige Prüfung also noch aussteht.
Es gibt zudem eine bewusste Auslassung: Sprach- und Audiobearbeitung innerhalb bestehender Videos. Wie Google selbst einräumte, arbeite man „daran, dies zu testen und besser zu verstehen, wie wir diese Funktion verantwortungsbewusst bereitstellen können.“ Übersetzung: Das Deepfake-Risiko ist real und man hält die gefährlichste Funktion noch zurück.
Jeder Omni-Clip enthält Googles unsichtbares SynthID-Wasserzeichen sowie C2PA Content Credentials – die Herkunft ist direkt in der Gemini-App, in Chrome und in der Suche verifizierbar. Das ist nicht optional. Das ist mittlerweile Pflicht.
Was das tatsächlich für deinen Workflow bedeutet
Nimmst du den Hype weg, bleibt etwas grundlegend Neues:
- Das Werkzeug ist das Gespräch. Keine Timeline, keine Ebenen, keine Keyframes. Nur Worte.
- Der Feedback-Loop verkürzt sich. Was früher 90-sekündige Re-Generierungen erforderte, wird zu 10-sekündigen Anpassungen.
- Der Vorsprung der Profis schrumpft. Wenn jeder mit Geschmack Videos so schnell bearbeiten kann, wie er Slack-Nachrichten schreibt, verlagert sich der Engpass von der Ausführung hin zur Idee.
Für Marketing-Teams, Indie-Creators, Pädagogen und jeden, der schon einmal „nur einen schnellen 10-Sekunden-Clip“ brauchte – das ist der Wendepunkt. Nicht weil das Modell perfekt ist, sondern weil das Interaktionsmuster endlich stimmt.
Zukünftige Videobearbeitung benötigt keine Software. Sie benötigt Wortschatz.
Eine einheitliche API für die Videogenerierung in der Produktion
Während Google Gemini Omni Flash in der Gemini-App und via Google Flow für Endnutzer ausrollt, benötigen Entwickler und Produktteams, die dieselbe multimodale Video-Engine in ihre eigenen Workflows einbetten möchten, eine stabile und vorhersehbare API-Schicht.
Atlas Cloud bietet Gemini Omni Flash über eine einheitliche, OpenAI-kompatible API an, neben über 300 weiteren Bild-, Video- und LLM-Modellen. So kannst du Googles multimodales Modell integrieren, ohne dich mit separaten Anbieter-Accounts, Abrechnungsportalen oder SDKs herumschlagen zu müssen.
Beide Gemini Omni Flash Varianten sind jetzt live auf Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Ideal für | Inputs | Auflösung | Dauer | Startpreis |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Developer) | Reine prompt-basierte, filmische Generierung | Text (bis 20.000 Zeichen) | 720p / 1080p / 4K | 4, 6, 8, 10 Sek. | USD0.2 + USD0.1/Sek. |
| Gemini Omni Flash Image-to-Video (Developer) | Subjekt-konsistentes Video aus echten Referenzen | Text + bis zu 7 Referenzbilder | 720p / 1080p / 4K | 4, 6, 8, 10 Sek. | USD0.2 + USD0.1/Sek. |
Schnelleinstieg – Generiere ein Gemini Omni Flash Video in 5 Zeilen:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
Die API liefert sofort eine Prediction-ID zurück – frage über /api/v1/model/prediction/{id} die URL des gerenderten MP4-Videos ab. Das vollständige Schema, Code-Beispiele in 7 Sprachen sowie ein No-Code-Playground sind auf den oben verlinkten Modell-Seiten verfügbar.
Eines noch – für alle, die damit bauen
Hier ist die unbequeme Realität hinter jedem solchen Modell-Launch: Bis zum nächsten Quartal werden drei weitere Ankündigungen über das „weltbeste Videomodell“ folgen. Jede wird ein anderes SDK, einen anderen Auth-Flow, eine andere Rate-Limit-Dynamik und ein anderes Preismodell haben. Dein Team wird eine Woche verlieren, um jedes Modell einzubinden. Und dann eine weitere Woche, um das vorherige zu entfernen.
Genau das ist das Problem, das Atlas Cloud löst.
Wir bieten Entwicklern einen einzigen Endpunkt mit Zugriff auf über 300 Modelle – jedes große Basismodell, die führenden Open-Source-Releases und spezialisierte Lösungen für Bild, Video und Reasoning. Wechsle das Modell mit einer einzigen Zeile Code. Führe Benchmarks direkt nebeneinander durch, ohne SDKs neu integrieren zu müssen. Implementiere das Modell, das heute angesagt ist, und wechsle zum nächsten, ohne irgendetwas neu schreiben zu müssen.
Denn das Einzige, was bei KI gerade sicher ist, ist, dass sich die Bestenliste jeden Dienstag ändert. Baue dafür.






