Die meisten Leute glauben immer noch, dass bessere Wörter zu besseren Bildern führen. Das stimmte vor zwei Jahren. Heute nicht mehr.
Im Jahr 2026 liegt der wahre Unterschied nicht zwischen den Modellen, sondern zwischen Nutzern, die beschreiben, und Nutzern, die konstruieren. Die einen tippen „kinoreife Beleuchtung, 4k, ultra-detailliert“. Die anderen bauen Szenen auf – mit Lichtführung, Tiefenebenen und Kamerawinkeln.
Wenn deine Bilder immer noch flach wirken, liegt das wahrscheinlich nicht am Modell. Es liegt daran, was du ihm nicht sagst.
Warum deine Prompts nicht mehr ausreichen (Perspektive 2026)
Generische Prompts funktionieren nicht mehr. Modelle haben Sätze wie „beste Qualität“ oder „hohes Detail“ millionenfach gesehen. Solche Wörter bewirken heute kaum noch etwas.
Was zählt wirklich? Strukturierte Eingaben. Woher kommt das Licht? Was ist im Vordergrund, was im Hintergrund? Welches Objektiv verwendest du? Moderne Modelle reagieren auf diese Variablen. Sie ignorieren das Füllmaterial.
Hier ist ein häufiges Muster: Jemand schreibt: „ein schönes Porträt mit weichem Licht“. Das Modell liefert etwas Flaches. Warum? Keine Lichtrichtung. Keine Tiefenstaffelung. Kein Kamerawinkel. Das Modell muss raten. Und Raten führt zu durchschnittlichen Ergebnissen.
Der Wechsel, den du vollziehen musst, ist einfach: Hör auf, das Ergebnis zu beschreiben. Fang an, die Szene zu konstruieren.
Die 7 Profi-Tipps
-
Sag dem Licht, wo es hin soll
„Weiches Licht“ ist vage. Seitenlicht, Gegenlicht, Licht von oben – das gibt dem Modell etwas Konkretes. Richtung erzeugt Schatten. Schatten erzeugen Tiefe. Tiefe lässt ein Bild realistisch wirken.
Versuche dies anstelle von „weichem Porträtlicht“:
Ein Porträt einer Frau, Seitenlicht von links, weiche Schatten auf der rechten Gesichtshälfte, dezentes Umgebungslicht im Hintergrund

Du siehst den Unterschied sofort. Das Modell weiß genau, wo das Licht sitzt.
-
Nutze echte Fotografie-Setups
Drei-Punkt-Beleuchtung. Rim-Light (Hintergrundlicht). Rembrandt-Licht. Das sind nicht nur schicke Begriffe. Es sind Muster, die das Modell während des Trainings tausende Male gesehen hat. Nutze sie, und deine Ergebnisse werden stabiler.
Beispiel:
Produktfoto eines Sneakers, Drei-Punkt-Beleuchtung, starkes Hauptlicht, weiches Fülllicht, dezentes Rim-Light zur Trennung des Produkts von einem dunklen Hintergrund

Das funktioniert jedes Mal besser als „dramatische Beleuchtung“.
-
Baue Tiefe Ebene für Ebene auf
Flache Bilder entstehen meist, weil sich alles auf der gleichen Ebene befindet. Korrigiere das, indem du Vordergrund, Mittelgrund und Hintergrund explizit benennst.
Beispiel:
Eine Kaffeetasse auf einem Holztisch (Vordergrund), eine Person, die am Laptop arbeitet (Mittelgrund), ein sanft verschwommener Café-Innenraum mit warmen Lichtern (Hintergrund)

Jetzt hat das Modell räumliche Beziehungen, mit denen es arbeiten kann.
-
Nutze Kamerasprache, keine Stil-Labels
„Cyberpunk-Stil“ ist schwammig. „35mm-Objektiv, Untersicht, Weitwinkel“ ist präzise. Kameraeinstellungen lassen sich direkt darauf übertragen, wie Bilder aufgebaut werden.
Behalte diese im Hinterkopf:
- 35mm für einen natürlichen Alltags-Look
- 85mm für Porträts mit Kompression
- Weitwinkel für Drama und Größenverhältnisse
- Untersicht, Augenhöhe, Draufsicht für die Perspektive
Beispiel:
Ein Nahaufnahme-Porträt, 85mm-Objektiv, geringe Schärfentiefe, Augenhöhe, sanfte Hintergrundunschärfe

Das gibt dem Modell viel klarere Anweisungen als „ästhetisches Porträt“.
-
Lenke die Aufmerksamkeit durch Kontrast
Überall hohe Details sind nicht das Ziel. Kontrast schon. Hell gegen Dunkel. Warm gegen Kalt. Scharfes Motiv gegen unscharfen Hintergrund.
Drei Arten von Kontrast funktionieren besonders gut:
- Lichtkontrast: helles Motiv vor dunklem Hintergrund
- Farbkontrast: warmer Spot auf einem kühl getönten Hintergrund
- Detailkontrast: scharfes Motiv, unscharfe Umgebung
Beispiel:
Ein Motiv, beleuchtet durch einen warmen Scheinwerfer vor einem dunklen, kühl getönten Hintergrund, kontrastreiche Beleuchtung, starker Fokus auf das Motiv
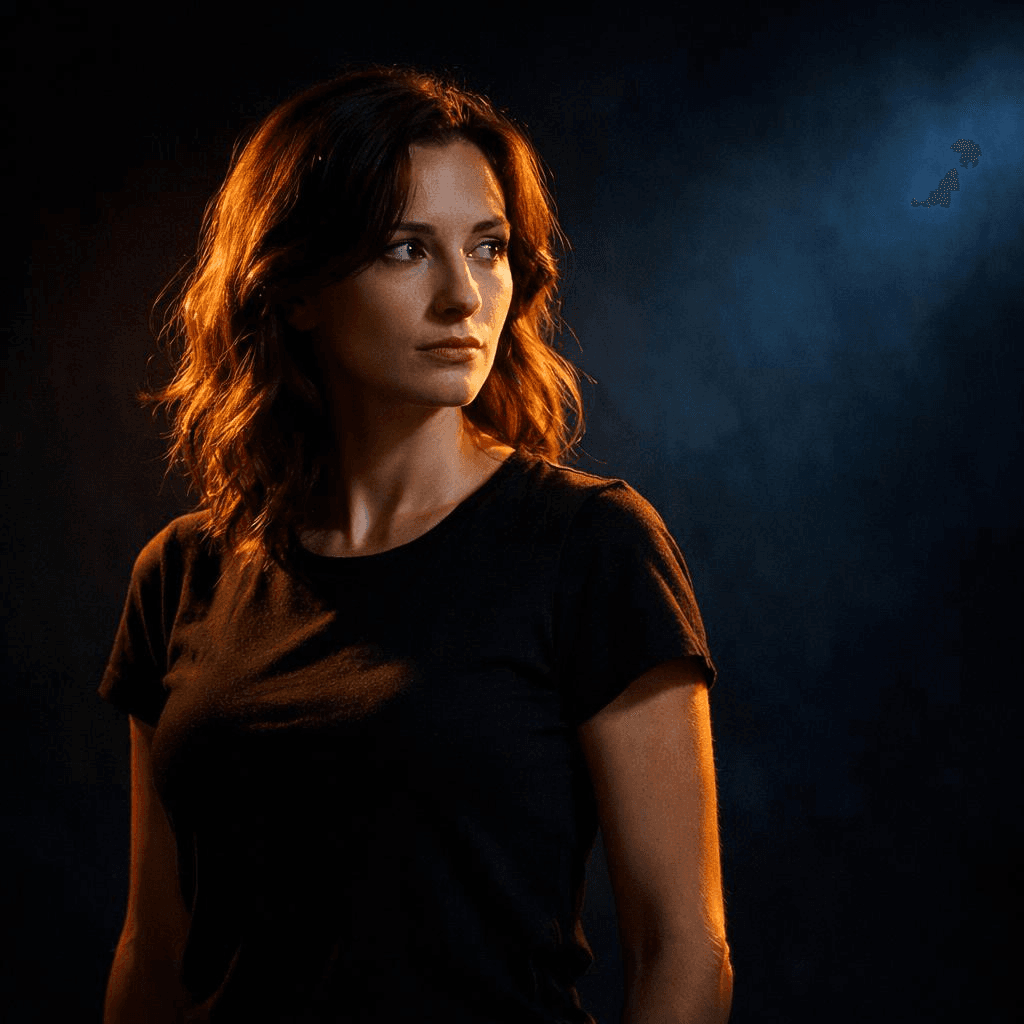
Der Blick des Betrachters wird genau dorthin gelenkt, wo du ihn haben willst.
-
Nutze Einschränkungen gegen das Chaos
Lange Prompts werden unübersichtlich. Anstatt mehr Details hinzuzufügen, setze Grenzen. Sag dem Modell, was du nicht willst. Kein Durcheinander. Keine Verzerrung. Keine zusätzlichen Objekte.
Beispiel:
Minimalistisches Produktfoto, zentrierte Komposition, sauberer weißer Hintergrund, kein Durcheinander, kein Text, keine Verzerrung

Einschränkungen bewirken oft mehr als zusätzliche Beschreibungen.
-
Iteriere wie ein Regisseur, nicht wie ein Glücksspieler
Niemand erhält beim ersten Versuch das perfekte Bild. Profis generieren, feilen nach, generieren erneut.
Ein einfacher Workflow:
- Schritt eins: Grundkomposition, Motiv und Umgebung
- Schritt zwei: Richtungsbeleuchtung und Kontrast hinzufügen
- Schritt drei: Details verfeinern, Durcheinander entfernen
Jeder Durchgang verbessert das Ergebnis. So kommst du von Zufall zu Konsistenz.
Alles zusammengefügt — Ein professionelles Prompt-Framework
Hör auf, Prompts als lange Sätze zu schreiben. Schreibe sie als modulare Systeme.
Hier ist eine Struktur, die funktioniert:
plaintext1[Motiv] + [Umgebung] + [Beleuchtung] + [Kamera] + [Komposition] + [Farbe] + [Einschränkungen]
Sieh dir den Unterschied zwischen einem einfachen und einem strukturierten Prompt an.
Beispiel: Vom einfachen Prompt zum professionellen Prompt
Einfacher Prompt (Typischer Nutzer):
Eine weibliche Person trägt ein weißes Sommerkleid, sauberer Hintergrund, Studiobeleuchtung, hohe Details, E-Commerce-Stil

Professioneller Prompt (Strukturiert):
Eine weibliche Person trägt ein weißes Sommerkleid (Motiv), steht in einem minimalistischen Studio mit einem weichen beigen strukturierten Hintergrund (Umgebung), Seitenlicht von rechts erzeugt weiche Schatten auf der linken Körperseite, dezentes Rim-Light trennt die Silhouette vom Hintergrund (Beleuchtung), fotografiert mit einem 85mm-Objektiv, Augenhöhe (Kamera), Motiv leicht außermittig mit geringer Schärfentiefe, sanfte Unschärfe im Vordergrund verleiht Tiefe (Komposition), warme natürliche Töne, weicher Kontrast (Farbe), saubere Komposition, kein Durcheinander, keine Verzerrung, keine zusätzlichen Objekte (Einschränkungen)

Fazit — Vom Prompten zum Regieführen
Ein einzelnes großartiges Bild zu bekommen ist gut. Aber echte Projekte erfordern Hunderte konsistenter, hochwertiger Visuals. Manuelles Prompten lässt sich nicht skalieren.
Du stößt auf praktische Probleme: Latenz, Kosten pro Bild, Beibehaltung des visuellen Stils über Batches hinweg. Prompt-Design allein löst das nicht. Du brauchst ein System.
Genau hier wird API-basierte Bildgenerierung essenziell. Anstatt jedes Mal Prompts in eine Oberfläche zu tippen, integrierst du die Generierung direkt in deinen Workflow. Strukturierte Prompts werden wiederverwendet, automatisiert und über die Zeit optimiert.
Plattformen wie Atlas Cloud bieten dafür eine einheitliche API-Ebene.
Und wenn du zu folgenden Gruppen gehörst:
• Entwickler, die einen einfachen, kostengünstigen KI-Zugang suchen. • Teams, die Projekte mit KI in mehreren Bereichen abwickeln. • Unternehmen, die zuverlässige KI für wichtige Aufgaben benötigen. • Leute, die Tools wie ComfyUI und n8n nutzen.
Probiere Atlas Cloud, und du wirst feststellen, dass du vom Experimentieren zur Produktion übergehst. Ohne die Infrastruktur von Grund auf neu aufbauen zu müssen.
Die Zukunft besteht nicht darin, isoliert bessere Prompts zu schreiben, sondern kontrollierbare, wiederholbare und produktionsreife visuelle Systeme aufzubauen.
FAQ
Warum wirken meine KI-Bilder immer noch flach?
Flache Bilder bedeuten meist, dass Tiefenhinweise fehlen. Überlege, wie Fotografie funktioniert. Tiefe entsteht durch Schatten, Überlappungen und Fokusunterschiede. Dein Prompt muss das explizit machen.
Nimm einen einfachen Prompt: „eine Person sitzt an einem Schreibtisch.“ Das sagt dem Modell fast nichts über Tiefe. Probiere stattdessen etwas wie: „eine Person sitzt an einem Schreibtisch (Mittelgrund), ein verschwommenes Fenster mit Stadtlichtern (Hintergrund), eine Kaffeetasse in scharfem Fokus (Vordergrund).“ Jetzt hat das Modell Ebenen, mit denen es arbeiten kann.
Beleuchtung ist ein weiterer Punkt, bei dem Fehler passieren. Viele Prompts erwähnen nur Umgebungslicht. Das sorgt für flache, gleichmäßige Ausleuchtung. Füge eine gerichtete Quelle hinzu: Seitenlicht, Gegenlicht, Rim-Light. Such dir eines aus. Das Modell wird Schatten werfen, und plötzlich hat dein Bild Volumen.
Noch etwas: Versuche nicht, jeden Winkel des Bildes mit Details zu füllen. Leerer Raum und Unschärfe sind nützlich. Sie sagen dem Betrachter, wo er hinschauen soll. Manchmal sorgt weniger Detail für mehr Tiefe.
Kann KI die Produktfotografie ersetzen?
Ja, in vielen Fällen. Aber seien wir ehrlich, wo es funktioniert und wo nicht.
Wenn du ein Hero-Shot für eine Luxusuhr brauchst — die Art, bei der jede Reflexion auf dem Metall zählt und die Textur des Lederarmbands exakt sein muss — gewinnt die traditionelle Fotografie immer noch. Dafür kann man ein echtes Studio nicht schlagen.
Für fast alles andere ist KI schneller und günstiger. Katalogbilder, Lifestyle-Szenen, saisonale Variationen, A/B-Tests für Werbemittel. Du kannst in Sekunden ein sauberes Produktfoto auf weißem Hintergrund generieren. Dann nimmst du dieses Bild und setzt es mithilfe eines KI-Generators in eine Strandszene, eine Winterhütte oder eine moderne Küche.
Keine Studio-Miete, kein Licht-Rig, keine Retusche. Jedes Bild kostet nur Cents.
Für kleine Marken und Direct-to-Consumer-Startups ändert das alles. Sie können jetzt visuelle Inhalte produzieren, die mit Unternehmen konkurrieren, die über große Budgets verfügen. Das war vor zwei Jahren noch nicht möglich.
Wie unterscheidet sich das Bildgenerierungsmodell von OpenAI von früheren Versionen?
Das neue Modell, GPT‑image‑1.5, hat einige architektonische Änderungen unter der Haube. Es verwendet einen Diffusion-Transformer. Das ist eine komplizierte Art zu sagen, dass es räumliche Beziehungen besser handhaben kann.
Ältere Versionen zerlegten komplexe Szenen oft in Stücke, die nicht ganz zusammenpassten. Eine Hand schwebte manchmal neben einer Tasse, anstatt sie zu halten. Schatten zeigten in die falsche Richtung. Die neue Version hält die Dinge verbunden. Eine Hand hält die Tasse, der Schatten fällt dort, wo er hingehört.
Die Textdarstellung ist ein weiterer großer Sprung. Frühere Modelle produzierten wirre Zeichen, die wie zufällige Symbole aussahen. GPT‑image‑1.5 generiert lesbare Wörter in mehreren Sprachen. Du kannst Englisch und Chinesisch im selben Bild mischen. Das funktioniert jetzt tatsächlich.
Das Modell unterstützt nativ auch höhere Auflösungen – bis zu 2K ohne Upscaling. Weniger Artefakte, schärfere Details.
Es gibt einen Nachteil: Das Modell ist weniger nachsichtig bei vagen Prompts. Du kannst nicht einfach „ein schönes Porträt“ sagen und Wunder erwarten. Du musst sorgfältiger sein. Aber wenn du strukturierte Anweisungen gibst – Lichtrichtung, Tiefenebenen, Kameraeinstellungen –, ist die Ausgabequalität besser als alles, was frühere Generationen geliefert haben.






