APIs zur KI-Videogenerierung gelten als launisch – und das aus gutem Grund. Text-Completions schlagen bei Fehlern sofort mit einem 400-Fehler fehl. Das Videorendering verhält sich anders und ist unvorhersehbarer. Ein Job kann ohne Vorwarnung ewig in einer GPU-Warteschlange hängen. Er liefert möglicherweise nur die Hälfte der angeforderten Clips. Manchmal wird das Rendering perfekt abgeschlossen, aber das endgültige Video sieht physisch unmöglich oder verzerrt aus.
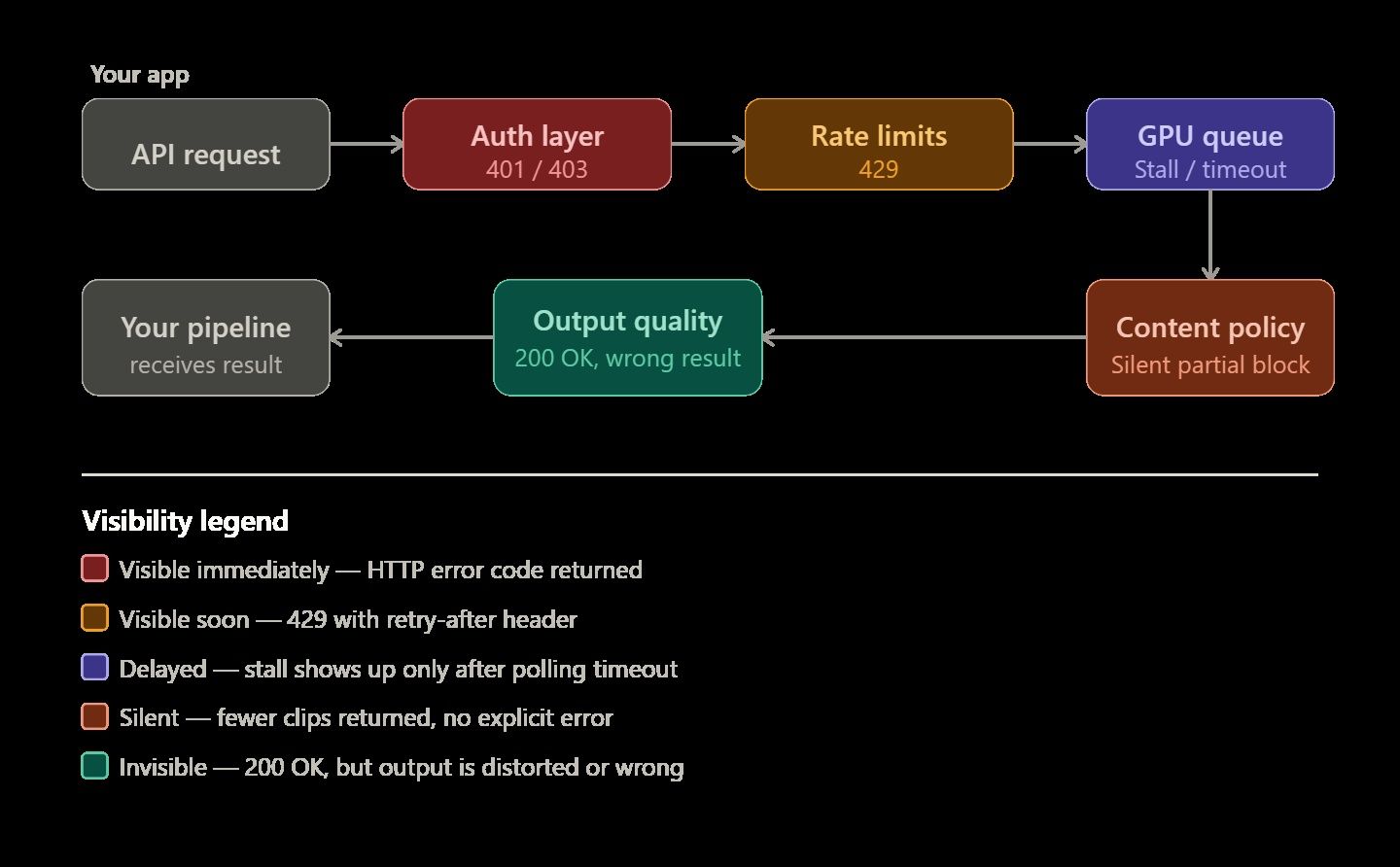
Um ein zuverlässiges System aufzubauen, müssen Sie verstehen, warum diese spezifischen Fehler auftreten. Dieses Wissen ist der Hauptunterschied zwischen einer einfachen Demo und einer Videopipeline, die für echte Nutzer tatsächlich funktioniert.
Dieser Leitfaden führt Sie durch die häufigsten Fehlermodi, zeigt Ihnen, wie Sie API-Antworten präzise lesen, und präsentiert konkrete Strategien für den Aufbau einer Videorendering-Pipeline, die kostengünstiger ist und seltener ausfällt. Die Codebeispiele verwenden die Atlas Cloud API, eine einheitliche Inferenzplattform, die Zugriff auf über 300 Video- und multimodale Modelle über einen einzigen Endpunkt bietet – was sie zu einer nützlichen Referenz für Multi-Modell-Muster macht.
Die fünf Kategorien von KI-Video-API-Fehlern
Fehler in KI-Videopipelines lassen sich meist in fünf Gruppen einteilen. Wenn Sie die richtige Kategorie kennen, können Sie Probleme schneller lösen – sei es durch Code-Anpassungen, das Umschreiben von Prompts oder einfaches Abwarten.
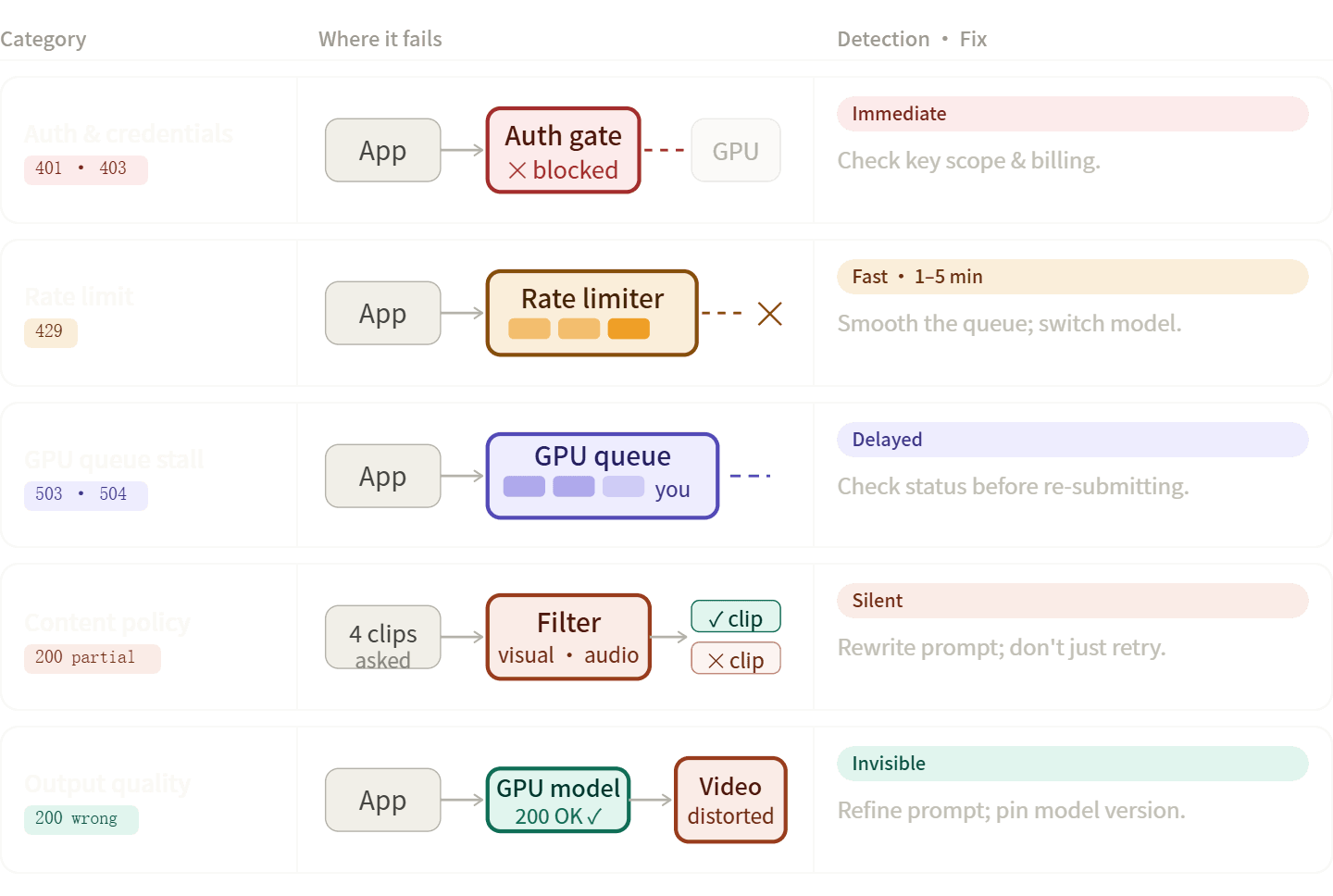
Authentifizierungs- und Berechtigungsfehler (401, 403)
| Code | Typische Ursache | Lösung |
| 401 Unauthorized | Fehlender oder fehlerhafter Authorization: Bearer <key>-Header | Sicherstellen, dass der Key aus Umgebungsvariablen geladen wird, nicht hardcodiert |
| 403 Forbidden (Quote) | API-Credits aufgebraucht | Guthaben aufladen oder Plan upgraden |
| 403 Forbidden (Berechtigung) | Key hat nicht den richtigen Scope für das Modell | Key mit korrekten Berechtigungen neu generieren |
Hier kommt es oft zu Verwirrung. Ein 403-Fehler wegen überschrittener Quote und ein 403-Fehler wegen fehlender Berechtigungen nutzen denselben Code, erfordern aber unterschiedliche Lösungen. Schauen Sie nicht nur auf die Statusnummer. Lesen Sie immer die vollständige Fehlermeldung im Body, um zu sehen, was schiefgelaufen ist.
Auf Plattformen wie Atlas Cloud deckt ein einziger API-Key alle Modelle ab – das bedeutet, dass "Auth Drift" (wenn Keys für Anbieter A funktionieren, aber bei Anbieter B abgelaufen sind) nicht vorkommt.
Rate-Limit-Fehler (429)
Rate Limits sind bei Video-APIs schmerzhafter als bei Text-APIs, da jede Anfrage einen GPU-Slot für 30–90 Sekunden belegt. Eine Handvoll gleichzeitiger Anfragen kann ein Limit ausreizen, das auf dem Papier großzügig aussieht.
Wichtige Unterscheidungen, die Sie zuerst prüfen sollten:
- RPM: Produktionsmodelle der Veo 3.1 API erlauben 50 RPM; Preview-Modelle sind auf 10 RPM mit maximal 10 gleichzeitigen Anfragen pro Projekt begrenzt.
- Limit für gleichzeitige Anfragen: Selbst innerhalb Ihres RPM-Budgets führt das Erreichen des Concurrency-Limits zu einem 429-Fehler.
- TPM (Tokens per Minute): Für Video weniger verbreitet, aber relevant auf Plattformen mit einheitlicher Abrechnung über Modalitäten hinweg.
Was wirklich hilft:
| Ansatz | Wann er funktioniert | Wann nicht |
|---|---|---|
| Exponential Back-off + Retry | 429-Fehler durch kurzzeitige Spitzen | Wenn das Concurrency-Limit das eigentliche Hindernis ist |
| Burst Smoothing / Request Queuing | Hochvolumige Batch-Pipelines | Interaktive, latenzempfindliche UX |
| Off-Peak-Scheduling (nächtliche Batches) | Content-Pre-Generation-Workflows | Echtzeit-Generierung |
| Modell-Routing zu einer weniger ausgelasteten Variante | Einheitliche Plattformen mit mehreren äquivalenten Modellen | Single-Provider-Setups |
Content Policy und Safety-Filter-Ablehnungen
Diese sind schwer zu diagnostizieren, da die API-Antwort nicht immer ein klarer Fehler sein muss – es können auch einfach weniger Clips geliefert werden, als angefordert wurden. Die Dokumentation zu Veo weist explizit darauf hin, dass bei der Rückgabe weniger Videos als angefordert einige Ausgaben von Sicherheitsfiltern blockiert worden sein könnten, anstatt dass die gesamte Anfrage auf Transportebene fehlgeschlagen ist.
Zwei unterschiedliche Auslöser:
- Visuelle Prompts: Inhalt, Szenenkontext oder implizierte Gewalt/explizite Inhalte.
- Audio-/Dialog-Prompts: Sprachinhalte, Songanfragen und komplexe Soundscapes lösen eigene Filter-Stacks aus.
Wenn Ihr Clip nur fehlschlägt, wenn Audio Teil des Prompts ist, debuggen Sie Audio getrennt von der visuellen Szene. Ein erneut versuchter, durch Richtlinien blockierter Prompt wird selten erfolgreich sein – der Prompt muss geändert werden.
Transport- und Infrastrukturfehler (500, 503, 504)
| Code | Typische Lösungszeit | Was zu tun ist |
|---|---|---|
| 429 RESOURCE_EXHAUSTED | 1–5 Minuten | Back-off und Retry |
| 503 Service Unavailable | 30–120 Minuten | Warten; Status-Dashboard prüfen |
| 504 Gateway Timeout | Variabel | Prüfen, ob das Rendering noch läuft, bevor erneut gesendet wird |
| 500 Internal Server Error | Hängt ab | Prediction-ID protokollieren; nicht ohne Statusprüfung auto-retryen |
Die goldene Regel bei 500/504-Fehlern: Prüfen Sie, ob das Rendering noch läuft, bevor Sie erneut senden. Blindes Retry bei einem 504 kann zu doppeltem Rendering und doppelten Kosten führen.
Fehler in der Ausgabequalität
Dies sind keine HTTP-Fehler – die API gibt 200 zurück, aber die Ausgabe ist falsch. Häufige Formen:
- Visuelle Artefakte oder geometrische Ungenauigkeiten: KI-Video ist probabilistisch. Das Modell interpretiert Eingaben, anstatt sie physikalisch zu berechnen.
- Fehlendes Audio bei Modellen, die es unterstützen: Normalerweise ein Problem mit dem Prompt oder den Parametern, kein Infrastrukturfehler.
- Falsche Dauer oder Auflösung: Ausgelöst durch nicht unterstützte Kombinationen – nicht alle Modelle unterstützen alle Dauer-/Auflösungspaare.
- Stille Pipeline-Abbrüche: Manche Encoding-Pipelines verwerfen Videos in bestimmten Formaten stillschweigend; dies fällt erst bei der Qualitätssicherung auf.
Asynchrone Antworten lesen: Prediction-IDs und Status-Polling
KI-Videogenerierung ist konzeptionell asynchron. Der Request-Response-Zyklus hat zwei Phasen:
- POST an den Generierungs-Endpunkt → Empfang einer
prediction_id - GET an den Ergebnis-Endpunkt mit dieser ID → Polling bis zum terminalen Status
Das Response-Schema von Atlas Cloud verdeutlicht, wie eine abgeschlossene Prediction aussieht:
plaintext1{ 2 "id": "pred_abc123", 3 "status": "completed", 4 "model": "bytedance/seedance-2.0/text-to-video", 5 "outputs": ["https://storage.atlascloud.ai/outputs/result.mp4"], 6 "metrics": { "predict_time": 45.2 }, 7 "created_at": "2025-01-01T00:00:00Z", 8 "completed_at": "2025-01-01T00:00:45Z" 9}
Die drei terminalen Zustände:
| Status | Bedeutung | Aktion |
|---|---|---|
| completed | Rendering erfolgreich; Ausgaben verfügbar | Innerhalb des Ablaufzeitfensters herunterladen |
| failed | Rendering fehlgeschlagen; Fehlerfeld prüfen | Fehlermeldung loggen; über Retry entscheiden |
| expired | Ausgaben nicht mehr verfügbar | Falls noch benötigt, neu senden |
Der häufigste Polling-Fehler
Entwickler prüfen routinemäßig auf status === "failed", lesen aber nie das darauf folgende Fehlerfeld. Genau dort befinden sich jedoch die handlungsrelevanten Informationen – ohne diese wissen Sie zwar, dass ein Rendering fehlgeschlagen ist, aber nicht, ob Sie den Prompt anpassen, Ihre Quote prüfen oder eine Infrastrukturstörung abwarten müssen.
Produktionsreifes Polling-Muster
plaintext1import time 2import requests 3 4def poll_prediction(prediction_id: str, api_key: str, max_wait: int = 600) -> dict: 5 url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 6 headers = {"Authorization": f"Bearer {api_key}"} 7 terminal_states = {"completed", "failed", "expired"} 8 wait = 5 9 10 for _ in range(max_wait // wait): 11 resp = requests.get(url, headers=headers).json() 12 status = resp.get("status") 13 14 if status in terminal_states: 15 if status == "failed": 16 print(f"Render failed: {resp.get('error')}") 17 return resp 18 19 time.sleep(wait) 20 wait = min(wait * 1.5, 60) # Back-off auf 60s begrenzen 21 22 raise TimeoutError(f"Prediction {prediction_id} did not complete within {max_wait}s")
Loggen Sie metrics.predict_time bei jedem abgeschlossenen Rendering. Anstiege bei diesem Wert sind ein Frühindikator für eine Verschlechterung der Infrastruktur – ein nützliches Signal, bevor Sie echte Ausfälle sehen.
Strukturierung einer resilienten Rendering-Pipeline
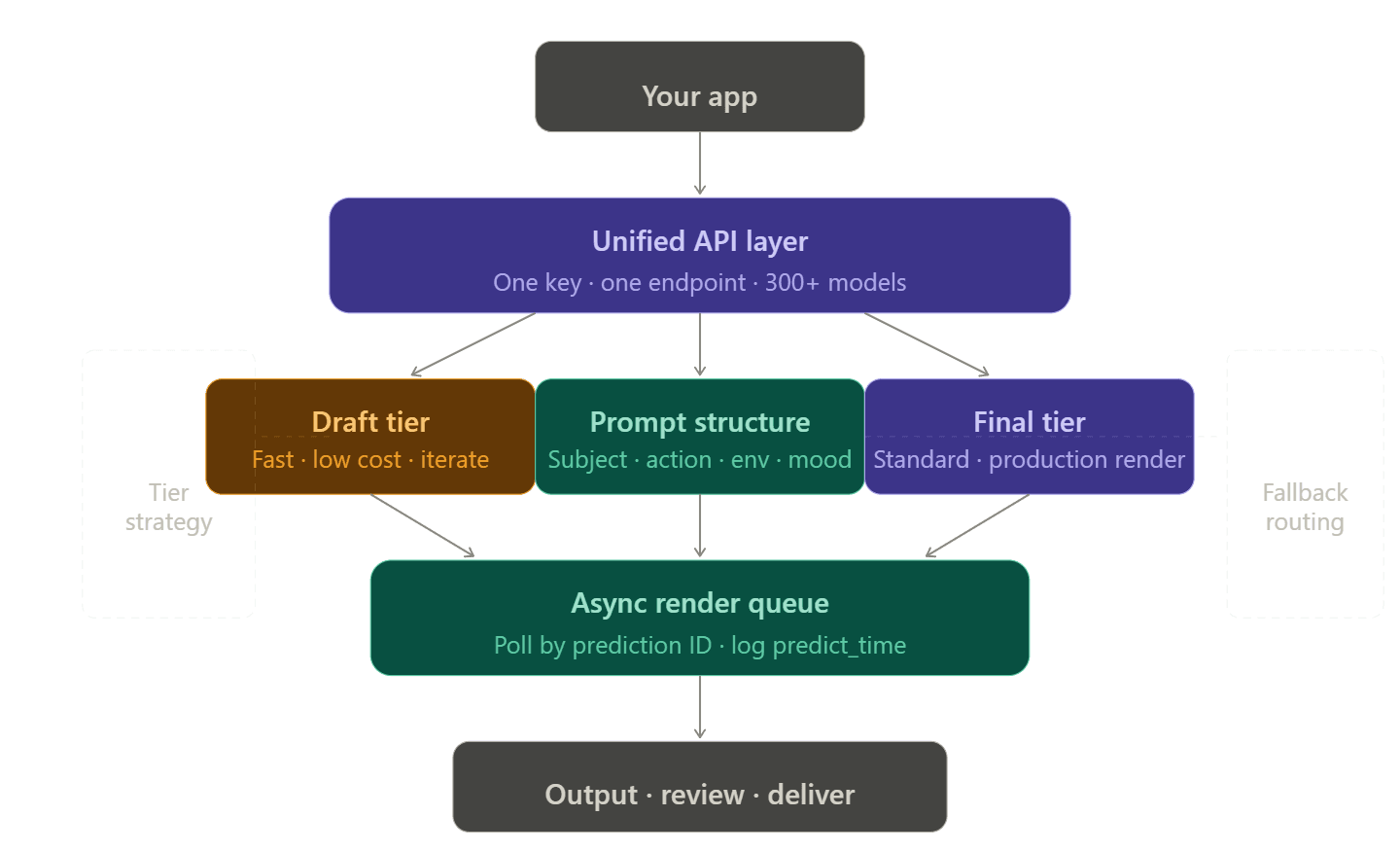
Single-Vendor vs. Unified API-Architektur
Mehrere Konten, Tokens und Abrechnungsseiten für jeden Videoanbieter zu verwalten, ist mühsam. Entwickler nennen das oft "Integrationssteuer". Es wird schnell schlimmer: Wenn ein Modell ein Limit erreicht, brauchen Sie ein Backup. Dieses Backup benötigt dann seinen eigenen API-Key, eine eigene Abrechnung und individuellen Code für die Fehlerbehandlung.
Unified-API-Plattformen eliminieren dies, indem sie mehrere Anbieter über einen einzigen Endpunkt leiten. Auf Atlas Cloud erfordert der Wechsel von openai/sora-2/text-to-video zu bytedance/seedance-2.0/text-to-video nur die Änderung eines Strings – Header, Authentifizierung und Abrechnung bleiben identisch.
Tiering von Entwurf bis Finale
Eine der effektivsten Maßnahmen für Kosten und Zuverlässigkeit ist es, für die jeweilige Workflow-Stufe das richtige Modell-Tier zu wählen:
| Stufe | Empfohlenes Tier | Warum |
|---|---|---|
| Prompt-Exploration / Konzept-Tests | Fast / Budget | >78% Kostenersparnis gegenüber Standard; Fehler sind günstiger |
| Interne Review-Entwürfe | Fast-Tier | Reicht für Stakeholder-Review aus |
| Finale Produktionsrenderings | Standard / Pro-Tier | Qualitätsunterschied rechtfertigt Kosten |
| Batch-Content (Social Media, Marketing) | Fast-Tier | Volumen macht den Kostenunterschied signifikant |
Auf Atlas Cloud kostet das Seedance 2.0 Fast-Tier $0.081/Sek. gegenüber $0.10/Sek. für Standard – ein Unterschied, der sich in der Skalierung summiert. Ein Team, das monatlich 200 Zehn-Sekunden-Clips generiert, würde $162 für das Fast-Tier gegenüber $200 für Standard ausgeben.
Prompt Engineering als Fehlerprävention
Vage Prompts sind eine unterschätzte Ursache für Pipeline-Fehler. Ein Prompt wie "eine Person geht" zwingt das Modell zu zu vielen willkürlichen Entscheidungen, was zu inkonsistenten Ergebnissen führt, die mehr Retries erfordern.
Eine zuverlässige Prompt-Struktur aus 4 Komponenten:
plaintext1[Subjekt + Details] + [Aktion + Bewegungsstil] + [Umgebung + Licht] + [Kamera + Stimmung] 2 3Beispiel: 4"Eine Frau im roten Mantel geht zügig durch eine regenbenetzte Straße in Tokio bei Nacht, 5Neonreflexionen auf nassem Asphalt, Medium Tracking Shot, filmisch und angespannt"
Bei Modellen, die multimodale Eingaben unterstützen – Seedance 2.0 akzeptiert bis zu 12 Referenzdateien (Bilder, Videoclips und Audio) – reduziert die Bereitstellung visueller Referenzen die Mehrdeutigkeit, die zu Qualitätsfehlern führt.
Das richtige Modell wählen
Nicht jedes KI-Videotool scheitert aus demselben Grund, da sie für unterschiedliche Ziele gebaut sind. Das falsche Modell für die spezifische Aufgabe zu nutzen, ist ein großer Fehler. Das führt zu schlechten Ergebnissen, die wie technische Bugs aussehen, aber meist ist das Modell einfach nicht für diese Aufgabe gemacht.
Referenz der Modellfähigkeiten
| Modell | Stärke | Worauf achten? | Preise (Atlas Cloud) |
|---|---|---|---|
| Wan 2.7 | Physikalische Simulation, realistische Objektinteraktion | Nur Einzelbild-Referenz; höhere Kosten | $0.1/Sek. |
| Kling 3.0 | Hochauflösende Ausgabe; natives Lip-Sync; Free-Tier (66 Credits täglich) | Längere Generierungszeiten bei max. Auflösung | $0.071–0.143/Sek. |
| Veo 3.1 | Filmische Qualität; starke Sicherheitskonformität | Preview-Modell Rate Limits (10 RPM) | $0.05–0.20/Sek. |
| Seedance 2.0 | Multi-Referenz-Eingabekontrolle; natives Audio | Erfordert sorgfältigere Prompt-Struktur | $0.081–0.10/Sek. |
| Wan 2.6 | Niedrigste Kosten; High-Volume-Content | Kein natives Audio; max. 1080p | $0.018–0.07/Sek. |
Preise basierend auf der Dokumentation von Atlas Cloud, April 2026. Für spezifische Preise konsultieren Sie bitte die offizielle Website.
Wann das Modell wechseln vs. den Request fixen
Modell wechseln, wenn:
- Clips konsistent nur bei Audio- oder Dialog-Prompts fehlschlagen (evtl. mangelnde Audio-Fähigkeit des Modells)
- Physik oder Objektinteraktionsqualität das Problem ist, nicht der Prompt
- Sie ein Preview-Modell nutzen und Rate-Limits erreichen, die ein Produktionsmodell nicht hätte
Prompt fixen, wenn:
- Die Ausgabe stilistisch abweicht, aber strukturell korrekt ist
- Sicherheitsfilter bei spezifischer Sprache auslösen
- Dauer- oder Auflösungsparameter abgelehnt werden
Pinnen Sie einen spezifischen Versions-String (z. B. kling-v3.0-std, nicht kling-latest). Stille Modell-Updates können Qualitätsregressionen einführen, die ohne Version-Pinning fast unmöglich zu debuggen sind.
Ihr Debugging-Toolkit
Was in jeder Stufe geloggt werden sollte
Logging ist der schnellste Weg, die Debugging-Zeit zu halbieren. Ein minimal effektives Log erfasst:
Bei Anfrage:
- Modell-ID und Version
- Prompt-Hash, nicht den vollen Prompt (hält Logs kompakt)
- Dauer-, Auflösungs- und Modus-Parameter
- Zeitstempel
Bei Antwort:
- Prediction-ID
- Initialer Status
- Sofortige Fehlermeldung
Bei Polling-Abschluss:
- Finaler Status
predict_timeaus den Metriken- Inhalt des Fehlerfelds (falls fehlgeschlagen)
- Output-URL (falls abgeschlossen)
Infrastruktur- vs. Anwendungsfehler lesen
Wenn eine Generierung fehlschlägt, spart eine schnelle Abfolge Zeit:
- API-Status-Dashboard zuerst prüfen – wenn die Plattform beeinträchtigt ist, debuggen Sie das Falsche.
x-deny-reasonResponse-Header lesen – Egress-Proxy-Ablehnungen tauchen hier auf und sehen ohne diesen Header wie Modellfehler aus.- Auf CORS-Fehler prüfen, falls Sie vom Frontend aufrufen – diese verursachen in den Browser-DevTools das gleiche Symptom wie Auth-Fehler.
- Dateibeschränkungen verifizieren, bevor Sie einen Modellfehler annehmen – die meisten Plattformen setzen ein max. Eingabedateigröße (oft 16 MB) und eine begrenzte Auswahl an Formaten voraus.
Das Monitoring-Panel von Atlas Cloud zeigt den Auto-Scaling-Status und nutzungsbezogene Daten pro Request an, was hilft, einen langsamen Infrastruktur-Tag von einem Prompt- oder Code-Problem zu unterscheiden.
Kostenoptimierung
Die drei Hebel
Rendering-Kosten sind ein Produkt aus drei Variablen. Alle drei gleichzeitig zu optimieren, anstatt nur ein billigeres Modell zu wählen, bringt die größten Ersparnisse:
| Hebel | Kostengünstige Wahl | Kostspielige Wahl | Typischer Multiplikator |
|---|---|---|---|
| Modell-Tier | Fast | Standard/Pro | 3–5× |
| Dauer | 4–5 Sekunden | 12–15 Sekunden | 3× |
| Auflösung | 720p | 4K | 2–4× |
Ein einzelnes 8-sekündiges 4K-Standard-Rendering kann 6–8× mehr kosten als ein äquivalentes 720p-Fast-Rendering bei gleicher Dauer. Wenn Ihr Distributionskanal Social Media oder Web ist, ist 720p oder 1080p für Endnutzer meist ununterscheidbar.
Nutzungsbasierte vs. Abo-Abrechnung
Consumer-KI-Pläne (z. B. Google AI Pro für $19.99/Monat) bieten begrenzte Videogenerierung über das Interface, beinhalten aber keinen API-Zugriff. Dies ist ein häufiger Planungsfehler für Teams, die von Consumer-Tools zu Produktions-Pipelines wechseln.
Atlas Cloud nutzt nutzungsbasierte Abrechnung, damit Ihre Kosten mit Ihrem tatsächlichen Aufbau übereinstimmen. Dies funktioniert am besten, wenn sich Ihr Projektbedarf wöchentlich ändert. Sie sollten die Kosten pro Sekunde des fertigen Videos tracken. Dies ist der beste Weg, um verschiedene Modelle und Preistiers fair zu vergleichen.
Wiederverwendung von Referenz-Assets
Wenn Sie viele Clips generieren, die dieselben Charaktere, Szenen oder Stilreferenzen enthalten, registrieren Sie diese Assets vorab:
- Referenzbilder oder -videos einmal hochladen; die zurückgegebene Asset-ID speichern
- In nachfolgenden Anfragen
asset://<ark_asset_id>übergeben, statt erneut hochzuladen - Datei-Uploads werden auf den meisten Plattformen nicht berechnet – nur die generierte Ausgabedauer wird in Rechnung gestellt.
Checkliste für die Produktionsreife
Bevor Sie eine Videogenerierungspipeline in die Produktion geben, prüfen Sie Folgendes:
Authentifizierung
- API-Key aus Umgebungsvariablen geladen, nicht hardcodiert
- Key hat korrekte Scopes für alle verwendeten Modelle
- Rotationsrichtlinie aktiv
Rate-Limits und Concurrency
- RPM und Limits für gleichzeitige Anfragen für jedes Modell-Tier bestätigt
- Burst-Smoothing oder Queue für Batch-Workflows eingerichtet
- Fallback-Modell für Rate-Limit-Szenarien konfiguriert
Fehlerbehandlung
- Terminale Zustände (completed, failed, expired) alle behandelt
- Fehlerfeld bei jedem fehlgeschlagenen Status erfasst und geloggt
- Subprocess/Request-Timeout auf ≥ 10 Minuten für lange Renderings gesetzt
- Kein blindes Auto-Retry bei 500/504 ohne vorherige Statusprüfung
Inhalte und Prompts
- Prompts vorab anhand von Content-Richtlinien geprüft
- Audio- und visuelle Trigger im Test isoliert
- 4-Komponenten-Prompt-Struktur als Team-Standard übernommen
Modellkonfiguration
- Spezifischer Versions-String gepinnt (nicht "latest")
- Modell-Tier auf die Workflow-Stufe abgestimmt (Fast für Entwürfe, Standard für Finale)
- Alle erforderlichen Parameter für das gewählte Modell bestätigt (Dauer, Auflösung, Audio)
Kostenkontrolle
- Nutzungsbasiertes Billing-Dashboard mit Alerts konfiguriert
- Fast-Tier als Standard für alle Nicht-Final-Renderings
- Referenz-Asset-IDs für wiederkehrende Assets verwendet
Observability
- Prediction-ID, Status und
predict_timebei jedem Rendering geloggt - API-Status-Dashboard als Lesezeichen gespeichert und vor tiefem Debugging geprüft
- Alerts für
predict_time-Spitzen konfiguriert
Eine Videopipeline, die mit Fehlern umgehen kann, ist nicht wesentlich schwerer zu bauen als eine, die ständig bricht. Sie müssen nur klug mit Fehlern in jedem Schritt umgehen. Stellen Sie sicher, dass Ihr Logging solide ist und bleiben Sie bei spezifischen Modellversionen. Bevor Sie sich um alles andere kümmern, etablieren Sie eine Pipeline, die von schnellen Entwürfen zu finalen Renderings führt. Der Rest ergibt sich von selbst.
FAQ
Was verursacht die "429 Resource Exhausted"-Fehler im Premium-Plan?
Ein 429-Fehler bedeutet lediglich, dass Sie Ihre Rate Limits erreicht haben. Um einen reibungslosen Betrieb zu gewährleisten, begrenzen Anbieter Ihre Anfragen und Tokens.
- Die Lösung: Implementieren Sie Exponential Backoff in Ihrem Code. Dies hilft dem System, automatisch zu warten und es erneut zu versuchen. Prüfen Sie zudem Ihr "Usage Tier" im Dashboard. Sie müssen ggf. mehr ausgeben, um höhere Geschwindigkeiten freizuschalten.
Wie lassen sich False Positives bei der Content-Moderation vermeiden?
Sicherheitsfilter missverstehen technische Prompts oft als Richtlinienverstoß.
- Die Lösung: Passen Sie Ihren Prompt an, indem Sie vage Wörter durch technische Begriffe ersetzen. Sagen Sie nicht "chaotische Energie", wenn Sie "schnelle Kamerabewegung" meinen. Sie können auch ein LLM nutzen, um Ihre Prompts zu bereinigen und sie in klare Beschreibungen zu verwandeln, die die Maschine versteht.
Wie lässt sich die Latenz meiner Rendering-Pipeline verringern?
Latenz entsteht meist durch ineffizientes Polling oder große Modellgrößen. Verwenden Sie Webhooks statt manuellem Polling, um Daten bei Abschluss zu erhalten. Bei Self-Hosting hilft FP8-Quantisierung, um die Inferenz zu beschleunigen. API-Nutzer sollten auf Asynchrone Verarbeitung setzen, um mehrere Generierungen parallel statt sequenziell abzuwickeln.






