
Heutige KI-Avatare können echte Echtzeit-Konversationen führen und lassen sich sogar mitten im Satz unterbrechen – und mit einem Open-Source-Projekt kannst du einen solchen Avatar selbst hosten und alle Daten lokal behalten. Dieser Beitrag zeigt auf, wie ein produktionsreifer Echtzeit-Digital-Human mit OpenTalking erstellt wird und wo du im Vergleich zu minutengenauen Diensten wie HeyGen Kosten sparst.
Hier ist der Moment, der meine Aufmerksamkeit erregte: Ein Avatar auf meinem Bildschirm sprach, ich fiel ihm mitten im Satz ins Wort, und er hielt inne, um zuzuhören – um dann genau da anzuknüpfen, wo ich aufgehört hatte. Kein vorgerenderter Clip, der einfach durchläuft. Ein echter Dialog. Untertitel liefen synchron mit, die Latenz war so gering, dass es sich nicht wie eine KI anfühlte.
Und der erste Schritt beim Aufbau hat mich nichts gekostet und erforderte nicht einmal eine GPU.
Warum betone ich das? Weil die meisten Leute bei „Digital Human“ immer noch an die steifen, Skripte vorlesenden PowerPoint-Puppen von vor zwei Jahren denken – eingefrorene Mimik, Einweg-Wiedergabe, taub für alles, was man sagt. Die eigentliche Frage ist also nicht: „Kann ein digitaler Mensch Geld verdienen?“, sondern:
Wie weit sind KI-Avatare im Jahr 2026 tatsächlich?
Weit genug, dass sie sich von einem „Video, das sich bewegt“ zu „etwas, das antwortet“ entwickelt haben. Nach der Echtzeit-Demo von GPT-4o hat sich der Standard verschoben auf: Echtzeit, unterbrechbar, kann Rückfragen stellen. Dieses Jahr hat die Open-Source-Szene eine Welle solcher Projekte hervorgebracht – SoulX-LiveAct, Alibabas Mnn3dAvatar, duix.ai, LiveTalking. Das Projekt, das ich hier untersuche, verknüpft die gesamte Pipeline auf ungewöhnlich saubere Weise: OpenTalking.
Kein unnötiges Drumherum – gehen wir drei Punkte durch: Was es kann, was es wert ist und wie man es als Nicht-Entwickler aufbaut.
1. Was es kann: Ein Avatar, der tatsächlich antwortet
OpenTalking ist ein Open-Source-Framework zur Orchestrierung von Echtzeit-Konversationen mit digitalen Menschen. Einfach ausgedrückt: Es verkettet die gesamte Schleife – Benutzer spricht → Speech-to-Text (STT) → ein LLM überlegt sich eine Antwort → Text-to-Speech (TTS) → der Avatar spricht und streamt via WebRTC in deinen Browser – zu einer einzigen Echtzeit-Pipeline.
Was es tatsächlich leisten kann:
- Echtzeit-Konversation – er antwortet dir live, kein vorab aufgezeichnetes Video.
- Unterbrechbarkeit – sprich dazwischen und er hält inne, um zuzuhören (das ist der Teil, der sich menschlich anfühlt).
- Untertitel-Events – Untertitel werden passend zum Sprechen eingeblendet.
- Klonen – Audio-/textgesteuerte Generierung, damit du deinen eigenen digitalen Zwilling erstellen kannst.
Setze das in einem Unternehmen ein und die Sache wird schnell konkret: ein Livestream-Host, der rund um die Uhr verkauft, ohne Feierabend zu machen, oder ein Support-Mitarbeiter, der um 3 Uhr morgens online ist und bei dem man mit einer Rückfrage dazwischengehen kann.
2. Was es wert ist: Die Zahlen im Detail
Das, was einen Nicht-Entwickler wirklich interessiert: Spart das Geld oder bringt es welches ein? Hier sind die öffentlichen Daten:
- Ein traditioneller Marken-Livestream mit einem menschlichen Team kostet ¥150k–250k pro Monat; ein KI-Avatar-Livestream wird auf einige Tausend bis ¥20k/Monat geschätzt – etwa 90 % Kostenersparnis (laut iResearch 2026 Digital-Human E-commerce Livestream White Paper).
- Ein digitaler Support-Agent kann über 60 % der häufigen Anfragen abfangen und die Betriebskosten um 30–60 % senken.
Nun zum anderen Weg – ein fertiges SaaS-Produkt wie HeyGen. Es ist absolut schlüsselfertig und das Ergebnis sieht großartig aus, aber es berechnet die Nutzung pro Minute: Die API kostet etwa 1 USD/Minute für Standard-Generierung, 4 USD/Minute für Avatar IV, 3 USD/Minute für Avatar V; und der Creator-Plan (29 USD/Monat) beinhaltet 200 Credits – das reicht nur für etwa 10 Minuten Premium-Avatar-Video.
Lass diesen Unterschied kurz sacken: SaaS bedeutet: Jede Minute, die du nutzt, bezahlst du. Ein selbst gehostetes Open-Source-Setup baut man einmal auf, danach fallen hauptsächlich Stromkosten und die Wertminderung der GPU an. Für ein Unternehmen, das lange und in hohem Volumen läuft (man denke an tägliches Livestreaming), sind diese beiden Kostenkurven nicht nur ein bisschen verschieden – sie liegen Welten auseinander.
3. Wie man es als Nicht-Entwickler baut: Ohne GPU starten
Dies ist der Kern der Analyse. Die klügste Design-Entscheidung von OpenTalking ist, dass man nicht gezwungen wird, am ersten Tag eine GPU zu kaufen. Es bietet dir drei Deployment-Stufen, die du nacheinander erklimmen kannst:
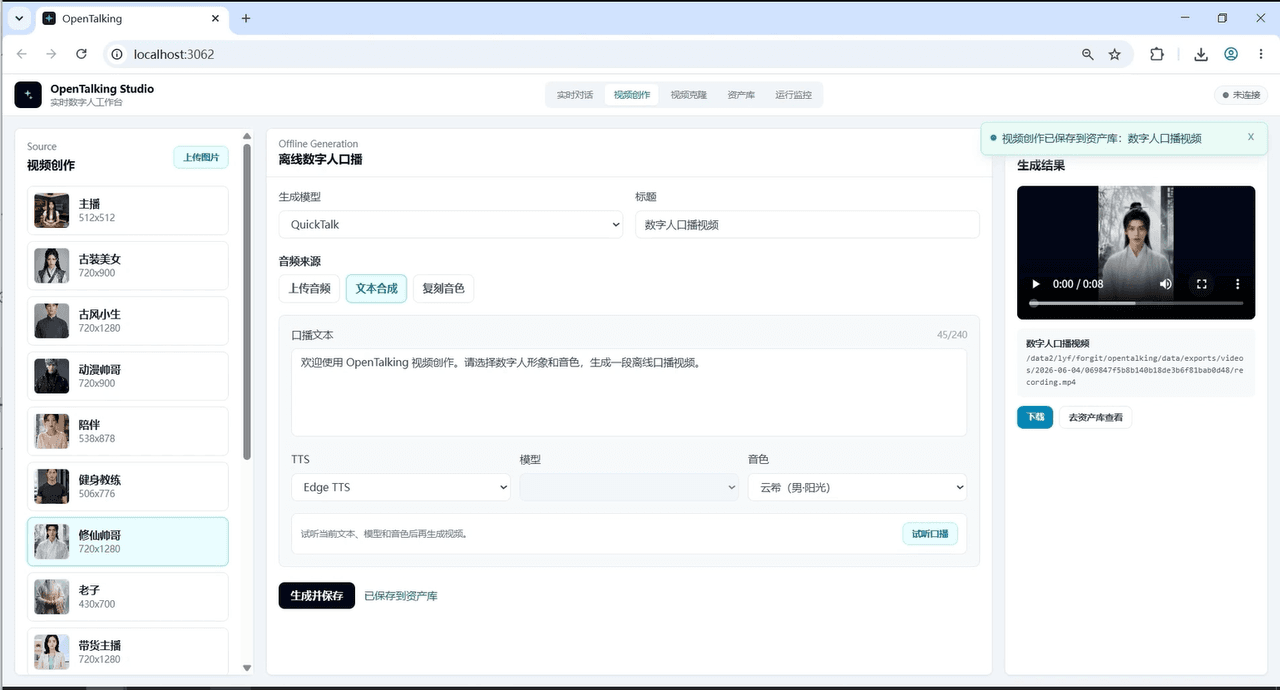
Schritt 0 – Mock-Modus (keine GPU, erst die Logik beweisen)
Starte die gesamte Produkt-Schleife mit dem Mock-Backend – Frontend-Interaktion, Session-Status, der komplette Konversationsfluss – auf einem gewöhnlichen Computer. Der Punkt dabei: Bestätige, dass dieses Produkt genau das ist, was du willst, bevor du auch nur einen Cent für eine GPU ausgibst. Die meisten Leute scheitern an der Hürde: „Ich muss erst eine Karte kaufen, nur um anzufangen.“ Hier kannst du das Ganze erst einmal testen.
Schritt 1 – Verpasse ihm ein Gehirn und einen Mund (das LLM)
Damit der Avatar antworten kann, verbindest du ein LLM für die Antworten. OpenTalking spricht die OpenAI-kompatible API, du musst also nicht im Code programmieren – gib einfach einen Endpoint und einen Schlüssel ein. Für diesen Schritt habe ich einen Schlüssel auf AtlasCloud genommen: Ein Schlüssel ruft DeepSeek, Seedance, Nano Banana und mehr auf, sodass ich mir nicht unzählige separate Konten registrieren musste. Stimme/TTS wird direkt im Web-UI ausgewählt.
Schritt 2 – Füge eine Consumer-GPU hinzu, tausche das Rendering-Modell aus
Sobald die Logik läuft und das Modell angebunden ist, entferne den Mock-Modus und schließe ein echtes Rendering-Backend an. Lokal reicht eine Consumer-Karte wie eine RTX 3060 (8 GB VRAM) für den Anfang völlig aus; sie unterstützt QuickTalk, Wav2Lip, MuseTalk, FlashTalk und mehr – wähle nach Qualität vs. Geschwindigkeit.
Schritt 3 – Skaliere erst, wenn das Geschäft wächst
Wenn du wächst, skaliert das System auf Multi-GPU und sogar NPUs wie die Huawei Ascend 910B2. Das bedeutet, das System wächst mit dir von „Basteln auf meinem Laptop“ bis hin zum „privaten Unternehmens-Deployment“ – ohne dass du mitten im Prozess das Framework wechseln musst.
4. Warum also nicht einfach ein SaaS? Wo Open-Source/Self-Hosting gewinnt
Nehmen wir die Namen, die jeder kennt, und führen einen ehrlichen Vergleich durch (jeder hat seine Stärken – kein Hype, kein Hate):
| Dimension | OpenTalking (Open-Source, Self-Host) | HeyGen / D-ID (SaaS) | ComfyUI Avatar-Workflows |
|---|---|---|---|
| Setup-Aufwand | Mittel (Deployment, aber Mock-Modus hilft) | Niedrig (schlüsselfertig, tolles Ergebnis) | Hoch (Nodes verkabeln, Graphen tunen) |
| Abrechnung | Einmalige Erstellung; nur Hardware/Strom | Laufend pro Minute / pro Credit | Kostenlos bei Eigenbetrieb |
| Daten | Lokal, verlassen nie deine Domäne | Hochgeladen auf deren Server | Lokal |
| Echtzeit + unterbrechbar | Nativ | Videogenerierungs-fokussiert; eingeschränkter Live-Chat | Meist Offline-Rendering |
| Anpassbarkeit | Hoch (erweiterbare Backends, editierbare Orchestrierung) | Niedrig (standardisiertes Produkt) | Hoch (flexibles Node-Ökosystem) |
Fair ist fair: SaaS im Stile von HeyGen gewinnt eindeutig beim Thema „kein Aufwand“ – wenn du dich nicht um das Deployment kümmern willst, einfach nur ein Ergebnis brauchst und dein Volumen gering ist, ist das die richtige Wahl. Das Node-Ökosystem von ComfyUI ist ebenfalls stark. Der Vorteil von OpenTalking ist nicht, dass es „jeden bei der Bildqualität schlägt“ – es sind zwei Dinge: Die Daten verlassen niemals deine Maschine (eine harte Anforderung für Regierung, Finanzen, Gesundheitswesen oder jedes Unternehmen, das keine Kundengespräche an Dritte weitergeben will) und es gibt keine minutengenaue Abrechnung (was sich bei hohem Volumen auf lange Sicht auszahlt).
Was das Richtige ist, hängt davon ab, ob dein Geschäft „gelegentliche Clips“ oder „täglichen Hochbetrieb“ bedeutet und ob es dich stört, deine Daten in fremde Hände zu geben.
Fazit
Zurück zur Eingangsfrage – wie weit sind KI-Avatare gekommen? Weit genug, dass einer in Echtzeit mit dir chatten, sich unterbrechen lassen und auf deiner eigenen Maschine laufen kann. Die Hürde ist niedriger, als man denkt: Probiere es erst im kostenlosen Mock-Modus aus, bestätige, dass es das ist, was du willst, und investiere dann. Für einen Nicht-Entwickler, der in diesen Bereich einsteigt, ist diese Reihenfolge wahrscheinlich der sicherste Weg.
❓ FAQ
F: Welche GPU brauche ich, um das zu bauen?
A: Um ein echtes Rendering-Modell lokal auszuführen, reicht für den Anfang eine Consumer-Karte wie eine RTX 3060 (8 GB VRAM); später kannst du auf Multi-GPU oder eine Ascend NPU skalieren. Aber beachte: Schritt 0 (Mock-Modus) benötigt gar keine GPU, ein gewöhnlicher Computer reicht aus, um die Logik zu testen.
F: Ich habe keine GPU. Kann ich es trotzdem ausprobieren?
A: Ja. Der Mock-Modus validiert den gesamten Konversationsfluss ohne GPU; wenn du ein echtes Modell willst, aber keine Karte hast, kannst du auf Cloud/Remote-Inference umsteigen und das Rendering in die Cloud auslagern.
F: Wie viel spart man wirklich im Vergleich zu HeyGen?
A: Strukturell entfällt die Minutenabrechnung. Die API von HeyGen kostet ca. 1–4 USD/Minute und die monatlichen Credits reichen oft nur für ca. 10 Minuten; Self-Hosting ist eine einmalige Einrichtung plus Hardware- und Stromkosten. Je öfter und länger du das System laufen lässt, desto mehr lohnt sich Self-Hosting – bei einer Handvoll gelegentlicher Clips ist SaaS tatsächlich weniger aufwendig.
F: Kann ich das kommerziell nutzen?
A: Technisch deckt es ab, was man für kommerzielle Zwecke benötigt – Echtzeit-Konversation, Support, Livestream-Zwillinge – mit privatem Deployment und Daten, die in deiner Domäne bleiben. Aber vor dem Live-Gang solltest du die Lizenzierung/Compliance der verwendeten Rendering-Modelle, Stimmen und Avatare prüfen. Avatare beinhalten das Gesicht und die Stimme von jemandem – kläre die Rechte vorher.
F: Ich bin totaler Anfänger. Wo fange ich an?
A: ① Führe das Projekt im Mock-Modus aus und erlebe den Konversationsfluss in deinem Browser; ② verbinde einen OpenAI-kompatiblen LLM-Schlüssel (für die Einfachheit nimm einen von AtlasCloud – mehrere Modelle, ein Schlüssel); ③ wähle eine Stimme; ④ füge eine GPU hinzu und tausche als letzten Schritt gegen ein echtes Rendering-Modell aus. Erst beweisen, dann bezahlen.






