Google Gemini Omni ist ein KI-All-in-One-Modell von Google DeepMind, das am 19. Mai 2026 auf der Google I/O vorgestellt wurde. Sein wichtigster Meilenstein ist die native Multimodalität. Das bedeutet, dass es Text, Bilder, Ton und Video in einem einzigen System verarbeitet und erstellt, anstatt verschiedene Tools miteinander zu verbinden. Es wurde für Creator, Entwickler und Unternehmen konzipiert, die Videos durch einfache Konversation erstellen und bearbeiten möchten, ohne dabei zwischen verschiedenen Apps wechseln zu müssen.
Ein Überblick über die Gemini Omni Funktionen beginnt mit einer einfachen Idee: Erstelle alles aus jedem beliebigen Input. Im Gegensatz zu herkömmlichen Text-to-Video KI-Tools kombiniert Omni die Schlussfolgerungsfähigkeit (Reasoning) von Gemini mit fortschrittlichem Media-Rendering in einem einzigen Durchgang.
Wichtige Funktionen auf einen Blick
| Funktion | Details |
|---|---|
| Akzeptierte Inputs | Text, Bild, Audio, Video |
| Primärer Output | Video (Bilder & Audio folgen in Kürze) |
| Bearbeitungsstil | Konversationell, Multi-Turn-Prompts |
| Erstes Modell | Gemini Omni Flash |
| Verfügbarkeit | Abonnenten von Google AI Plus, Pro & Ultra |
Zugangsmöglichkeiten
- Gemini App — Weltweit für AI Plus/Pro/Ultra-Abonnenten
- Google Flow — Vollständige Workflows für Kurzfilme
- YouTube Shorts / YouTube Create — Kurzvideo-Erstellung
- Developer API — Verfügbar in wenigen Wochen
Was ist Google Gemini Omni und wie funktioniert es?
Google Gemini Omni ist ein gewaltiger Sprung nach vorn. Es ist das zentrale All-in-One-KI-Modell von Google DeepMind für kreative Aufgaben. Das auf der Google I/O 2026 präsentierte System verarbeitet gleichzeitig Text, Bilder, Sound und Video, um hochwertige Videoinhalte zu erzeugen. Es löst offiziell Veo innerhalb des Gemini-Ökosystems ab.
Die Kern-Engine: Native Multimodalität erklärt
Die meisten bisherigen KI-Video-Tools folgten einem sequenziellen Prozess: Input in Textbeschreibungen umwandeln und diese an einen separaten Video-Renderer weiterleiten. Gemini Omni arbeitet anders. Es basiert auf einem nativen multimodalen Modell, das alle Medientypen simultan in einer zentralen Engine verarbeitet, statt sie durch isolierte Schritte zu schleusen.
Dies ist entscheidend, da der Wegfall von Konvertierungsebenen dazu führt, dass das Modell einen reichhaltigeren Kontext beibehält. Wenn Sie zusätzlich zum Text-Prompt ein Referenzfoto bereitstellen, analysiert Omni beides gleichzeitig und bewahrt visuelle Details, die durch einen Text-Konvertierungsschritt normalerweise verloren gingen.
Gemini Omni multimodaler Input in der Praxis
Gemini Omni multimodaler Input unterstützt folgende Kombinationen innerhalb eines einzelnen Prompts:
| Input-Typ | Anwendungsbeispiel |
|---|---|
| Nur Text | Szenen von Grund auf beschreiben |
| Bild + Text | Ein Standbild mit einer schriftlichen Anweisung animieren |
| Video + Text | Bestehende Clips konversationell bearbeiten |
| Audio + Text | Den Ton begleitend zum visuellen Prompt steuern |
| Gemischt (alle vier) | Referenzclips, Stilvorlagen und Erzählung kombinieren |
Echtzeitverarbeitung und konversationelle Kontrolle
Da das logische Denken innerhalb eines einzigen Modells stattfindet, ist die Echtzeitverarbeitung von Bearbeitungsbefehlen praktikabel geworden. Omni verfeinert Ergebnisse durch eine fortlaufende Konversation — tauschen Sie einen Hintergrund aus, passen Sie die Beleuchtung an oder stabilisieren Sie eine Aufnahme durch eine einfache Anweisung. Ein erneuter Start des Prompts ist nicht erforderlich.
Nicole Brichtova von Google DeepMind beschrieb es als "mehr als nur ein Veo-Update" — es ist die Kombination aus Geminis Reasoning und Media-Rendering in einem kohärenten System.
Konversationelle KI zur Videobearbeitung: Nutzung von Gemini Omni für komplexe Anpassungen
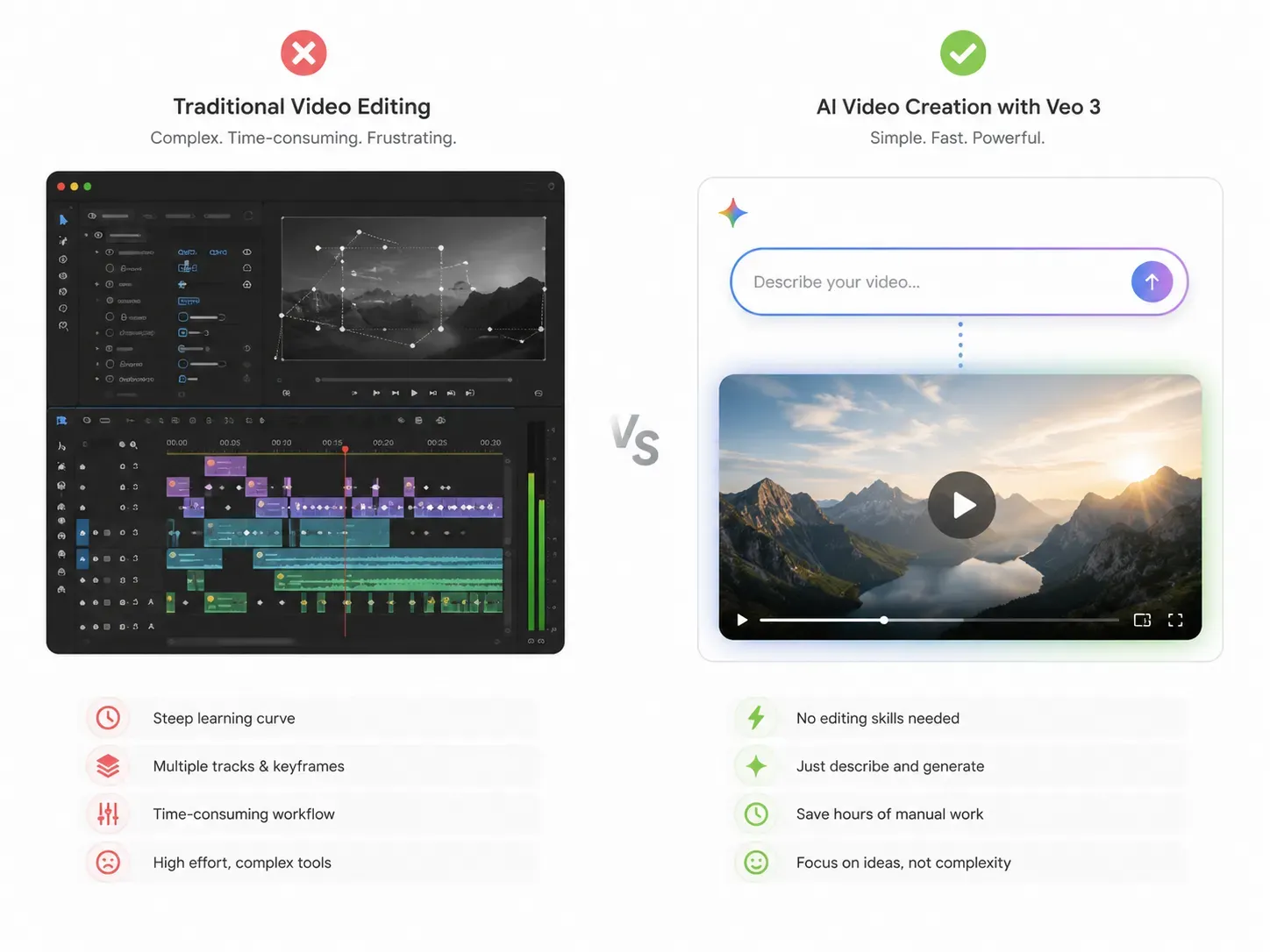
Die Architektur zu verstehen ist das eine, sie einzusetzen das andere. Genau hier hebt sich die konversationelle KI zur Videobearbeitung von Gemini Omni von herkömmlichen Tools ab.
Traditionelle Videoschnittprogramme erfordern Timelines, Ebenen und manuelles Keyframing. Gemini Omni ersetzt diesen Workflow vollständig. Laden Sie Ihr Filmmaterial hoch, schreiben oder sprechen Sie aus, was geändert werden soll, und das Modell rendert den Clip neu. Keine Plugins. Keine externe Software.
Kann Gemini Omni komplexe KI-Video-Elemente ersetzen?
Ja – und das ist eine der praktisch nützlichsten Funktionen. Laut offizieller Google-Dokumentation umfasst die Videobearbeitung von Assets unter anderem:
- Hintergrundtausch — Ersetzen der Umgebung hinter einer Person bei gleichzeitiger Beibehaltung des Charakters
- Garderoben- und Stiländerungen — Modifikation der Kleidung oder Transfer eines visuellen Stils auf einen Clip
- Objektaustausch — Austausch eines spezifischen Elements mitten im Shot
- Beleuchtungsanpassungen — Änderung der Stimmung oder Intensität der Szenenbeleuchtung durch einen einzigen Befehl
- Videostabilisierung — Glätten von wackeligen Aufnahmen durch einen natürlichsprachlichen Prompt
- Charaktertausch — Ersetzen einer Person durch eine andere unter Verwendung eines Referenzbildes
Interaktive Videobearbeitung durch Multi-Turn-Konversation
Was diese interaktive Videobearbeitung von einer einmaligen Generierung unterscheidet, ist die Multi-Turn-Schleife. Jede Bearbeitungsanweisung baut auf der vorherigen auf, sodass das Modell die Szenenkohärenz beibehält – derselbe Hintergrund, dieselbe Lichtlogik und dieselbe Identität des Charakters bleiben über mehrere Runden hinweg konsistent.
Ein Creator könnte zum Beispiel zuerst anweisen: "Tausche den Hintergrund gegen eine Stadtstraße aus", dann ergänzen: "Mache die Beleuchtung wärmer" und schließlich: "Stabilisiere die Aufnahme" – alles ohne die Generierung neu starten zu müssen.
KI-Video-Elementaustausch: Was man aktuell erwarten kann
Der KI-Video-Elementaustausch im aktuellen Modell Gemini Omni Flash ist auf 10-sekündige Clips ausgelegt. Komplexere Änderungen von Video-Assets in längeren Formaten – sowie zusätzliche Output-Typen wie eigenständige Bilder und Audio – sind für zukünftige Releases geplant.
Die Multi-Turn-Schleife meistern: Ein praktischer Gemini Omni Prompting-Guide
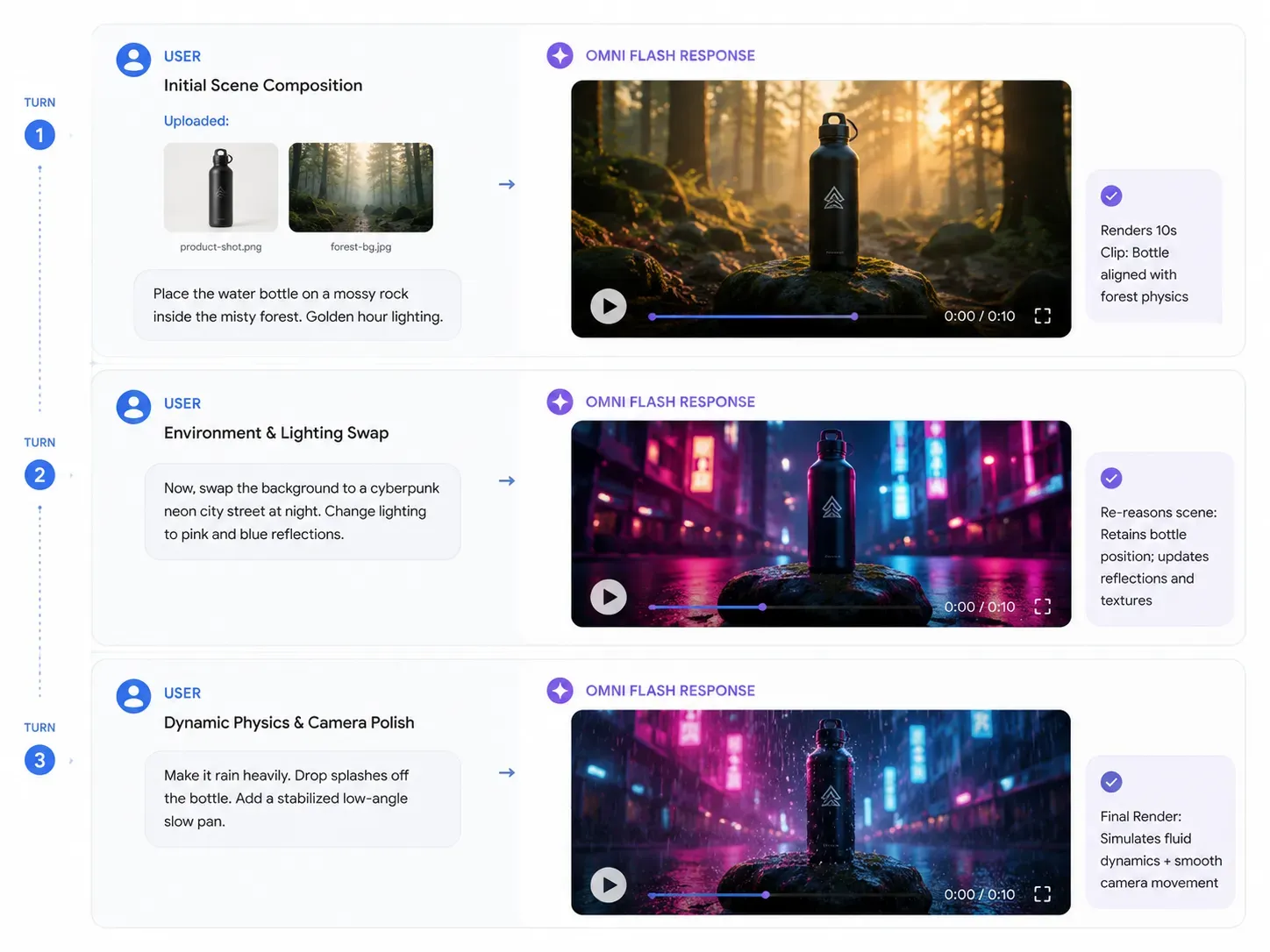
Um das volle Potenzial der nativen Multimodalität von Gemini Omni auszuschöpfen, muss sich Ihre Prompting-Strategie von der einmaligen Generierung hin zu einem fortlaufenden Dialog verlagern. Da die Physics-Engine des World Models die Umgebungslogik beibehält, können Sie Anweisungen Schritt für Schritt aufbauen.
Hier ist ein produktionsbereiter Entwurf für einen typischen Workflow im kommerziellen Bereich:
Turn 1: Der erste Referenz-Input
Input-Assets: Upload von marken-produkt-shot.png (eine metallische Wasserflasche) und hintergrund-referenz.jpg (ein nebliger Wald).
Prompt: "Generiere eine 10-sekündige cineastische Produktpräsentation. Platziere die metallische Wasserflasche aus dem Produktfoto auf einem moosigen Felsen im nebligen Wald. Stelle die Beleuchtung auf den frühen Morgen zur Golden Hour ein."
Erwarteter KI-Output: Omni analysiert beide Bilder gleichzeitig und platziert die Flasche realistisch auf dem Felsen, inklusive physikalisch korrektem Gewicht und korrektem Schattenwurf.
Turn 2: Die dynamische Anpassung
Input-Kontext: Kontinuierlicher Chat in derselben Sitzung (kein erneuter Upload nötig).
Prompt: "Tausche nun den Hintergrund. Ersetze den nebligen Wald durch eine minimalistische Cyberpunk-Neon-Stadtstraße bei Nacht. Ändere die Beleuchtung so, dass kühle blaue und heiße pinke Neonreflexionen auf der metallischen Oberfläche der Flasche zu sehen sind."
Erwarteter KI-Output: Die Hintergrundumgebung ändert sich sofort. Entscheidend ist, dass die Position der Flasche auf dem Felsen konsistent bleibt, sich aber die Reflexionen auf ihrer Oberfläche dynamisch an die neuen Neonlichtquellen anpassen.
Turn 3: Der physikalische Feinschliff
| Prompt-Aktion | Zielbefehl |
|---|---|
| Umgebungsphysik hinzufügen | "Lass es in der Szene stark regnen. Sorge dafür, dass Regentropfen realistisch von der Oberseite der Flasche abperlen und Wasserwellen auf dem Boden entstehen." |
| Kamerasteuerung anwenden | "Schwenke die Kamera langsam aus einem niedrigen Winkel nach oben und wende eine natürlichsprachliche Videostabilisierung an, um den Übergang zu glätten." |
Während das Beherrschen der Multi-Turn-Schleife innerhalb von Google Flow Ihren Prompt-Workflow optimiert, benötigen Entwickler, die Multi-Modell-Workflows skalieren, oft eine größere Flexibilität. Die Implementierung einheitlicher multimodaler KI-APIs ermöglicht es Plattformen wie Atlas Cloud, über 300 Modelle – inklusive fortschrittlicher Video-, Bild- und LLM-Reasoning-Engines – unter einer einzigen Orchestrierungsschicht bereitzustellen.
Realität simulieren: Die Kraft der Gemini Omni Physics-Engine
Konversationelle Bearbeitung liefert nur dann großartige Ergebnisse, wenn das Modell versteht, warum eine Szene so aussieht, wie sie aussieht. Hier wird die Gemini Omni Physics-Ebene (World Model) entscheidend.
Auf der Google I/O 2026 beschrieb Google DeepMind CEO Demis Hassabis Gemini Omni nicht als Videogenerator, sondern als World Model – ein System, das ein inneres Verständnis der Realität aufbaut und nachvollzieht, was in einer gegebenen Szene als Nächstes passieren sollte.
Was "World Model" in der Praxis bedeutet

Die meisten früheren Video-KI-Tools sagten den nächsten Frame voraus, indem sie Pixelmuster in großem Maßstab abglichen. Sie erzeugten Filmmaterial, das zwar echt aussah, sich aber nicht konsistent verhielt – Charaktere verformten sich zwischen Schnitten, Schatten ignorierten Lichtquellen und Flüssigkeiten bewegten sich eher wie eine Textur statt wie eine Substanz.
Gemini Omni wird anders trainiert. Laut Google integriert das Modell ein echtes Verständnis von Physik, Bewegung und räumlichem KI-Verständnis, um seine Ergebnisse auf der Funktionsweise der realen Welt zu gründen.
Physikalische Eigenschaften, die Gemini Omni simuliert
Laut Google verfügt das Modell über ein intuitives Verständnis der folgenden physikalischen Eigenschaften, basierend auf Genie – der Spielwelt-Simulationsplattform von DeepMind:
| Physikalische Eigenschaft | Praktischer Effekt im Video |
|---|---|
| Schwerkraft | Objekte fallen und landen mit korrektem Gewicht |
| Kinetische Energie | Impuls bleibt bei Kollisionen erhalten |
| Fluiddynamik | Wasser, Rauch und Flüssigkeiten verhalten sich natürlich |
| Beleuchtungskonsistenz | Schatten verschieben sich korrekt bei Szenenbearbeitung |
| Räumliche Anatomie | Charakterproportionen bleiben über Schnitte hinweg konsistent |
Warum das für konsistente Videogenerierung wichtig ist
Während der I/O 2026-Keynote wurde diese Ebene auf die Probe gestellt, indem ein hochpräzises Claymation-Erklärvideo über Proteinfaltung erstellt wurde – ein Beweis dafür, dass das Modell über bloßen Pixelabgleich hinausgeht und die tatsächliche wissenschaftliche und räumliche Realität versteht.
Dieses World-Model-Fundament ermöglicht konsistente Videogenerierung bei Multi-Turn-Bearbeitungen. Wenn ein Benutzer einen Hintergrund austauscht oder die Beleuchtung anpasst, fügt das Modell nicht einfach nur eine neue Ebene hinzu – es berechnet die physikalische Beziehung zwischen dem Subjekt, der neuen Umgebung und der Lichtquelle neu. Das Ergebnis ist eine Simulation der physischen Realität auf Szenenebene, statt nur Pixel zu flicken.
Der Paradigmenwechsel: Pixel-Matching vs. World Simulation
| Legacy Video-KI-Tools (Alte Ära) | Google Gemini Omni (World Model) |
| ❌ Fehlt logisches Verständnis; sagt lediglich die statistische Wahrscheinlichkeit des nächsten Pixel-Clusters voraus. | 🧠 Versteht Objektmasse, kinetischen Impuls und Energieerhaltung. |
| ❌ Schatten verzerren sich und Texturen reißen dynamisch, sobald sich der Kamerawinkel ändert. | 🧠 Simuliert globale Beleuchtung und sorgt dafür, dass Lichtstrahlen und Reflexionen natürlich brechen. |
| ❌ Charakteranatomie und Hintergrundstrukturen verzerren sich nach 3–5 Sekunden. | 🧠 Bewahrt eine einheitliche Umgebung, Lichtlogik und Identität über Multi-Turn-Bearbeitungen hinweg. |
Individuelle digitale Avatare: Kann Gemini Omni KI-Avatare für Creator erstellen?
Die beschriebene Physik des World Models lässt generiertes Filmmaterial echt aussehen. Die Avatar-Funktion sorgt dafür, dass es wie Sie aussieht.
Kann Gemini Omni einen KI-Avatar erstellen? Ja. Gemini Omni Flash enthält ein dediziertes Avatar-Tool, mit dem Creator ein digitales Abbild ihrer selbst erstellen können – unter Verwendung ihres eigenen Erscheinungsbildes und ihrer Stimme – und dieses direkt in generierten Videos einsetzen können, ohne jedes Mal Referenzmaterial hochladen zu müssen.
![]()
So funktioniert das Avatar-Onboarding
Um Missbrauch zu verhindern, hat Google vor der Erstellung eines Avatars einen strukturierten Verifizierungsschritt hinzugefügt. Laut TechCrunch absolvieren Benutzer einen speziellen Onboarding-Prozess, bei dem sie sich selbst aufnehmen und eine Reihe von Zahlen vorlesen müssen. Das aufgezeichnete Abbild wird dann gespeichert und für zukünftige Sitzungen wiederverwendet.
Die vollständige Sprachbearbeitung bestehender Clips Dritter wird noch geprüft, während Google an einer verantwortungsvollen Implementierung arbeitet. Alle individuellen digitalen Avatare und generierten Videos tragen das digitale Wasserzeichen „SynthID“ von Google, das über die Gemini-App, Gemini in Chrome und die Google-Suche verifizierbar ist.
Wie integriert sich Gemini Omni in YouTube Shorts und Google Flow?
Die folgende Tabelle zeigt den aktuellen Zugang nach Plattform:
| Plattform | Zugangslevel | Anmerkungen |
|---|---|---|
| Gemini App | AI Plus, Pro & Ultra-Abonnenten | Volle Omni Flash-Funktionen inklusive Avatar |
| Google Flow Plattform | AI-Abonnenten | Inklusive Flow Agent, Batch-Bearbeitung, Flow Music |
| YouTube Shorts Creator Tools | Kostenlos, kein Abo nötig | Ausrollung ab der Woche der Google I/O 2026 |
| YouTube Create App | Kostenlos | Gleicher Zeitplan wie Shorts |
| Developer API | Folgt in wenigen Wochen | Zugang für Enterprise und Google AI Studio |
Die Google Flow Plattform erhielt neben Omni Flash zusätzliche Updates: einen Flow-Agent für Brainstorming und Batch-Generierung, eine benutzerdefinierte Tools-Funktion für teilbare No-Code-Workflows und Flow Music-Unterstützung für vollständige Musikvideo-Erstellung und Stiltransformation.
Inhaltssicherheit und Herkunft: Wie das Google SynthID-Wasserzeichen Medien schützt
Leistungsstarke Avatar-Erstellungs- und Videobearbeitungstools werfen eine offensichtliche Frage auf: Was hindert sie daran, irreführende Inhalte zu erstellen? Googles Antwort ist ein nicht optionales, unmerkliches Wasserzeichen, das in jeden Clip eingebettet ist, den Gemini Omni produziert.
Was ist das Google SynthID Video-Wasserzeichen?
Das Google SynthID Video-Wasserzeichen ist kein sichtbares Logo oder ein entfernbarer Metadaten-Tag. Es handelt sich um ein Signal, das im Moment der Generierung direkt in die Pixel eines Videos eingebettet wird – unsichtbar für das menschliche Auge, aber lesbar durch die Erkennungstools von Google. Laut der I/O 2026 Keynote hat SynthID seit seiner Einführung bereits über 100 Milliarden KI-generierte Bilder und Videos markiert.
Entscheidend ist, dass das Signal so konzipiert ist, dass es gängige Nachbearbeitungsoperationen übersteht, die eine oberflächliche Markierung ansonsten löschen könnten:
- Kompression und Neukodierung
- Größenänderung und Zuschneiden
- Formatkonvertierung
Für Gemini Omni ist SynthID standardmäßig aktiviert und kann nicht deaktiviert werden.
Wie funktioniert die Verifizierung der KI-Medienherkunft?
Die KI-Medienherkunft (AI Media Provenance) kann über drei Google-Oberflächen überprüft werden: die Gemini-App, Gemini in Chrome und die Google-Suche. Benutzer laden einen Clip hoch, und das Erkennungstool markiert die spezifischen Zeitstempel, an denen ein Wasserzeichensignal gefunden wurde – dies bietet eine kontextuelle Verifizierung anstelle eines simplen Ja/Nein-Ergebnisses.
SynthID als Deepfake-Mitigationsstrategie
| Sicherheitsebene | Funktionsweise |
|---|---|
| Pixel-Level-Wasserzeichen | Übersteht Kompression, Zuschneiden, Neukodierung |
| Nicht-optionale Einbettung | Kann vom Benutzer nicht deaktiviert werden |
| Plattformübergreifende Nutzung | OpenAI und ElevenLabs übernehmen den C2PA-Standard |
| Avatar-Onboarding-Schranke | Erfordert Sprachverifizierung, bevor das Abbild gespeichert wird |
| Sprachbearbeitung zurückgehalten | Volle Sprachbearbeitung wird bis zur verantwortungsvollen Implementierung zurückgehalten |
Sundar Pichai fasste den Kontext auf der I/O 2026 zusammen: Studien zeigen, dass Menschen hochwertige Deepfake-Videos nur in etwa einem Viertel der Fälle korrekt identifizieren. SynthID bildet zusammen mit der zurückgehaltenen Sprachbearbeitungsfunktion den mehrschichtigen Ansatz von Gemini Omni zur Deepfake-Mitigation und Inhaltssicherheit.
Gemini Omni Flash vs. Pro: Abo-Modelle, Token-Preise und API-Zugang
Nachdem die Funktionen klar sind, stellt sich die praktische Frage: Was kostet der Zugriff und welcher Tarif passt zu Ihrem Workflow?
Wie bekommt man aktuell Zugriff auf Gemini Omni Flash?

Die Einführung von Gemini Omni Flash begann am 19. Mai 2026. Die Zugangswege hängen davon ab, wie Sie es nutzen möchten:
| Tarif-Stufe | Monatlicher Preis | Cloud-Speicher | Gemini App & Kernfunktionen |
|---|---|---|---|
| Google AI Plus | 7,99 USD / Monat | 200 GB | Nutzungslimits: 2x höher als ohne Google AI-Plan; Plus-Zugang zum Flash Thinking-Modell; |
| Google AI Pro | 19,99 USD / Monat | 5 TB | Nutzungslimits: 4x höher als ohne Google AI-Plan; Plus-Zugang zum Pro-Modell, Deep Research und mehr; |
| Google AI Ultra | 99,99 USD / Monat | 20 TB | Nutzungslimits: 5x höher als Pro-Tarif; Höhere Limits als im Pro-Plan, plus Zugriff auf fortgeschrittenste Funktionen wie Deep Think; |
Wie man Zugang zu Gemini Omni innerhalb von Google Flow erhält, hängt von den durch den Tarif zugewiesenen Google Flow Omni-Credits ab: vom Einstiegszugang in AI Plus über fortgeschrittene Multi-Turn-Film-Pipelines in AI Pro bis hin zu Studio-Rechenressourcen mit hohen Limits in AI Ultra.
Für Standard-Anwendungsbereitstellungen hält Googles Pay-per-Token-Modell für Vertex AI die Kosten vorhersehbar. Für produktionsreife Rendering-Pipelines, die an starre API-Ratenlimits stoßen, bietet der Wechsel zu flexiblen On-Demand GPU-Preismodellen jedoch einen kosteneffizienteren Plan, der Teams die volle Kontrolle über die Hardware ohne Mindestverpflichtungen gibt.
Gemini Omni Flash vs. Pro: Was ist der Unterschied?
Im Vergleich Gemini Omni Flash vs. Pro ist eine Seite bestätigt, die andere noch nicht verfügbar. Flash generiert 10-sekündige Clips – laut Nicole Brichtova von Google DeepMind ist dies eine bewusste Bereitstellungsbeschränkung, um die Rechenlast zum Start zu verwalten, keine Modellbeschränkung.
Omni Pro wurde angekündigt, hat aber noch kein Veröffentlichungsdatum. Google sagt, es werde erscheinen, sobald das Team "einen deutlichen Sprung gegenüber Flash" sieht. Bis dahin ist Flash das einzige öffentlich verfügbare Omni-Modell.
Gemini Omni vs. Google Veo: Was hat sich geändert?
Gemini Omni vs. Google Veo ist ein architektonischer Wandel, kein einfaches Versions-Update. Veo 3.1 bleibt mit GA API-Zugang für Text-to-Video-Generierung aktiv. Omni fügt eine Reasoning-Ebene hinzu, akzeptiert alle vier Input-Typen simultan und führt konversationelle Multi-Turn-Bearbeitung ein – Funktionen, für die Veo ursprünglich nicht ausgelegt war.
Eine einheitliche API für die Videoproduktion
Während Google Gemini Omni Flash in der Gemini-App und in Google Flow für Endbenutzer ausrollt, benötigen Entwickler und Produktteams, die dieselbe multimodale Video-Engine in ihre eigenen Workflows einbetten möchten, eine stabile und vorhersehbare API-Ebene.
Atlas Cloud stellt Gemini Omni Flash über eine einheitliche, OpenAI-kompatible API bereit, zusammen mit über 300 weiteren Bild-, Video- und LLM-Modellen – sodass Sie Googles natives multimodales Modell integrieren können, ohne separate Anbieterkonten, Abrechnungsportale oder SDKs verwalten zu müssen.
Beide Gemini Omni Flash-Varianten sind auf Atlas Cloud live:
| Variante | Bestens geeignet für | Inputs | Auflösung | Dauer | Startpreis |
| Gemini Omni Flash Text-to-Video (Developer) | Reine prompt-gesteuerte cineastische Generierung | Text (bis 20.000 Zeichen) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/s |
| Gemini Omni Flash Image-to-Video (Developer) | Motiv-konsistentes Video aus echten Referenzen | Text + bis zu 7 Referenzbilder | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/s |
Quick Start — Generiere ein Gemini Omni Flash-Video in 5 Zeilen:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "Ein nebliger Wald zur goldenen Stunde, cineastischer Dolly-Shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
Die API gibt sofort eine Prediction-ID zurück – rufen Sie /api/v1/model/prediction/{id} ab, um die URL des gerenderten MP4-Videos zu erhalten. Vollständiges Schema, Code-Beispiele in 7 Sprachen und ein No-Code-Playground sind auf den oben verlinkten Modellseiten verfügbar.
Fazit: Die Zukunft multimodaler Inhalte
Gemini Omni repräsentiert weit mehr als nur einen besseren Videogenerator. Durch die Verschmelzung von Geminis Reasoning-Engine mit nativer multimodaler Generierung hat Google das, was früher vier separate Tools erforderte – Text-Prompting, Bildreferenzierung, Video-Rendering und Post-Produktion – in einen einzigen konversationellen Workflow überführt.
Die Auswirkungen sind weitreichend. Die Physik des World Models sorgt dafür, dass Bearbeitungen ohne manuelles Compositing glaubwürdig aussehen. Die Herkunft durch SynthID stellt sicher, dass Verantwortlichkeit fest eingebaut ist, nicht nachträglich angefügt. Die Avatar-Erstellung bedeutet, dass Creator in großem Stil produzieren können, ohne jedes Mal vor der Kamera stehen zu müssen. Und da Omni Flash bereits in der Gemini-App, Google Flow und YouTube Shorts verfügbar ist, ist die Eintrittsschwelle niedrig genug für einzelne Creator wie auch für Enterprise-Teams.
Was als Nächstes kommt – Omni Pro, breiterer API-Zugang und erweiterte Output-Modalitäten – wird definieren, wie weit dieser Wandel geht.
Jetzt sind wir auf Ihre Meinung gespannt. Welche Funktion von Gemini Omni werden Sie als Erstes in Ihrem Workflow testen – konversationelle Hintergrundbearbeitung, Avatar-Erstellung oder physikalisch fundierte Szenengenerierung? Schreiben Sie Ihre Antwort unten in die Kommentare.






