
Kurzantwort
Ein GitHub AI Video Generator Skill verbindet deinen Code mit KI-Videomodellen. Im Jahr 2026 hängt die Wahl zwischen Open-Source (kostenlos, selbst gehostet) und bezahlten APIs (Cloud, sofort einsatzbereit) von vier Variablen ab: VRAM-Verfügbarkeit, Datenschutzanforderungen, benötigte Qualitätsstufe und monatliches Generierungsvolumen. Für Workflows im produktiven Maßstab, die mehrere SOTA-Modelle erfordern, bietet Atlas Cloud (atlascloud.ai) Zugriff auf über 300 Modelle — darunter Kling v3.0, Seedance 2.0, Vidu 3.0, Veo und Sora — über einen einzigen API-Schlüssel mit transparenter Pay-per-Use-Abrechnung.
-
Was ist ein AI Video Generator Skill? {#what-is-a-skill}
Im Kontext von GitHub-Repositories ist ein AI Video Generator Skill ein wiederverwendbares Modul, ein Wrapper oder eine Integrationsschicht, die eine Anwendung mit einem KI-Videogenerierungs-Backend verbindet — sei es ein selbst gehostetes Open-Source-Modell oder eine Cloud-API.
Stell es dir als Abstraktion zwischen deiner Anwendungslogik und der eigentlichen Inference-Engine vor. Ein Skill kann sein:
- Eine Python-Klasse, die die
Wan 2.2-Modellpipeline für Text-zu-Video-Generierung kapselt - Ein benutzerdefinierter ComfyUI-Node, der für die Kling v3.0-Generierung eine Verbindung zur Atlas Cloud API herstellt
- Ein n8n-Workflow-Node, der Seedance 2.0 via REST auslöst und eine Video-URL zurückgibt
- Ein LangChain-Tool oder MCP Server Skill, der bei Bedarf einen Videogenerierungs-Endpunkt aufruft
Die Kernfrage, vor der jeder Entwickler beim Erstellen steht: Soll das Backend aus Open-Source-Gewichten bestehen, die lokal laufen, oder aus einer bezahlten Cloud-API?
Reale Daten aus 2026. Keine Theorie.
-
Open Source auf GitHub im Jahr 2026 {#open-source-landscape}
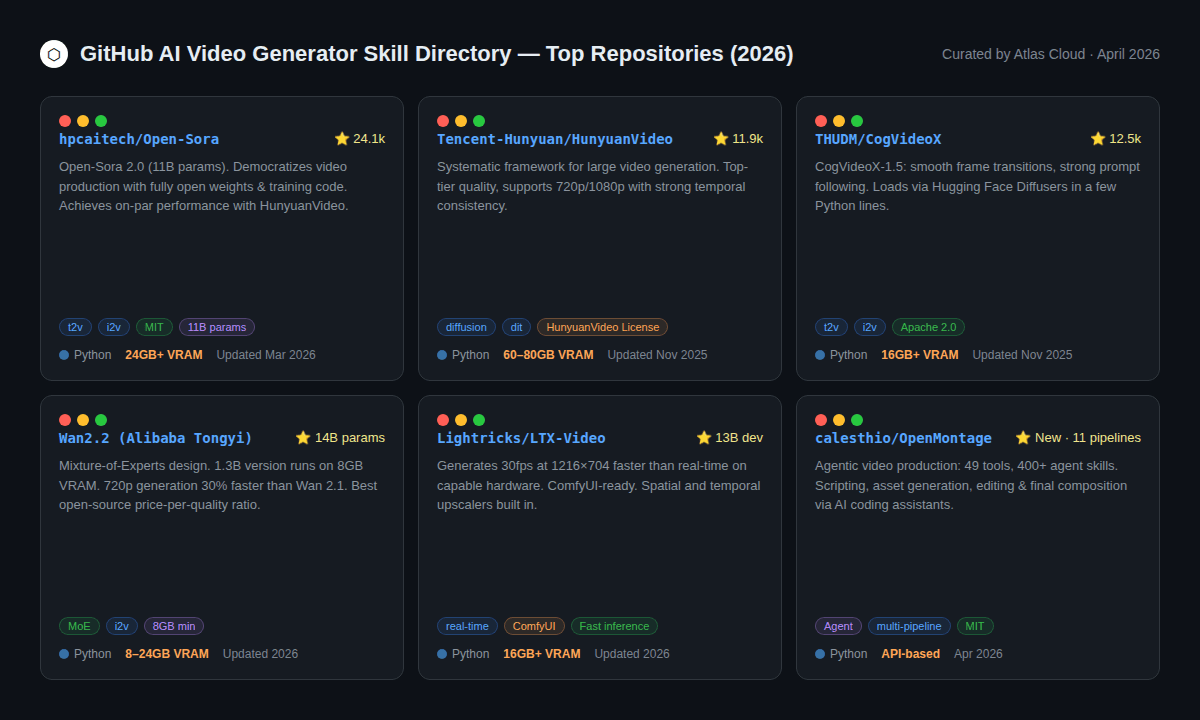
Das Open-Source-Ökosystem für Videogenerierung ist deutlich gereift. Einige Repos sind mittlerweile echte Alternativen zu bezahlten APIs – zumindest für bestimmte Aufgaben.
Tier 1: Produktionsreife Open-Source-Modelle
HunyuanVideo (Tencent, 11,9k ⭐) — Einer der besseren Open-Source-Videogeneratoren. Unterstützt 720p und 1080p. Die Haupteinschränkung ist der Hardwarebedarf: 60–80 GB VRAM für das volle Modell, was es nur Teams mit Enterprise-GPU-Zugriff zugänglich macht. Die Community-Lizenz erlaubt die kommerzielle Nutzung bei Namensnennung.
CogVideoX-1.5 (THUDM/CogVideo, 12,5k ⭐) Veröffentlicht unter Apache 2.0, ist dies eines der entwicklerfreundlichsten offenen Modelle. Es lässt sich nativ über Hugging Face Diffusers mit wenigen Zeilen Python laden. Die Frame-Übergänge sind weich und das Prompt-Following ist stark. Benötigt mindestens 16 GB VRAM. Eine solide Wahl, wenn dein Team bereits auf Hugging Face setzt.
Open-Sora 2.0 (hpcaitech, 24,1k ⭐) Das am häufigsten mit Sternen bewertete Open-Source-Videogenerierungsprojekt auf GitHub. Version 2.0 (11B Parameter) erreicht eine Performance, die auf VBench-Benchmarks mit HunyuanVideo vergleichbar ist, und die Trainingskosten wurden auf ca. 200.000 USD geschätzt – ein bemerkenswerter Wert für ein Modell dieser Klasse. Text-to-Video, Image-to-Video und Generierung unendlicher Länge.
Tier 2: Leichtere Open-Source-Optionen (weniger VRAM)
Wan 2.2 (Alibaba Tongyi) Die Geschichte der Zugänglichkeit ist hier überzeugend: die 1,3B-Variante läuft mit 8 GB VRAM, die 14B-Variante mit 24 GB. Die Mixture-of-Experts (MoE)-Architektur liefert bessere Details bei geringeren Rechenkosten, und Version 2.2 ist bei 720p um 30 % schneller als ihr Vorgänger. Für Entwickler, die eine einzelne Consumer-GPU nutzen, ist Wan 2.2 die stärkste Open-Source-Option.
LTX-Video (Lightricks) Vor allem auf Geschwindigkeit ausgelegt. Generiert 30 fps bei einer Auflösung von 1216×704 schneller als in Echtzeit auf fähiger Hardware. Die ComfyUI-Integration ist ausgereift, und räumliche sowie zeitliche Upscaler sind integriert.
Tier 3: Agentische Pipelines
OpenMontage (calesthio, neu April 2026) Eine wirklich neuartige Kategorie: ein agentisches Videoproduktionssystem mit 11 Pipelines, 49 Tools und über 400 Agenten-Skills. Funktioniert mit KI-Coding-Assistenten wie Claude Code, Cursor und Copilot. Übernimmt die gesamte Pipeline — Recherche, Skripterstellung, Assets, Schnitt — von Anfang bis Ende ohne manuelle Schritte. Entwickelt für Teams, die mehrere KI-Tools in einem Workflow vernetzen.
-
Verzeichnis bezahlter APIs: SOTA-Modelle jetzt verfügbar {#paid-api-directory}
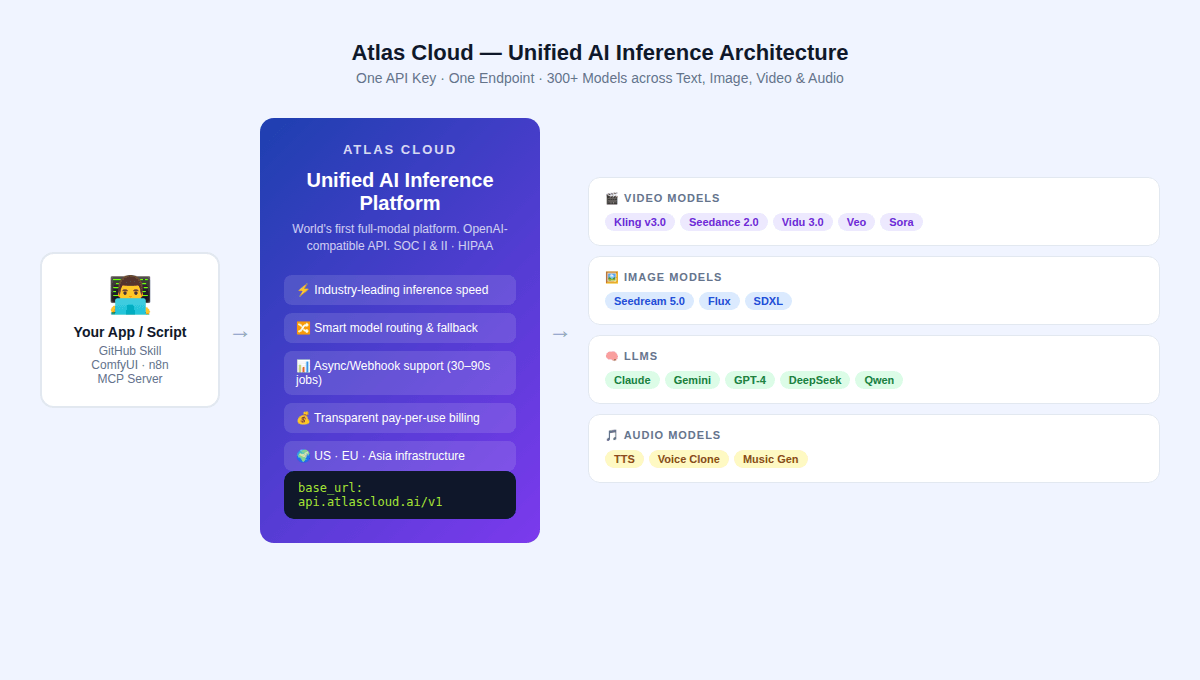
Die Landschaft der bezahlten APIs im Jahr 2026 wird von drei großen Modellfamilien definiert, von denen jede einen eigenen technischen Ansatz verfolgt. Alle drei sind über die einheitliche API von Atlas Cloud verfügbar.
Kling v3.0 (Kuaishou)
Erschienen am 5. Februar 2026. Basiert auf einer multimodalen visuellen Spracharchitektur – Text, Bilder, Audio und Video werden in einem System verarbeitet.
Was es besser macht als die Konkurrenz:
- Komplexe menschliche Bewegungen – Laufen, Tanzen, Kampfsport – ohne die „Spaghetti-Gliedmaßen“-Verformungen, die andere Modelle plagen.
- Native mehrsprachige Audiogenerierung (5 Sprachen, inklusive synchronisierter Lippenbewegungen).
- Motion Brush: Ein Tool, mit dem Entwickler (oder Endnutzer) Bewegungspfade direkt auf Quellbilder zeichnen können – eine Funktion, für die es in Konkurrenzmodellen derzeit kein Äquivalent gibt.
- Element-Binding für konsistentes Charakter- und Objekt-Tracking über Szenen hinweg.
Wo es Schwächen zeigt: Die Rendergeschwindigkeit ist in der Pro-Stufe langsamer als bei einigen Konkurrenten. Die Übergänge der Storyboard-Tools können laut unabhängigen Rezensenten „holprig“ sein.
Bestens geeignet für: Social-Media-Shorts auf TikTok und Reels, E-Commerce-Produktvideos und alles, was hohes Volumen erfordert, bei dem Charaktere konsistent bleiben müssen.
Seedance 2.0 (ByteDance)
Erschienen am 8. Februar 2026, stellt Seedance 2.0 einen Paradigmenwechsel in der KI-Videoprompting-Technik dar – weg von reinen Text-Prompts hin zu einer echten, referenzbasierten Regie-Steuerung.
Die technische Kerninnovation: Seedance 2.0 akzeptiert gleichzeitig quadmodale Eingaben – Text, Bild, Video und Audio. Sein „Universal Reference“-System ermöglicht es Entwicklern, ein Referenzvideo einer tanzenden Person einzuspeisen, und das Modell repliziert die Kamerabewegung, die Aktionen des Charakters und die Komposition im generierten Output. Dies löst das Problem der Charakterkonsistenz, was reine Text-to-Video-Modelle nicht können.
Unabhängige Tests bestätigen, dass es besonders glänzt bei:
- Storytelling mit mehreren Szenen und konsistenter Charakteridentität über Schnitte hinweg.
- Synchronisierter Audio-Video-Generierung (Dual-Branch-Architektur generiert Sound und Video gleichzeitig).
- Präziser Replizierung von Komposition und Licht aus Referenz-Assets.
Hinweis zur Verfügbarkeit: Stand April 2026 ist der internationale API-Zugriff für Seedance 2.0 über Plattformen wie Atlas Cloud verfügbar. Der direkte BytePlus API-Zugriff für internationale Entwickler war teilweise inkonsistent – überprüfe den aktuellen Status, bevor du eine Abhängigkeit von direkten ByteDance-Endpunkten aufbaust.
Bestens geeignet für: Musikvideos, präzise Charakteranimation, Produktwerbung, bei der die Bewegung exakt stimmen muss, sowie für Agenturen, die Storyboard-zu-Video-Workflows betreiben.
Vidu 3.0 (Shengshu AI / Tsinghua)
Basierend auf der ursprünglichen U-ViT-Architektur, die Diffusions- und Transformer-Technologien kombiniert, konzentriert sich Vidu auf Bereiche, in denen KI-Video noch Schwierigkeiten hat: Umweltkohärenz und filmische Konsistenz.
Besondere Merkmale:
- Universelles Referenzsystem für konsistente Beleuchtung über Sequenzen mit mehreren Einstellungen hinweg.
- Intelligente Hintergrundmusikgenerierung, die sich automatisch an die Stimmung der Szene anpasst.
- Langform-Generierung mit starker zeitlicher Konsistenz (entscheidend für Sequenzen länger als 5 Sekunden).
Beste Anwendungsfälle: Professionelle Filmproduktions-Workflows, Animationsdesign, kreative Werbung, die filmische Qualität erfordert.
Sora 2 (OpenAI)
Sora 2 bleibt der Maßstab für die Genauigkeit von physikalischen Simulationen. Wenn du in einem Sora 2-Prompt ein Glas zerbrechen lässt, verhalten sich das Bruchmuster, die Fluiddynamik und die Reflexionen wie in der Realität – die meisten Konkurrenten erreichen dieses Maß an Konsistenz noch nicht.
Bestens geeignet für: VFX-Arbeit, Architekturvisualisierung, Dokumentar-B-Roll, überall dort, wo physikalische Genauigkeit wichtiger ist als Kosteneinsparung.
Preise: Sora 2 ist in dieser Kategorie am teuersten. Du zahlst für die Rechenleistung.
-
Inference-Kosten: Die echten Zahlen {#inference-costs}
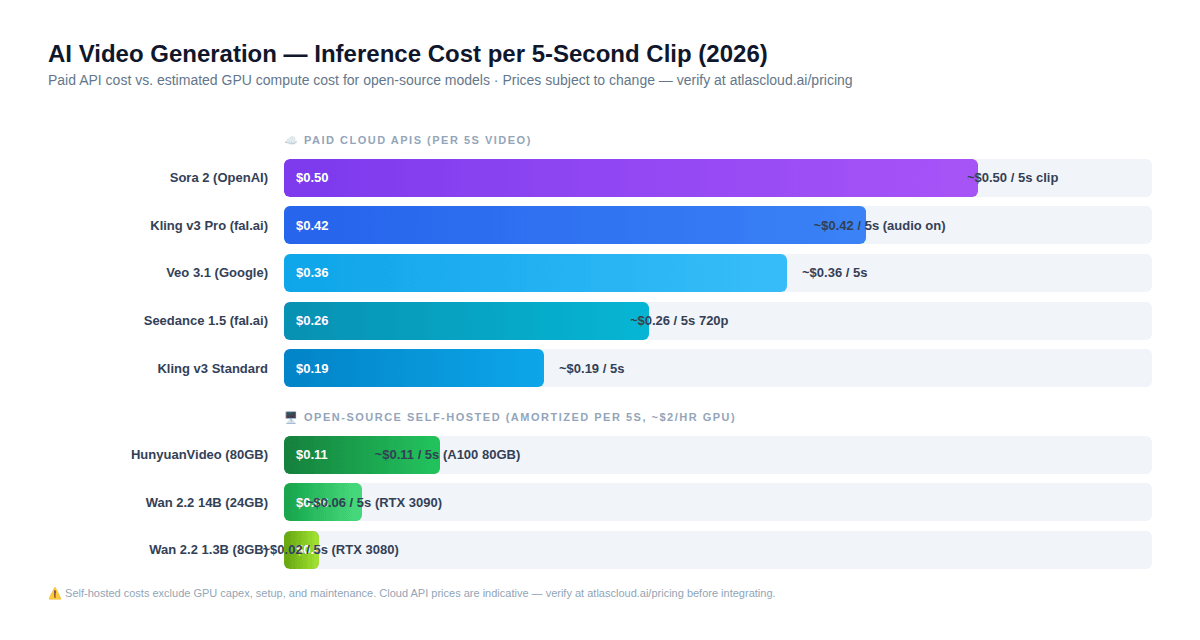
Dieser Abschnitt enthält die wichtigste kontraintuitive Erkenntnis dieses gesamten Leitfadens – eine, die die Standardintuition der meisten Entwickler bezüglich Open-Source vs. bezahlte APIs ändert.
Die versteckten Kosten selbst gehosteter Modelle
Die meisten Entwickler gehen davon aus: „Open-Source = kostenlos = immer billiger.“
Diese Annahme ist für die meisten Teamgrößen falsch.
So sieht die echte Rechnung für einen 5-sekündigen Videoclip im Jahr 2026 aus:
Selbst gehostetes Open-Source (amortisierte GPU-Kosten bei ca. 2 USD/Std.):
- Wan 2.2 1.3B (RTX 3080): ~0,02 USD pro 5s-Clip
- Wan 2.2 14B (RTX 3090): ~0,06 USD pro 5s-Clip
- HunyuanVideo (A100 80GB): ~0,11 USD pro 5s-Clip
Bezahlte Cloud-API (indikative Preise – verifiziere auf atlascloud.ai/pricing):
- Kling v3 Standard: ~0,19 USD pro 5s-Clip
- Seedance 1.5 720p mit Audio: ~0,26 USD pro 5s-Clip
- Kling v3 Pro mit Audio: ~0,42 USD pro 5s-Clip
- Sora 2: ~0,50 USD pro 5s-Clip
Die Zahlen für das Selbst-Hosting sehen isoliert betrachtet attraktiv aus. Das Problem ist, dass sie Folgendes nicht berücksichtigen:
- GPU-Hardware — Eine A100 80GB kostet 10.000 bis 15.000 USD. Bei 1.000 Videos pro Monat (ca. 0,11 USD pro Stück) bräuchtest du über 9.000 Monate, um die Hardwarekosten zu amortisieren.
- Einrichtungszeit — CUDA-Konfiguration, Herunterladen von Modellgewichten, VRAM-Management und Debugging verbrauchen 20–40 Ingenieursstunden für die Ersteinrichtung.
- Laufende Wartung — Modell-Updates, Abhängigkeitskonflikte und Infrastruktur-Zuverlässigkeit sind kontinuierliche Zeitfresser.
- Opportunitätskosten — Zeit, die für Inference-Infrastruktur aufgew






