
Kling 2.6 ist das bisher bedeutendste Kling AI-Update, bringt jedoch eine wichtige Einschränkung mit sich, die Sie kennen sollten, bevor Sie loslegen.
Diese Veröffentlichung markiert das erste Mal, dass Kling ein echtes natives Audio-Sync-Modell herausgebracht hat. Zuvor war jedes generierte Video im Grunde ein Stummfilm. Ersteller mussten Voiceovers, Soundeffekte und Hintergrundgeräusche manuell hinzufügen, nachdem das Video erstellt wurde. Das neue VIDEO 2.6-Modell ändert alles: Es erstellt die Optik, realistische Voiceovers, passende Soundeffekte und Hintergrund-Audio gleichzeitig. Dieses Feature hebt das Tool in eine völlig neue Klasse.
Was gut funktioniert
Das Modell ist hervorragend darin, Bild und Ton aufeinander abzustimmen. Sprachrhythmus, Hintergrundgeräusche und die Aktionen auf dem Bildschirm stimmen perfekt überein. Dies beendet die übliche Diskrepanz zwischen Video- und separaten Audiospuren. Filmische Sounds wirken unglaublich realistisch. Man kann Details wie prasselndes Feuer, Regen auf der Straße und die vielschichtigen Geräusche einer Menschenmenge deutlich hören. Die Unterstützung umfasst sechs Audiotypen:
| Audiotyp | Anwendungsfall |
| Sprach-Narration | Produktvideos, Vlogs |
| Dialog mit mehreren Personen | Interviews, Skits |
| Gesang / Rap | Musikdarbietungen |
| Umgebungsgeräusche | Natur, urbane Szenen |
| Objekt-/Aktions-SFX | Aufprall, mechanische Geräusche |
| Gemischter Sound | Vollständig immersive Produktion |
Die Haupteinschränkung
Dialogszenen mit drei oder mehr Sprechern können zu inkonsistenter Stimmzuordnung führen. Um die zuverlässigste audiovisuell Synchronisation zu erreichen, sollten sich Ersteller auf Dialoge mit zwei Personen beschränken oder alternative Bildausschnitte wählen.
Der Vergleich
Version 2.6 ist ein großer Fortschritt gegenüber den älteren, stummen Modellen. Einige Anwender benötigen möglicherweise perfekte Kontrolle oder massiv hochwertige Ergebnisse; diese sollten sich stattdessen Kling 3.0 ansehen. Die meisten Content-Ersteller bewerten Kling 2.6 jedoch sehr positiv, da es eine hervorragende Qualität zum fairen Preis liefert.
Die Anatomie des nativen Kling-Audios: Ein tiefer Einblick in Dialoge, SFX und Umgebungsgeräusche
Kling 2.6 fügt nicht einfach Audio über das Video. Es generiert alle drei Audioschichten gleichzeitig mit den visuellen Frames in einem einzigen Durchgang. So funktioniert jede Schicht in der Praxis:
Dialoge und Sprache
Die Dialoggenerierung von Kling AI deckt einen breiteren Bereich ab, als die meisten Ersteller erwarten. Das Modell bewältigt problemlos Solo-Reden, Dialoge zwischen Charakteren, Narration, Gesang und Rap. Es passt den emotionalen Ton an jeden Stil an. Zudem ist das Tool zweisprachig und unterstützt von Natur aus Sprachausgaben in Englisch und Chinesisch. Wenn Sie andere Sprachen eingeben, übersetzt das Modell diese automatisch ins Englische für die Sprachgenerierung, ohne den gesamten Video-Output zu beeinträchtigen.
Das 8-sekündige Video oben demonstriert unseren direkten Output mit Kling 2.6 über die Atlas Cloud Orchestrierungsplattform. Durch das Hochladen eines hochauflösenden Basisbildes des Sprechers und einer vorab aufgenommenen 8-sekündigen englischen Sprachspur hat die Engine das Lip-Sync nativ verarbeitet.
Beachten Sie, wie die Synchronisation der Gesichtsmuskeln flüssig auf komplexe Phoneme abgebildet wird, ohne das übliche roboterhafte Verzerren des Mundes (Uncanny Valley). Dies dient als perfekte Blaupause für schnell generierte KI-Markenbotschafter.
Schnelle Zeitspar-Regeln:
- Achten Sie auf die Groß- und Kleinschreibung. Verwenden Sie für alltägliche Wörter Kleinschreibung. Sparen Sie Großbuchstaben für Namen und Akronyme auf.
- Kennzeichnen Sie Ihre Sprecher. Geben Sie jeder Person ein Tag wie [Charakter A] oder [Charakter B]. Dies verhindert, dass die KI ihre Stimmen vermischt.
- Beschreiben Sie die Stimmung. Fügen Sie Tonnotizen direkt neben das Label. Schreiben Sie zum Beispiel [Reporter, ruhige und feste Stimme].
Soundeffekte (SFX)
KI-Video-Soundeffekte in 2.6 werden kontextabhängig ausgelöst und nicht manuell zugewiesen. Das Modell liest die Szenenbeschreibung und schließt auf passende Sounds. Die KI generiert Geräusche direkt basierend auf Ihren Aktionswörtern. Sie kann Schritte auf Kies, brechendes Glas, quietschende Reifen oder Maschinensummen erzeugen. Um die besten Ergebnisse zu erzielen, benennen Sie die spezifische Geräuschquelle klar. Beispielsweise funktioniert [Holztür schlägt zu, lauter Knall] deutlich besser als nur „da ist ein Geräusch“.
Umgebungsgeräusche
Die Synthese von Umgebungsgeräuschen übernimmt die Ebene der Umgebung: Café-Gemurmel, Regen gegen Glas, Wind über einem offenen Feld, ankommende U-Bahnen. Diese Hintergrundspuren spielen unter Ihren Dialogen und Soundeffekten. Sie verleihen Ihrem Video echte Tiefe. Benennen Sie die spezifische Umgebung in Ihrem Prompt. Verwenden Sie zum Beispiel Begriffe wie `[Akustik kleiner Raum]` oder `[Hall offene Halle]`. Dies gibt dem Modell ein klares Ziel und verbessert das Audio.
Dauer: 5-Sekunden- vs. 10-Sekunden-Output
Diese Wahl beeinflusst direkt die Audiostabilität. Die Entscheidung zwischen Kling 5-Sekunden- oder 10-Sekunden-Video ist besonders wichtig für sprachlastige Inhalte.
| Inhaltstyp | Empfohlene Dauer | Grund |
| Nur Atmosphäre / SFX | 5s | Sauberer, kompakter Output |
| Monolog / Narration | Beide | Abhängig von Skriptlänge |
| Dialog mit mehreren Personen | 10s | Stabilere Stimmwechsel |
| Gesang / Rap | 10s | Verhindert Abschneiden von Text |
Für Gesangs- oder Dialogszenen wird der 10-Sekunden-Parameter für vollständigere und stabilere Ergebnisse empfohlen. Kürzere Clips eignen sich gut für reine Atmosphäre oder Aktions-Sound-Paarungen, aber alles, was gesprochene Zeilen beinhaltet, profitiert vom längeren Zeitfenster, um Audio-Drifts in den letzten Sekunden zu vermeiden.
Die perfekte Kling 2.6-Prompt-Formel für makellose audiovisuell Synchronisation
Die meisten Synchronisationsprobleme in Kling 2.6 entstehen nicht durch das Modell selbst, sondern durch Prompts, die zu viel Spielraum für Interpretationen lassen. Betrachten Sie Ihren Prompt wie eine Regieanweisung: Je präziser Sie jedes Element definieren, desto weniger muss die Inferenz-Engine raten – und beim Raten geht oft der Rhythmus verloren.
Die Kernformel
Diese Kling-Prompt-Vorlage bildet direkt ab, wie das Modell die Generierung verarbeitet:
Szene → Subjekt → Bewegung und Kamera → Audio-Blaupause
Die offizielle Prompt-Struktur lautet: Szene (Szenenbeschreibung) + Element (Subjektbeschreibung) + Bewegung (Bewegungsbeschreibung) + Audio (Dialog / Gesang / Soundeffekte / Musik) + Anderes (Stil / Emotion / Kamera).
Jeder Block speist einen anderen Teil der Generierungs-Pipeline. Wenn einer ausgelassen wird, muss das Modell die Lücke füllen, was dazu führt, dass der audiovisuelle Rhythmus auseinanderfällt.
Aufschlüsselung Block für Block
| Block | Was zu enthalten ist | Häufiger Fehler |
| Szene | Ort, Beleuchtung, Tageszeit | Zu vage: „ein Raum“ |
| Subjekt | Aussehen, Rolle, Position im Bild | Unbenannte oder nur Pronomen |
| Bewegung / Kamera | Aktionssequenz, Kling-Kamerasteuerung (langsamer Zoom, Tracking-Shot, Nahaufnahme) | Gar keine Kameraanweisung |
| Audio-Blaupause | Dialog in Anführungszeichen, Emotions-Tag, SFX-Label, Ambient-Schicht | Dialog im Beschreibungstext versteckt |
Fertiges Beispiel: Die Anatomie eines perfekten Renders
Aufgrund regionaler API-Beschränkungen und Warteschlangen auf der nativen Kling-Plattform ist die Nutzung der einheitlichen kling-v2.6-std-avatar-Pipeline auf Atlas Cloud der zuverlässigste Weg für automatisierte Massenproduktion. Obwohl diese Stufe auf ein statisches Talking-Head-Format statt auf dynamische Szenen mit mehreren Akteuren beschränkt ist, ist sie exzellent in der präzisen phonetischen Zuordnung.
Um die Autorität unserer Kernformel zu beweisen, haben wir die obige Blaupause durch Kling 2.6 (kwaivgi-kling-v2.6-std-avatar-Stufe) über die Atlas Cloud Orchestrierungsplattform laufen lassen. Der 2-sekündige Clip oben repräsentiert den unbearbeiteten, kommerziellen Single-Pass-Output.
Lassen Sie uns aufschlüsseln, warum dieser Render makellose Natürlichkeit erreicht, anstatt in das "Uncanny Valley" zu fallen:
- Bildkomposition (Frame 0): Durch ein Ausgangsbild, bei dem die Moderatorin bereits mit der Smartwatch an der Wange positioniert war, haben wir das Risiko von Gliedmaßen-Verzerrungen eliminiert. Die KI muss keine komplexe Knochenmechanik erraten; sie animiert nur die Mikromimik.
- Phonetische Lip-Sync-Genauigkeit: Beachten Sie, wie die Lippenbewegungen und das Zahn-Tracking der Moderatorin perfekt mit den schnellen Silbenwechseln von „Zero lag. All day battery.“ übereinstimmen.
- Filmische Beleuchtung & Tiefe: Die geringe Schärfentiefe (cremiges Hintergrund-Bokeh) filtert Hintergrundgeräusche stark heraus und zwingt die KI-Pipelines dazu, 100 % ihrer Rechenleistung auf das Rendern realistischer Hautporen und scharfer Kleidungstexturen zu konzentrieren.
Dauer und das Audiofenster
Zu wissen, was die maximale Clip-Länge von Kling AI ist, ist wichtig für die Audio-Planung. Aktuelle Outputs sind auf 10 Sekunden begrenzt. Für eine Produktdemo wie das Beispiel oben sind 10 Sekunden die richtige Wahl: Sie geben dem Voiceover Raum, sauber zu enden, ohne das letzte Wort abzuschneiden. Fünf-Sekunden-Clips eignen sich für reine Atmosphäre oder Aktions-SFX-Paarungen, bei denen keine gesprochene Zeile zu Ende geführt werden muss.
Planen Sie Ihre Skriptlänge basierend auf Ihrer Cliplänge, bevor Sie den Prompt schreiben, nicht danach.
Image-to-Video-Workflow: Wahrung der Charakterkonsistenz mit Kling Motion Control
Für professionelle Ersteller ist der Text-zu-Video-Pfad nur ein Einstiegspunkt. Der Kling Image-to-Video-Workflow ist der Ort, an dem ernsthafter, charaktergetriebener Content entsteht. In Kombination mit der Kling 2.6 Motion Control erhalten Sie eine Konsistenz, die durch reine Textprompts einfach nicht erreicht werden kann.
Wie die I2V-Pipeline die Identität verankert
Wenn Sie ein Referenzbild im „Image-to-Audio-Visual“-Modus hochladen, dient dies als visueller Vertrag mit dem Modell. Das Eingabebild spezifiziert Aussehen, Komposition, Stil und andere visuelle Merkmale des Subjekts, wodurch das generierte Video näher am Originalbild liegt. Dies ist die Grundlage der KI-Charakterkonsistenz: Das Modell behandelt das hochgeladene Gesicht, die Kleidung und die Bildsprache als feste Vorgaben, nicht als Vorschläge.
Dies ist besonders wichtig für:
- Markenbotschafter-Content, der dasselbe Gesicht über mehrere Clips hinweg erfordert
- IP-Charaktere, die ihr Aussehen über Szenen hinweg beibehalten müssen
- Hosts für Produktdemos, bei denen die visuelle Identität Teil des Assets ist
Motion Control: Projektion physischer Daten
Ein Referenzbild fixiert das Aussehen. Die Kling 2.6 Motion Control fügt die physische Ebene hinzu, indem Gestik-, Haltungs- und Bewegungsdaten von einer Bewegungsreferenz auf den generierten Charakter projiziert werden. Die Bewegungsreferenz fungiert als Performance-Vorlage, wobei das Modell die Körpermechanik überträgt und dabei die durch das Eingabebild verankerte visuelle Identität bewahrt.
Diese Trennung von Identität (Bild) und Bewegung (Referenzclip) macht den Ansatz der KI-Animation per Referenzvideo zuverlässiger als das bloße Beschreiben von Bewegungen in Textform.
Lip-Sync und Audio-Ausrichtung in I2V
Kling 2.6 Lip-Sync wird nativ verarbeitet, wenn „Native Audio“ im „Image-to-Video“-Modus aktiviert ist. Das Voice-Control-Feature erlaubt Ihnen, eine spezifische Stimme an einen Charakter im Format [Charakter@Stimmenname] zu binden, wodurch das Modell Stimmcharakteristiken präzise replizieren kann, um den spezifizierten Inhalt vorzutragen.
| Eingabeebene | Was sie steuert |
| Referenzbild | Gesicht, Kleidung, Bildausschnitt, visueller Stil |
| Bewegungsreferenz | Gestik, Haltungswechsel, Körperrhythmus |
| Voice Control-Bindung | Klangfarbe, Vortragsstil, sprachübergreifende Konsistenz |
| Prompt-Audio-Block | Dialoginhalt, Emotions-Tag, Ambient-Schicht |
Fertiges Beispiel: Anwendung der Kernformel auf Image-to-Video (I2V)-Workflows
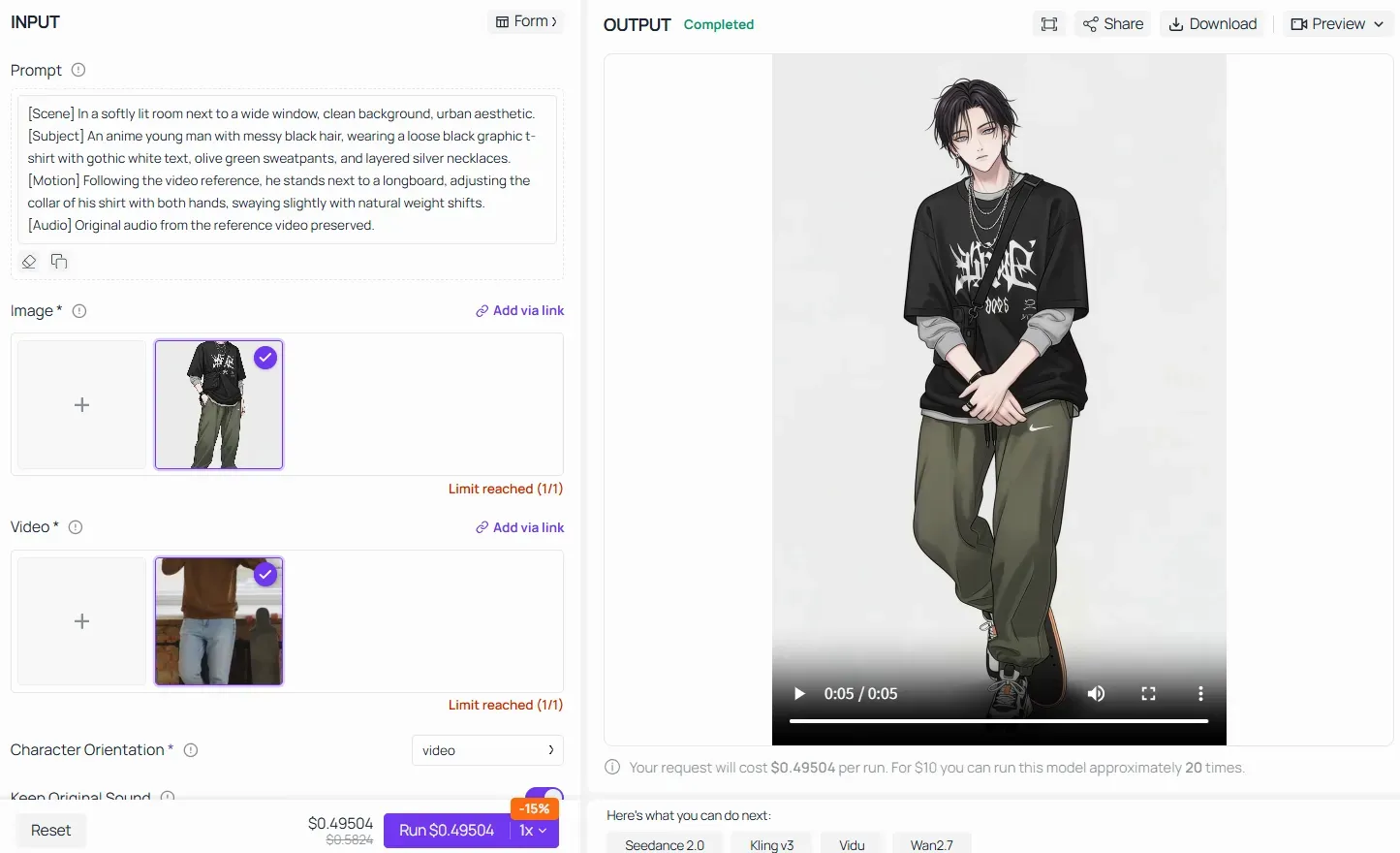
Bei der Nutzung fortschrittlicher Funktionen wie Video-Referenz / Motion Transfer auf Plattformen wie Atlas Cloud behält die Kernformel ihre absolute Gültigkeit. Statt der KI vage Anweisungen wie „lass den Anime-Charakter denselben Tanz machen“ zu geben, müssen Sie den Prompt strukturieren, indem Sie die Szene aufschlüsseln, die hochgeladenen Merkmale des Subjekts fixieren und das Motion-Mapping festlegen:
Indem Sie jeden Block der Pipeline ausfüllen, stellen Sie sicher, dass das KI-Modell die schwere physische Knochenmechanik nahtlos aus dem realen Video auf das hochgeladene Anime-Asset überträgt, ohne dessen visuelle Identität zu zerstören.
Faustregel für Motion Control in Kling 2.6: Ihr Text-Prompt muss sich nicht um kleine mechanische Details sorgen (wie „Arm um 45 Grad nach oben bewegen“). Lassen Sie das Referenzvideo die Schwerstarbeit für die Kinematik leisten. Nutzen Sie stattdessen Ihre [Subjekt]- und [Szene]-Blöcke, um den visuellen Stil, die Texturen und die Farbpaletten knallhart zu fixieren. So stellen Sie sicher, dass die KI die Performance überträgt, ohne die Identität des Originalbildes zu verzerren.
Bildqualität und praktische Grenzen
Beachten Sie eine wichtige Regel: Ihr finales Video sieht nur so gut aus wie das Bild, das Sie hochladen.
Verwenden Sie immer hochauflösende Bilder. Niedrigauflösende Bilder führen zu körnigen und unscharfen Videos. Die KI kann diese unsauberen Details später nicht korrigieren. Dieses Problem fällt bei Nahaufnahmen von Gesichtern besonders stark auf.
Verwenden Sie ein hochauflösendes Quellbild, damit die Charakterkonsistenz sowohl über 5-sekündige als auch über 10-sekündige Ausgabefenster ohne Qualitätsverlust erhalten bleibt.
Technische Fehlersuche: Lösung von Generierungsengpässen und Audio-Drift
Selbst erfahrene Ersteller stoßen bei Kling 2.6 auf Reibungspunkte. Die zwei am häufigsten gemeldeten Probleme sind Generierungen, die mitten im Prozess stecken bleiben, und Dialoge, die nach der Hälfte des Clips die Synchronität verlieren. Beide haben identifizierbare Ursachen und praktische Lösungen.
Warum Kling bei 99 % hängen bleibt
Wenn Ihr Video bei 99 % stecken bleibt, hat das meist zwei Gründe. Erstens könnten die Server überlastet sein. Zweitens könnte Ihr Prompt zu kompliziert für das System sein. Die KI versucht, alle Sounds und visuellen Elemente exakt zur gleichen Zeit zu erstellen. Wenn Sie zu viel in Ihren Prompt packen, kollidieren die Anweisungen. Diese Verwirrung verlangsamt das System oder lässt es komplett einfrieren.
Lösungsansätze:
- Versuchen Sie es später erneut. Aktualisieren Sie die Seite und reichen Sie den Prompt zu ruhigeren Zeiten ein. Früher Morgen ist meist am besten.
- Vereinfachen Sie den Prompt. Teilen Sie einen komplizierten Prompt in zwei kleinere auf. Lassen Sie sie als separate Videogenerierungen laufen.
- Entfernen Sie gestapelte Umgebungsbeschreibungen und behalten Sie eine dominante Sound-Ebene pro Clip bei.
- Reduzieren Sie die Anzahl der Charaktere, wenn Sie drei oder mehr Sprecher in einer einzigen Generierung verwenden.
So beheben Sie Dialog-Drift
Beheben Sie Dialog-Drifts, indem Sie die Grundursache angehen: Die Multi-Sprecher-Verarbeitung des Modells lässt nach der 5- bis 6-Sekunden-Marke nach, wenn zu viele Stimm-Anweisungen konkurrieren. Die Leistung kann in Szenen mit drei oder mehr Charakteren sinken.
| Szenario | Empfohlene Lösung |
| Dialog mit zwei Sprechern über 10s | 10s-Dauer mit klaren Sprecherwechsel-Hinweisen nutzen |
| Drei oder mehr Sprecher | In separate Clips pro Sprecherpaar aufteilen |
| Langer Monolog drifftet | Skript kürzen, damit es bequem in das 10s-Fenster passt |
| Gesang bricht ab | Immer den 10s-Parameter für musikalische Inhalte nutzen |
Reduzierung von Artefakten und Optimierung von Credits
Um Generierungsartefakte zu reduzieren, halten Sie die Image-to-Video-Quelldateien hochauflösend und vermeiden Sie widersprüchliche Szenenbeschreibungen. Zur Optimierung des Credit-Verbrauchs: Beachten Sie, dass die Aktivierung von „Native Audio“ im Professional-Modus 10 Credits pro Sekunde kostet, gegenüber 5 Credits pro Sekunde ohne Audio. Entwerfen Sie Entwürfe ohne Audio und aktivieren Sie es erst für das finale Rendering, um Ihr Budget für Plattformbeschränkungen besser zu verwalten.
Kling 2.6 vs. Kling 3.0 vs. Wan 2.6 vs. Veo 3.1: Der direkte Vergleich
Erwarten Sie nicht, dass ein KI-Video-Tool absolut alles kann. Wenn Sie integriertes Audio wünschen, hängt die „beste“ Wahl von Ihrem Budget, Ihrem Workflow und den tatsächlichen Anforderungen Ihres Videoclips ab.
Funktionsvergleich auf einen Blick
| Feature | Kling 2.6 | Kling 3.0 | Wan 2.6 | Veo 3.1 |
| Natives Audio | Voll (Dialog/SFX/Ambience) | Voll (Single-Pass Sync) | Voll (inkl. Lip Sync) | Voll (3D Spatial Audio) |
| Max. Clip-Länge | 10s | 15s | 15s | 8s |
| Max. Auflösung | 1080p | Nativ 4K | 1080p | Nativ 4K |
| Motion Control | Stark (Skelett/Video-Referenz) | Stark (Volle Identitäts-Sperre) | Moderat (Stil/Motion-Transfer) | Moderat (Fluiddynamik-Physik) |
| Multi-Shot | Nein | Ja (Bis zu 6 Shots im Durchgang) | Ja (Multi-Szenen-Support) | Nein |
| Voice Control | Ja | Ja | Nein (Prompt-abhängig) | Nein (Prompt-abhängig) |
| Preise | $0.048 - $0.095/s | $0.071 - $0.357/s | $0.018 - $0.7/s | $0.05 - $0.2/s |
Hinweis: Die Preise beziehen sich auf Atlas Cloud.
Wo Kling 2.6 die Nase vorn hat
Kling 2.6 vs. Wan 2.6 ist beim Thema Audio kein knappes Rennen. Wan 2.6 hat nur eine teilweise Audio-Unterstützung, während Kling 2.6 vollständige native Dialoge, SFX und Ambient-Ebenen in einem Durchgang liefert. Für Ersteller, die komplette, soundfertige Clips ohne Postproduktion benötigen, ist Kling 2.6 der sauberere Workflow.
Kling 2.6 kostet über 50 % weniger als Veo 3.1. Wenn Sie keine Videoqualität auf Hollywood-Niveau benötigen, ist Kling die klügere Wahl. Es ermöglicht Ihnen, große Mengen an Content zu erstellen, ohne Ihr Budget zu sprengen.
Wo Veo 3.1 die Nase vorn hat
Veo 3.1 vs. Kling Video läuft auf Realismus und Audio-Spatialisierung hinaus. Veo 3.1 generiert dreidimensionale Soundumgebungen, in denen sich Audioquellen durch das Stereofeld bewegen, mit 48 kHz und Stereo-AAC-Kodierung bei 192 kbps. Stand März 2026 bietet kein anderes großes KI-Videomodell dieses Level an Audio-Spatialisierung. Für Dialoge in Broadcast-Qualität und Text-Rendering bleibt Veo 3.1 die stärkere Wahl.
Vergleich der KI-Video-Physik
Bei der KI-Video-Physik unterscheiden sich die Modelle deutlich. Kling 2.6 liefert exzellente Bewegungsflüssigkeit mit einer Physiksimulation, die für menschliche Bewegungen realistischer wirkt, während Veo 3.1 gelegentliche physikalische Inkonsistenzen zeigt, aber bei Beleuchtung und Texturen glänzt.
Entscheidungsrahmen
- Wählen Sie Kling 2.6 für: sprachgesteuerte Charaktere, budgetbewusste Produktion, Social-Content, komplette audiovisuelle Ausgabe in einem Durchgang.
- Wählen Sie Kling 3.0 für: längere filmische Aufnahmen, Storyboards mit mehreren Szenen, 4K-Output.
- Wählen Sie Wan 2.6 für: Open-Source, kostenlose Iterationen und Entwurfstests.
- Wählen Sie Veo 3.1 für: Spatial Audio, Text-Rendering, fotorealistische Produktanzeigen.
Fazit: Der neue Rhythmus des KI-Filmemachens
Die traditionelle Videoproduktionskette – visuelle Daten exportieren, Voiceover separat generieren, Soundeffekte unterlegen und dann alles in der Postproduktion mischen – gilt bei der Verwendung von Kling 2.6 nicht mehr. Die gesamte Sequenz lässt sich nun in eine einzige Prompt-Eingabe zusammenfassen.
Ersteller, die am schnellsten vorankommen, sind diejenigen, die das Schreiben von Prompts als Regiearbeit und nicht als Suchanfrage behandeln. Der eigentliche Trick für Video auf Profi-Niveau ist einfach: Packen Sie Ihre Szenen-, Subjekt-, Bewegungs- und Soundpläne in einen klaren Prompt.
Aktuell ist Kling 2.6 eines der besten verfügbaren Tools. Es funktioniert großartig für große Content-Teams, Solo-Ersteller und Marketing-Studios, die schnelles, hochwertiges Video benötigen. Die technische Decke wird weiter steigen. Die Beherrschung der Prompt-Struktur baut heute das kreative Fundament, um mit dieser Entwicklung zu wachsen.






