
MiniMax hat gerade eine 15,6-fache Dekodier-Beschleunigung bei 1M Token angeteasert. Sollte dieser Wert Bestand haben, sinken die Kosten für die Ausführung von Kontexten mit einer Million Token um nahezu eine Größenordnung – und die Generierung wird dabei sogar schneller statt langsamer.
Für alle, die auf diesen Modellen aufbauen, verschiebt sich damit die Grenze des Wirtschaftlichen. Workloads, die sich bisher nicht rechneten, werden plötzlich machbar: einem Coding-Agenten die gesamte Codebasis statt nur Fragmente zu übergeben, stundenlange Agenten-Runs mit riesigen Historien oder Retrieval über ganze Dokumentensätze anstatt zerstückelter Ausschnitte. Die Frage, mit der jedes Team kämpft – wie viel kann ich in das Kontextfenster stopfen, bevor die Rechnung oder die Latenz das Produkt killt? – bekommt eine deutlich höhere Obergrenze.
Der Mechanismus dahinter ist Sparse Attention, und MiniMax ist damit nicht allein. DeepSeek hat es über drei Modellreihen hinweg implementiert, Qwen hat eine eigene Version, und jetzt folgt MiniMax. Die Richtung ist vorgegeben. Was sich ändert, sind die Konsequenzen: Wenn jedes Frontier-Modell langen Kontext günstig verarbeiten kann, hört das Modell selbst auf, der Burggraben zu sein – und genau das ist der Punkt, der Ihre Aufmerksamkeit verdient, worauf wir am Ende zurückkommen werden.
Zuerst zwei ehrliche Vorbehalte, denn sie sind für jeden wichtig, der dies tatsächlich einsetzen möchte:
- Es handelt sich um MiniMax' eigene Zahlen aus einer einzigen Teaser-Grafik eines noch nicht veröffentlichten Modells auf deren Hardware-Setup. Ein starkes Signal für die Richtung – kein Benchmark eines Drittanbieters. Betrachten Sie sie als „Behauptungen von MiniMax“ und testen Sie sie an Ihrem eigenen Workload, sobald die Weights verfügbar sind.
- M3 ist noch nicht öffentlich. Wir erwarten, es bei Atlas Cloud mit Day-Zero-Zugang bereitzustellen, sobald es erscheint – mehr dazu am Ende.
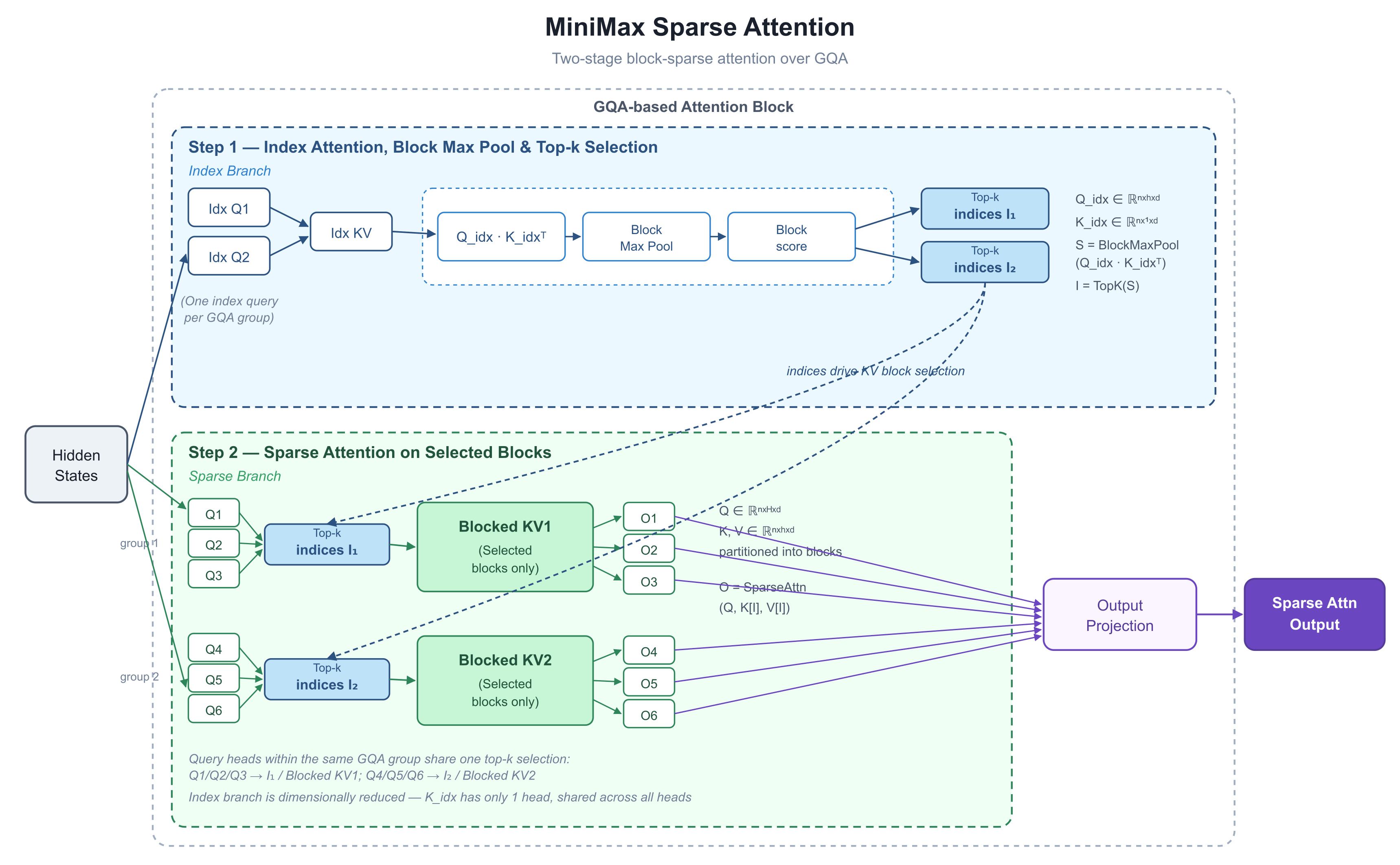
Wie schafft MiniMax das? Am 26. Mai postete Skyler Miao, Leiter der F&E bei MiniMax, ein Diagramm auf X – zurückhaltende Farbpalette, viel Inhalt – mit dem Titel MiniMax Sparse Attention. Zwei Kurven lieferten die Zahlen, auf die sich alle stürzten: 9,7× schnellere Prefill, 15,6× schnellere Dekodierung bei 1M Token. Die Community war sich fast einig, dass es sich um den M3-Teaser handelt. Wir haben das Diagramm analysiert, um die Architektur hinter diesen Zahlen zu verstehen.
Ein wenig Grundlagen vor der Analyse. Drei Begriffe machen die ganze Geschichte aus:
- Prefill ist der Durchgang, bei dem ein Modell Ihren Input in einem Rutsch liest.
- Decode ist die langsamere, Token-für-Token-Phase, in der es den Output schreibt – und bei langem Kontext ist die Dekodierung das Nadelöhr, da jedes neue Token auf alles Vorherige zurückblickt.
- Sparse Attention ist die Lösung: Statt dass jedes Token auf jedes andere Token achtet (der Standardfall, dessen Kosten mit dem Quadrat der Sequenzlänge wachsen), beachtet das Modell nur eine sorgfältig ausgewählte Untermenge – und bewahrt so den Großteil der Qualität bei einem Bruchteil der Rechenlast. Wie man diese Untermenge auswählt, unterscheidet die einzelnen Labore voneinander.
Und der Grund, warum dieser Teaser Gewicht hat: Im Oktober veröffentlichte MiniMax einen Beitrag mit dem Titel Why Did M2 End Up as a Full Attention Model? – ungewöhnlich direkt wurde erklärt, dass M2 auf die effiziente „Lightning Attention“ von M1 verzichtet habe, weil effiziente Attention noch nicht produktionsreif war. Sechs Monate später taucht M3 mit Sparse Attention im Zentrum auf. Der Subtext ist ein einziger Satz: Dieses Mal ist sie es.
1. Was das Diagramm zeigt: zwei Stufen – auswählen, bevor man rechnet
Das Diagramm zeigt die interne Entfaltung eines einzelnen Attention-Blocks. Der entscheidende Schritt ist die Trennung von „welche Token beachtet werden“ und „wie die Attention darüber berechnet wird“ in zwei klar voneinander getrennte Schritte.
Ein Hinweis zum Substrat, da es immer wieder vorkommt: M3 basiert auf GQA – Grouped-Query Attention. In einer Standard-Attention-Schicht trägt jeder „Query-Head“ seine eigene Menge an Keys und Values, was ausdrucksstark ist, aber den KV-Cache (den Key/Value-Cache – die gespeicherten Keys und Values aller vorherigen Token, damit sie nicht bei jedem Schritt neu berechnet werden müssen) aufbläht. GQA unterteilt Query-Heads in Gruppen, und jede Gruppe teilt sich einen Satz an Keys und Values. Es ist das gängige speichersparende Layout, das heute in den meisten Produktionsmodellen verwendet wird. Behalten Sie das im Hinterkopf – es ist das Fundament des gesamten Designs.
Schritt 1: Index-Branch – alles günstig bewerten
Die obere Hälfte ist der Index-Branch. Er läuft neben dem Hauptpfad mit einer einzigen Aufgabe: Dem Rest des Blocks mitzuteilen, welche Token-Blöcke einen Blick wert sind.
Jede GQA-Gruppe teilt sich eine Index-Query (das Diagramm zeigt sechs echte Heads, gepaart mit zwei Index-Queries, „Idx Q“ – eine pro Gruppe). Die Key-Seite dieses Zweigs ist bewusst reduziert:

Beachten Sie, dass K_idx nur einen Head hat – jeder Head teilt sich denselben Index-Key. Das macht den Bewertungsschritt (Q_idx · K_idxᵀ) nahezu kostenlos.
Block Max Pool komprimiert dann diese Token-Level-Scores in Block-Level-Scores (die Sequenz wird in Blöcke fester Größe unterteilt und der Top-Score pro Block beibehalten):

Schließlich entscheidet TopK – „behalte die k höchstbewerteten Elemente“ – welche KV-Blöcke für diese Schicht und diese Gruppe überleben. Das Ergebnis ist eine kurze Liste von Indizes: I₁, I₂.
Schritt 2: Sparse-Branch – wo die eigentliche Attention läuft
Die untere Hälfte ist die tatsächliche Berechnung. Die Queries, Keys und Values liegen weiterhin in der Standard-GQA-Form vor. Unter Verwendung von I₁ und I₂ aus Schritt 1 zieht der Block nur die ausgewählten Untermengen aus den vollständigen Keys und Values und führt die Attention nur über diese aus:

Die wichtigste Designentscheidung: Jeder Query-Head in einer Gruppe teilt sich eine einzige Top-K-Auswahl. Im Diagramm verwenden Q1/Q2/Q3 alle I₁; Q4/Q5/Q6 verwenden alle I₂. Das ist das Hardware-Alignment-Prinzip, auf dem das NSA-Paper von DeepSeek beharrt – eine Gruppe von Queries lädt einen Satz an KV-Blöcken, dieser Satz passt in einem einzigen Durchgang in den SRAM (den kleinen, extrem schnellen On-Chip-Speicher der GPU), und Standard-Kernels im FlashAttention-Stil (die dominierende optimierte Attention-Implementierung) können unverändert wiederverwendet werden.
2. Drei bewusste Abgrenzungen gegenüber der DeepSeek-Familie
Die Community hat dies sofort mit den drei Sparse-Attention-Designs von DeepSeek verglichen:
- NSA — Native Sparse Attention. „Native“ bedeutet, dass die Sparsity von Beginn des Vortrainings an implementiert wurde und nicht nachträglich hinzugefügt wurde. Drei parallele Zweige (Komprimierung + Auswahl + Sliding Window) plus ein gelernter Gate.
- DSA — DeepSeek Sparse Attention. Die Variante, die in DeepSeek V3.2 ausgeliefert wurde; Token-Level-Auswahl mit einem sehr leichten Indexer.
- CSA — Community-Kürzel für die Block-Level-Ausrichtung, die mit DeepSeek V4 assoziiert wird. (Diese Bezeichnung ist weniger standardisiert als NSA/DSA, also betrachten Sie es eher als Arbeitstitel denn als offiziellen Begriff.)
Die knappe Einschätzung der Community: M3 verwendet GQA statt MLA, Block-Level-Auswahl im Geiste von CSA, aber die Attention-Berechnung erfolgt auf den echten Keys und Values.
Als Tabelle erweitert:
| Dimension | DeepSeek V3.2 DSA | DeepSeek NSA | DeepSeek V4 CSA | MiniMax M3 (abgeleitet) |
|---|---|---|---|---|
| KV-Substrat | MLA (latent) | GQA | MLA | GQA |
| Granularität der Auswahl | Token-Level | Block-Level | Block-Level | Block-Level |
| Parallele Zweige | 1 (Indexer + Select) | 3 (Compress + Select + Sliding) | 1 | 1 (nur Select) |
| Wo die Attention läuft | Echte K/V | Drei-Wege-Fusion | Komprimierte KV | Echte K/V |
| Indexer-Kosten | Lightning Indexer | Komprimierungs-Zweig | Block-Summaries | Single-Head K + Block Max Pool |
| Gating | keine | gelernter Gate | keine | keine |
Diese Tabelle verbirgt ein weiteres Akronym, das eine Definition wert ist: MLA — Multi-head Latent Attention, DeepSeeks Markenzeichen. Anstatt vollständige Keys und Values zu cachen, komprimiert MLA sie in einen kleinen geteilten „Latent“-Vektor, cached diesen und dekomprimiert bei Bedarf. Der KV-Cache schrumpft dramatisch – aber die Mathematik entspricht nicht mehr der Standard-Attention, daher sind spezielle Kernels erforderlich. Dieser Kontrast treibt den ersten der drei Trade-offs von M3 an.
Erste Abgrenzung: GQA als Substrat, nicht MLA. Da M3 bei einfachem GQA bleibt, funktioniert der Standard-Serving-Stack – vLLM und SGLang (die zwei weit verbreiteten Open-Source-Inference-Server) plus FlashAttention – mit wenig bis gar keiner Modifikation. Kein technischer Aufwand, um den latenten KV-Cache von MLA zu umgehen. Für ein Labor, das „produktionsreif“ anstrebt, ist dies der Weg mit dem geringsten Risiko. Dies ist die geschäftlich am besten nachvollziehbare Idee im gesamten Design: MiniMax hat sich für das optimiert, was sofort auf der Hardware und Software läuft, die bereits jeder hat.
Zweite Abgrenzung: Block-Level-Auswahl, aber Attention läuft auf den echten Keys und Values. Im Gegensatz zu CSA, das die Attention über komprimierte KV berechnet, behält M3 die volle Ausdrucksstärke der Standard-Softmax-Attention bei. Der Preis: Der KV-Cache schrumpft nicht zusammen mit der Sparsifizierung – aber etwas Speicher gegen den Erhalt der Qualität zu tauschen, ist ein sinnvoller Handel.
Dritte Abgrenzung: Die anderen beiden Zweige von NSA sind verschwunden. NSA führt drei parallele Pfade aus (Komprimierung + Auswahl + Sliding Window) plus ein gelernter Gate. M3 behält nur die Auswahl bei. Eine Zusammenfassung der Community nannte es eine „gestraffte, vereinfachte NSA“. Kurz gesagt: Engineering zuerst. Von den beiden weggelassenen Zweigen wird der Sliding Window wahrscheinlich durch RoPE (Rotary Position Embedding – der Standard, wie Modelle Token-Positionen kodieren) plus einen Attention-Sink ersetzt, oder einfach durch dichte Attention als Fallback pro Schicht, so wie es Gemma 3 und Qwen3-Next handhaben. Der Komprimierungszweig geht im minimalen „Single-Head K + Block Max Pool“ auf.
3. Wie man die Zahlen liest
| Phase | Beschleunigung bei 1M | Was das bedeutet |
|---|---|---|
| Prefill | 9,7× | Verarbeitung von 1M Token Input in einem Durchgang |
| Decode | 15,6× | Generierung Token für Token |
Dass die Dekodierung die Prefill-Phase überholt, ist logisch. Während des Prefills muss der Index-Branch immer noch die volle Input-Länge scannen, daher wirken sich die Einsparungen nur auf die Haupt-Attention aus. Während der Dekodierung interagiert jedes neue Token nur noch mit seinen ausgewählten KV-Blöcken, und der Druck auf die Speicherbandbreite des KV-Caches sinkt um etwa eine Größenordnung – genau dort, wo die Kosten der Dekodierung liegen.
Rechnet man das Auswahlverhältnis zurück: Nehmen wir eine Blockgröße von 64 Token an, dann entsprechen 1M Token ca. 16.000 Blöcken. Eine 15,6-fache Dekodier-Beschleunigung impliziert, dass jede Query tatsächlich nur etwa 6–7 % der Blöcke berührt – ein effektives rezeptives Feld von etwa 60k–70k Token. Dieses Verhältnis liegt fast exakt auf der Sparsity-Rate, die das NSA-Paper berichtet (6–10 %). Kein Zufall – das ist der „Sweet Spot“ für diese Art von Design bei einem 1M-Maßstab.
4. Ableitungen zum Rest von M3
Extrapoliert man diesen einen Attention-Block auf das vollständige Modell – klar als Inferenz gelabelt, da ein Diagramm nur einen Ausschnitt zeigt:
- Das MoE-Rückgrat bleibt wahrscheinlich.MoE – Mixture of Experts – ist das Rückgrat des Modells (getrennt von der Attention): Statt jedes Token durch ein riesiges Netzwerk zu schicken, leitet ein Router jedes Token an einige wenige spezialisierte „Experten“-Subnetzwerke, sodass man die Qualität eines großen Modells bei der aktiven Rechenleistung eines kleinen Modells erhält. M2 kam mit 230B Gesamtparametern / ca. 10B aktiven / Top-2-Routing; M2.7 hatte bereits die Expertenanzahl auf 256 erhöht. Es gibt keinen Grund für M3, dies aufzugeben – die wahrscheinliche Änderung liegt in einer tieferen und breiteren Struktur.
- Der Full-Attention-Stack wird durch Block-Sparse GQA ersetzt. Es ist unwahrscheinlich, dass die Lightning Attention von M1 zurückkehrt. M3 wettet nicht erneut auf lineare Attention; es schlägt den Weg „Softmax-Ausdrucksstärke + Top-K-Block-Auswahl“ ein – sub-quadratische Kosten bei gleichbleibender Qualität.
- Höchstwahrscheinlich nativ trainierte Sparsity. Dies ist die zentrale Lehre aus dem NSA-Paper: Das Sparse-Muster muss während des Vortrainings in die Gradienten einfließen, sonst wird das Retrieval-Verhalten des Modells beeinträchtigt. MiniMax hat eine eigene Forschungslinie für Retrieval-Heads, daher sollten sie in diese Falle nicht tappen.
- Das Schlachtfeld ist 1M+ Kontext. M1 wurde auf 1M trainiert und bei der Inferenz auf 4M extrapoliert. M3 scheint bereit, dies zu festigen und gleichzeitig die Inferenzkosten massiv zu senken – ein sehr natürlicher Produktzyklus.
5. Einordnung von M3 in das Design-Spektrum 2026
Über den Zeitraum 2025–2026 haben sich Sparse-Attention-Designs schnell auseinanderentwickelt:
- DeepSeek V3.2 DSA: MLA + Token-Level Top-K, sehr leichter Indexer; stabilste Qualität, aber aufwendiges Kernel-Engineering.
- DeepSeek NSA: GQA, drei Zweige + Gate; höchstes Qualitätspotenzial, am komplexesten zu implementieren.
- Qwen3-Next: Schichtweise Mischung aus dichter und linearer Attention; robust, aber relativ konservativ.
- MiniMax M3: GQA + Single-Branch Block-Auswahl; minimal, nutzt den „Hardware-Rückenwind“.
Der Subtext des M3-Designs ist eindeutig: Jage nicht der theoretisch optimalen Attention hinterher – jage derjenigen hinterher, die sofort läuft, schnell ist und die Wiederverwendung bestehender Kernels erlaubt. Es passt zur Entscheidung, bei M2 auf Full-Attention zurückzugreifen: Erst Qualität mit Mainstream-Methoden stabilisieren, dann sauber ersetzen, sobald die Technologie wirklich ausgereift ist.
6. Was das bedeutet, wenn Sie die nächste Welle von KI-Apps bauen
Treten Sie einen Schritt von der Architektur zurück, und man sieht ein größeres Muster. Jedes ernstzunehmende Labor implementiert mittlerweile eine Version von „Trained-in“ Sparse Attention – DeepSeek über drei Linien hinweg, Qwen mit seinem schichtweisen Mix, jetzt MiniMax. Die Richtung ist gesetzt, und die Konsequenz ist einfach: Wenn jedes Frontier-Modell langen Kontext günstig ausführen kann, hört das Modell selbst auf, der Burggraben zu sein. Die reinen Inferenzkosten bewegen sich in Richtung Commodity. Differenzierung findet auf einer höheren Ebene statt – bei der Frage, welches Modell Sie für welchen Workload ausführen, wie Sie dazwischen routen und wie schnell Sie das nächste übernehmen, wenn es sechs Wochen später erscheint.
Das ist ein schwierigeres Problem, als nur den „günstigsten Endpunkt zu finden“. Ein Team, das eine Produktions-App betreibt, balanciert vier Dinge gleichzeitig aus – Qualität, Latenz, Kosten und den geschäftlichen Nutzen, den das Feature tatsächlich vorantreibt – und die richtige Antwort unterscheidet sich je nach Workload und verschiebt sich mit jedem Release-Zyklus. M2 war im Oktober Full-Attention; M3 ist im Mai Block-Sparse. Was auch immer Sie im letzten Quartal angebunden haben, ist bereits einen Schritt hinterher.
Das günstigste Modell zu wählen, ist für Entwickler keine Gewinnerstrategie mehr. Stattdessen werden diejenigen gewinnen, die auf einer Schicht aufbauen, die es ihnen erlaubt, Modelle auszuwählen, zu routen und zu tauschen, ohne jedes Mal neu integrieren zu müssen, wenn sich das Frontier verschiebt – und die ihr Engineering-Budget in ihr eigenes Produkt stecken, statt alle paar Wochen Release-Notes hinterherzujagen.
Genau auf dieser Ebene operiert Atlas Cloud: eine API über mehr als 300 Modelle hinweg, die LLM, Video, Bild und Audio abdeckt, mit intelligentem Routing und Day-Zero-Zugang zu neuen Launches. Dieselbe Linse, die wir benutzt haben, um dieses Diagramm zu zerlegen, nutzen wir, um zu entscheiden, was wir aufnehmen und wie wir es routen. M3 ist noch nicht öffentlich – wenn es erscheint, werden wir es bei Atlas mit Day-Zero-Zugang bereitstellen, damit die Teams, die bereits auf uns aufbauen, es ihren Nutzern am Tag der Veröffentlichung präsentieren können, nicht erst ein Quartal später.
Abschließende Gedanken
Vieles lässt sich aus einem einzigen Diagramm nicht bestätigen: ob das Sparse-Muster Schicht für Schicht gemischt wird, ob es einen dichten Fallback gibt, ob der Index-Branch Embeddings mit dem Hauptnetzwerk teilt, ob das Top-K während des Trainings hart oder weich ist, wie die Loss-Funktion des Index-Branch formuliert ist. All das wartet auf das offizielle Paper oder die Weights.
Aber eines ist bereits klar: Nach DeepSeek hat ein weiteres großes Labor Sparse Attention + langen Kontext + offene Weights zu einem funktionierenden Stack zusammengesetzt. In der zweiten Jahreshälfte 2026 wird 1M Kontext im Open-Source-Bereich wahrscheinlich von einem Verkaufsargument zu einem Standard – und das allein ist wichtiger als jeder einzelne Benchmark.
Referenzen
- Skyler Miao (MiniMax R&D lead), Original-Post auf X: Something BIG is coming — https://x.com/SkylerMiao7/status/2059285750458544561
- Community-Zusammenfassung: MiniMax details its M3 sparse attention architecture — https://digg.com/ai/78gnmbpg
- MiniMax Blog: Why Did M2 End Up as a Full Attention Model? — https://www.minimax.io/news/why-did-m2-end-up-as-a-full-attention-model
- DeepSeek NSA Paper: Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention — https://arxiv.org/pdf/2502.11089
- DeepSeek V3.2 DSA Write-up: Architectural Efficiency in LLMs: DeepSeek-V3.2-Exp and DSA — https://gregrobison.medium.com/architectural-efficiency-in-large-language-models-a-comprehensive-analysis-of-deepseek-v3-2-exp-e9802adfcdbd
- Sebastian Raschka: A Technical Tour of the DeepSeek Models from V3 to V3.2 — https://magazine.sebastianraschka.com/p/technical-deepseek
- MiniMax-01 Tech Report: Scaling Foundation Models with Lightning Attention — https://filecdn.minimax.chat/_Arxiv_MiniMax_01_Report.pdf






