
Starre ID3-Genre-Tags ruin deine lokale Musiksammlung. Indem du die fortschrittliche Audioanalyse von AudioMuse-AI mit der skalierbaren API von AtlasCloud kombinierst, verwandelst du ein statisches Verzeichnis von Mediendateien in eine zutiefst intuitive, semantische Suchmaschine, die emotionsgesteuerte Playlists direkt auf deinen selbst gehosteten Server leitet.
![]()
Die Wärme der Musik zurückgewinnen: Baue eine wirklich intuitive lokale Bibliothek mit AudioMuse-AI
Du sitzt spätabends an deinem Schreibtisch. Du möchtest weder eine energiegeladene Elektro-Playlist hören, noch ist dir nach steriler klassischer Musik zumute. Was du eigentlich willst, ist eine ganz bestimmte Stimmung: „Ruhiger, atmosphärischer Indie-Folk mit dezenten, regnerischen akustischen Untertönen, um runterzukommen.“
Wenn du deine selbst gehostete Navidrome- oder Jellyfin-Instanz öffnest und genau diesen Satz in die Suchleiste eingibst, erhältst du exakt null Ergebnisse.
Seit Jahrzehnten verbringen wir Musikliebhaber unzählige Stunden damit, ID3-Tags akribisch zu organisieren, Coverbilder zu säubern und fließende Kunstformen in starre Genre-Schubladen wie „Rock“, „Jazz“ oder „Pop“ zu zwängen. Aber seien wir ehrlich: Genre-Labels sind ein Relikt aus der Marketing-Ära der Plattenläden des 20. Jahrhunderts. Sie verstehen nicht, wie Musik sich tatsächlich anfühlt.
Die Zukunft der Verwaltung einer privaten Musiksammlung liegt nicht in statischen Metadaten. Sie liegt in der semantischen Audioanalyse. Große Sprachmodelle (LLMs) sind weit mehr als nur Chat-Interfaces; sie sind der ultimative Schlüssel zur Entschlüsselung des unquantifizierbaren emotionalen Gewichts deiner Musik. Durch den Einsatz des Open-Source-Tools AudioMuse-AI in Verbindung mit einem intelligenten LLM-Router wie AtlasCloud kannst du deine lokalen Dateien wieder zum Leben erwecken und Playlists basierend auf purer Stimmung, akustischer Textur und lyrischer Bedeutung generieren.
Was ist AudioMuse-AI?
AudioMuse-AI ist eine selbst gehostete, quelloffene Audio-Intelligence-Engine, die direkt neben deinem bestehenden Medien-Setup läuft. Sie fungiert als KI-gestütztes Gehirn, das direkt mit beliebten selbst gehosteten Musikplattformen wie Jellyfin, Navidrome, LMS/Lyrion und Emby verbunden werden kann.
Anstatt Text-Tags zu parsen, verarbeitet AudioMuse-AI rohe Audiodateien. Es führt lokalisierte neuronale Netzmodelle aus, um komplexe mathematische akustische Vektoren zu extrahieren (unter Verwendung von Contrastive Language-Audio Pretraining, kurz CLAP), und ordnet lyrische Themen in 72 unterstützten Sprachen zu.
Sobald der erste Scan abgeschlossen ist, schaltest du Funktionen frei, gegen die die Algorithmen kommerzieller Streaming-Dienste oberflächlich wirken:
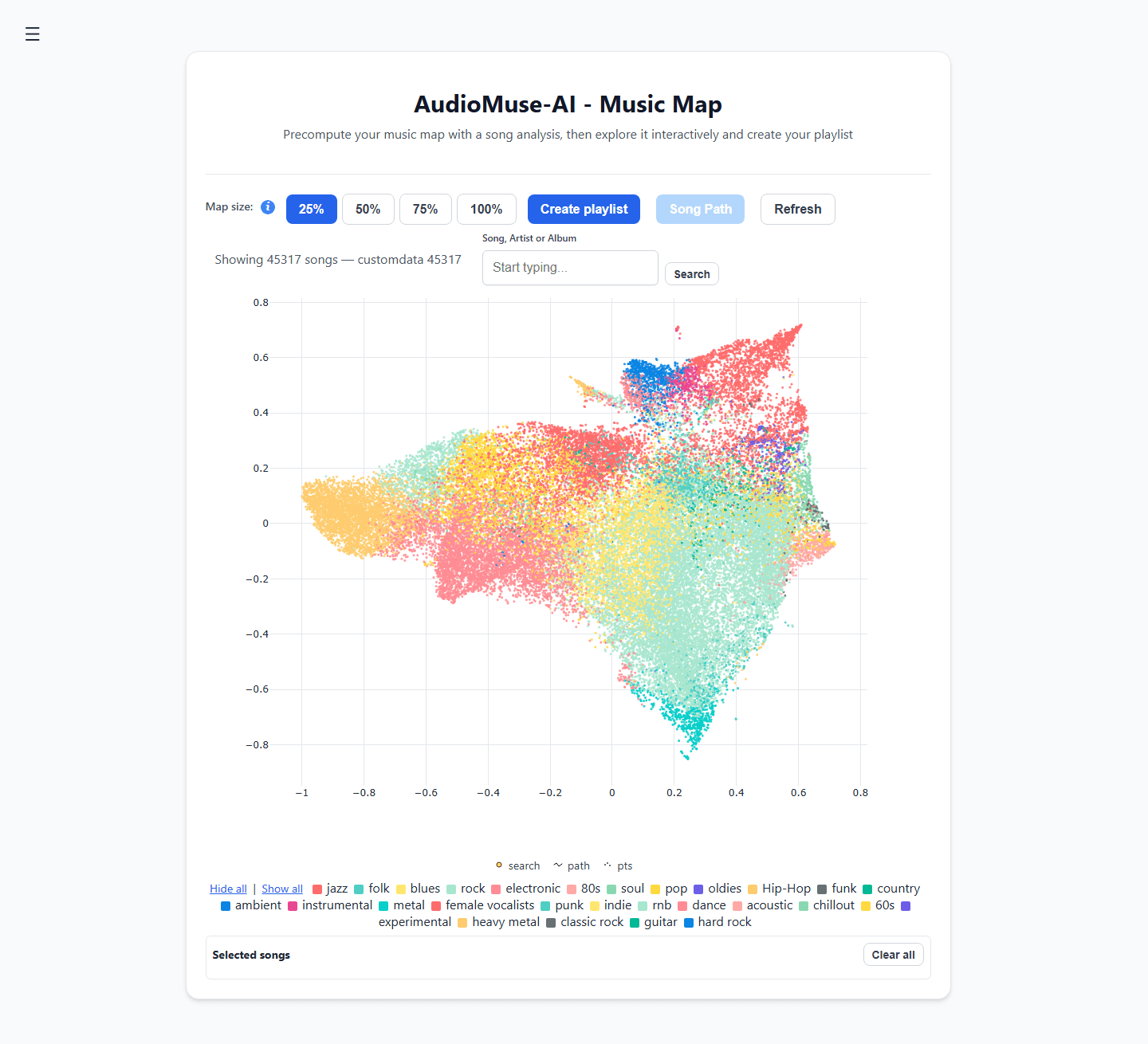
- Akustisches Clustering: Erstellt automatisch eine visuelle, interaktive 2D-„Musikkarte“ deiner Bibliothek und gruppiert Titel nach ihren tatsächlichen Schallwellen statt nach willkürlichen Genres.
- Song-Pfade: Wähle einen schwungvollen Funk-Titel als Startpunkt und ein melancholisches Ambient-Stück als Ziel. Die Engine berechnet automatisch die klangliche Brücke zwischen ihnen und generiert eine Playlist, die die Stimmung schrittweise und nahtlos verändert.
- Semantische Liedtextsuche: Durchsuche deine Bibliothek nach narrativen Themen oder emotionalen Konzepten (z. B. „Lieder über das Aufwachsen in einer Kleinstadt“), anstatt nur nach exakten Übereinstimmungen von Liedtexten zu suchen.
Schritt-für-Schritt-Anleitung: Aufbau deiner semantischen Musik-Suchmaschine
Gehen wir den Aufbau einer vollständigen, Metadaten-freien semantischen Playlist-Pipeline durch.
Schritt 1: Vorbereitung der Umgebung und Bereitstellung
AudioMuse-AI kann nativ auf macOS, Linux und Windows ausgeführt werden, aber für ein Standard-Home-Server- oder NAS-Setup ist Docker Compose der sauberste Weg.
Erstelle ein Verzeichnis auf deinem Server, lade die offizielle docker-compose.yaml aus der Dokumentation herunter und stelle sicher, dass deine Umgebungsdatei korrekt konfiguriert ist.
YAML
plaintext1version: '3.8'services:audiomuse:image: neptunehub/audiomuse-ai:latestcontainer_name: audiomuse-aiports:- "8000:8000"volumes:- /path/to/your/music:/music:ro- ./data:/app/dataenvironment:- POSTGRES_PASSWORD=your_secure_password- REDIS_PASSWORD=your_secure_passwordrestart: unless-stopped
⚠️ Hardware-Hinweis: Die zugrunde liegenden KI-Modelle verlassen sich stark auf moderne CPU-Befehlssätze. Wenn du dies in einer virtualisierten Umgebung wie Proxmox ausführst, stelle sicher, dass dein CPU-Typ auf „Host“ eingestellt ist, um die AVX2-Unterstützung durchzureichen. Wenn du es auf einer generischen QEMU-Virtual-CPU ausführst, stürzt der Container beim Start sofort ab.
Starte es mit folgendem Befehl:
Bash
plaintext1docker compose up -d
Schritt 2: Ausführen des Audio-Framework-Scans
Öffne deinen Browser und navigiere zu http://DEINE-SERVER-IP:8000. Du wirst vom Einrichtungsassistenten begrüßt. Verbinde deinen Medienserver (gib zum Beispiel deine Navidrome-URL und dein persönliches API-Token ein).
Sobald die Verbindung steht, gehe zum Dashboard Analysis and Clustering und klicke auf „Start Analysis“.
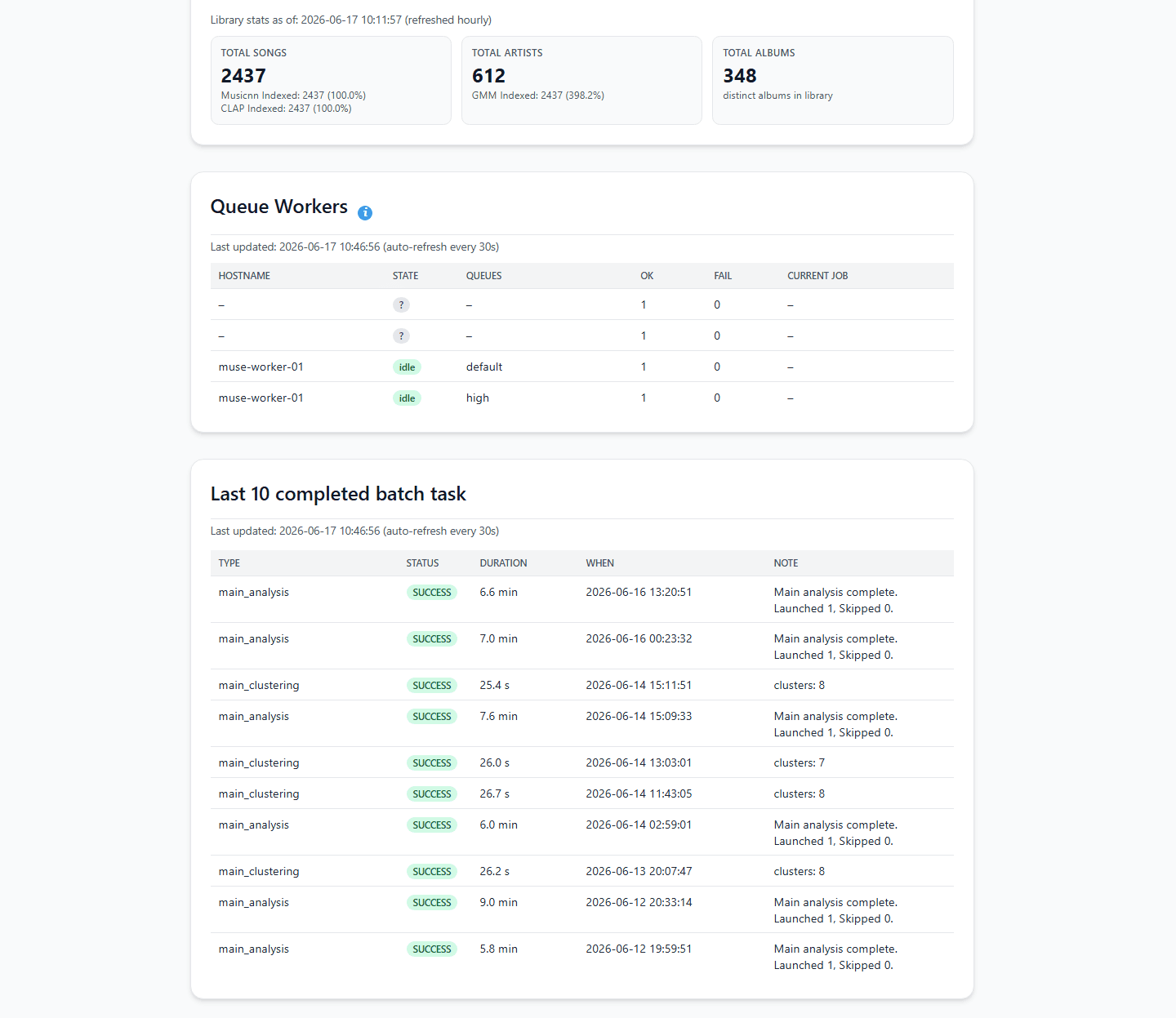
Die Engine beginnt nun mit der Berechnung der akustischen Fingerabdrücke. Je nach Größe deiner Bibliothek und ob du auf einem Intel i5 Mini-PC oder einem Raspberry Pi 5 arbeitest, kann diese erste Analysephase von wenigen Minuten bis zu mehreren Stunden dauern, während die rohen Wellenformen verarbeitet werden.
Schritt 3: Das KI-Gehirn mit AtlasCloud antreiben
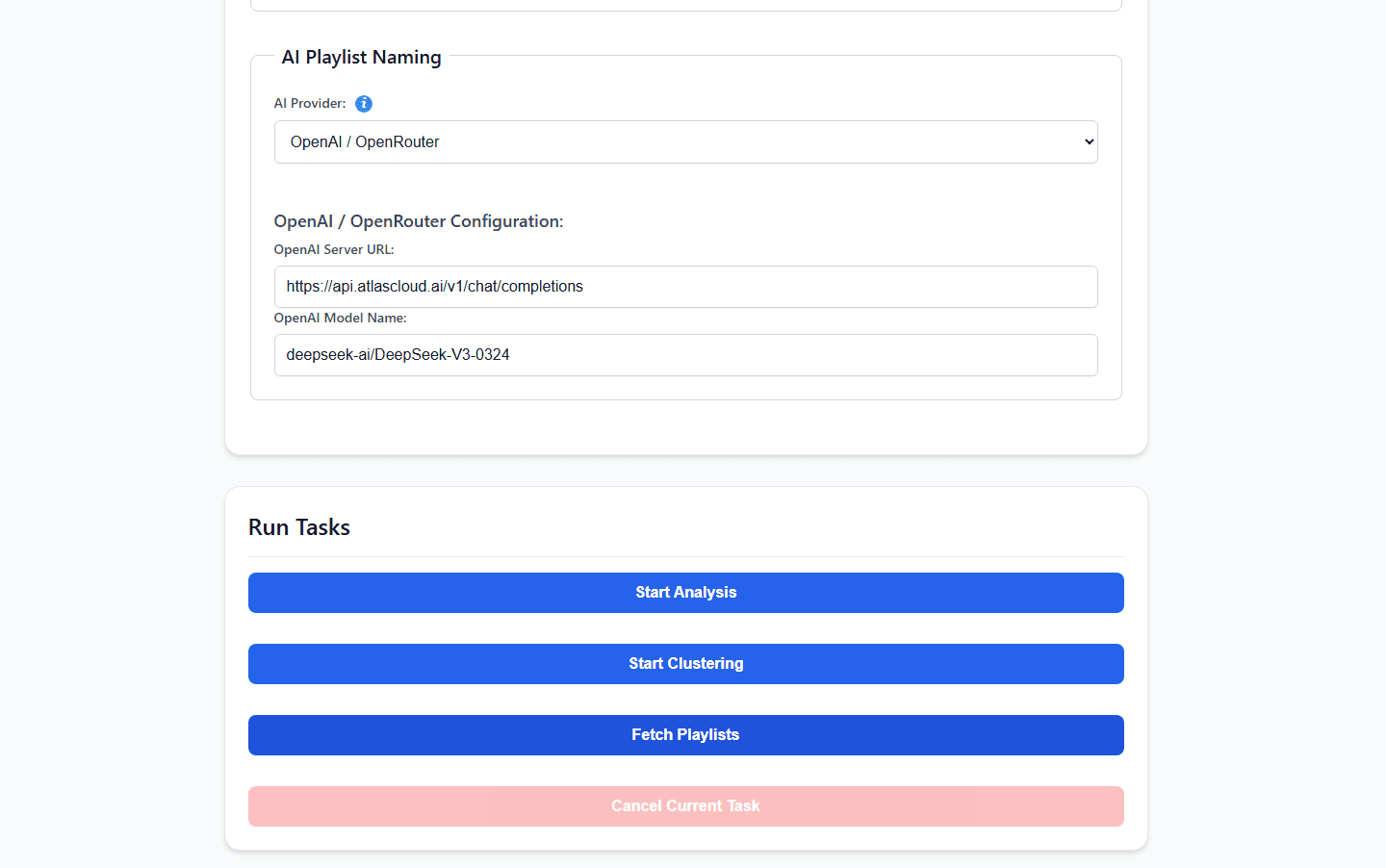
Hier stoßen wir auf einen klassischen Flaschenhals bei selbst gehosteten Systemen. AudioMuse-AI bietet ein interaktives Playlist-Chat-Interface (app_chat.py) und eine Engine für tiefe Lyric-Embeddings. Wenn du massive, komplexe Sprachmodelle lokal ausführst, um diese semantischen Abfragen zu bewältigen, kann dies die CPU deines NAS leicht auf 100 % auslasten, was zu schmerzhaften API-Timeouts und verzögerten Playlist-Generierungen führen kann.
Um deine lokale Hardware leicht, kühl und leise zu halten, können wir die rechenintensive semantische Analyse an eine externe API auslagern. Wie offiziell im OpenAI-kompatiblen KI-Provider-Handbuch des Projekts dokumentiert, kannst du deine Anfragen nahtlos über AtlasCloud leiten, indem du den nativen OPENAI-Core-Provider verwendest.
Füge diese Variablen einfach in deine Server-Umgebungskonfiguration ein:
Bash
plaintext1AI_MODEL_PROVIDER=OPENAI 2OPENAI_SERVER_URL=https://api.atlascloud.ai/v1/chat/completions 3OPENAI_MODEL_NAME=qwen3.5:9b 4OPENAI_API_KEY=your_secure_atlas_cloud_key
Durch die Nutzung von AtlasCloud entfällt die Notwendigkeit, riesige, mehrere Gigabyte große Modelle auf deiner lokalen Festplatte zu verwalten. Ein einziger Schlüssel gibt AudioMuse-AI sofortigen Zugriff auf leistungsstarke Reasoning-Modelle, um deine natürlichsprachlichen Anfragen im Handumdrehen zu analysieren – mit Verarbeitungszeiten im Subsekundenbereich.
Schritt 4: Generiere deine erste „Vibe“-Playlist
Nachdem AtlasCloud nun das semantische Mapping übernimmt, navigiere zum Tab Instant Playlists. Lass uns testen, wie gut das System traditionelle Grenzen überschreitet. Gib eine hochabstrakte Anweisung ein:
„Gib mir einen Vibe für nächtliche Autofahrten bei Regen. Starte akustisch und langsam, aber entwickle dich zum Ende hin zu etwas mit einem treibenden elektronischen Puls.“
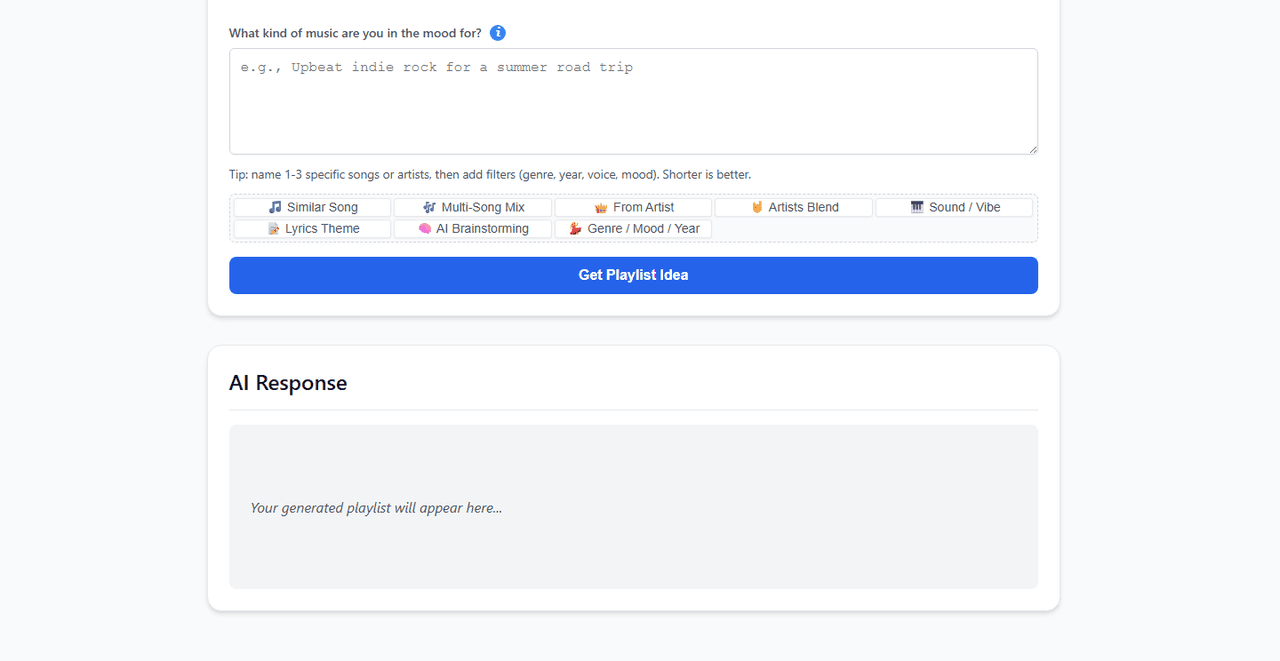
AtlasCloud verarbeitet die grundlegende emotionale Absicht deiner Anweisung, gibt den strukturellen Entwurf an den lokalen Vektorindex von AudioMuse-AI zurück und liefert sofort eine wunderbar kuratierte Auswahl. Klicke auf „Export to Media Server“, und die benutzerdefinierte Playlist wird über Jellyfin oder Navidrome sofort an die Musik-App auf deinem Smartphone übertragen.
Vergleich: Lokale Audio-KI vs. die Konkurrenz
| Feature | AudioMuse-AI + AtlasCloud | Plex / Plexamp | Spotify / Apple Music |
|---|---|---|---|
| Datenschutz & Kontrolle | Volles Eigentum. Daten bleiben lokal; LLM-Anfragen werden sicher per Proxy weitergeleitet. | Teilweise privat. Erfordert proprietären Account und aktiven Plex Pass. | Keine Privatsphäre. Deine Hörlogs werden für Ad-Tracking monetarisiert. |
| Metadaten-Abhängigkeit | Keine. Analysiert direkt rohe Audiowellenformen und Liedtext-Themen. | Hoch. Erfordert akkurate Basis-Tags, bevor die Analyse beginnt. | Absolut. Verlässt sich komplett auf kommerzielle Genre-Tags und Datenbank-IDs. |
| Kaltstart-Performance | Perfekt. Kann obskure lokale Indie-Titel analysieren und sofort zuordnen. | Schlecht. Kontextualisiert Titel nicht, wenn sie nicht in der Plex-Datenbank vorhanden sind. | Schrecklich. Wenn ein Song keine Millionen Streams weltweit hat, ignoriert ihn der Algorithmus. |
| Semantische Suche | Fortgeschritten. Versteht komplexe natürlichsprachliche Anfragen via LLM. | Nicht vorhanden. Auf einfache Filter (Jahr, Genre, Stimmungs-Tags) beschränkt. | Moderat. Gut im Text-Parsing, aber strikt auf den Katalog beschränkt. |
Technische Vorbehalte & Fehlerbehebung
- Der VNNI Lyric Re-Analysis Bug: Wenn du deinen Container-Stack kürzlich auf die neuesten AudioMuse-AI-Builds aktualisiert hast, achte genau auf deine CPU-Architektur. Ältere Revisionen des GTE-Mehrsprachen-Embedding-Modells konnten auf älteren CPUs ohne VNNI-Befehlssätze (Hardware vor 2019) zu fehlerhaften Vektor-Mappings führen. Wenn du auf deinem Linux-Host ausführst und keine Ausgabe erhältst, solltest du deine alten Datenbanktabellen über das PostgreSQL-CLI löschen und einen frischen Lyric-Scan auslösen, um saubere semantische Suchergebnisse zu erhalten.text
1grep -oE 'avx512_vnni\|avx_vnni' /proc/cpuinfo - Timeout-Anpassungen für Medienserver: Beim Synchronisieren riesiger Playlists mit mehr als 500 Titeln zurück nach Navidrome können die anfänglichen Synchronisations-Handshakes die Standard-Proxy-Limits überschreiten. Wenn du in deinen Logs Abbrüche beim Verbindungs-Handshake siehst, überprüfe den offiziellen Parameter-Guide, um die Timeout-Flags deines Servers anzupassen.
Häufig gestellte Fragen (FAQ)
Warum schlägt mein Jellyfin-Verbindungstest bei der Einrichtung fehl?
Dies liegt normalerweise an einer falschen Formatierung der Basis-URL oder einem ungültigen API-Token-Geltungsbereich. Stelle sicher, dass du die vollständige HTTP/HTTPS-Adresse inklusive Port verwendest (z. B.
1http://192.168.1.50:8096Kann ich AudioMuse-AI auf einem alten Server ohne AVX2-Befehlssätze ausführen?
Ja, aber du kannst nicht die Standard-Docker-Images verwenden. Du musst explizit das spezialisierte Docker-Image mit dem Suffix -noavx2 ziehen (z. B.
1neptunehub/audiomuse-ai:latest-noavx2Wie verbessert die AtlasCloud API die Antwortgeschwindigkeit von app_chat.py?
Wenn du mit dem Konversations-Assistenten für Playlists interagierst, muss das System dein Feedback in strukturierte JSON-Schemas umwandeln. Die Verarbeitung dieses Textes auf der CPU eines lokalen Servers kann 10 bis 30 Sekunden pro Nachricht dauern. Das Routen dieser spezifischen Anfragen über einen optimierten Cloud-Partner wie AtlasCloud liefert Antworten in Millisekunden und stellt sicher, dass der Arbeitsspeicher deines lokalen Servers frei bleibt, um hochauflösende FLAC-Dateien ohne Ruckeln zu streamen.






