Claude Code kostet etwa 13 USD pro Entwickler und aktivem Tag. Bei intensiver Automatisierung können diese Kosten zwischen 500 und 2.000 USD pro Ingenieur und Monat liegen (CloudZero, 2026). Für ein Team von 50 Personen ist das ein fünfstelliger Kostenblock, der scheinbar aus dem Nichts auftaucht. Wenn Ihre KI-Programmierkosten im letzten Quartal in die Höhe geschossen sind und sich niemand erklären kann, warum, sind Sie damit nicht allein – und die Lösung lautet selten: „Weniger KI nutzen.“
Das eigentliche Problem ist, dass agentenbasierte Programmier-Tools Tokens grundlegend anders verbrauchen als ein Chat-Fenster, und die meisten Teams zahlen den vollen Preis für Tokens, die sie zu einem Bruchteil der Kosten erhalten könnten. Dieser Leitfaden erläutert sieben konkrete Taktiken zur Reduzierung der KI-Programmierkosten, liefert die Zahlen hinter jeder Taktik und zeigt die exakten Konfigurationsänderungen, die sie effektiv machen.
Die wichtigsten Erkenntnisse
- Agentenbasierte Coding-Tools verbrauchen 10 bis 100 Mal mehr Tokens als ein Chat, da der vollständige Kontext bei jedem Tool-Aufruf erneut gesendet wird (LeanOps, 2026).
- Prompt-Caching ist der Hebel mit der größten Wirkung: Cache-Reads kosten etwa 10 % der Standard-Input-Tokens; ein Team konnte seine gesamten LLM-Ausgaben allein dadurch um 59 % senken.
- Die Umstellung der täglichen Programmierarbeit auf Open-Weight-Modelle wie GLM, Kimi und DeepSeek kann die Kosten pro Token gegenüber Frontier-Modellen um 80 % oder mehr senken, bei einem geringeren Qualitätsunterschied, als die meisten erwarten.
- Die Bündelung all Ihrer Tools über ein einziges Gateway ermöglicht ein einheitliches Budget, einen einzigen API-Schlüssel und konsistente Preise, anstatt bei fünf verschiedenen Anbietern Einzelhandelspreise zu zahlen.
Warum die KI-Programmierkosten außer Kontrolle geraten
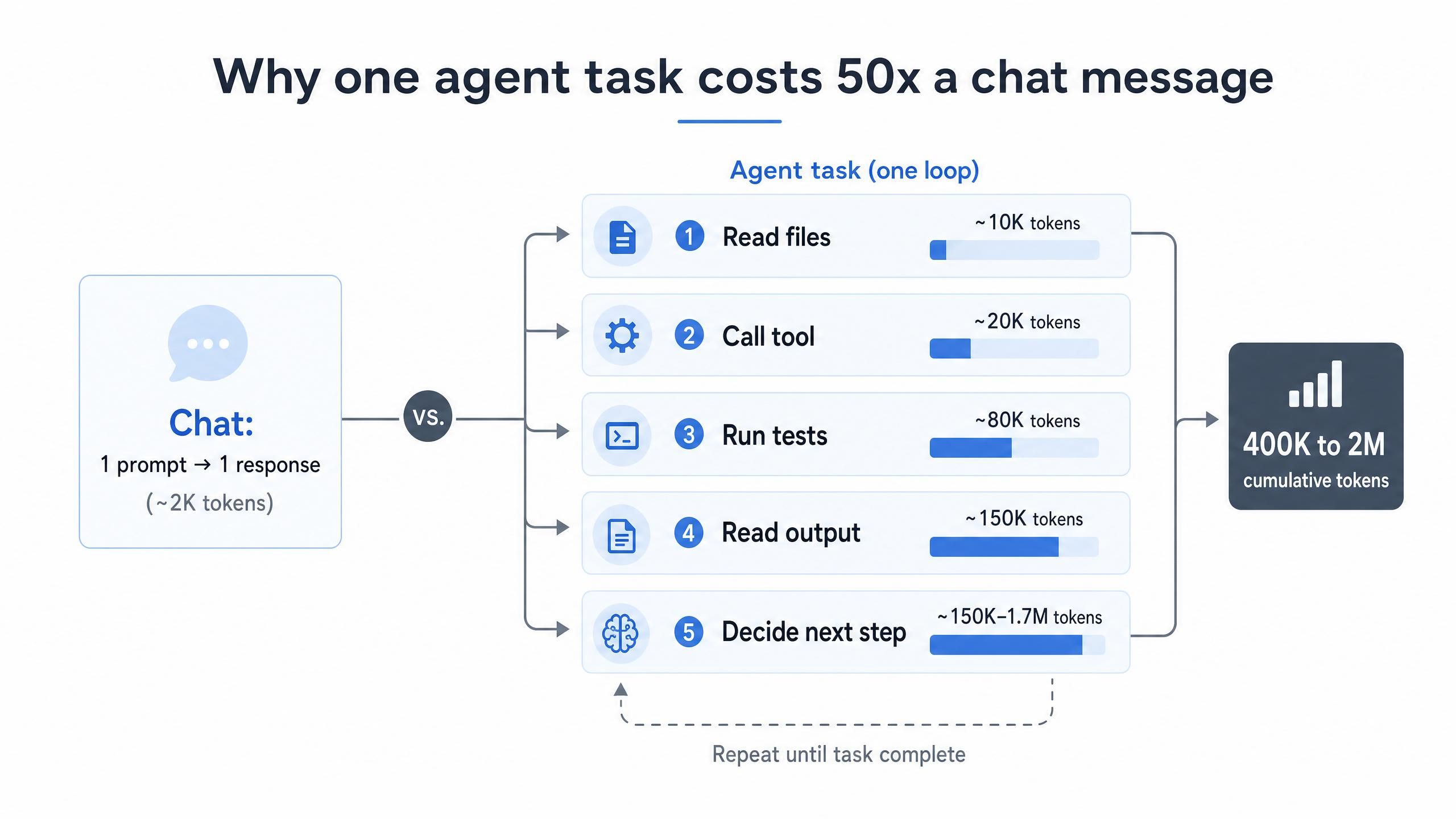
Der Hauptgrund für die hohen KI-Programmierkosten ist struktureller, nicht verhaltensbedingter Natur. Ein Chat-Austausch sendet einen Prompt und erhält eine Antwort. Ein Agent arbeitet völlig anders: Er liest Dateien, ruft Tools auf, führt Tests aus, liest die Ausgabe und entscheidet über die nächste Aktion. Jeder dieser Reasoning-Schritte sendet den angesammelten Kontext erneut, wodurch sich der Token-Verbrauch mit jeder Schleife summiert. Genau aus diesem Grund verbrauchen KI-Agenten 10 bis 100 Mal mehr Tokens als Chatbots (LeanOps, 2026).
Die Zahlen wachsen schnell. Eine einzige nicht triviale Agenten-Aufgabe kann 400.000 bis 2.000.000 kumulative Input-Tokens über die API schicken, während sich das Kontextfenster füllt und leert (Morph, 2026). Multiplizieren Sie das mit Dutzenden Aufgaben pro Tag im Team, und die monatliche Rechnung ist kein Rundungsfehler mehr.
Dies ist für große Organisationen kein hypothetisches Problem. Laut einem von The Next Web berichteten Bericht hat Microsoft einen Großteil seiner internen Claude Code-Lizenzen teilweise aufgrund der Kosten zurückgezogen, wobei die Kosten pro Ingenieur auf 500 bis 2.000 USD stiegen (The Next Web, 2026). Wenn eine der am besten ausgestatteten Ingenieursorganisationen der Welt vor der Rechnung zurückschreckt, lohnt es sich zu verstehen, wohin die Tokens tatsächlich fließen, bevor Sie versuchen, Kosten zu sparen.
So reduzieren Sie KI-Programmierkosten, ohne die Geschwindigkeit zu drosseln
Die gute Nachricht ist: Fast keine dieser Taktiken erfordert, weniger Code zu schreiben oder den Agenten zu überwachen. Sie funktionieren, indem sie Verschwendung beseitigen, die Arbeit neu bewerten und jeden Auftrag dem günstigsten Modell zuweisen, das die Aufgabe tatsächlich bewältigen kann. Hier sind die sieben Taktiken mit der größten Wirkung, in etwa nach dem Aufwand-Nutzen-Verhältnis geordnet.
Taktik 1: Prompt-Caching nutzen, um Programmierkosten zu senken
Prompt-Caching ist die wirkungsvollste Änderung, die Sie vornehmen können. Wenn ein Agent bei jedem Schritt denselben System-Prompt, dieselben Tool-Definitionen und denselben Dateikontext erneut sendet, ermöglicht Caching dem Modell, diese wiederholten Inhalte aus dem Cache zu lesen, anstatt sie neu zu verarbeiten. Cache-Reads werden mit etwa 0,10-facher Rate der Standard-Input-Tokens berechnet – ein Rabatt von 90 % auf den wiederholten Teil jeder Anfrage (Finout, 2026).
Wichtig zu wissen: Cache-Writes kosten etwas mehr als ein normales Input-Token, etwa das 1,25-Fache der Standardrate für ein fünfminütiges Zeitfenster. Caching zahlt sich also aus, wenn der Kontext innerhalb der Gültigkeitsdauer (TTL) wiederverwendet wird, was genau dem Muster eines Agenten entspricht. Der reale Effekt ist nicht theoretisch: Das Team bei ProjectDiscovery dokumentierte eine Senkung der LLM-Gesamtkosten um 59 % nach der Implementierung von Prompt-Caching in ihrer Pipeline (ProjectDiscovery, 2026).
Wenn Sie Claude Code oder einen kompatiblen Agenten verwenden, stellen Sie sicher, dass Caching aktiviert ist und Ihr System-Prompt sowie große Dateikontexte in cachefähigen Blöcken liegen. Diese eine Änderung sorgt oft für den größten prozentualen Rückgang auf der Rechnung.
Taktik 2: Modell an Aufgabe anpassen, um Kosten pro Token zu senken
Die meisten Teams leiten jede Anfrage an ihr leistungsfähigstes Modell weiter – das ist so, als würde man mit einem Lastwagen zum Supermarkt fahren, um Lebensmittel zu kaufen. Das klügere Muster besteht darin, das teure Frontier-Modell für die Arbeit zu reservieren, die es wirklich benötigt, und alles andere an ein günstigeres Modell zu senden.
Eine praktische Aufteilung sieht so aus:
- Reasoning, Architektur, komplexes Debugging: ein Top-Tier-Modell, bei dem die Qualität den Preis rechtfertigt.
- Alltägliche Code-Generierung und Änderungen: ein starkes Open-Weight-Modell der Mittelklasse.
- Hintergrund-Jobs mit hohem Volumen, Klassifizierung, Boilerplate: das günstigste fähige Modell.
Die Einsparungen sind dramatisch, da die Preisspanne enorm ist. Am günstigen Ende läuft DeepSeek V4 Flash mit etwa 0,14 USD pro Million Input-Tokens, während Frontier-Modelle ein Vielfaches davon kosten (Codersera, 2026). Wenn Sie 80 % Ihres Token-Volumens für ein Modell aufwenden, das einen Bruchteil kostet, während Sie das Premium-Modell für die restlichen 20 % behalten, können Sie die Gesamtkosten um mehr als die Hälfte senken, ohne dass die Ausgabequalität spürbar leidet.
Taktik 3: Kontextfenster schlank halten
Da jedes Token im Kontext bei jedem Agentenschritt erneut gesendet wird, ist ein aufgeblähtes Kontextfenster eine Steuer, die Sie wiederholt zahlen. Zwei Gewohnheiten helfen: Erstens, begrenzen Sie jede Aufgabe strikt, damit der Agent nur die Dateien lädt, die er wirklich benötigt, anstatt das gesamte Repository. Zweitens, starten Sie eine neue Sitzung, wenn Sie Aufgaben wechseln, anstatt eine Unterhaltung Hunderttausende veralteter Tokens ansammeln zu lassen.
Ein hilfreiches mentales Modell: Wenn Sie eine Datei nicht in einen Chat kopieren würden, um eine Frage zu beantworten, lassen Sie sie nicht im Kontext des Agenten. Das Kürzen eines Kontextfensters von 200.000 auf 40.000 Tokens spart nicht nur einmal. Es spart bei jedem einzelnen Tool-Aufruf für den Rest dieser Aufgabe, wodurch der Zinseszinseffekt zu Ihren Gunsten arbeitet.
Taktik 4: Auf Open-Weight-Modelle umsteigen
Dies ist die Taktik mit der größten Schlagzeilen-Einsparung und den meisten veralteten Annahmen. Die Open-Weight-Programmiermodelle, die 2026 veröffentlicht wurden, sind wirklich gut. Auf SWE-Bench Pro erreicht ein führendes Frontier-Modell etwa 91 Punkte, während Kimi K2.6 76,8 und DeepSeek V4 Pro fast 77 Punkte erreicht (Codersera, 2026). Das ist eine echte Lücke beim härtesten Benchmark, aber für routinemäßige Feature-Arbeit, Refactorings und das Schreiben von Tests ist der Unterschied weitaus geringer als der Preisunterschied.
Und der Preisunterschied ist der entscheidende Punkt. Open-Weight-Modelle wie GLM, MiniMax, Kimi und DeepSeek kosten pro Token einen Bruchteil der Preise für Frontier-Modelle. Für die meisten täglichen Programmierarbeiten erledigt ein Open-Weight-Modell den Job zu einem Bruchteil der Kosten. Das Hindernis war historisch gesehen der Zugang: das Jonglieren mit separaten Konten, Schlüsseln und inkonsistenten Preisen bei verschiedenen Anbietern.
Hier ändert ein einheitliches Coding-Gateway die Rechnung. Eine Plattform wie Atlas Cloud aggregiert die wichtigsten Open-Weight-Modelle hinter einer einzigen API und einem gemeinsamen Guthaben. So können Sie heute Claude Code, Codex oder OpenClaw auf GLM-5.1 ausrichten und morgen auf Kimi K2.6, ohne etwas an der Infrastruktur zu ändern. Atlas Cloud veröffentlicht Credit-Multiplikatoren pro Modell, die zu etwa 45 % bis 55 % Ersparnis gegenüber der offiziellen API-Preisgestaltung der Modelle führen.
Hier ist ein Ausschnitt, wie sich die Credit-Multiplikatoren bei beliebten Coding-Modellen übersetzen:
| Modell | Kontext | Input-Multiplikator | Output-Multiplikator | Ca. Ersparnis vs. offiziell |
|---|---|---|---|---|
| deepseek-ai/deepseek-v4-flash | 1M | 0,23 | 0,46 | ~50 % |
| deepseek-ai/deepseek-v3.2 | 160K | 0,42 | 0,62 | ~55 % |
| minimaxai/minimax-m2.5 | 200K | 0,65 | 2,18 | ~45 % |
| moonshotai/kimi-k2.6 | 262K | 1,72 | 7,26 | ~45 % |
| zai-org/glm-5.1 | 200K | 2,54 | 7,99 | ~45 % |
Quelle: Atlas Cloud Coding Plan Credit-Regeln. Credit-Kosten = Input-Tokens × Input-Multiplikator + Output-Tokens × Output-Multiplikator.
Taktik 5: Hintergrundarbeiten stapeln
Nicht jedes Token muss zu interaktiven Echtzeit-Preisen ausgegeben werden. Nächtliche Evals, große Klassifizierungsjobs, Dokumentationsläufe und Massen-Refactorings benötigen keinen wartenden Menschen – sie können also über günstigere Batch-Lanes oder mit dem kostengünstigsten verfügbaren Modell laufen. Dieses nicht dringende Volumen von Ihrem Premium-Modell wegzubewegen, ist „gefundenes Geld“, da Sie bereits den vollen Preis dafür zahlten, ohne dass die höhere Qualität einen Nutzen hatte.
Das Prinzip ist einfach: Trennen Sie „Ich warte darauf“-Tokens von „Das kann über Nacht fertig werden“-Tokens und berechnen Sie sie unterschiedlich. Für die meisten Teams macht ein überraschend großer Teil des gesamten Token-Volumens den nächtlichen Typ aus.
Taktik 6: Alle Tools über ein Coding-Gateway leiten
Die Verbreitung verschiedener Tools treibt die KI-Programmierkosten unbemerkt in die Höhe. Ein typischer Entwickler nutzt vielleicht Claude Code im Terminal, Codex für einige Aufgaben, Cursor im Editor und ein paar Agenten am Rande – jeder mit eigenem Abonnement, eigenem Schlüssel und undurchsichtiger Abrechnung. Sie verlieren die Übersicht über die Gesamtausgaben und zahlen überall den Einzelhandelspreis.
Die Konsolidierung auf einen einzigen OpenAI-kompatiblen Endpunkt löst beide Probleme. Da Atlas Cloud eine Basis-URL und einen Guthaben-Pool bereitstellt, der für Codex, Claude Code, OpenClaw, OpenCode, Cursor und direkte API-Aufrufe funktioniert, erhalten Sie eine Rechnung, ein Budget und einen zentralen Ort für Modellwechsel. Die Pläne beginnen bei einem 10-USD-Monats-Starter-Tarif bis hin zu höheren Stufen für Teams, und Pay-as-you-go-Pakete bieten einen Rabatt von 41 %.
Claude Code auf das Gateway auszurichten, erfordert eine einzige Konfigurationsdatei. Bearbeiten Sie unter macOS oder Linux
1~/.claude/settings.jsonJSON1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "zai-org/glm-5.1", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "zai-org/glm-5.1", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "zai-org/glm-5.1", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
Für Codex-Benutzer liegt das Äquivalent in
1~/.codex/config.toml1base_url1https://api.atlascloud.ai/v11~/.codex/auth.jsonTaktik 7: Budgets festlegen und KI-Programmierkosten überwachen
Man kann nicht reduzieren, was man nicht sieht. Teams, die von hohen Rechnungen überrumpelt wurden, hatten fast immer eine Gemeinsamkeit: keine Ausgabenkontrolle und keine Transparenz pro Entwickler. Die Lösung besteht darin, eine Obergrenze für den Verbrauch festzulegen, bevor der Monat beginnt, nicht erst, wenn die Rechnung eintrifft.
Ein credit-basierter Plan mit einem täglichen Kontingent erledigt dies strukturell. Anstelle eines unbegrenzten Zählers deckelt ein monatliches Abonnement, das täglich zu Mitternacht ein festes Guthaben auffrischt, den Wirkungsradius eines aus dem Ruder laufenden Agenten. Wenn Sie skalieren müssen, bedeuten anteilige Upgrades, dass Sie nur die Differenz zahlen. Der Upgrade-Prozess von Atlas Cloud verrechnet beispielsweise den verbleibenden Wert mit der neuen Stufe.
Ein realer Kostenvergleich: KI-Programmierkosten nach Modellen
Um die Einsparungen zu verdeutlichen: Betrachten Sie einen Entwickler, der an einem geschäftigen Tag etwa 1,5 Millionen Input-Tokens und 300.000 Output-Tokens durch seinen Agenten jagt – ein realistischer Wert, da einzelne Aufgaben kumulativ siebenstellige Input-Werte erreichen können. Bei einem Frontier-Modell, das mit etwa 5 USD pro Million Input und 25 USD pro Million Output bepreist ist, sind das etwa 7,50 USD für Input plus 7,50 USD für Output, also etwa 15 USD pro Entwickler-Tag, was dem allgemein zitierten Wert von 13 USD entspricht (CloudZero, 2026).
Lassen Sie das gleiche Volumen durch ein Open-Weight-Modell wie GLM oder Kimi über ein rabattiertes Gateway laufen, sinkt der Input-Anteil allein um 70 % oder mehr, wobei der Output dicht folgt. Fügen Sie Prompt-Caching hinzu, wird der wiederholte Kontext, der die Agenten-Workloads dominiert, zu einem Zehntel des Preises abgerechnet. Kombinieren Sie diese drei Taktiken, kann ein Entwickler-Tag von 15 USD realistisch auf 3 bis 5 USD sinken, ohne die Arbeitsweise zu ändern.

Die genauen Zahlen variieren je nach Arbeitslast, aber die Formel bleibt: Der Großteil der KI-Programmierkosten ist wiederholter Kontext, der durch ein überteuertes Modell läuft – beides ist korrigierbar.
Zusammenfassung: Eine Konfiguration für niedrige Kosten
Wenn Sie eine Startkonfiguration suchen, die die meisten Einsparungen mit minimalem Aufwand erzielt: Nutzen Sie ein Open-Weight-Modell wie GLM-5.1 oder Kimi K2.6 als Standard, halten Sie ein Frontier-Modell für komplexes Reasoning bereit, aktivieren Sie Prompt-Caching überall, halten Sie Aufgaben kurz, um den Kontext schlank zu halten, und leiten Sie alle Tools über einen OpenAI-kompatiblen Endpunkt mit täglichem Budget.
Diese Kombination geht alle Kostentreiber gleichzeitig an: Sie bewertet die Tokens neu, stoppt die Zahlung für wiederholten Kontext und deckelt das Risiko. Teams, die dies unter einem Schlüssel und einem Budget konsolidieren möchten, können dies über die Atlas Cloud Coding Plan-Konsole einrichten. Die Einrichtung dauert wenige Minuten; die Ersparnisse kehren jeden Tag zurück.
Häufig gestellte Fragen zu KI-Programmierkosten
Warum sind meine KI-Programmierkosten so viel höher als beim Chat?
Da Agenten bei jedem Reasoning-Schritt den gesamten angesammelten Kontext erneut senden, während ein Chat jeden Prompt nur einmal sendet. Dieser strukturelle Unterschied bedeutet, dass Agenten 10 bis 100 Mal mehr Tokens verbrauchen (LeanOps, 2026).
Was ist der schnellste Weg, die Kosten zu senken?
Aktivieren Sie Prompt-Caching. Wiederholter Kontext wird nach dem Caching mit etwa 10 % des Standard-Input-Preises berechnet (Finout, 2026). Dies erfordert keine Änderung an Ihrer Arbeitsweise.
Sind günstigere Open-Weight-Modelle gut genug?
Für die meisten täglichen Aufgaben: Ja. Auf dem SWE-Bench Pro erreichen Top-Open-Modelle Werte im hohen 70er-Bereich gegenüber ca. 91 bei Frontier-Modellen (Codersera, 2026), aber routinemäßige Aufgaben belasten diesen Unterschied selten.
Wie viel kann ich realistisch sparen?
Durch Kombination von Prompt-Caching, einem günstigeren Standardmodell und einem schlanken Kontext sinken die Kosten pro Entwickler-Tag von ca. 15 USD auf etwa 3 bis 5 USD.
Muss ich meine Tools wechseln?
Nein. Die meisten Einsparungen resultieren aus der Preisgestaltung und Wiederverwendung der Tokens, nicht aus dem Client. Ihre Tools (Claude Code, Codex, OpenClaw) auf einen rabattierten Endpunkt auszurichten, ist nur eine Konfigurationsänderung.
Fazit
KI-Programmierkosten wirken mysteriös, bis man den Mechanismus versteht: Agenten senden den gleichen Kontext immer wieder, und die meisten Teams zahlen dafür Frontier-Preise. Korrigieren Sie diese zwei Dinge – mit Prompt-Caching, smarterem Modell-Routing, schlankem Kontext und einem rabattierten Gateway –, und die Rechnung sinkt um die Hälfte oder mehr, ohne dass jemand anders codieren muss. Starten Sie diese Woche mit Caching, prüfen Sie den Modellbedarf Ihrer Aufgaben und konsolidieren Sie Ihre Tools auf ein Budget. Die Einrichtung dauert einen Nachmittag; die Einsparungen sind dauerhaft.






