
Jenseits von n8n: Warum Rust die einzige Antwort auf absturzfreie KI-Workflows ist
Es ist 2:00 Uhr morgens, und ein asynchroner JavaScript-Node in deiner produktiven n8n-Umgebung stößt im Hintergrund auf einen Fehler bei der impliziten Typumwandlung. Ein Webhook eines Drittanbieters hat einen Integer in einen String verwandelt. Da Node.js Code dynamisch zur Laufzeit auswertet, bricht die Ausführung mitten im Prozess ab. Der Workflow stoppt, Daten bleiben halb verarbeitet zurück und dein Team kämpft damit, den fehlerhaften Zustand der Zustandsmaschine zu beheben.
Für Entwickler, die geschäftskritische Automatisierungen und Multi-Agenten-Pipelines aufbauen, ist Laufzeit-Instabilität eine tickende Zeitbombe. Die Lösung besteht darin, das Paradigma der untypisierten, interpretationslastigen Orchestrierung komplett hinter sich zu lassen.
Hier kommt flow-like ins Spiel, eine Open-Source-Workflow-Automatisierungs-Engine auf Enterprise-Niveau, die von Grund auf in Rust entwickelt wurde. Indem flow-like die dynamische Unschärfe von Node.js gegen ein starres, stark typisiertes Ökosystem zur Kompilierzeit tauscht, ändert es die Regeln für Produktions-Pipelines. Es verwandelt unvorhersehbare Multi-Agenten-Verhaltensweisen in zuverlässige, deterministische Aufgaben, die auf einem einzelnen Terminal oder in einem Kubernetes-Cluster ohne eine einzige Laufzeitüberraschung ausgeführt werden können.
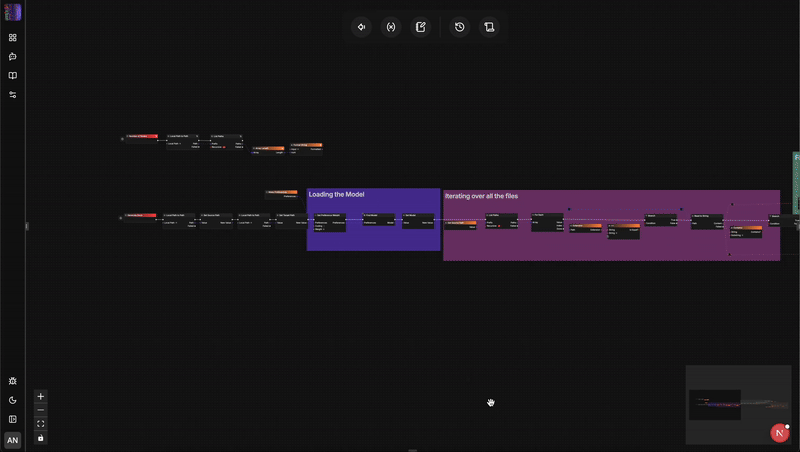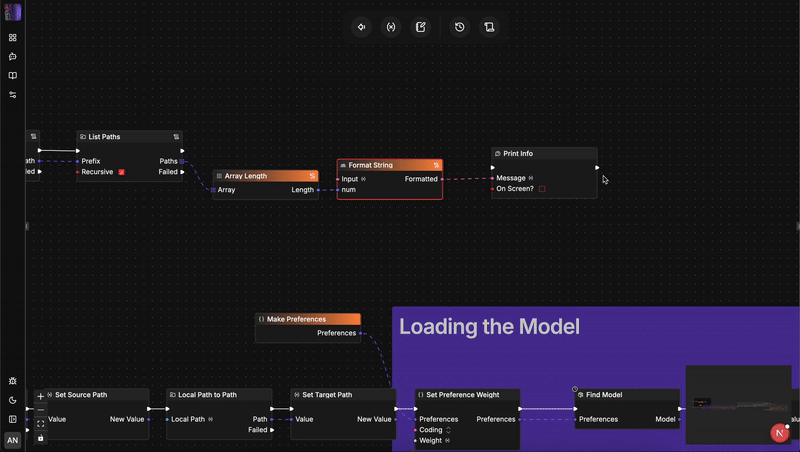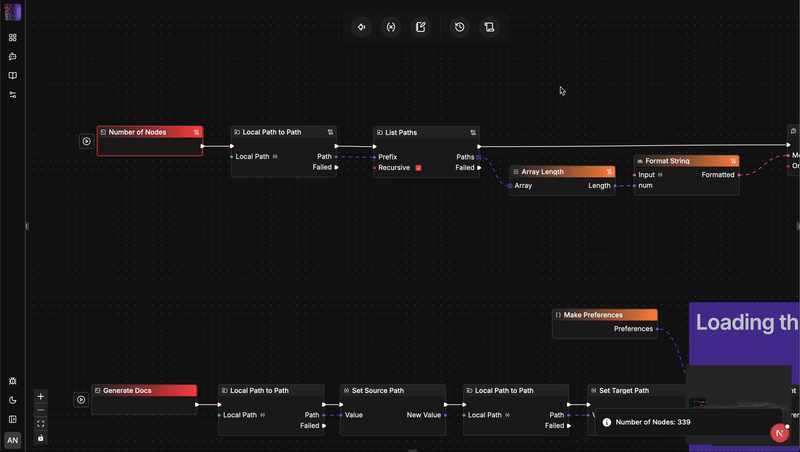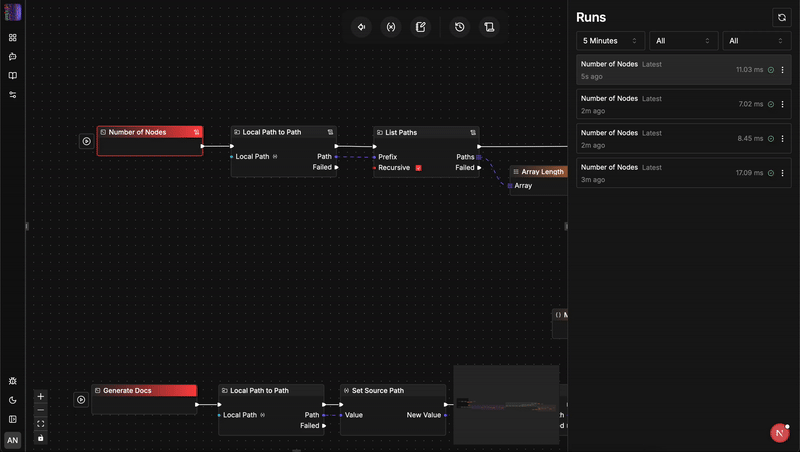
Architektonischer Vergleich: flow-like vs. n8n
Um zu verstehen, warum ein Sprachwechsel so wichtig ist, muss man genau betrachten, wie diese beiden Engines mit Status, Sicherheit und Skalierung umgehen.
Typsicherheit vs. untypisiertes Chaos
Das offensichtlichste Problem bei n8n ist die vollständige Abhängigkeit von losen JSON-Payloads, die blind zwischen Node.js-Modulen weitergereicht werden. Wenn ein Node ein verschachteltes Dictionary ausgibt, wo ein anderer Node ein flaches Objekt erwartet, entdeckt die Engine diese Diskrepanz erst, wenn der echte Produktionsdatenverkehr hindurchläuft.
Im Gegensatz dazu arbeitet flow-like mit einem strikten "Strong-Type Contract"-Modell über alle Datengrenzen hinweg. Variablen werden explizit mit Kernkonstrukten wie VariableType::String, VariableType::Execution oder benutzerdefinierten Structs deklariert. Wenn eine Ausgabe-Payload nicht mit dem Schema-Vertrag übereinstimmt, den der Consumer-Pin erwartet, erkennt die Pipeline-Engine dies frühzeitig. Die Ausführungs-Pipeline wirft deterministische Validierungs-Blöcke, bevor fehlerhafte oder unerwartete Payloads verarbeitet werden.
Hochperformante Nebenläufigkeit ohne Garbage Collection
Node.js stützt sich auf einen Single-Threaded-Event-Loop, um nebenläufige E/A-Vorgänge zu bewältigen. Wenn ein n8n-Container große Dateien parst oder hochfrequente Webhooks verarbeitet, verursacht die V8 JavaScript-Engine einen enormen Speicher-Overhead und plötzliche Latenzspitzen aufgrund von Garbage Collection (GC)-Pausen.
flow-like nutzt die Zero-Cost-Abstraktionen und das manuelle Speichermanagement von Rust. Mit asynchronen Traits und ressourcenschonenden Hashing-Utilities wie blake3 skaliert flow-like mühelos auf erstaunliche 244.000 Workflows pro Sekunde. Es verarbeitet Daten-Arrays und komplexe verschachtelte Schleifen mit einer durchschnittlichen internen Ausführungsgeschwindigkeit von nur ~0,6 ms pro Node und benötigt dabei nur einen Bruchteil des Speicherbedarfs einer Node.js-Laufzeitinstanz.
Showcase: Aufbau einer leckfreien, multimodalen KI-Verarbeitungspipeline in 3 Minuten
Sehen wir uns an, wie einfach es ist, einen Live-Workflow mit starker Typisierung einzurichten und auszuführen, der Eingabedaten über lokale Parameter verarbeitet und ein fortschrittliches Cloud-Modell zur Bearbeitung aufruft.
Schritt 1: Lokale Umgebungseinrichtung & Kompilierung
Da flow-like eine reine native Anwendung ohne externe Laufzeitabhängigkeiten ist, ist das Kompilieren unkompliziert. Klone das Projekt und verifiziere die Struktur des Workspaces mit Cargo:
Bash
plaintext1git clone https://github.com/Rheosoph/flow-like.git 2cd flow-like 3cargo build --release
Der Kompilierungsprozess verpackt alles – einschließlich der zugrunde liegenden WASM-Sandboxing-Laufzeiten und Typdefinitionen – in eine einzige ausführbare Binärdatei.
Schritt 2: Verbinden des Cloud-Brains über Atlas Cloud
Während flow-like auf lokaler Consumer-Hardware blitzschnell arbeitet, erfordert die Verarbeitung unstrukturierter Daten oder die Generierung präziser JSON-Schema-Strukturen fortschrittliche Inferenz-Fähigkeiten. Anstatt benutzerdefinierten API-Code zu schreiben oder tausende Zeilen modell-spezifischer Wrapper-Bibliotheken zu laden, enthält flow-like einen nativen BuildAtlasCloudNode-Node in seinem Standardkatalog.
Das zugrunde liegende Layout-Register konfiguriert das System für die Zielplattform:
Rust
plaintext1let mut node = Node::new( 2 "ai_generative_build_atlascloud", 3 "Atlas Cloud Model", 4 "Builds a model served by Atlas Cloud, a full-modal AI inference platform exposing a single OpenAI-compatible API...", 5 "AI/Generative/Provider" 6);
💡 Entwickler-Hinweis: Dieser Ansatz eliminiert die traditionelle Reibung bei der Verwaltung von API-Keys. Ich verwende einen einzigen API-Token von Atlas Cloud in diesem Node. Dadurch kann ich dynamisch Deep-Reasoning-Modelle wie DeepSeek-V4-Pro, Qwen oder GLM starten oder zwischen ihnen wechseln, ohne manuell Konten registrieren oder separate Client-Pakete für jedes Modell initialisieren zu müssen.
Hier ist ein Beispiel für die Konfiguration der Verbindungseigenschaften:
JSON
plaintext1{ 2 "node_id": "ai_generative_build_atlascloud", 3 "inputs": { 4 "endpoint": "https://api.atlascloud.ai/v1", 5 "api_key": "ac_prod_secure_token_7721", 6 "model_id": "deepseek-ai/deepseek-v4-pro" 7 } 8}
Schritt 3: Auslösen der Pipeline & Überprüfen der Metriken
Wenn ein Ausführungssignal den exec_in-Pin erreicht, aktiviert die Engine die Runner-Logik:
Rust
plaintext1let mut hasher = blake3::Hasher::new(); 2hasher.update(b"atlascloud"); 3// System hashes parameters and returns a unique, reusable VLM Bit structure
Die Engine validiert die Struktur, verpackt die Authentifizierungslogik sauber innerhalb einer OpenAI-kompatiblen Laufzeit-Provider-Instanz (custom:openai) und leitet das strukturierte Bit-Objekt über den model-Pin an nachgelagerte visuelle Extraktions-Blöcke weiter.
Produktions-Leistungsindikatoren (KPIs):
- Speicherbedarf bei Engine-Initialisierung: ~24 MB RAM
- Interne Node-Pin-Latenz: < 0.1ms
- Fehler durch Typsicherheit: 0 (Bereits beim Konfigurationsschritt abgefangen)
Vergleichstabelle: Engine-Spezifikationen im Überblick
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Architektur-Dimension | n8n Workflow-Engine | flow-like Architektur |
| Zugrunde liegende Sprache | Node.js (TypeScript / JavaScript) | Rust (Reiner nativer Core) |
| Typisierung der Datenschnittstelle | Loses JSON (Dynamische Validierung zur Laufzeit) | Stark typisierte Verträge (Pins erzwingen Strukturen) |
| Max. nebenläufiger Durchsatz | ~220 Aufgaben/Sek. (V8 Event-Loop-gebunden) | ~244.000 Workflows/Sek. (Zero-GC Ausführung) |
| Execution Sandboxing | VM2/Isolates (Anfällig für Prototype Pollution) | WebAssembly (WASM) Isolation |
| Offline-Architektur | Schwere Docker-Umgebungen erforderlich | Local-First Native (Läuft nahtlos auf Raspberry Pi) |
| Ökosystem der Modellanbindung | Separate Community-Integrationen pro Anbieter | Einheitliche Endpunkte (via Atlas Cloud Node-Layer) |
FAQ: Skeptik gegenüber Rust-basierter Automatisierung auflösen
Bedeutet eine Rust-basierte Engine, dass ich nativen Rust-Code schreiben muss, um einen Node zu bauen?
Nein, du musst kein Rust schreiben, um die Plattform zu erweitern. Während der Engine-Core reines Rust ist, nutzt flow-like WebAssembly (WASM)-Sandboxing, um die Erstellung benutzerdefinierter Nodes in über 15 Sprachen zu unterstützen – darunter TypeScript, Python und Go –, ohne die Sicherheitsgarantien der Engine zu verletzen.
Wie geht das typsichere System mit beliebigen, dynamischen API-Payloads um?
Es bildet lose Eingaben am Ingestion-Node in einen wohldefinierten Struct-Container ab. Durch die Durchsetzung strikter Grenzen an den Eingabe-Pins werden fehlende Schlüssel oder Formatänderungen sofort am Grenz-Node erkannt und behandelt, wodurch sichergestellt wird, dass interne Logikschritte niemals auf undefinierte Laufzeitvariablen stoßen.
Wie hoch ist der präzise Speicher-Overhead bei der Verarbeitung massiver Schleifen?
Die Plattform belegt bei typischer hoher Auslastung durchschnittlich weniger als 30 Megabyte an Basis-Speicher. Da Rust Ressourcen-Blockregister sofort freigibt, sobald Daten den Gültigkeitsbereich verlassen, anstatt Garbage-Collection-Vorgänge in eine Warteschlange zu stellen, zeigen Speichergraphen eine flache Linie, selbst bei der Verarbeitung umfangreicher Iterationsmatrizen.






