DeepSeek v4: Alles, was wir bisher wissen – Funktionen, Veröffentlichungsdatum und Zugriff über Atlas Cloud
Einleitung: Was ist DeepSeek v4?
AtlasCloud erweitert sein Portfolio an generativer KI um die kommende Ergänzung DeepSeek v4.
- Was es ist: Das neueste Flaggschiff des DeepSeek-Teams. Während DeepSeek v3.2 den Standard für kosteneffiziente Open-Source-Codierungsmodelle setzt, verschiebt v4 die Grenzen von Logik und Speicher durch proprietäre Manifold-Constrained Hyper-Connections (mHC)- und Engram Memory-Technologien.
- Hauptvorteil: v4 generiert nicht nur Code-Snippets, sondern agiert wie ein leitender Softwarearchitekt, der ganze Repository-Strukturen für dateiübergreifendes Schlussfolgern und komplexe Fehlerbehebungen versteht.
- Status: Bevorstehende Veröffentlichung (erwartet Mitte Februar 2026 – lesen Sie unsere Analyse dazu, was Sie von DeepSeek V4 erwarten können).
Warum sind wir so zuversichtlich, dass DeepSeek v4 ein Wendepunkt ist? Weil es das größte Problem der Branche löst: KI muss die Logik eines Projekts verstehen und sich daran erinnern.
📣 Update – 24. April 2026: DeepSeek-V4 wurde offiziell veröffentlicht. Lesen Sie unseren vollständigen Bericht darüber, was tatsächlich ausgeliefert wurde, einschließlich der neuen Sparse-Attention-Architektur, 1M Token Kontext und Agent-Benchmark-Ergebnissen – im DeepSeek-V4 Preview Launch.
Technischer Deep Dive: Hauptfunktionen
Um Claude Opus 4.5 herauszufordern, hat DeepSeek das Modell von Grund auf neu aufgebaut. Geleakte Papiere deuten auf einen grundlegenden Wandel in der Art und Weise hin, wie das Modell Speicher und logische Stabilität handhabt. Lassen Sie uns die vier Säulen dieses Updates aufschlüsseln.
Architektur: Überlegenes logisches Schlussfolgern
-
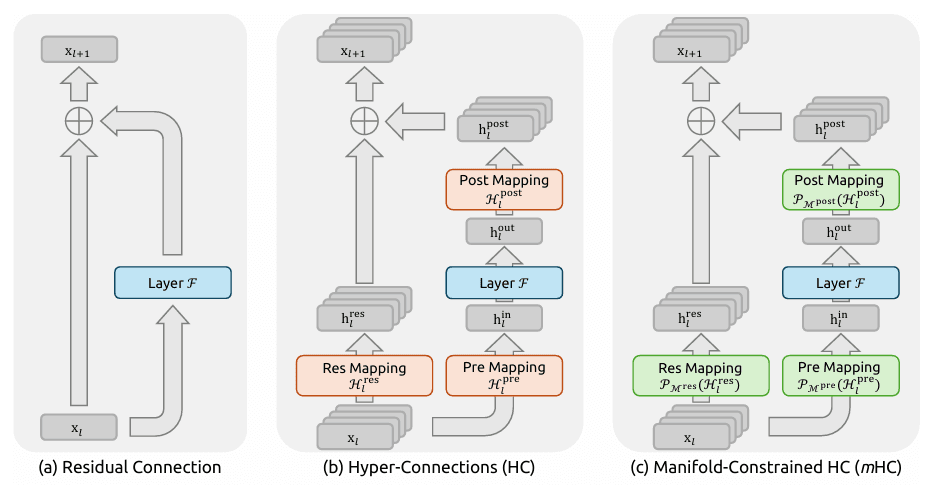
Manifold-Constrained Hyper-Connections (mHC)
- Das Konzept: DeepSeek v4 erfindet eine neue Methode der "neuronalen Verdrahtung". Herkömmliche Verbindungen verlieren in tiefen Netzwerken oft Informationen, aber mHC fungiert wie eine "logische Superautobahn" für das Gehirn der KI.
- Das Ergebnis: Bei der Verarbeitung massiver, komplexer Logik (wie dem Refactoring von Tausenden von Codezeilen) lernt das Modell schneller und behält logische Zusammenhänge besser bei. Dies eliminiert die "Logik-Halluzinationen" und Inkonsistenzen, die bei der Generierung von langem Kontext häufig auftreten.
Effizienz: Geringere Inferenzkosten
-
Mixture-of-Experts (MoE) 2.0
- Das Konzept: Obwohl v4 ein Parameter-Gigant ist (Hunderte von Milliarden), nutzt es eine optimierte MoE-Architektur, um für jedes Token nur die relevantesten "Experten" zu aktivieren.
- Das Ergebnis: Es bietet die perfekte Balance zwischen hoher Leistungsfähigkeit (massives Wissensnetzwerk) und effizienter Skalierung (läuft so leicht wie ein kleineres Modell).
-
Sparse Attention
- Das Konzept: Anstatt Texte mittels Brute-Force komplett zu scannen, konzentriert sich das Modell nun intelligent nur auf die wichtigsten Informationen. Dies senkt die Rechenkosten drastisch und beschleunigt die Verarbeitung von langem Kontext.
Speicher: Intelligentes Kontextmanagement
-
Engram Memory (Selektive Speicherung & Abruf)
- Das Konzept: Die KI hört auf, auswendig zu lernen, und fängt an zu "verstehen". Sie erkennt Projektstrukturen, befolgt Namenskonventionen (snake_case vs. camelCase) und identifiziert Codierungsmuster (und ahmt die spezifischen Factory-Muster Ihres Teams nach).
- Das Ergebnis: Es programmiert wie ein erfahrener Mitarbeiter.
-
Multi-Head Latent Attention (MLA)
- Das Konzept: Stellen Sie sich dies als "Super-Kurzschrift" vor. Wo andere Modelle 100 Token benötigen, um Informationen zu speichern, komprimiert MLA sie in 10 Schlüsselsymbole.
- Das Ergebnis: Wenn ein Abruf erforderlich ist, rekonstruiert das Modell mathematisch die ursprüngliche Bedeutung ohne Informationsverlust. Dies erhält eine unglaubliche Detailtreue bei deutlich geringerem VRAM-Verbrauch.
Anwendung: Engineering in der Praxis
- Repo-Level-Verständnis & Fehlerbehebung
- Das Ziel ist nicht nur das Schreiben einer Funktion, sondern die Kontrolle über die Codebasis. Bei SWE-bench-Tests zielt DeepSeek v4 darauf ab, über 80,9 % der komplexen, realen Probleme durch das Verständnis dateiübergreifender Abhängigkeiten zu lösen.
Anwendungsfälle: Kosten senken & Effizienz steigern
DeepSeek v4 ist für anspruchsvolles Engineering gebaut. So schlägt es sich im Vergleich zur Konkurrenz:
Refactoring von Legacy-Code
Für undokumentierte, chaotische Altsysteme ist die mHC-Architektur ein Lebensretter. Sie verfolgt logische Abhängigkeiten über lange Distanzen für ein sicheres Refactoring.
- VS GPT-4o: GPT-4o leidet oft unter "Logik-Halluzinationen" (erfindet nicht existierende Funktionsaufrufe), wenn der Kontext 10k Token überschreitet. DeepSeek v4 behält über lange Kontexte hinweg 100 % logische Konsistenz bei.
- VS Claude 3.5 Sonnet: Während Sonnet hochwertig ist, ist es langsam und teuer für massive Refactoring-Jobs. Die MoE-Architektur von DeepSeek v4 bietet ca. 40 % schnellere Inferenzgeschwindigkeiten zu geringeren Kosten auf Atlas Cloud.
Repo-Level Feature-Entwicklung
Beim Hinzufügen einer neuen API zu einem ausgereiften Projekt nutzt v4 "Engram Memory", um den Kontext sofort zu erfassen.
- VS herkömmliche Autovervollständigung: Standard-Tools ignorieren oft projektspezifische Normen und führen Stil-Inkonsistenzen ein. DeepSeek v4 ahmt Ihre bestehende Codebasis so gut nach, dass es sich anfühlt wie Copy-Paste von Ihrem besten Entwickler.
Vollständige Fehlerverfolgung
Eine Erfolgsquote von 80,9 % bei SWE-bench bedeutet die Behandlung von Fehlern, die Frontend, Backend und Datenbanken umfassen.
- VS Claude Opus 4.5 (erwartet): Opus 4.5 wird wahrscheinlich leistungsstark, aber teuer sein. DeepSeek v4 bietet nahezu SOTA-Leistung zu einem Preis, der iterative "Reflektions- und Korrekturschleifen" ermöglicht, ohne das Budget zu sprengen.
📉 Das Fazit: ROI für Teams
Für Startups und Entwicklerteams liefert die Kombination aus DeepSeek v4 und AtlasCloud einen greifbaren ROI:
- Produktivität: Senken Sie die Programmierzeit für erfahrene Entwickler um 30-50 %.
- Kosten: Verglichen mit dem Mieten von Dual-RTX-4090-Servern oder dem Bezahlen für Closed-Source-APIs können Teams mit der integrierten API von AtlasCloud über 60 % der gesamten Rechenkosten einsparen.
Die Hardware-Grenze: Lokal hosten? Überlegen Sie es sich zweimal.
Vielleicht sind Sie versucht, diesen "Programmiergott" auf Ihrer lokalen Maschine laufen zu lassen. Aber wir müssen Ihnen die Realität vor Augen führen: Leistung hat ihren Preis.
- Mindestanforderung: Dual RTX 4090s
- Übersetzung: Sie kaufen zwei der teuersten Consumer-GPUs auf dem Markt und koppeln sie. Die Kosten für die GPUs allein entsprechen ungefähr 3x iPhone 17 Pro Max-Geräten (oder einem ordentlichen Gebrauchtwagen).
- Empfohlen: Single RTX 5090 (2026 Flaggschiff)
- Übersetzung: Dies ist der "Ferrari" unter den GPUs. Der Preis wird nicht nur durch Scalper extrem hoch sein, sondern die Verfügbarkeit wird zudem sehr knapp sein.
Angesichts der hohen GPU-Preise fragen Sie sich: Ist es das wert, Tausende von Dollar auszugeben und sich mit Lüftergeräuschen, Hitze und Konfigurationsaufwand herumzuschlagen, nur um ein Modell laufen zu lassen?
Die smarte Lösung: Atlas Cloud Day 0-Zugang
Sie müssen nicht reich sein, um DeepSeek v4 zu nutzen; Sie müssen nur schlau sein. Anstatt "elektronische Ziegelsteine" zu kaufen, die an Wert verlieren, wählen Sie die Cloud.
AtlasCloud ist bereit für den Launch:
-
Unser Versprechen: Genießen Sie Ihren Urlaub. Überlassen Sie uns die Drecksarbeit der Bereitstellung. Wir überwachen die offiziellen Release-Kanäle rund um die Uhr.
-
Kernvorteile:
- Sofortiger Zugriff: Sobald die Open-Source-Gewichte veröffentlicht werden, geht unsere API-Integration live.
- Null Hürden: Keine teure Hardware, kein CUDA-Abhängigkeitschaos. Bringen Sie einfach Ihren Prompt mit.
- Kompromisslose Erfahrung: Wir bieten volle Kontextunterstützung und stellen sicher, dass der "Engram"-Speichermechanismus bei 100 % Kapazität ohne Quantisierungsverlust arbeitet.
Nutzung auf Atlas Cloud
Atlas Cloud ermöglicht es Ihnen, Modelle Seite an Seite zu nutzen – zuerst in einem Playground, dann über eine einzige API.
Methode 1: Direkt im Atlas Cloud Playground nutzen
Methode 2: Zugriff über API
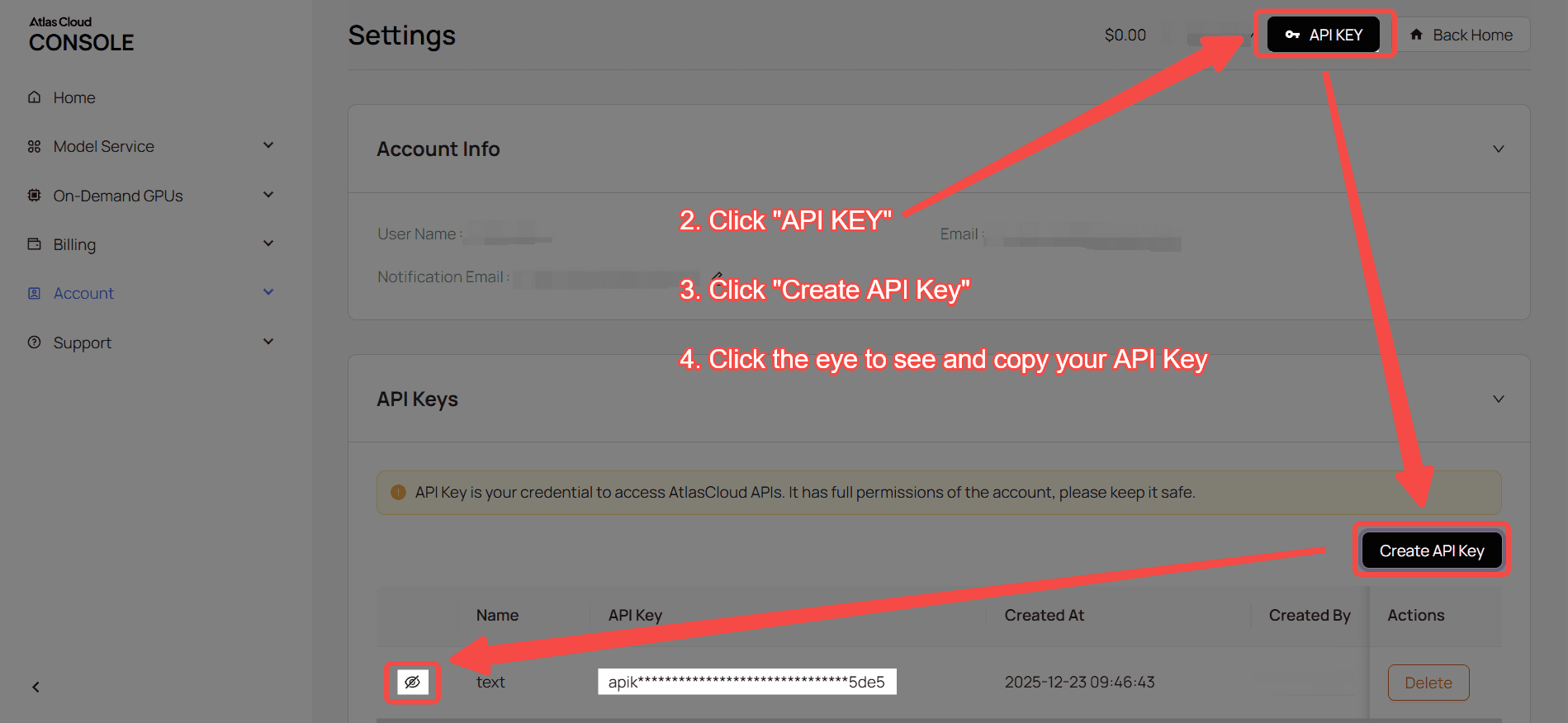
Schritt 1: API-Key abrufen
Erstellen Sie einen API-Key in Ihrer Konsole und kopieren Sie ihn für die spätere Verwendung.
Schritt 2: API-Dokumentation prüfen
Überprüfen Sie den Endpunkt, die Anfrageparameter und die Authentifizierungsmethode in unserer API-Dokumentation.
Schritt 3: Erste Anfrage stellen (Python-Beispiel)
Beispiel: Generierung mit DeepSeek v3.2:
python1import requests 2 3url = "https://api.atlascloud.ai/v1/chat/completions" 4headers = { 5 "Content-Type": "application/json", 6 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 7} 8data = { 9 "model": "deepseek-ai/deepseek-v3.2", 10 "messages": [ 11 { 12 "role": "user", 13 "content": "what is difference between http and https" 14 } 15 ], 16 "max_tokens": 32768, 17 "temperature": 1, 18 "stream": True 19} 20 21response = requests.post(url, headers=headers, json=data) 22print(response.json())






