
Wenn Sie GPU-Kernel schreiben, befinden Sie sich irgendwo auf einem Spektrum. Am einen Ende steht Triton: schnell zu schreiben, aber der Compiler trifft die meisten Entscheidungen bezüglich Layout und Shared Memory für Sie. Am anderen Ende steht CUTLASS / CuTe: volle Kontrolle, um den Preis von sehr viel Template-Maschinerie. TileLang liegt in der Mitte. Sie schreiben Python, geben aber explizit an, was im Shared Memory liegt, wie die Pipeline gestaged ist und wie Warps die Arbeit aufteilen – ein Layout-Inference-Pass erledigt den Rest.
In diesem Beitrag behandeln wir das mentale Modell, schreiben einen GEMM und bauen schließlich einen echten Produktions-Kernel: DeepSeeks MLA-Decode, bei dem die interessanten Entscheidungen tatsächlich zum Tragen kommen. Das Ziel ist nicht Vollständigkeit, sondern zu zeigen, wie man über Tiles nachdenkt und wo TileLang einem stillschweigend die schwierigen Teile abnimmt. Wir schließen mit einer typischeren Geschichte aus der Produktion ab – einem Kernel, bei dem der Gewinn keineswegs Geschwindigkeit war.
Das mentale Modell
Hier ist die gesamte Idee in drei Punkten.
- Ein Tile ist ein Objekt erster Klasse. Ein geformter Datenblock (z. B. block_M × block_K) gehört einem Thread-Block, einem Warp oder einem Thread und wird von diesem bearbeitet. Sie hören auf, rein auf Thread-Block-Ebene zu denken, wie man es in Triton tut, und Sie hören auf, einzelne Threads von Hand zu verwalten, wie man es in CUDA tut.
- Sie platzieren Puffer selbst in der Speicherhierarchie. Sie deklarieren, was in den Shared Memory geht (T.alloc_shared), was in die Register geht (T.alloc_fragment) und was Thread-lokal ist. Dies ist der größte Unterschied zu Triton, das die Zuweisung und das Staging von Shared Memory im Compiler verbirgt.
- Der Compiler leitet das Thread-Mapping ab. Sobald Sie festgelegt haben, wo ein Tile lebt und welche Operation darauf ausgeführt wird (eine Kopie, ein GEMM, eine Reduktion), parallelisiert ein Layout-Inference-Pass dies über Threads hinweg und berechnet die Register- und Shared-Memory-Layouts. Sie können dies bei Bedarf überschreiben, müssen es aber meistens nicht. Dieser Pass ist die tragende Funktion – bis wir bei MLA ankommen, werden Sie sehen, warum.
Wenn Sie von Triton kommen, ist hier die grobe Zuordnung.
| Triton | TileLang | |
|---|---|---|
| Granularität | Thread-Block + implizite Vektorisierung | Tile (Block / Warp / Thread) |
| Shared Memory | vom Compiler verwaltet | explizit alloc_shared + copy |
| Layout | der Compiler entscheidet | abgeleitet, aber annotierbar |
| Pipelining | tl.range + Compiler | explizit T.Pipelined(num_stages=) |
| Tensor Core | tl.dot | T.gemm mit wählbarer Warp-Policy |
| Backends | NVIDIA (hauptsächlich) / AMD | NVIDIA / AMD / CPU / WebGPU / CuTeDSL, plus Ascend & MUSA-Forks |
Kurz gesagt: Wenn Sie eine feine Kontrolle über Blocking, Pipeline-Tiefe und Warp-Partitionierung haben möchten, ohne CUTLASS schreiben zu müssen, ist TileLang der "Sweet Spot". Für einfache elementweise Operationen oder leichte Fusionen ist Triton nach wie vor schneller zur Hand.
Einrichtung
plaintext1conda create -n tilelang python=3.10 -y 2conda activate tilelang 3pip install tilelang # Prebuilt Wheel, einfachster Weg
Wenn Sie an den Compiler-Passes arbeiten möchten, bauen Sie stattdessen aus dem Quellcode (Sie benötigen eine lokale LLVM/CUDA-Toolchain):
plaintext1git clone --recursive https://github.com/tile-ai/tilelang.git 2cd tilelang && pip install -r requirements-dev.txt 3pip install -e . -v --no-build-isolation
Schreiben wir einen GEMM
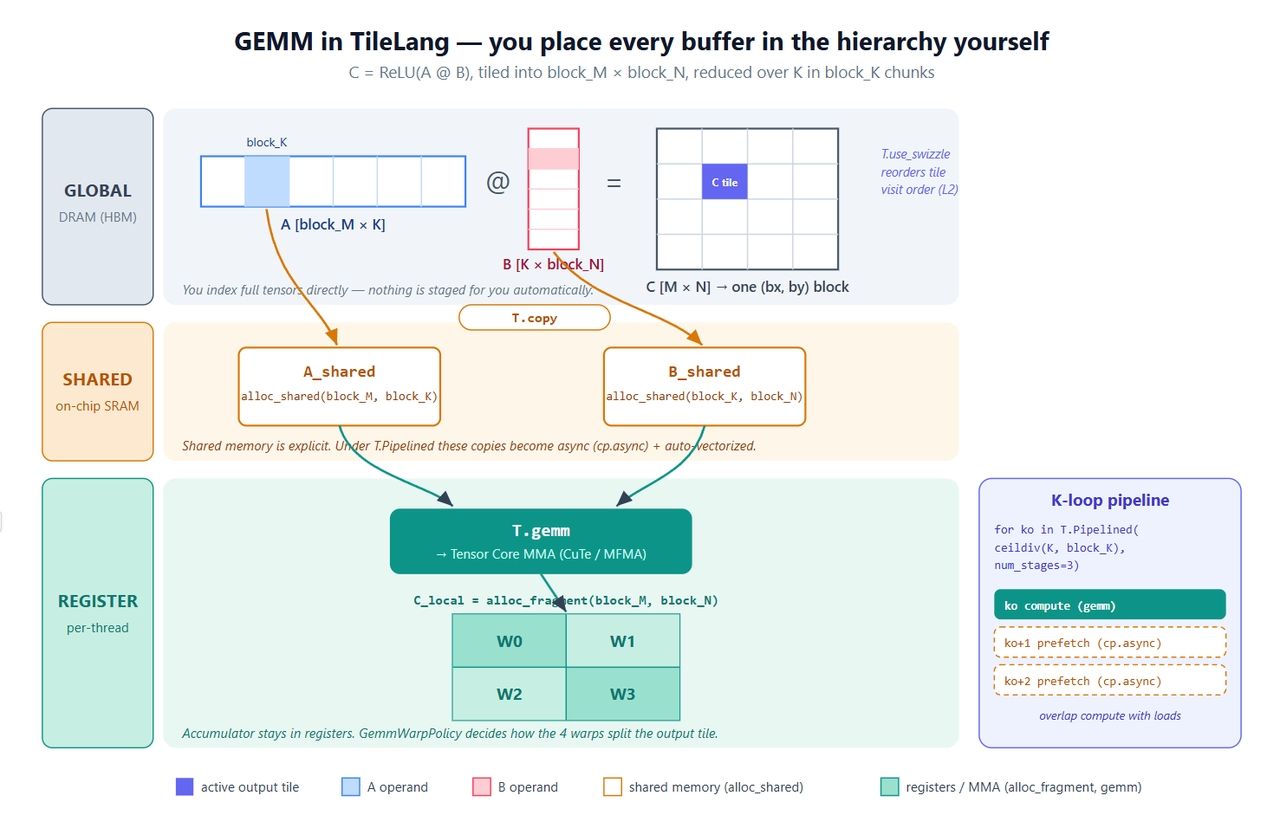
Wir beginnen mit dem Kernel, mit dem jeder startet: C = ReLU(A @ B). Er ist klein, berührt aber jedes wichtige Primitiv – explizite Puffer, parallele Kopie, Software-Pipelining, den Tensor Core-Aufruf und ein L2-Swizzle.
python1import tilelang 2import tilelang.language as T 3import torch 4 5@tilelang.jit 6def matmul(M, N, K, block_M, block_N, block_K, 7 dtype="float16", accum_dtype="float"): 8 9 @T.prim_func 10 def matmul_relu_kernel( 11 A: T.Tensor((M, K), dtype), 12 B: T.Tensor((K, N), dtype), 13 C: T.Tensor((M, N), dtype), 14 ): 15 # Grid-Dims: (#Blöcke entlang N, #Blöcke entlang M); 128 Threads pro Block 16 with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), 17 threads=128) as (bx, by): 18 19 # Definieren Sie explizit, wo jedes Tile liegt. 20 A_shared = T.alloc_shared((block_M, block_K), dtype) # Shared Memory 21 B_shared = T.alloc_shared((block_K, block_N), dtype) 22 C_local = T.alloc_fragment((block_M, block_N), accum_dtype) # Register-Akkumulator 23 24 T.use_swizzle(panel_size=4, order="col") # optional: bessere L2-Wiederverwendung 25 T.clear(C_local) # Akkumulator nullen 26 27 for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages=3): 28 T.copy(A[by * block_M, ko * block_K], A_shared) # global -> shared 29 T.copy(B[ko * block_K, bx * block_N], B_shared) 30 T.gemm(A_shared, B_shared, C_local) # Tile-Level MMA 31 32 for i, j in T.Parallel(block_M, block_N): # gefustes ReLU 33 C_local[i, j] = T.max(C_local[i, j], 0) 34 35 T.copy(C_local, C[by * block_M, bx * block_N]) # Zurückschreiben 36 37 return matmul_relu_kernel 38 39 40M = N = K = 1024 41kernel = matmul(M, N, K, block_M=128, block_N=128, block_K=64) 42a = torch.randn(M, K, device="cuda", dtype=torch.float16) 43b = torch.randn(K, N, device="cuda", dtype=torch.float16) 44c = torch.empty(M, N, device="cuda", dtype=torch.float16) 45kernel(a, b, c) 46 47torch.testing.assert_close(c, torch.relu(a @ b), rtol=1e-2, atol=1e-2) 48print("gemm ok")
Hier ist, was jedes Stück bewirkt:
- Drei Puffer, drei Ebenen. A_shared und B_shared liegen im Shared Memory; C_local lebt in den Registern. Akkumulator in Registern, Operanden gestaged über Shared Memory – das ist das Standard-GEMM-Rezept, nur dass Sie es hier selbst aufschreiben. Das ist der ganze Unterschied zu Triton in einer Zeile.
- T.copy ist Syntactic Sugar für eine parallele Kopie. Sie expandiert zu einem Move im T.Parallel-Stil, und der Compiler leitet daraus einen vektorisierten, coalesced Global→Shared-Transfer ab. Wenn die Kopie innerhalb von T.Pipelined steht, wird sie automatisch zu cp.async.
- T.Pipelined(extent, num_stages=N) ist eine Software-Pipeline. num_stages=3 bedeutet Triple-Buffering – während Sie K-Tile ko berechnen, sind die Ladevorgänge für ko+1 und ko+2 bereits unterwegs. In Triton ist das ein Compile-Flag; hier ist es einfach die Schleife, was leichter nachzuvollziehen ist.
- T.gemm(A, B, C) ist das Matmul auf Tile-Ebene. Es wird auf NVIDIA zu CuTe/MMA und auf AMD zu den entsprechenden Intrinsics übersetzt. Es nimmt außerdem transpose_A / transpose_B und eine policy=T.GemmWarpPolicy.* entgegen, die steuert, wie Warps das Ausgabe-Tile aufteilen. Behalten Sie das Policy-Argument im Hinterkopf – das ist die ganze Geschichte, wenn wir zu MLA kommen.
- T.use_swizzle ordnet das Scheduling der Thread-Blöcke so um, dass Blöcke, die im L2 benachbart sind, zeitlich nahe beieinander ausgeführt werden. Bringt meist ein paar Prozent freie Bandbreite.
Die Abbildung unten ordnet all dies der Hardware zu. Es lohnt sich, sie im Vergleich zum Code zu lesen, da die markierten Stellen genau die Bereiche sind, in denen TileLang Ihnen die Kontrolle überlässt, die Triton für sich behält.
Ein paar Primitive, die Sie brauchen werden
Sie können die meisten Kernel mit einem kleinen Vokabular schreiben:
- Allokation: T.alloc_shared, T.alloc_fragment (Register), T.alloc_local.
- Verschieben und Initialisieren: T.copy(src, dst) zwischen zwei beliebigen Ebenen; T.clear, T.fill.
- Berechnung: T.gemm(...); T.Parallel(d0, d1, ...) für elementweise Schleifen (dies ist der Einstiegspunkt für die Layout-Inference); T.reduce_max / T.reduce_sum; skalare Mathematik wie T.exp, T.exp2, T.max, T.infinity.
- Scheduling: T.Pipelined(extent, num_stages=), T.use_swizzle(...), T.annotate_layout(...) wenn Sie ein spezifisches Layout benötigen (Vermeidung von Bank-Konflikten, benutzerdefiniertes Swizzle).
- Dynamische Shape: M = T.dynamic("m"), damit Sie nicht pro Shape neu kompilieren müssen (wird in einigen Versionen T.symbolic genannt).
Überprüfung Ihrer Arbeit
Zwei Dinge, die Sie oft brauchen werden. Um zu sehen, was der Compiler tatsächlich ausgegeben hat:
plaintext1print(kernel.get_kernel_source()) # generiertes CUDA / HIP
Und um die Zeit zu messen:
plaintext1profiler = kernel.get_profiler(tensor_supply_type=tilelang.TensorSupplyType.Normal) 2print(f"latency: {profiler.do_bench()} ms")
T.print(buf) gibt ein Tile aus dem Kernel heraus aus, und das examples/plot_layout-Skript im Repository zeichnet das Speicherlayout, was nützlich ist, wenn Sie einen Bank-Konflikt suchen oder ein Swizzle prüfen.
Jetzt ein echter: MLA-Decode
Der GEMM zeigt die Mechanik. Dieses Beispiel zeigt, warum sie wichtig sind. Wir gehen durch DeepSeeks MLA (Multi-Head Latent Attention) Decode-Kernel, da dies das sauberste Beispiel dafür ist, wie TileLang sich bezahlt macht. Die TileLang-Referenz erreicht etwa die H100-Performance von FlashMLA (gebenchmarkt bei Batch 64/128 in fp16, deutlich vor Triton und FlashInfer) in etwa 80 Zeilen Python. Die interessante Frage ist wie, denn der schwierige Teil bei MLA ist nicht die Mathematik – es ist der Register-Druck.
Lassen Sie uns die Schleife wiederholen, die jeder kennt. Jeder Kernel der FlashAttention-Familie hat die gleiche Form. Pro Query-Block streamen Sie über Key/Value-Blöcke und behalten ein laufendes Maximum und einen Nenner bei, sodass die vollständige Score-Matrix nie im Speicher landet:
plaintext1# acc_s : [block_M, block_N] Scores für diesen KV-Block 2# acc_o : [block_M, dim] Ausgabe-Akkumulator 3for i in range(num_kv_blocks): 4 acc_s = Q @ K[i].T 5 m_prev = scores_max 6 scores_max = max(m_prev, rowmax(acc_s)) 7 scores_scale = exp(m_prev - scores_max) 8 acc_o *= scores_scale # vorherige Ausgabe skalieren 9 acc_s = exp(acc_s - scores_max) # Wahrscheinlichkeiten 10 acc_o += acc_s @ V[i]
Sowohl acc_s als auch acc_o möchten in den Registern bleiben. Für MHA oder GQA ist das in Ordnung. Für MLA ist es das nicht.
Hier wird es schwierig. Die Head-Dimensionen von MLA sind groß: Query und Key sind 576 breit (ein 512 breiter "Nope"-Teil ohne Positional Encoding, plus ein 64 breiter "Rope"-Teil), und der Value ist 512. Also acc_o = [block_M, 512], und es muss während der gesamten KV-Schleife in den Registern resident bleiben.
Nun zur Hardware. Auf Hopper ist der schnelle Pfad wgmma.mma_async, der 4 Warps (128 Threads) zu einer Warpgroup verbindet und ein Mindest-M von 64 erfordert. Das kleinste M, das eine Warpgroup besitzen kann, ist also 64, was bedeutet, dass eine Warpgroup einen 64 × 512 Akkumulator halten würde. Das ist zu groß für die Registerdatei einer einzelnen Warpgroup. Es gibt Spill, und die Performance stürzt ab.
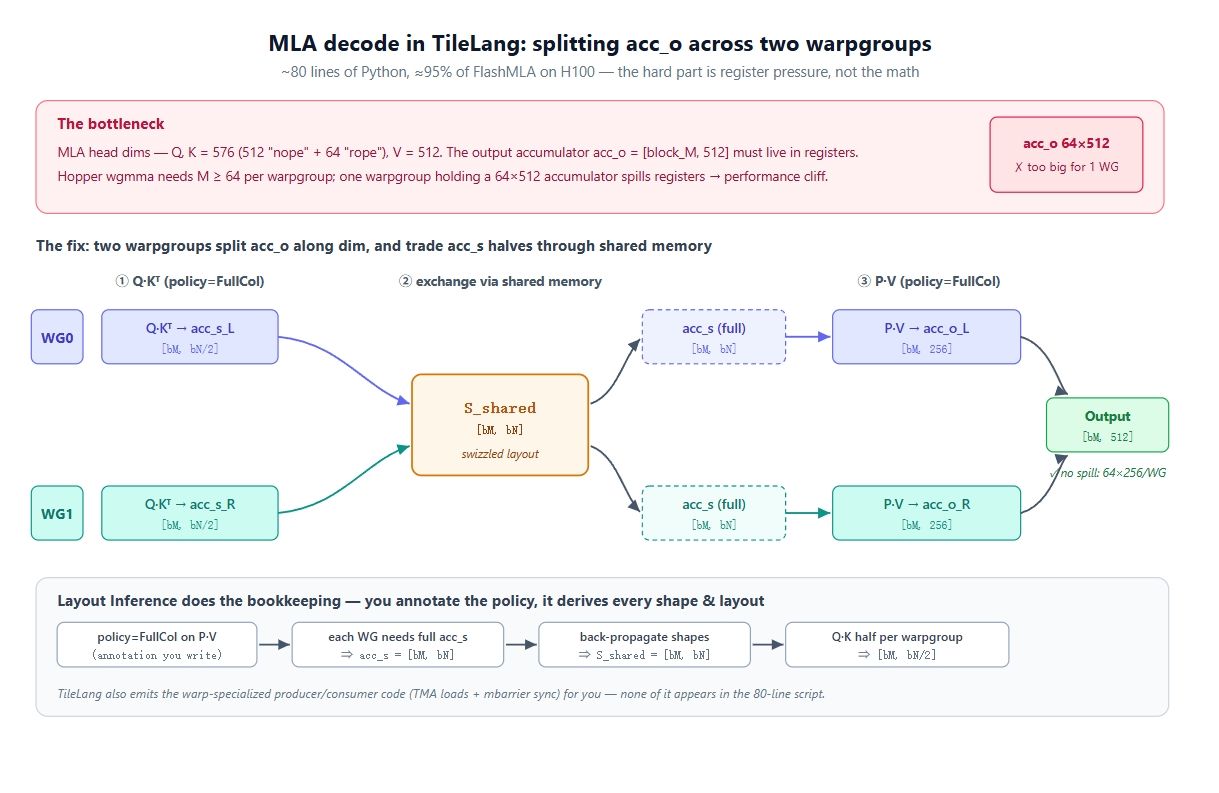
Die Lösung ist, die Ausgabe auf zwei Warpgroups aufzuteilen. Sie können M nicht unter 64 verkleinern, also bleibt nur die Dimension-Achse. Verwenden Sie zwei Warpgroups: WG0 besitzt acc_o[:, :256], WG1 besitzt acc_o[:, 256:]. Jetzt hält jede einen 64 × 256 Akkumulator, was passt. Das schafft jedoch ein zweites Problem: Der P @ V-Schritt (mit policy=FullCol, wobei jede Warpgroup einen Spalten-Slab der Ausgabe produziert) benötigt das vollständige acc_s, aber bei Q @ K hat jede Warpgroup natürlicherweise nur die Hälfte berechnet. Die Lösung ist ein Shared-Memory-Swap. Während Q @ K schreibt jede Warpgroup ihre Hälfte von acc_s in den Shared Memory und liest die Hälfte der anderen Warpgroup zurück, sodass danach beide das vollständige acc_s halten und jeweils ihren Slab von acc_o berechnen können. Das Diagramm oben ist genau das: Scores aufteilen, über S_shared tauschen, Ausgabe aufteilen.
In CuTe würden Sie die Layouts, die Swizzles, das Tensor-Core-Alignment und die Producer/Consumer-Synchronisation von Hand schreiben, um das zu erreichen. Der Grund, warum es hier auf ~80 Zeilen kollabiert, ist die Layout-Inference.
Schlüsseln wir auf, was Layout-Inference tut. Sie annotieren die Absicht bei den T.gemm-Aufrufen, und sie propagiert die Constraints für Sie durch das Programm:
- policy=FullCol bei P @ V bedeutet, dass jede Warpgroup das vollständige acc_s benötigt, also acc_s = [block_M, block_N].
- Das propagiert zurück zum Staging-Puffer, also ist S_shared in T.copy(S_shared, acc_s) ebenfalls [block_M, block_N].
- Und vorwärts in Q @ K: Mit FullCol ist das Score-Slab jeder Warpgroup [block_M, block_N/2].
Die wichtige Erkenntnis ist, dass Sie nie eine dieser Shapes selbst schreiben. Sie wählen die Warp-Policy und schreiben die Mathematik; die Shapes, die geswizzelten Layouts und der Warp-spezialisierte Producer/Consumer-Code ergeben sich alle aus der Inference.
Das Kernel-Skelett. Beim MLA-Decode teilt sich die Query in einen "Nope"-Teil (Q, dim 512) und einen "Rope"-Teil (Q_pe, dim 64) auf, und der komprimierte Latent dient sowohl als K als auch als V. Der Score ist also eine Summe aus zwei GEMMs, und die Ausgabe ist eine weitere. Die innere Schleife sieht so aus (ein repräsentatives Skelett, siehe example_mla_decode.py):
python1# acc_s = Q_nope @ KV^T + Q_rope @ K_pe^T 2T.gemm(Q_shared, KV_shared, acc_s, transpose_B=True, 3 policy=T.GemmWarpPolicy.FullCol, clear_accum=True) 4T.gemm(Q_pe_shared, K_pe_shared, acc_s, transpose_B=True, 5 policy=T.GemmWarpPolicy.FullCol) 6 7# Online Softmax 8T.copy(scores_max, scores_max_prev) 9T.fill(scores_max, -T.infinity(accum_dtype)) 10T.reduce_max(acc_s, scores_max, dim=1, clear=False) 11# ... exp, rescale acc_o durch scores_scale, reduce_sum in logsum ... 12 13# acc_o += P @ V (V ist derselbe latente KV) 14T.copy(acc_s, acc_s_cast) 15T.gemm(acc_s_cast, KV_shared, acc_o, policy=T.GemmWarpPolicy.FullCol)
Der S_shared-Austausch zwischen den beiden Warpgroups ist der Teil, den die Inference für Sie einfügt, sobald die FullCol-Policies erzwingen, dass acc_s pro Warpgroup vollständig sein muss.
Das Schöne daran: Die Optimierungen sind jeweils nur eine Zeile. Hier zahlt sich TileLang aus – das gesamte Performance-Toolkit besteht aus Einzeilern, und das mühsame Lowering wird für Sie erledigt.
- Threadblock-Swizzling für L2-Wiederverwendung: T.use_swizzle(panel_size, order="row").
- Shared-Memory-Swizzling gegen Bank-Konflikte: T.annotate_layout({S_shared: T.layout.make_swizzled_layout(S_shared)}) — XOR-Style Adress-Remapping, damit gleichzeitige Zugriffe über Banken verteilt werden statt zu serialisieren.
- Warp-Spezialisierung: Sie schreiben ein einfaches Skript, und es wird in eine Producer-Warpgroup (TMA-Loads) plus Consumer-Warpgroups umgewandelt, wobei die mbarrier-Synchronisation generiert wird. Nichts davon taucht in Ihrem Code auf.
- Pipelining: T.Pipelined(range, num_stages) überlappt Ladevorgänge mit Berechnungen – mehr Stages, mehr Überlappung, aber mehr Shared Memory.
- Split-KV (FlashDecoding-Stil): Wenn der Batch klein ist und die SMs im Leerlauf sind, teilen Sie den KV-Kontext über SMs auf und führen ihn zusammen. Es ist ein num_split-Parameter plus ein Combine-Kernel.
Die wirklich schwierige Überlegung – Register-Budget gegen das M≥64-Minimum, wer besitzt was über Warpgroups hinweg, der Shared-Memory-Swap – drücken Sie aus, indem Sie eine Policy wählen und die Mathematik schreiben. Alles, was in CuTe hunderte fragile Zeilen wären, ist hier Inference und Codegen. Das ist das Pitch, und MLA ist der Bereich, in dem es am überzeugendsten ist.
Eines unserer Beispiele: ein Drop-in RMSNorm bei AtlasCloud
Das letzte Beispiel ist einer unserer Produktions-Kernel bei AtlasCloud, aus der Wan-Video-Generierung VAE auf H100/H200. Es ist eine großartige Illustration der anderen Stärke von TileLang: eine Konfiguration abzudecken, die ein handoptimierter Kernel nicht erreichen kann, mit einem sauberen Drop-in.
Das Setup. Wir liefern bereits einen handoptimierten, gefusten RMSNorm + SiLU-Kernel aus. Er ist schnell und für die versteckten Dims D ∈ {96, 192, 384} kompiliert, die eine Modell-Konfiguration verwendet. Eine neuere Konfiguration benötigt Kanalbreiten wie {160, 256, 320, 512, 640, 1024}. Wir haben ein TileLang-Drop-in geschrieben, um genau diese Lücke zu schließen.
Der TileLang-Kernel. Ein Drop-in mit derselben Schnittstelle (BTHWC in/out, gleiche Mathematik, gleiches Eps), das jedes C unterstützt, das ein Vielfaches von 32 ist. Zwei Durchläufe, vollständig coalesced, FP32-Akkumulator:
python1@T.prim_func 2def main(X: T.Tensor((M, C), dtype), # M = B*T*H*W Zeilen 3 gamma: T.Tensor((C,), dtype), 4 Y: T.Tensor((M, C), dtype)): 5 with T.Kernel(T.ceildiv(M, BLOCK_M), threads=128) as bm: 6 X_chunk = T.alloc_shared((BLOCK_M, BLOCK_C), dtype) 7 ss = T.alloc_fragment((BLOCK_M,), accum_dtype) # FP32 Quadratsumme 8 # Durchgang 1: Schleife über C in BLOCK_C-Chunks, akkumuliere Quadratsumme in FP32 9 # rinv = rsqrt(ss / C + 1e-5) 10 # Durchgang 2: Lade X neu, y = silu(x * gamma * rinv), schreibe zurück
BLOCK_C ist 128/64/32 je nach C, um das TMA-BoxDim ≤ 256 Limit einzuhalten, und der FP32-Akkumulator verhindert, dass die Quadratsumme in FP16 überläuft. Der Dispatch behält den handoptimierten Pfad bei, wo er funktioniert, und fällt nur zurück, wenn er muss:
python1_ATLAS_SUPPORTED_D = (96, 192, 384) 2 3def rms_silu_dispatch(x, gamma, out): 4 if x.shape[-1] in _ATLAS_SUPPORTED_D: 5 atlas_rms_norm_silu(x, gamma, out=out) # handoptimierten Pfad behalten 6 else: 7 tilelang_rms_silu_bthwc(x, gamma, out=out) # Lücke abdecken
Was es uns gebracht hat. Nur Vorteile, und es ist ein echtes Drop-in – gleiche Schnittstelle, gleiche Mathematik, gleiches Eps, sodass es ohne Änderungen an der Aufrufstelle hinter den bestehenden Dispatch passt.
| Was | Gewinn |
|---|---|
| Bisher nicht unterstützte Konfiguration | 0 → 1 — es läuft jetzt (der Hauptgewinn) |
| Attention-Block RMSNorm vs. die Eager-PyTorch-Norm, die es ersetzt hat | 42 μs → 20 μs (~2× schneller) |
| End-to-End VAE bei Produktionsauflösung (720×1280, 21 Frames) | ~1.79× Encode, ~1.78× Decode |
Die erste Zeile ist der eigentliche Punkt: TileLang erlaubte uns, eine Modell-Konfiguration zu bedienen, die zuvor keinen schnellen Pfad hatte, ohne den handoptimierten Kernel zu berühren, der bereits für die andere Konfiguration funktioniert. Ein Drop-in, in Python geschrieben, und ein ganzer Modellpfad wurde von "wirft Fehler" zu "produktiv".
Wo TileLang glänzt
- Feine Kontrolle über Blocking, Pipeline-Stufen und Warp-Partitionierung, ohne CUTLASS/CuTe schreiben zu müssen.
- Strukturell komplexe, layout-sensitive Kernel: GEMM-Varianten, die FlashAttention-Familie, MLA, lineare Attention, dequant-fused quant GEMM, MoE-Routing.
- Abdeckung eines Ops oder einer Konfiguration, die Ihre handoptimierten Kernel nicht erreichen (eine versteckte Dimension außerhalb des instanziierten Sets, ein ungewöhnliches Layout) – und dabei einen Eager-Fallback schlagen.
- Ein Kernel-Body über Backends hinweg (NVIDIA / AMD / Vendor-Forks).
- Das gesamte Optimierungs-Toolkit ist ein Aufruf nach dem anderen – T.use_swizzle, T.annotate_layout, T.Pipelined, Warp-Spezialisierung, Split-KV – wobei das Lowering für Sie erledigt wird.
Fazit
Das Coole an TileLang ist, dass die schwierige logische Arbeit in Ihrem Kopf bleibt, nicht in Boilerplate-Code. Sie entscheiden, wie die Arbeit auf Warps aufgeteilt wird, wo Puffer liegen und wie tief die Pipeline läuft – und dann machen Layout-Inference und Warp-Spezialisierung daraus die Register-Layouts, die Swizzles und den Producer/Consumer-Tanz, die ansonsten hunderte Zeilen CuTe wären. Sie wählen eine Policy und schreiben die Mathematik. Das ist das ganze Pitch, und deshalb kann ein 80-zeiliger MLA-Kernel neben einem handoptimierten CUTLASS-Kernel existieren.






