Resumen: GLM-5-Turbo, desarrollado por Zhipu AI (Z.ai), es un modelo de lenguaje de gran tamaño diseñado para casos de uso de OpenClaw y es el primer lanzamiento de código cerrado de la compañía (previamente probado bajo el nombre en clave Pony-Alpha-2), cuyo lanzamiento en Atlas Cloud está programado próximamente.
El modelo ofrece mejoras significativas en el uso de herramientas, ejecución de instrucciones, flujos de trabajo de múltiples pasos y manejo de tareas a largo plazo, al mismo tiempo que admite una ventana de contexto de hasta 200 mil tokens. Sus capacidades de análisis de datos son comparables a las de Claude Opus 4.6 y supera a GLM-5 en tareas de automatización y procesamiento de información. Al aprovechar la API unificada y el ecosistema multimodal de Atlas Cloud, GLM-5-Turbo permite una implementación eficiente en la automatización empresarial compleja, el análisis de documentos largos y el desarrollo de software, ofreciendo una solución de IA rentable y de fácil integración para desarrolladores y empresas.
¡Nos complace anunciar que GLM-5-Turbo llega a Atlas Cloud!
- Qué es GLM-5-Turbo: Desarrollado por Zhipu AI (Z.ai), GLM-5-Turbo es un modelo de lenguaje de gran tamaño diseñado para casos de uso de OpenClaw. Marca el primer lanzamiento de código cerrado del equipo, ofreciendo una mayor eficiencia en tiempo de ejecución que GLM-5 a un menor costo por llamada. Anteriormente, Zhipu AI había probado de forma informal su modelo de próxima generación bajo el nombre en clave Pony-Alpha-2.
- Características principales: GLM-5-Turbo ofrece mejoras sustanciales en el uso de herramientas, seguimiento de instrucciones, flujos de trabajo de múltiples pasos y ejecución persistente de tareas. Admite modos de razonamiento dinámico en varios escenarios, salida en tiempo real (streaming), integración mejorada de herramientas y manejo de contextos largos de hasta 200 mil tokens.
- Fecha de lanzamiento: 24/03/2026.
GLM-5 atrajo la atención anteriormente como el modelo de código abierto con mejor rendimiento en el Artificial Analysis Intelligence Index, superando a Gemini 3 Pro. Como su sucesor, GLM-5-Turbo introduce una serie de actualizaciones iterativas, detalladas a continuación.
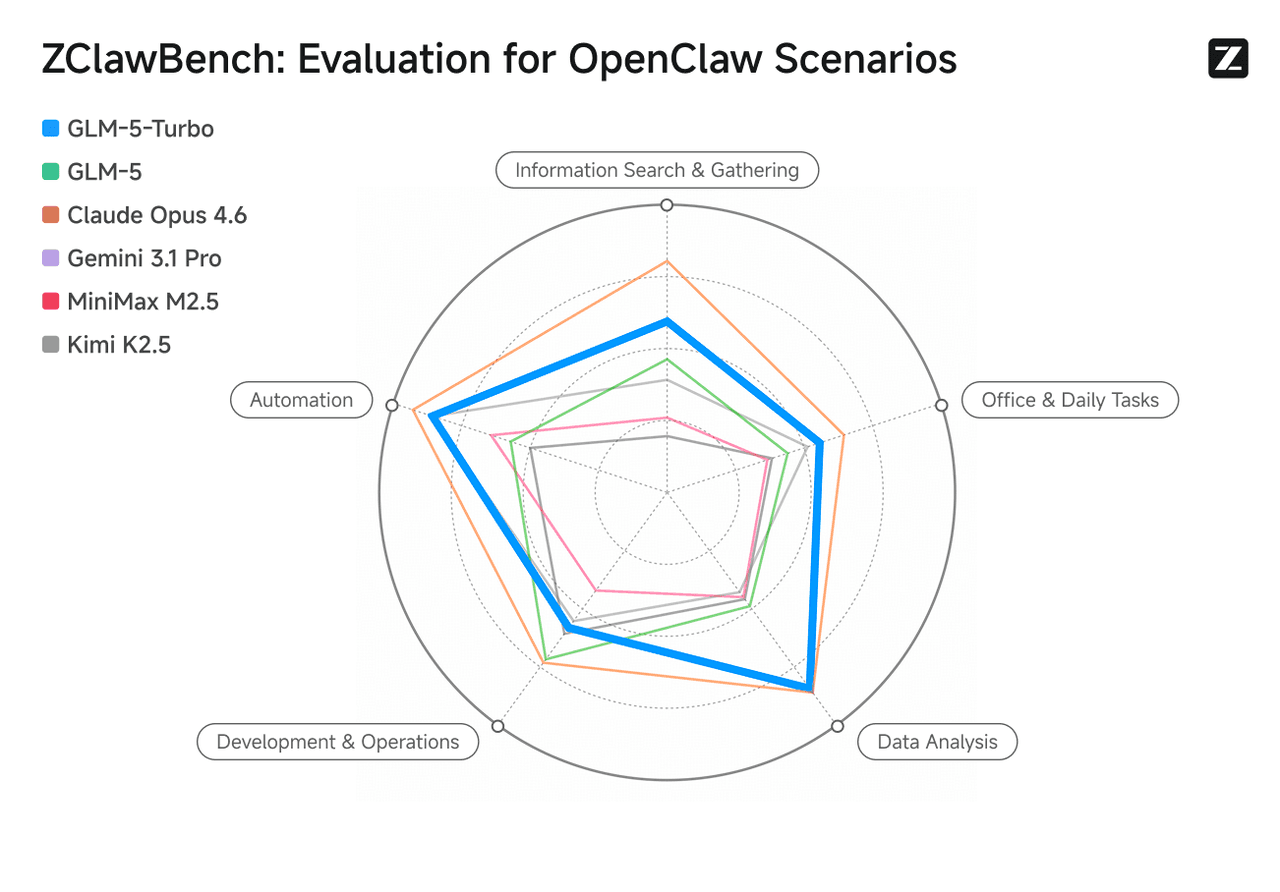
Posicionamiento central: un modelo optimizado para ClawBench
Sólido rendimiento en benchmarks
Optimizado para escenarios OpenClaw, GLM-5-Turbo mejora significativamente las capacidades en invocación de herramientas, ejecución de instrucciones y orquestación de tareas complejas. Su rendimiento en análisis de datos está a la par con Claude Opus 4.6, superando a GLM-5 en automatización, recuperación de información, productividad de oficina y tareas analíticas.
Fuente de la imagen: sitio web oficial de Zhipu AI (Z.ai).
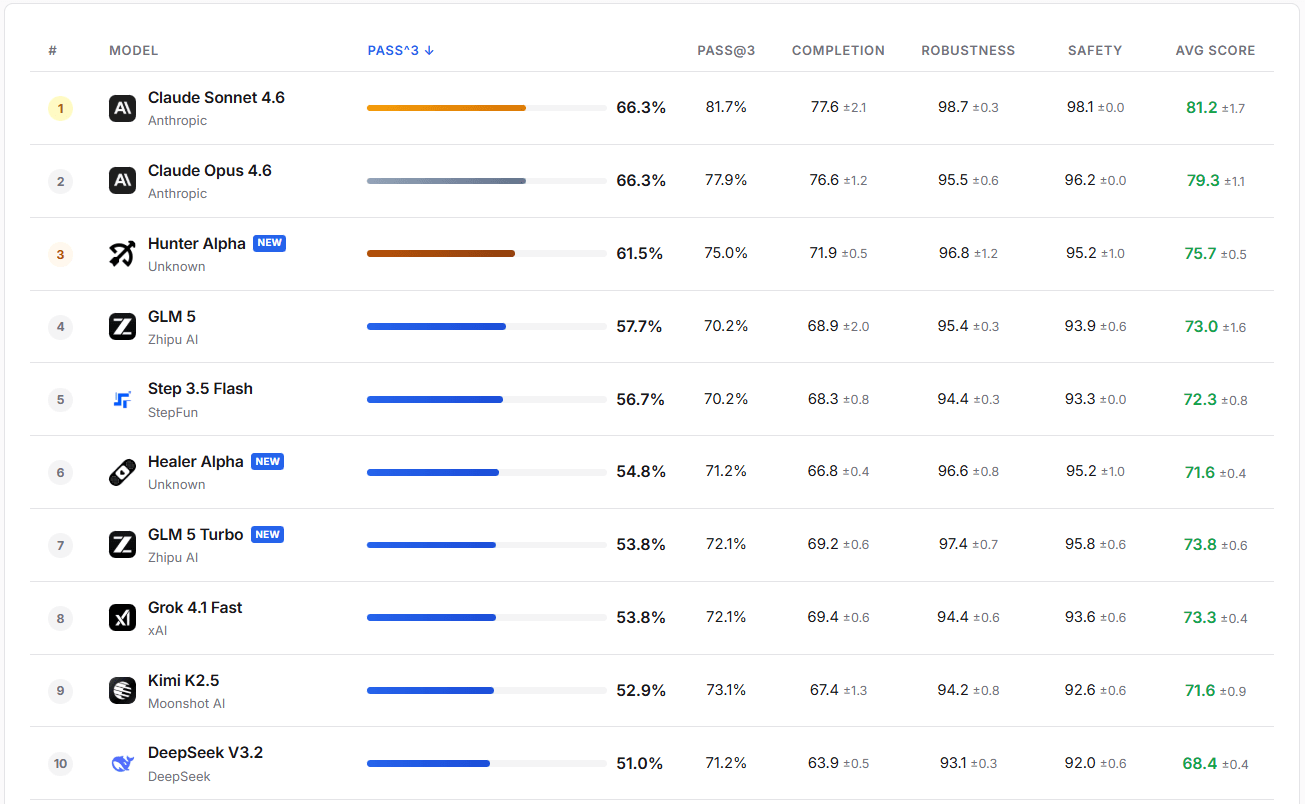
En evaluaciones prácticas, GLM-5-Turbo demuestra una gran robustez y seguridad. Su tasa de éxito PASS@3 supera a la de GLM-5, Step 3.5 Flash y Kimi K2.5.
Fuente de la imagen: https://claw-eval.github.io/
Uso mejorado de herramientas e integración externa
Z.ai ha reforzado las capacidades de agente de GLM-5-Turbo durante su entrenamiento, permitiendo una interacción fluida con herramientas externas. Esta orientación basada en la ejecución conlleva concesiones: algunos usuarios reportan un tono ligeramente más mecánico en comparación con GLM-5 en escenarios de juegos de rol.
Para adaptarse a las diversas fortalezas de los modelos, Atlas Cloud proporciona una interfaz unificada que permite a los usuarios consultar varios modelos simultáneamente, facilitando la comparación y selección lado a lado.
Además, los usuarios pueden definir habilidades personalizadas o permitir que GLM-5-Turbo las descubra e instale de forma autónoma.
Fuente de la imagen: Atlas Cloud

Ejecución autónoma a largo plazo
GLM-5-Turbo está optimizado para tareas que requieren disparadores programados o tiempos de ejecución extendidos. Maneja flujos de trabajo persistentes, de múltiples etapas y temporales con una sólida continuidad de tareas.
El modelo sugiere de forma proactiva estrategias de ejecución basadas en la complejidad de la tarea. En pruebas comparativas de optimización de código, GLM-5-Turbo generó recomendaciones que superaron a los modelos de la competencia en aproximadamente el 10% de los casos.
Ventana de contexto de 200 mil tokens
Con soporte para hasta 200 mil tokens (aproximadamente 133,000 palabras en inglés), GLM-5-Turbo puede retener y utilizar un contexto extenso dentro de una sola sesión. Esto permite una recuperación precisa de información previa, incluso en etapas avanzadas de una conversación.
Fuente de la imagen: Jim Allen Wallace (Redis)
Casos de uso
Automatización de flujos de trabajo complejos
Con sus capacidades OpenClaw mejoradas, GLM-5-Turbo puede descomponer procesos de negocio complejos, identificar la lógica subyacente y localizar o generar autónomamente las habilidades necesarias para ejecutar tareas.
Por ejemplo, en la producción de videos cortos, el modelo puede buscar, instalar y orquestar herramientas de escritura, generación de imágenes y producción de video, planificando y ejecutando todo el flujo de trabajo de principio a fin.
Preguntas y respuestas sobre documentos largos y análisis profundo
El modelo mantiene el contexto completo a través de documentos largos dentro de una única sesión, lo que permite respuestas precisas a preguntas de varios turnos. Su alta eficiencia de tokens garantiza respuestas rápidas con un menor costo computacional.
En bases de código a gran escala, GLM-5-Turbo puede analizar el diseño arquitectónico, mapear dependencias entre componentes y señalar posibles efectos en cascada a partir de cambios de código de bajo nivel.
“Vibe Coding”
Dentro del ciclo de vida del desarrollo de software, GLM-5-Turbo funciona más como un ingeniero full-stack integrado en flujos de trabajo complejos. Los desarrolladores pueden definir la lógica de alto nivel mientras el modelo construye incrementalmente la arquitectura de la aplicación en tiempo real.
Combinado con habilidades multimodales, los usuarios pueden cargar imágenes de UI, grabaciones de pantalla o bocetos, que el modelo puede convertir directamente en componentes frontend funcionales.
¿Por qué usar GLM-5-Turbo en Atlas Cloud?
Como plataforma de infraestructura de IA multimodal, Atlas Cloud proporciona a los usuarios una interfaz API unificada. Una vez conectado, los usuarios pueden desbloquear fácilmente más de 300 modelos de IA avanzados, incluyendo modelos de generación de texto, imágenes, video o multimodales.
Público objetivo
- Desarrolladores independientes que buscan soluciones simplificadas y de bajo costo para llamar a varios modelos de IA.
- Empresas que requieren una infraestructura estable, segura y escalable para respaldar sus actividades principales.
- Equipos de desarrollo que necesitan integrar eficientemente múltiples modelos multimodales en sus proyectos.
- Usuarios de flujos de trabajo que priorizan la compatibilidad de cadenas de herramientas y utilizan ComfyUI o n8n.
Características del producto
- Integración muy simplificada: La plataforma proporciona una API compatible con OpenAI, lo que simplifica instantáneamente la carga de trabajo del desarrollador. No hay que hacer malabares con múltiples claves de proveedores ni preocuparse por los costos de mantenimiento entre plataformas.
- Ventaja de costos: En comparación con la competencia, Atlas Cloud tiene costos de implementación más bajos. Nano Banana 2 cuesta USD0.056/imagen (competidor: USD0.07/imagen); Veo 3.1 tiene un precio de USD0.09/segundo (competidor: USD0.1/segundo). Además, la interfaz Playground ofrece transparencia total de precios, con el botón "Run" etiquetando directamente el monto de la deducción por imagen o segundo de video.
- Estabilidad y soporte de nivel empresarial: Atlas Cloud garantiza que la protección de datos cumpla con estrictos estándares de privacidad y pueda manejar información sensible.
- Listo para usar (Plug-and-Play): Diseñado para funcionar sin esfuerzo con herramientas como ComfyUI y n8n, ayudando a las empresas a reducir los costos de cambio y comenzar a trabajar de inmediato.
Comparación con productos similares
- Fal.ai: Aunque ofrecen algunos modelos, Atlas Cloud ofrece una selección más amplia (más de 300), precios más competitivos y los nuevos usuarios registrados reciben un crédito de prueba de USD1.
- Wavespeed: El precio es significativamente más alto. Atlas Cloud ofrece soporte adicional de cumplimiento empresarial y orientación técnica experta que Wavespeed no enfatiza.
- Kie.ai: Utiliza un sistema de crédito opaco. Atlas Cloud muestra el costo exacto de cada ejecución directamente en la interfaz. El recuento de modelos también es mayor que el de Kie.ai.
- Replicate: Se centra en el alojamiento de modelos. Las ventajas de Atlas Cloud radican en la unificación de API, la velocidad de despliegue de modelos y políticas de soporte más amigables para los desarrolladores.
- OpenAI o Google: Estos proveedores solo ofrecen sus propios modelos. Los usuarios con necesidades multimodales generalmente necesitan integrar múltiples servicios. Atlas Cloud integra modelos propietarios y de código abierto bajo una única API, lo que reduce la complejidad del sistema.
¿Cómo usar GLM-5-Turbo en Atlas Cloud?
Método 1: Usar directamente en la plataforma
Método 2: Usar mediante integración de API
Paso 1: Obtenga su API Key. Cree y pegue su clave API en la consola:


Paso 2: Consulte la documentación de la API. Verifique los parámetros de solicitud, los métodos de autenticación, etc.
Paso 3: Realice su primera solicitud (ejemplo en Python)
GLM-5 como ejemplo.
plaintext1{ 2 "model": "zai-org/glm-5", 3 "messages": [ 4 { 5 "role": "user", 6 "content": "Hello" 7 } 8 ], 9 "max_tokens": 1024, 10 "temperature": 0.7, 11 "stream": false 12}
Preguntas frecuentes (FAQ)
¿Cuál es la diferencia entre GLM-5-Turbo y GLM-5? GLM-5-Turbo es más rápido y rentable, con una eficiencia de tokens significativamente mejorada (se informa que es hasta tres veces superior a la de GLM-5). También está optimizado específicamente para escenarios OpenClaw.
¿Cómo se compara GLM-5-Turbo con MiniMax M2.7? Ambos modelos están optimizados para el uso de herramientas con agentes y cuentan con una mayor eficiencia de tokens que GLM-5. Cada uno admite ventanas de contexto de alrededor de 200 mil tokens (MiniMax M2.7 admite 196,608 tokens). Estamos preparando una publicación en el blog para una evaluación comparativa más detallada. ¡Estén atentos!
¿Qué modelo GLM se recomienda para la implementación de OpenClaw? GLM-5-Turbo, ya que está específicamente optimizado para escenarios OpenClaw y logra un rendimiento de análisis de datos comparable al de Claude Opus 4.6.






