Gemini Omni representa un cambio importante respecto a los sistemas de IA tradicionales. Funciona como un modelo de IA todo en uno que procesa la información de forma natural desde el inicio. En lugar de unir diferentes herramientas para distintos tipos de medios, funciona completamente sobre un motor neuronal universal. Al procesar texto, imagen, audio y video dentro de un espacio vectorial multimodal singular, elimina por completo los silos de datos heredados y los cuellos de botella en la comunicación.
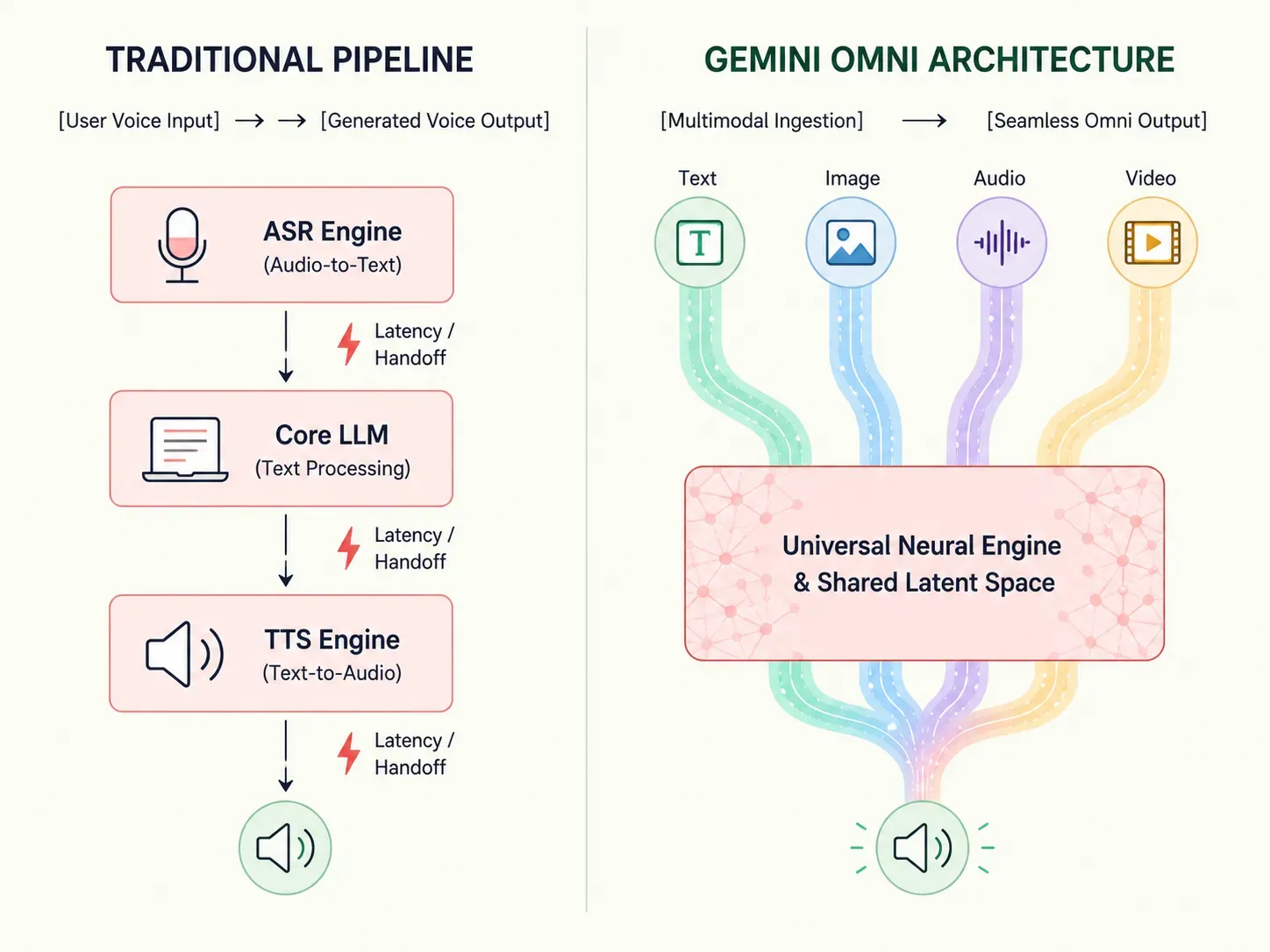
La inteligencia artificial tradicional depende de procesos escalonados: convertir voz a texto antes de que un modelo de lenguaje pueda siquiera comenzar a procesar una respuesta. Gemini Omni redefine fundamentalmente este flujo de trabajo.
- Ingesta nativa: El sistema procesa tokens de texto, píxeles de imagen, frecuencias de audio y fotogramas de video simultáneamente.
- Preservación del contexto: El procesamiento de datos de extremo a extremo evita que las emociones sutiles, las señales visuales y los pequeños detalles se pierdan entre diferentes capas.
Este cambio estructural aumenta la eficiencia del procesamiento y reduce las demoras a tiempos de respuesta casi humanos. Los desarrolladores y las empresas ahora pueden prescindir de complejas configuraciones de modelos múltiples y confiar en un sistema sólido construido para la computación multisensorial real.
Cómo un modelo procesa cuatro modalidades simultáneamente
Para entender cómo las funcionalidades de Gemini Omni procesan texto, imágenes, audio y video al mismo tiempo, debemos observar directamente su capa de datos central. Los sistemas tradicionales dirigen los diferentes tipos de archivos a través de submodelos aislados y separados. Gemini Omni evita por completo este método fragmentado. Implementa un marco de tokenización unificado que traduce de forma nativa todas las entradas a un lenguaje singular que el núcleo de la IA comprende.
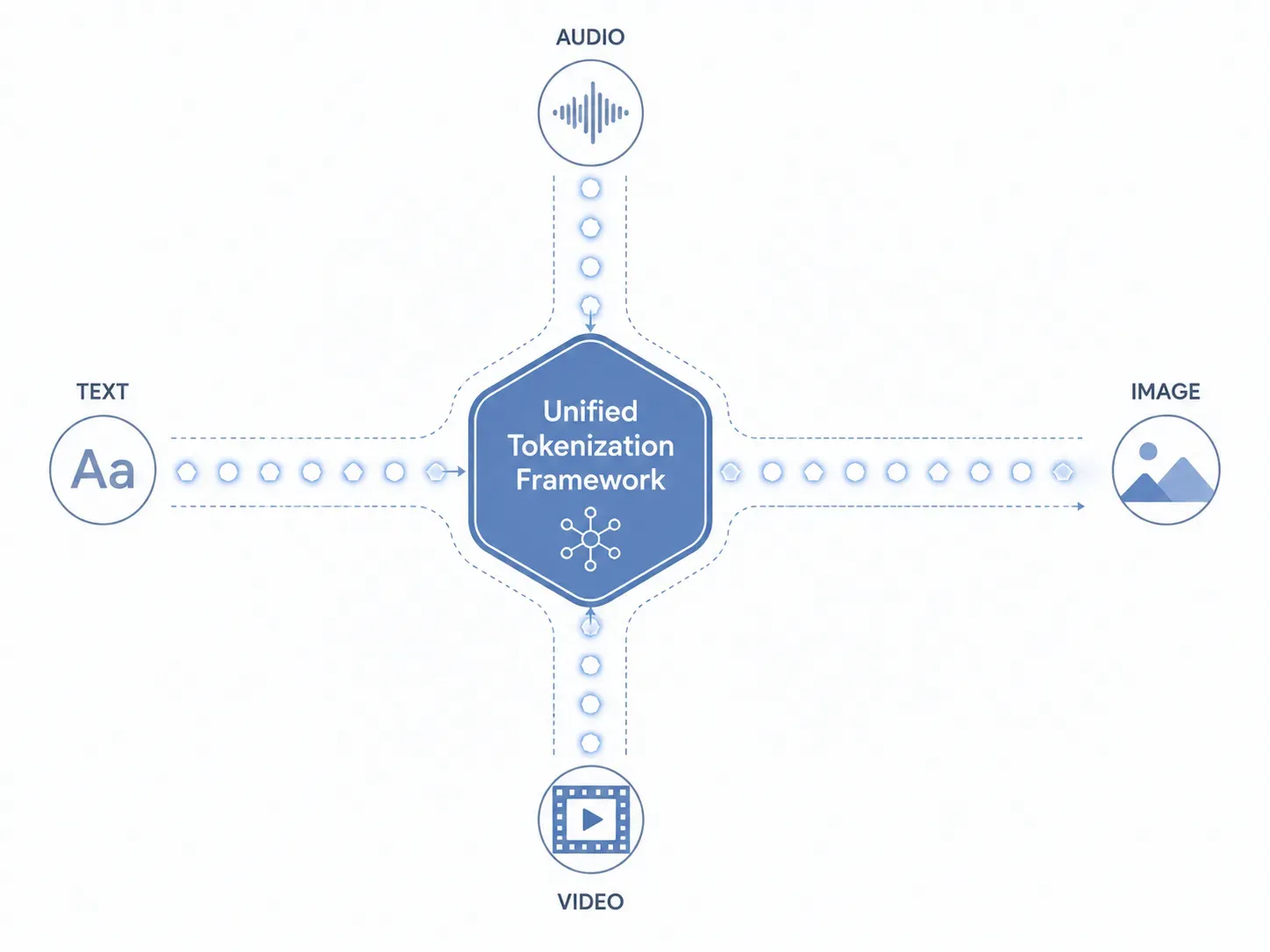
La mecánica de la tokenización unificada
¿Cómo maneja Gemini Omni diferentes tipos de archivos sin submodelos separados? La respuesta radica en cómo se ingieren y descomponen los datos antes de que comience la inferencia:
- Texto: Los caracteres alfanuméricos se convierten en tokens de texto semántico estándar.
- Imágenes: Los elementos visuales se dividen en pequeños parches de píxeles y se asignan como tokens visuales.
- Audio: Las ondas sonoras continuas se muestrean, capturando frecuencia y tono, y se transforman en tokens acústicos.
- Video: Las imágenes en movimiento se tratan como una secuencia continua de fotogramas temporales, estableciendo tokens espacio-temporales.
Pesos compartidos y procesamiento nativo de tensores
Una vez que esta diversa ingesta de datos multimodal se completa, todos los tipos de datos ingresan a una arquitectura de pesos compartidos. En lugar de utilizar codificadores especializados individuales que pasan datos de un lado a otro a través de puentes que inducen latencia, una única red neuronal central procesa todos los tokens de manera uniforme.
Utilizando procesamiento nativo de tensores, el modelo ejecuta cálculos matemáticos sobre tokens de texto, audio y visuales dentro de las mismas capas matriciales. Debido a que todo comparte el mismo espacio computacional, la red entiende directamente la relación entre una palabra hablada, una oración escrita, un píxel de imagen y un fotograma de video sin un solo paso de traducción.
Para ver estos principios de ingeniería y la tokenización nativa implementados a gran escala en escenarios del mundo real, vea la presentación "MIT Media Lab Research Vision". Esta presentación describe el cambio a largo plazo de la industria hacia la conexión de modelos de IA directamente con un rico espectro de señales del mundo físico y multisensorial:
Los pilares modales básicos: Mapa de procesamiento multimedia
Para comprender realmente el poder de Gemini Omni, hay que mirar más allá de la simple ingesta de datos. El modelo utiliza una arquitectura unificada donde el texto, las imágenes, el audio y el video existen dentro de un mapeo de espacio latente compartido. Cuando una entrada cambia en una modalidad, no solo activa una reacción aislada, sino que cambia dinámicamente los parámetros matemáticos de los otros tres formatos exactamente al mismo tiempo.
La matriz de interdependencia multimodal
Esta inferencia multimedia en tiempo real depende de flujos de datos interdependientes. En lugar de procesar datos en bloques secuenciales, el modelo sincroniza continuamente los cuatro pilares para lograr una alineación multimodal perfecta.
El siguiente mapa de procesamiento describe exactamente cómo estas entradas en vivo se influyen entre sí dentro de la red neuronal universal:
| Entrada de medio principal | Modalidades co-procesadas | Operación del sistema | Intención técnica profunda |
| Ondas acústicas | Texto + Fotogramas de video | Rastrea la cadencia de voz para indexar secuencias de video temporales | Alineación sensorial en tiempo real |
| Imágenes estáticas | Audio crudo + Texto | Traduce espectros de color visual a acústica contextual coincidente | Síntesis multimodal |
| Código alfanumérico | Matrices de video + Texto | Modifica variables de video estructurales directamente mediante lógica de programación | Ejecución de código generativo |
| Secuencias de video temporales | Pistas de audio + Código | Calcula actualizaciones espacio-temporales en pistas de datos multicapa | Análisis unificado de video-audio |
Sincronización de parámetros en tiempo real en acción
Cuando Gemini Omni procesa una transmisión de video en vivo, no separa las imágenes de la pista de fondo. Si la entrada de audio registra un aumento repentino en la frecuencia, como una persona gritando, el modelo actualiza instantáneamente sus expectativas de tokens visuales. Anticipa un movimiento físico rápido o un cambio en los fotogramas del video antes de que ocurran.
Esta profunda influencia cruzada evita la desviación del contexto. Debido a que toda la red equilibra estas variables simultáneamente, la salida permanece perfectamente coherente, ya sea que el modelo esté generando un resumen de video sincronizado o traduciendo una transmisión multisensorial en vivo sobre la marcha.
Eliminación de latencia y desviación de contexto: La ventaja de los pesos unificados
Para apreciar la velocidad de Gemini Omni, ayuda observar las ineficiencias matemáticas de las tuberías de IA "cosidas" tradicionales. Históricamente, crear un asistente capaz de manejar voz o video requería encadenar capas de software separadas y de un solo propósito.
plaintext1[Entrada de voz del usuario] 2 │ 3 ▼ 4 1. Motor ASR (Transcripción de audio a texto) 5 │ 6 ▼ 7 2. Capa de LLM central (Procesamiento de generación de texto) 8 │ 9 ▼ 10 3. Motor TTS (Síntesis de texto a audio) 11 │ 12 ▼ 13[Salida de voz generada]
Esta orquestación de varios pasos obliga a los datos a viajar a través de puentes de software continuos, lo que agrava los retrasos en la ejecución. El motor de texto a voz separado no puede escuchar la grabación de audio original. Esto causa una gran pérdida de datos en diferentes tipos de medios. Las señales vocales importantes, como el tono sarcástico, las vacilaciones o la angustia emocional de un usuario, desaparecen por completo cuando todo se aplana en texto sin formato.
Lograr una verdadera reducción de la latencia del flujo de trabajo
Gemini Omni elude estos límites operando sobre pesos neuronales unificados. Debido a que una sola red neuronal evalúa de forma nativa texto, audio y píxeles bajo un mismo techo matemático, escala las velocidades de ejecución de manera espectacular. Esta disposición produce una profunda reducción de latencia en la tubería.
Según los informes de evaluación comparativa de Google DeepMind, las arquitecturas multimodales nativas que ejecutan transmisiones de audio en vivo reducen los tiempos de respuesta de extremo a extremo a menos de 150 milisegundos. Este cambio iguala efectivamente el ritmo natural de la conversación humana en tiempo real.
Optimización de la retención de contexto
Más allá de la velocidad, la ejecución unificada garantiza un alto nivel de optimización de la retención de contexto. Cuando habla con el modelo, los pesos procesan sus frecuencias de audio junto con sus definiciones textuales simultáneamente.
- Procesamiento de entonación: La red captura modulaciones vocales directamente, respondiendo con la empatía o urgencia apropiadas.
- Sincronización visual: Las microexpresiones faciales sutiles o los movimientos espaciales dentro de un fotograma de video se traducen directamente en la salida conversacional sin errores de análisis.
Al eliminar los pasos de traducción intermedios, Gemini Omni evita que los pequeños detalles se desvanezcan. Esto construye una base sólida para interacciones fluidas y naturales entre humanos y máquinas a través de diferentes sentidos.
Construcción de flujos de trabajo empresariales con sistemas de IA omnicanal
Este cambio hacia la multimodalidad nativa cambia la forma en que las empresas crean y escalan herramientas digitales. Al utilizar una configuración de IA única, las empresas pueden reemplazar piezas de software desordenadas y separadas con flujos de trabajo unificados. Esto les permite ejecutar sistemas interactivos de medios mixtos fácilmente a gran escala.
La arquitectura de API única
Los desarrolladores ya no necesitan coordinar funciones en la nube dispares para el reconocimiento de voz, el análisis de texto y el procesamiento de imágenes. En cambio, una única integración de API unificada conecta la capa de aplicación directamente con la red central, como la API del modelo Atlas Cloud AI. Este camino simplificado permite a los equipos construir tuberías multimedia avanzadas con un marco de solicitud único.
plaintext1 ┌─────────────────────────────────┐ 2 │ API de Gemini unificada │ 3 └────────────────┬────────────────┘ 4 │ 5 ┌─────────────────────────┼─────────────────────────┐ 6 ▼ ▼ ▼ 7┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ 8│ Código en │ │ Capa de │ │ Dashboards │ 9│ tiempo real │ │ automatización │ │ multisensoriales │ 10└──────────────────┘ └──────────────────┘ └──────────────────┘
Por ejemplo, una plataforma de capacitación empresarial puede procesar una transmisión de video en vivo, rastrear la cadencia de audio de un orador, traducir el diálogo y actualizar dinámicamente un tablero de datos visual simultáneamente, todo impulsado por un único sistema de backend.
Ventajas de la implementación estratégica
¿Cuáles son las ventajas de implementación de cambiar a una arquitectura de modelo todo en uno?
Cambiar de configuraciones antiguas de modelos múltiples a una sola red neuronal ofrece beneficios inmediatos y sólidos para los sistemas de TI de la empresa:
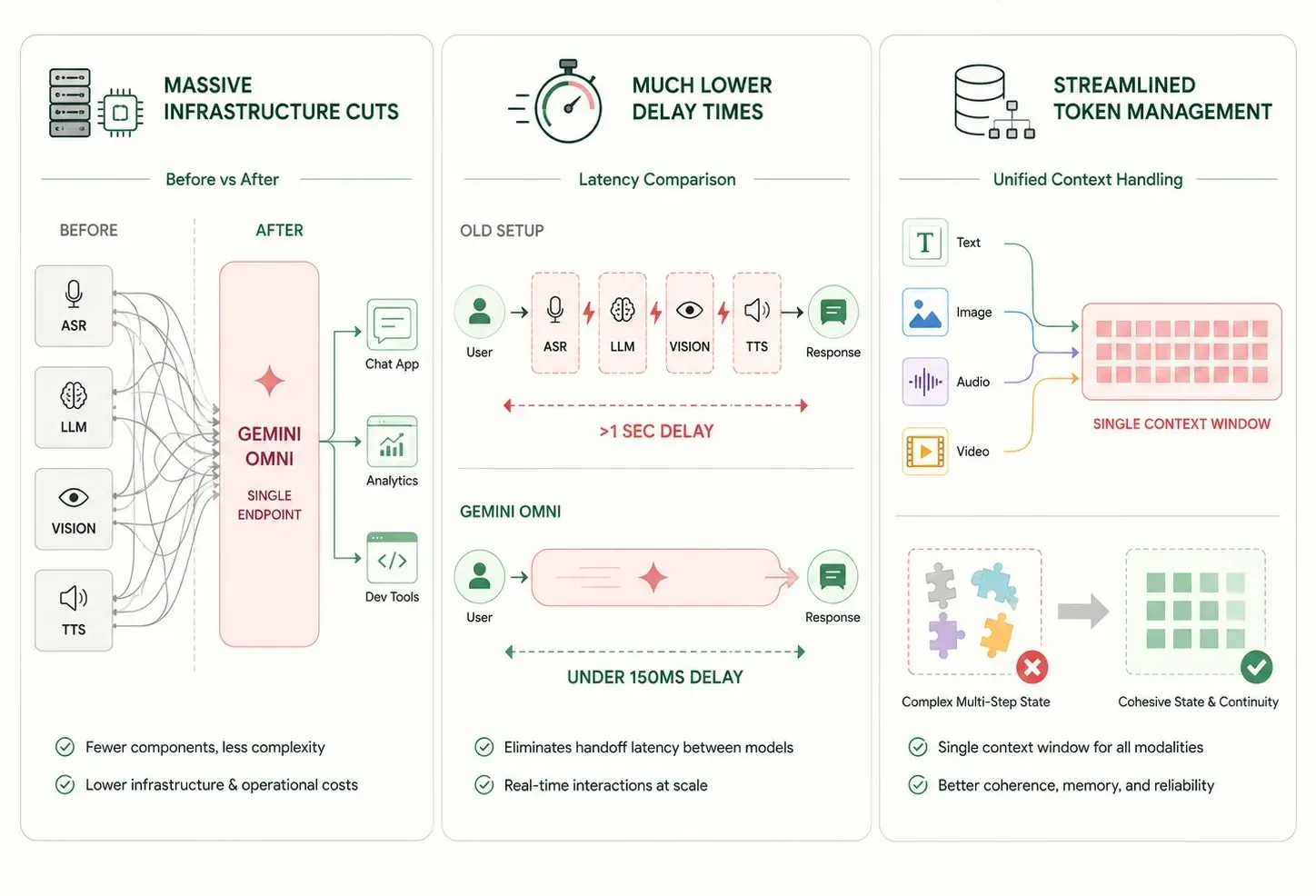
- Recortes masivos de infraestructura: Poner tareas de texto, visión y sonido en un solo modelo reduce la cantidad de puntos finales de software separados. Esto hace que el mantenimiento a largo plazo sea mucho más fácil.
- Tiempos de espera mucho más bajos: Omitir pasos de red adicionales entre herramientas pequeñas y especializadas reduce los tiempos de respuesta a menos de un segundo. Esto permite experiencias de usuario verdaderamente en tiempo real.
- Gestión de tokens simplificada: Una ventana de contexto única que rastrea todas las modalidades de manera uniforme reduce los problemas complejos de gestión de estado en procesos de varios pasos.
Lograr una implementación multimodal escalable
Al operar a través de marcos como Gemini Enterprise Agent Platform, las empresas pueden coordinar sin problemas redes de subagentes autónomos. Este sistema único facilita la ejecución de proyectos multimedia a gran escala. Utiliza configuraciones gestionadas que rastrean el contexto de fondo y la identidad del usuario a través de flujos de trabajo que duran días. Al mantener diferentes entradas en un espacio seguro, las empresas pueden automatizar tareas en diferentes medios de principio a fin sin perder datos o perder de vista el tema principal.
Restricciones computacionales y optimización de hardware para la inferencia de IA global
Si bien el procesamiento de cuatro flujos de datos separados bajo una arquitectura de red unificada desbloquea flujos de trabajo multimedia sin problemas, también introduce demandas sin precedentes en la infraestructura de hardware moderna. Navegar por este entorno requiere una gestión meticulosa de los recursos informáticos para superar las penalizaciones físicas extremas asociadas con el procesamiento multisensorial simultáneo a escala global.
La sobrecarga de la tokenización multimodal
El principal desafío de ingeniería surge de la sobrecarga de tokens multimodales. A diferencia de los conjuntos de datos de texto alfanuméricos estándar, las imágenes de alta definición, las frecuencias de audio crudas y los archivos de video secuenciales generan cantidades masivas de datos numéricos.
- Procesamiento de texto: Una sola página de escritura se convierte en aproximadamente 1,000 tokens densos y significativos.
- Procesamiento visual: Un minuto de metraje de video crudo, cuando se corta en pasos de fotograma constantes y bloques de píxeles, se descompone en cientos de miles de tokens visuales.
Cuando un solo núcleo de modelo procesa estos tipos de medios juntos, provoca un aumento exponencial en la densidad de la ventana de contexto. El mecanismo de atención del sistema debe evaluar cómo cada token se relaciona con todos los demás, amenazando con abrumar la memoria de gran ancho de banda (HBM) en el chip y saturar las capas de procesamiento.
Aceleración de cargas de trabajo mediante escalado de clústeres TPU
Para contrarrestar este cuello de botella, las infraestructuras empresariales dependen de plataformas de hardware especializadas diseñadas específicamente para la computación multisensorial. La última arquitectura de Google utiliza escalado de clústeres TPU para distribuir estas intensas cargas de trabajo de tokens unificados en entornos de centros de datos multicapa.
plaintext1 ┌─────────────────────────┐ 2 │ Tokens de Gemini unificados │ 3 └────────────┬────────────┘ 4 │ 5 ┌───────────────────────┴───────────────────────┐ 6 ▼ ▼ 7┌─────────────────────────────────┐ ┌─────────────────────────────────┐ 8│ Matriz TensorCore │ │ Matriz TensorCore │ 9│ (Aritmética de matriz paralela)│ │ (Aritmética de matriz paralela)│ 10└────────────────┬────────────────┘ └────────────────┬────────────────┘ 11 │ │ 12 └───────────────┬───────────────────────┘ 13 ▼ 14 ┌─────────────────────────┐ 15 │ Interconexión óptica │ 16 │ (ICI de latencia ultra │ 17 │ baja) │ 18 └─────────────────────────┘
Las configuraciones de hardware como la plataforma Trillium TPU v6e ofrecen un impresionante aumento de 4.7x en el rendimiento informático máximo por chip en comparación con las generaciones de hardware anteriores. Esta arquitectura especializada maneja estas demandas masivas combinando unidades de ejecución matricial optimizadas con diseños de infraestructura física profunda:
| Capa de motor de hardware | Especificaciones arquitectónicas | Función del sistema central |
| Matrices TensorCore ampliadas | Doble el área de la unidad de multiplicación de matriz (MXU) | Ejecuta aritmética paralela intensiva en tensores de video densos. |
| HBM de gran ancho de banda | Hasta 32 GB de HBM por chip | Aloja matrices de tokens masivas completamente en silicio para evitar cuellos de botella de memoria. |
| Interconexión inter-chip de próxima generación | Ancho de banda bidireccional de 800 GBps | Sincroniza variables de parámetros en decenas de miles de chips sin retraso. |
Al utilizar una estructura de red óptica personalizada junto con estas configuraciones de memoria profunda, las infraestructuras en la nube pueden escalar dinámicamente para manejar parámetros de entrada de millones de tokens. Esto permite a las empresas desplegar agentes de IA avanzados en tiempo real a nivel mundial sin arriesgarse a bloqueos de memoria o fallas en el tiempo de ejecución del sistema.
Una API unificada para la generación de video de producción
Mientras Google lanza Gemini Omni Flash dentro de la aplicación Gemini y Google Flow para usuarios finales, los desarrolladores y equipos de producto que desean integrar el mismo motor de video multimodal en sus propios flujos de trabajo necesitan una capa de API estable y predecible.
Atlas Cloud sirve Gemini Omni Flash a través de una API unificada y compatible con OpenAI, junto con más de 300 otros modelos de imagen, video y LLM, para que pueda integrar el modelo multimodal nativo de Google sin tener que hacer malabarismos con cuentas de proveedores, portales de facturación o SDK separados.
Ambas variantes de Gemini Omni Flash están activas en Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Mejor para | Entradas | Resolución | Duración | Precio inicial |
| Gemini Omni Flash Texto-a-Video (Desarrollador) | Generación cinemática pura impulsada por prompts | Texto (hasta 20,000 caracteres) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
| Gemini Omni Flash Imagen-a-Video (Desarrollador) | Video consistente en el sujeto a partir de referencias reales | Texto + hasta 7 imágenes de referencia | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
Inicio rápido: genere un video de Gemini Omni Flash en 5 líneas:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
La API devuelve un ID de predicción inmediatamente; consulte /api/v1/model/prediction/{id} para obtener la URL del MP4 renderizado. El esquema completo, ejemplos de código en 7 idiomas y un área de pruebas sin código están disponibles en las páginas de modelos vinculadas anteriormente.
Conclusión: Preparación para el futuro de la inteligencia de máquinas unificada
La llegada de Gemini Omni altera fundamentalmente los paradigmas de diseño de los desarrolladores, moviendo a la industria desde conectar herramientas separadas hasta implementar soluciones unificadas de una sola capa. En lugar de gestionar complejos puentes de integración entre APIs aisladas, los ingenieros ahora pueden confiar en marcos de aprendizaje automático de próxima generación que procesan naturalmente flujos de datos interdependientes bajo un mismo techo matemático.
plaintext1[Tubería de software heredada] 2API de texto separada ──┐ 3API de audio separada ─┼──► Ladrillos de tubería manuales ──► Producción frágil 4API de video separada ──┘ 5 6[Arquitectura Omni unificada] 7Tokens universales ──► Modelo de capa única nativo ──► Automatización sin interrupciones
Este cambio estructural requiere una revisión completa de cómo construimos productos digitales. Para seguir siendo competitivos, los equipos técnicos deben alejarse de los silos de datos estáticos y preparar los ecosistemas de software estándar para sistemas multisensoriales nativos.
Al operar directamente en una base de nube altamente optimizada como la infraestructura de Google Cloud AI, las empresas pueden escalar estas intensas cargas de trabajo de tokens sin arriesgarse a una desviación de contexto sistémica o penalizaciones de latencia. En última instancia, preparar su flujo de trabajo de desarrollo para el futuro significa diseñar soluciones en torno a un motor singular y cohesivo construido para comprender el mundo físico de manera holística.






