El 19 de mayo de 2026, durante el Google I/O, DeepMind presentó Gemini Omni. Ese mismo día, la guía de prompts de Gemini Omni se publicó en el sitio de documentación de DeepMind, situada entre la ficha técnica del modelo Omni Flash y las notas de la API. La mayoría de la gente vio las demostraciones del evento principal, por lo que la documentación pasó prácticamente desapercibida.
Empecemos con los datos clave. Gemini Omni es el nuevo modelo de generación multimodal de DeepMind. El primer producto, Gemini Omni Flash, genera vídeos de hasta 10 segundos a partir de cualquier combinación de entradas de texto, imagen, audio o vídeo. Todas las salidas incluyen una marca de agua SynthID. Los suscriptores de AI Plus, AI Pro y AI Ultra obtuvieron acceso inmediato; los usuarios de YouTube Shorts y de la aplicación YouTube Create obtendrán acceso gratuito a partir de esta semana de lanzamiento (según reporta Gagadget). El acceso a la API "llegará en unas semanas", según Google.
Volviendo a la guía de prompts, la guía de Google DeepMind explica este cambio directamente en la sección "World understanding" (Comprensión del mundo):
Con Veo, necesitas compartir instrucciones precisas para obtener los mejores resultados. Pero con Gemini Omni, no tienes que ser tan prescriptivo con tu prompt. En su lugar, dile a Omni lo que quieres crear y observa cómo el razonamiento y el conocimiento del mundo del modelo hacen realidad los detalles.
La traducción: escribe menos.
Lee esto junto con las guías de prompts que ByteDance y Kuaishou publican para sus propios modelos de vídeo. Los marcos difieren, pero apuntan en la misma dirección.
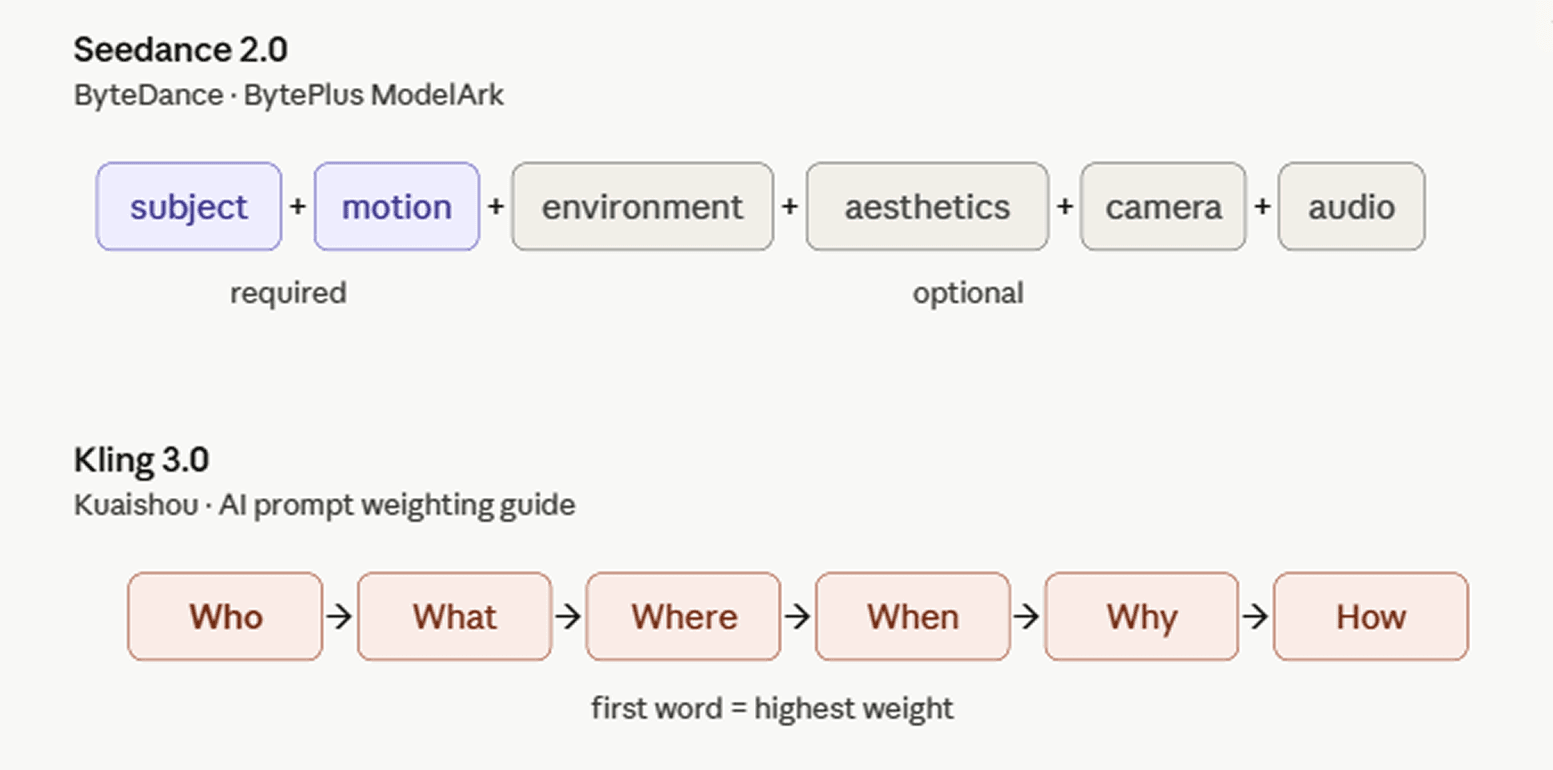
ByteDance documenta Seedance 2.0 en su plataforma internacional para desarrolladores con la guía de prompts de BytePlus ModelArk. La estructura recomendada es: sujeto + movimiento (+ entorno + estética + movimiento de cámara/corte + audio). No todos los componentes son obligatorios; eliges lo que se ajuste a la toma.
La guía de ponderación de prompts de IA de Kuaishou lo enmarca a través de la fórmula 5W1H: Quién (Who) + Qué (What) + Dónde (Where) + Cuándo (When) + Por qué (Why) + Cómo (How). El "Quién" —el sujeto— suele tener la mayor prioridad y encabeza el prompt, ya que la posición de la palabra determina su peso en Kling 3.0: lo que se menciona primero recibe la mayor atención computacional. Las elecciones estilísticas como el medio o la perspectiva funcionan mejor al final, actuando como un filtro sobre la escena ya establecida. La guía advierte contra la acumulación ciega de elementos; demasiadas palabras clave contradictorias degradan la calidad.
Tres empresas llegaron a esta conclusión de forma independiente, lo que sugiere que sus modelos alcanzaron un nivel de capacidad similar casi al mismo tiempo. Google te dice que escribas menos, ByteDance marca la mayoría de los componentes como opcionales y Kuaishou enfatiza el orden de las palabras sobre el volumen total. Los marcos específicos difieren, pero los tres laboratorios orientan a los creadores hacia prompts más libres y naturales.
Ahora, veamos cómo se aplica la guía de prompts de Gemini Omni en la práctica.
Estructura de prompts de Gemini Omni: 5 dimensiones que usa Google DeepMind
La guía comienza con un ejemplo completo:
Una toma de gran angular con seguimiento se desliza suavemente sobre un lago sereno, revelando un objeto colosal, reflectante y con forma de alubia metálica que levita sin esfuerzo por encima, girando lentamente para mostrar sus reflejos distorsionados de acantilados majestuosos y un objeto similar más pequeño parcialmente sumergido en el agua azul cristalina de abajo, mientras un sol brillante surge detrás de la anomalía flotante, bañando toda la escena con una luz diurna nítida y etérea con vibrantes tonos azules y verdes, creando un ambiente cinematográfico e impresionante subrayado por una partitura orquestal majestuosa y de otro mundo que enfatiza la inmensidad y el misterio del paisaje alienígena, con zumbidos profundos y tenues que emanan del objeto levitante.
Más de 90 palabras. Si la desglosas, obtienes 5 dimensiones.
- Encuadre y movimiento de cámara: ¿Gran angular, plano medio o primer plano? ¿Debería la cámara deslizarse suavemente o avanzar de repente? Los dos verbos producen resultados notablemente diferentes, por lo que vale la pena hacer algunas pruebas cuando buscas la sensación de movimiento adecuada.
- Estilo: ¿Realista, cinematográfico, etéreo, majestuoso? Esta dimensión no necesita detalles. Dile al modelo el tono emocional y es suficiente.
- Iluminación: ¿De dónde proviene la luz? ¿El sol, una farola, dentro o fuera de la cámara? ¿Debería sentirse nítida, cálida o etérea?
- Escena: Una línea de la guía merece ser destacada: "no necesitas describir cada pequeño detalle, ya que Omni trabajará con tu intención general". Esto coincide con lo que dicen Seedance y Kling en sus documentos oficiales.
- Acción e interacción: Quién y qué hay en la escena, cómo se mueven y cómo interactúan.
Edición conversacional de Gemini Omni frente a la reescritura de prompts de Veo
Omni y Veo producen una calidad de generación comparable. La verdadera diferencia está en lo que puedes hacer después de que se genera el vídeo.
Anteriormente, cambiar un detalle significaba reescribir todo el prompt, regenerar y esperar que la consistencia entre fotogramas se mantuviera. Omni reemplaza este paso con una conversación.
La guía oficial ofrece algunos ejemplos.
Un vídeo al estilo "stop-motion" de un niño pequeño. Primera edición: "cambia la mariposa por una abeja". Siguiente: "cambia la abeja por un pequeño enjambre de luciérnagas". Un elemento cambia por turno; los demás fotogramas se conservan automáticamente.
La cámara funciona de la misma manera. Un vídeo de un violinista recibe tres comandos en secuencia: "transporta al violinista al entorno de la imagen", "haz que el violín sea invisible", "cambia el ángulo de la cámara para que se sitúe sobre el hombro del violinista". Intercambio de entorno, eliminación de objetos, reposicionamiento de cámara, todo a través del lenguaje natural.
Hay un detalle importante a tener en cuenta. Los revisores externos señalan que, si tu instrucción de edición es demasiado vaga, Omni tiende a editar en exceso, cambiando elementos que querías mantener. La recomendación de Google: cambia una variable por turno y declara explícitamente lo que debe permanecer igual.
El ejemplo de sincronización intermodal es más interesante. Toma un vídeo nocturno de un edificio de apartamentos y añade la instrucción "las luces de los apartamentos empiezan a encenderse al ritmo de la música". El modelo analiza los ritmos de la banda sonora y alinea las luces de las ventanas con ellos. Hacer esto en After Effects requeriría una línea de tiempo, un metrónomo y fotogramas clave manuales.
Las 4 capacidades avanzadas de Gemini Omni: conocimiento del mundo, renderizado de texto, referencia de acción y entradas múltiples
La segunda mitad de la guía desglosa 4 capacidades.
Conocimiento del mundo aplicado
El ejemplo de prompt: Explica la diferencia entre la computación regular y la computación cuántica. Visualiza esta oración usando un estilo contemporáneo de medios planos que combine formas vectoriales minimalistas con ricas texturas orgánicas. La estética se define por una paleta de colores "eléctrica" de alto contraste, con rosas, cianos y limas de neón sobre un fondo azul marino profundo. Un sello distintivo de este estilo es el uso de sombreado de punteado y degradados granulosos, lo que añade una calidad táctil, similar a la risografía, a formas geométricas por lo demás simples. Al combinar bordes afilados con estas transiciones suavizadas y moteadas, la ilustración logra una sensación editorial y lúdica.
El modelo ya sabe qué es la superposición cuántica y cómo transmitirla a través de una serie comparativa de tomas. El usuario no tiene que explicar la mecánica cuántica, solo el tono visual.
Esto funciona porque Omni se ejecuta en un modelo de razonamiento de frontera, algo que los modelos de vídeo solo de generación no pueden igualar. Demis Hassabis, en una entrevista con Semafor después del I/O, enmarcó a Omni como un paso más en el proyecto de construir una IA que comprenda mejor el mundo real. Señaló que Waymo, la división de conducción autónoma de Alphabet, ya está probando modelos de mundo similares para dar a los coches autónomos una especie de "imaginación" para manejar situaciones impredecibles. La generación de vídeo es solo la aplicación más visible de esa arquitectura.
Renderizado de texto
El ejemplo de prompt: palabra por palabra, una palabra en la pantalla a la vez, cada palabra con un estilo animado diferente, ritmo perfecto al compás, carrete de presentación.
Referencia de acción compleja
Ejemplo de prompt: edita esto manteniendo todo igual, añade efectos de movimiento animados que salgan del monopatín.
Referencia de múltiples entradas
Ejemplo de prompt: Los pájaros del vídeo forman vagamente la forma imperfecta de un pájaro basado en la imagen. Se mueven al ritmo de la música del audio y se disipan mientras vuelan.
Transferencia de estilo
Ejemplo de prompt: Crea una progresión estilística de cuatro partes del vídeo de referencia que comience con una estética vibrante de crayón de colores, con trazos ricos, cerosos y texturizados, y diseños de personajes lúdicos dibujados a mano sobre un fondo de papel muy granulado. Transiciona suavemente a un boceto a lápiz de grafito sobre papel texturizado, utilizando sombreado cruzado, grosores de línea variables y un efecto de "línea hirviente" de 12 fps para enfatizar una sensación dibujada a mano. Luego, transfórmate en un estilo de vidrio translúcido 3D hiperrealista, caracterizado por complejas refracciones de luz, patrones cáusticos y suaves brillos internos dentro de un estudio minimalista. Concluye la secuencia con un aspecto de impresión risográfica táctil, aplicando una paleta limitada de tres colores, texturas de semitonos granulosas y superposiciones de registro intencionales para un acabado mecánico y retro.
Referencia de guion gráfico
Prompt: Muéstrame esto en la historia. Sigue la historia exactamente en orden comenzando desde arriba a la izquierda. Historia completa en 10 segundos. Cinemático.
Consistencia entre tomas
Por qué convergen los consejos de prompts de Gemini Omni, Seedance de ByteDance y Kling de Kuaishou
Volviendo a la observación anterior. La similitud en los consejos de prompts de Seedance, Kling y Omni no es resultado de un préstamo mutuo. Es más probable que esta generación de modelos alcanzara un nivel de capacidad similar por cuenta propia.
Una vez que un modelo puede manejar el lenguaje natural a nivel de escena, complementar los detalles con el conocimiento del mundo e inferir lo que el usuario realmente quiere decir, prescribir en exceso se convierte en el cuello de botella. Los tres laboratorios no se ponen de acuerdo sobre cuánta estructura añadir, pero están de acuerdo en que la respuesta no es seguir escribiendo más.
Este es el resultado de dos años de modelos de difusión entrenados conjuntamente con grandes modelos de lenguaje. Omni lleva el resultado a un estado relativamente completo.
Llamando a Gemini Omni a través de Atlas Cloud: API unificada para Seedance, Kling y Veo
Gemini Omni llegará a Atlas Cloud. Atlas Cloud agrega más de 300 modelos de IA de texto, imagen, vídeo y audio. Los principales modelos de vídeo ya funcionan en la plataforma: Seedance 2.0, Kling 3.0, Wan 2.7, Veo, entre otros. Para una comparación lado a lado, consulta el análisis profundo Wan 2.7 vs Seedance 2.0 vs Kling 3.0: qué API de vídeo deberían elegir los desarrolladores de Atlas Cloud.
Una cuenta ejecuta todo el flujo de trabajo. No es necesario registrarse, pagar o mantener claves de API en múltiples plataformas regionales. El Playground admite la depuración interactiva. Una API unificada compatible con OpenAI se conecta a los flujos de trabajo existentes.
La biblioteca de prompts de Atlas Cloud tiene más de veinte categorías de prompts listos para usar que cubren formatos de anime, ciencia ficción, misterio, comida y vlog. Cada prompt viene con un vídeo de ejemplo y notas de parámetros. Copia, cambia algunas palabras y ejecuta.
Una API unificada para la generación de vídeo en producción
Mientras Google lanza Gemini Omni Flash dentro de la aplicación Gemini y Google Flow para los usuarios finales, los desarrolladores y equipos de producto que desean integrar el mismo motor de vídeo multimodal en sus propios flujos de trabajo necesitan una capa de API estable y predecible.
Atlas Cloud ofrece Gemini Omni Flash a través de una API unificada compatible con OpenAI, junto con más de 300 modelos de imagen, vídeo y LLM, para que puedas integrar el modelo multimodal nativo de Google sin tener que lidiar con cuentas de proveedores, portales de facturación o SDK independientes.
Ambas variantes de Gemini Omni Flash están disponibles en Atlas Cloud:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Mejor para | Entradas | Resolución | Duración | Precio inicial |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Desarrollador) | Generación cinematográfica pura basada en prompts | Texto (hasta 20,000 caracteres) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
| Gemini Omni Flash Image-to-Video (Desarrollador) | Vídeo con sujetos consistentes a partir de referencias reales | Texto + hasta 7 imágenes de referencia | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/seg |
Inicio rápido: genera un vídeo de Gemini Omni Flash en 5 líneas:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
La API devuelve un ID de predicción inmediatamente; consulta /api/v1/model/prediction/{id} para obtener la URL del MP4 renderizado. El esquema completo, ejemplos de código en 7 idiomas y un Playground sin código están disponibles en las páginas del modelo enlazadas anteriormente.






