 Three serious video generation APIs shipped within weeks of each other in early 2026. Wan 2.7 (Alibaba), Seedance 2.0 (ByteDance), and Kling 3.0 (Kuaishou) each claim to be the best. Developers building production video pipelines need a clear answer, not a marketing brochure.
Three serious video generation APIs shipped within weeks of each other in early 2026. Wan 2.7 (Alibaba), Seedance 2.0 (ByteDance), and Kling 3.0 (Kuaishou) each claim to be the best. Developers building production video pipelines need a clear answer, not a marketing brochure.
This guide cuts through the noise. We'll compare architecture, real-world output quality, pricing, and the specific workflow conditions where each model wins — with concrete examples from production teams using Atlas Cloud.
The short answer, before we go deep: No single model dominates all use cases. Seedance 2.0 wins on multimodal control and face fidelity. Kling 3.0 wins on cinematic storytelling and benchmark scores. Wan 2.7 wins on flexibility, open-weight economics, and video editing. The right choice depends on what your application actually needs.
What's Actually New in 2026's Video API Landscape
 Before comparing models, it's worth naming what changed. The naive assumption — that newer models are simply "better" — misses the real story.
Before comparing models, it's worth naming what changed. The naive assumption — that newer models are simply "better" — misses the real story.
The 2026 generation of video APIs crossed three thresholds that previous models hadn't:
Threshold 1: Native audio is now table stakes. Seedance 2.0 and Kling 3.0 both generate audio and video in a single pass, with phoneme-level lip synchronization. Wan 2.7 added native audio conditioning in its latest release. Six months ago, any native audio capability was a differentiator. Now it's a baseline expectation.
Threshold 2: Reference inputs replaced prompting as the primary control surface. All three models now accept image and video references, not just text. This shifts the developer workflow from "write better prompts" to "provide better reference materials." The quality ceiling rose, but so did the complexity of input preparation.
Threshold 3: Character consistency is solvable — but the implementations differ. Maintaining the same face, costume, and posture across multiple generated clips was the hardest unsolved problem in AI video. All three models address it, through different mechanisms, with different reliability profiles.
Understanding these shifts helps clarify what the model comparison actually means.
Model-by-Model Breakdown

Wan 2.7 — Alibaba's Open-Weight Workhorse
Wan 2.7 is Alibaba's latest entry in the Wan video generation series, released in early 2026 within the Qwen ecosystem. It is an open-weight model, which is the single most important fact about it from a developer cost and deployment perspective.
What Wan 2.7 actually does: Wan 2.7 supports seven distinct generation modes: text-to-video, image-to-video, start-and-end-frame control, video continuation, video editing (style transfer), audio-to-video, and reference-to-video. No other single model checkpoint currently matches this range.
The architecture adds a chain-of-thought reasoning layer before image and video generation — described internally as "think before you draw." This is meaningful: most text-to-video models process prompts in a single forward pass, which produces spatial errors and layout inconsistencies on complex scenes. Wan 2.7's reasoning layer catches these before generation begins.
Key specifications:
- Resolution: 720p and 1080p (Ultra HD)
- Duration: up to 15 seconds, configurable
- Audio: native audio conditioning, syncs motion and lip movement to provided audio track during generation (not post-processing)
- Reference inputs: up to 9 images via 3×3 grid synthesis for character and style consistency
- First-and-last-frame control: define both keyframes; model interpolates the transition
- Video editing: style transfer from existing footage via text prompt
- Aspect ratios: 5 options including 9:16, 16:9, 1:1
Where Wan 2.7 wins:
The first-and-last-frame control is a genuine production capability. For e-commerce teams animating product shots — "product at rest" to "product in motion" — this produces controlled transitions without a full animation pass. The endpoint constraints are deterministic; what happens between frames is stochastic, but the compositional guardrails are there.
The video editing mode fills a gap that other models don't address at the API level. Wan 2.7 Video Edit takes existing footage and rewrites its visual style based on a text prompt, preserving motion, timing, and structure. An agency with one source video can generate three platform-specific variants (polished for YouTube pre-roll, animated for TikTok, illustrated for Instagram) as three API calls.
The 9-image reference grid for character consistency consolidates what previously required multiple generation passes or ControlNet workarounds.
Where Wan 2.7 has limits:
Wan 2.7 interprets prompts with more "creative license" than Seedance 2.0. Teams that need precise output — exact character behavior, specific camera movement — will find Seedance 2.0's reference system more deterministic. Wan 2.7 is best directed; Seedance 2.0 is best when you can show it exactly what you want.
**Pricing on Atlas Cloud:** Starting from $0.10/s for image-to-video. Open-weight option also available for teams with GPU infrastructure who want to eliminate per-generation costs at scale.
Seedance 2.0 — ByteDance's Director's Console
Seedance 2.0, developed by ByteDance and available since February 2026, takes a different architectural approach. Its Dual-Branch Diffusion Transformer (DB-DiT) processes video and audio streams simultaneously in separate synchronized branches, enforcing audio-visual alignment during generation rather than afterward.
The model's most distinctive feature is what its team calls the "Universal Reference" system — the ability to replicate composition, camera movement, and character actions from reference assets with a precision that previous models couldn't match. This shifts the developer workflow from prompting to directing: instead of describing what you want, you show the model exactly what you want.
What Seedance 2.0 actually does: Seedance 2.0 accepts quad-modal inputs — text, up to 9 images, up to 3 video clips, and audio — simultaneously. Its physics-based world model simulates realistic object motion and spatial consistency over time. The model achieves phoneme-level lip synchronization across 8+ languages, meaning mouth movements match generated speech at sub-word granularity.
Key specifications:
- Resolution: Up to 1080p (Ultra HD); the model's output resolution for image-to-video follows the input image's aspect ratio
- Duration: 4 to 60 seconds (set duration = -1 for automatic optimal length)
- Audio: native, phoneme-level lip sync across 8+ languages
- Reference inputs: up to 12 files (images, video clips, audio) simultaneously
- Usable output rate: ~90% versus an industry average of ~20%
- Speed: 30% faster than predecessor systems
Where Seedance 2.0 wins:
The 90% usable output rate is not a marketing number to dismiss. For production pipelines where failed generations mean wasted compute costs and human review time, this matters substantially. A pipeline generating 1,000 clips per month at 20% usability needs 5,000 generations to get 1,000 usable outputs. At 90% usability, you need 1,111. That's a 4.5x difference in actual API spend.
Face fidelity is Seedance 2.0's clearest technical advantage over the other two models. Our version of Seedance 2.0 supports realistic human faces without the content restrictions that apply on ByteDance's own Jimeng platform. For marketing, e-commerce, and brand content where actual faces need to appear in generated video, this is often the deciding factor.
The Universal Reference system makes Seedance 2.0 the right choice when the brief is specific. If the client says "make the character move exactly like this reference video," Seedance 2.0 is the most reliable path to that output.
Where Seedance 2.0 has limits:
Aspect ratio for image-to-video follows the input image — you can't specify it independently. Teams working with fixed output dimensions need to account for this in their input preparation workflow.
Atlas Cloud Seedance 2.0: We offer the **Full-Power version** at **1.8× the official rate** — first to market with real human face support and uncensored generation. Unlimited RPM, zero wait times, enterprise-grade infrastructure.
Kling 3.0 — Kuaishou's Cinematic Director
Kling 3.0 launched February 5, 2026 — three days before Seedance 2.0 dropped — and holds the highest ELO benchmark score (1243) among all AI video models as of April 2026, ahead of Google Veo 3.1, Runway Gen-4.5, and others.
The model suite includes two variants: Kling 3.0 (upgraded from Kling 2.6) for intelligent cinematic storytelling, and Kling 3.0 Omni (Kling O3, upgraded from Kling O1) for professional-grade subject consistency with custom subjects and voice clones.
What Kling 3.0 actually does: Kling 3.0 uses a Multi-modal Visual Language (MVL) architecture that processes text, image, audio, and video in a unified system. The model includes an "AI Director" that automatically plans camera angles, shot types, and character staging across sequences. It supports native 4K output and multilingual audio across Chinese, English, Japanese, Korean, and Spanish with multi-character dialogue.
Key specifications:
- Resolution: Up to 4K native (Ultra HD)
- Duration: 3 to 15 seconds
- Audio: native, multilingual lip-sync with multi-character dialogue support
- Scene planning: AI Director automates shot sequencing
- Motion transfer: extract motion pattern from reference video, apply to different subject
- Subject consistency: up to 4 reference images for character locking across generations
- Text rendering: best-in-class legibility for signs, brand logos, and price tags within video
Where Kling 3.0 wins:
Kling 3.0's motion transfer capability — uploading a reference video to extract its motion pattern and apply it to a completely different subject — drove a viral moment in early 2026 and remains its most distinctive differentiator. No other model in this comparison offers this automatically.
Text rendering is a practical advantage that's easy to underweight. Signs, brand logos, and price tags remain legible within Kling 3.0 videos. Anyone who has tried to maintain readable text in AI-generated video with competing models understands how significant this is. For e-commerce teams generating product videos where price or SKU information needs to appear on screen, Kling 3.0's text fidelity is a functional requirement, not a nice-to-have.
The 4K native output ceiling is the highest of the three models. For content that will appear on large displays or require significant post-production upscaling, Kling 3.0 has more resolution headroom.
Where Kling 3.0 has limits:
Kling 3.0's subscription pricing model for consumer access can be opaque. The native platform charges credits for failed generations, has queue times that exceed 30 minutes during peak hours, and restricts API access to enterprise tiers. Teams that need programmatic access without subscription friction should access it via our platform instead.
Kling 3.0 also interprets prompts with more "creative license" than Seedance 2.0, making it less reliable when the brief requires precise, predetermined motion.
**Pricing on our platform:** Kling 3.0 API access is available with competitive per-second pricing. Check our real-time pricing page for current rates, as these are subject to change.
Side-by-Side Comparison
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Dimension | Wan 2.7 | Seedance 2.0 | Kling 3.0 |
|---|---|---|---|
| Max Resolution | 1080p (Ultra HD) | 1080p (Ultra HD) | 4K (Ultra HD) |
| Max Duration | 15s | 60s | 15s |
| Native Audio | Yes | Yes (phoneme-level) | Yes (multi-language) |
| Input Modalities | Text, image, audio, video | Text, image, audio, video | Text, image, audio, video |
| Reference Images | Up to 9 (3×3 grid) | Up to 9 images + 3 videos | Up to 4 images |
| Video Editing Mode | Yes | No | Yes (Omni) |
| Face Fidelity | Good | Best-in-class | Good |
| Text-in-Video | Moderate | Moderate | Best-in-class |
| Open Weights | Yes | No | No |
| Atlas Cloud Pricing | From $0.10/s | $0.081–$0.10/s | See pricing page |
| Best For | Editing, open-weight economy | Face content, precise control | Cinematic storytelling, 4K |
Prices accurate as of April 2026. Check atlascloud.ai/pricing for current rates.
Decision Framework: Which Model for Which Use Case
Use Seedance 2.0 when:
**You're building face-forward content.** Marketing campaigns, product spokesperson videos, talking head sequences, and e-commerce content where real faces need to appear consistently across clips. Seedance 2.0's face fidelity and our uncensored access to full human face generation make this the clearest choice.
Your creative brief is specific. When you have a reference video showing exactly how the character should move, or a reference image showing exactly what the scene should look like, Seedance 2.0's Universal Reference system delivers the most faithful replication.
Your pipeline runs at volume. The 90% usable output rate and $0.081/s Fast tier pricing combine to significantly lower actual cost-per-usable-clip versus competitors. For pipelines generating thousands of clips monthly, this compounds.
You need long clips. Seedance 2.0's 60-second maximum duration is the longest available. Kling 3.0 and Wan 2.7 both top out at 15 seconds.
Use Kling 3.0 when:
You're building narrative content. Trailers, short films, serialized social content, and brand storytelling sequences where the AI Director's automatic scene planning saves significant manual work.
Text legibility in video is a requirement. E-commerce product listings, pricing cards, brand logos within generated scenes — Kling 3.0's text rendering is best-in-class.
You need motion transfer. Extracting motion from reference footage and applying it to a different subject is Kling 3.0's most distinctive capability. No comparable feature exists in the other two models.
Maximum resolution matters. 4K output for large-display content or post-production workflows requiring upscaling headroom.
Use Wan 2.7 when:
You need to restyle existing footage. The video editing mode — style transfer from source video via text prompt — addresses a workflow that Seedance 2.0 and Kling 3.0 don't cover as cleanly.
Your volume is high enough to justify self-hosting. As an open-weight model, Wan 2.7 can be deployed on your own GPU infrastructure. For teams generating thousands of videos monthly, eliminating per-second API costs makes the economics dramatically different.
You need multiple generation modes in one model. Seven distinct modes (text-to-video, image-to-video, start-end frame, video continuation, video editing, audio-to-video, reference-to-video) from a single model reduces integration complexity.
You're doing content variation at scale. The video editing mode is purpose-built for agencies that need multiple visual variants of the same source footage without re-shooting.
Why Atlas Cloud for All Three
Each of these models is available on its developer's own platform. Why use Atlas Cloud instead?
**Unified billing.** Managing three separate API keys, three billing accounts, and three documentation sets for Alibaba Cloud, ByteDance's BytePlus, and Kuaishou's Kling platform is operational overhead that scales badly. We provide a single API key, a single endpoint (`https://api.atlascloud.ai/v1`), and a single invoice.
Better pricing through smart routing. BytePlus bills Seedance 2.0 at a 1-minute minimum, meaning a 5-second clip is billed as 60 seconds. Atlas Cloud uses true per-second billing. For short-form content pipelines, this difference alone covers the cost of switching.
**No waitlist, no queue times.** Kling's native platform has extended queue times (sometimes exceeding 30 minutes) during peak hours. Our infrastructure eliminates queue time for all three models.
**Real human face support for Seedance 2.0.** ByteDance's own Jimeng platform restricts realistic human face generation. Our version of Seedance 2.0 lifts this restriction, making it usable for marketing and commercial content.
**OpenAI-compatible API format.** If your codebase already calls GPT or any OpenAI-compatible endpoint, switching to any model on our platform requires changing `base_url` and `api_key`. No client library changes, no schema rewrites.
Enterprise reliability. SOC 2 Type II certified, HIPAA compliant, 99.99% uptime SLA, RBAC access controls, and US data sovereignty for teams with compliance requirements.
Real Production Case Studies
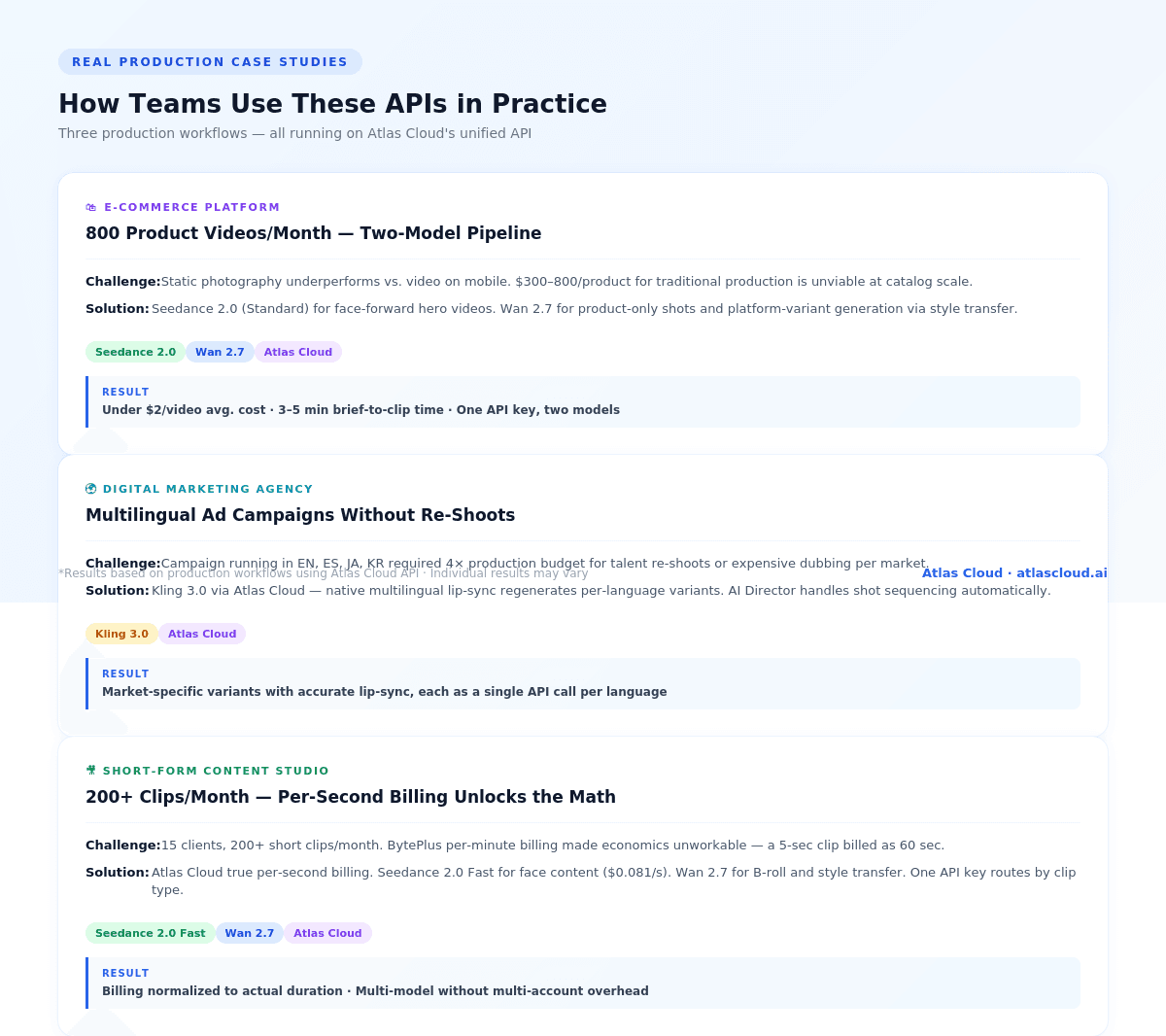
Case Study 1: E-Commerce Platform — Product Video at Scale
Team: A fashion e-commerce platform generating product lifestyle videos for 800+ SKUs per month.
Problem: Static product photography was underperforming versus video on mobile platforms. Traditional video production at $300–800 per product was economically impossible at scale.
**Solution:** The team built a two-model pipeline with us. Seedance 2.0 (Standard tier) handles hero product videos — the model's face fidelity ensures consistent model appearance across the catalog, and the Universal Reference system lets them maintain the same studio aesthetic by feeding a reference clip of the desired lighting and camera style. Wan 2.7 handles the volume work — product-only shots without faces, where the lower cost per second and video editing mode allow rapid style variants for different platforms (warm lifestyle for Instagram, clean white for product pages, animated for TikTok).
**Result:** 800 videos per month at approximately $0.081–$0.10/s for hero content and lower for variants. Average cost per video: well under $2. Time from brief to final clip: 3–5 minutes. They accessed both models through one API key with no additional integration work.
Case Study 2: Digital Marketing Agency — Multilingual Ad Campaigns
Team: A mid-sized agency running global campaigns for consumer brands across North America, Europe, and Southeast Asia.
Problem: Localized video ads require talent re-shoots or expensive dubbing for each market. A campaign running in English, Spanish, Japanese, and Korean was requiring 4x the production budget just for audio localization.
**Solution:** The agency switched to Kling 3.0 via our platform for its native multilingual lip-sync. A single generated video with the desired character and scene could be re-generated with a different language audio prompt. The AI Director feature handles scene-level shot sequencing, eliminating the need to manually specify every camera angle. Phoneme-level lip-sync across all four target languages meant the outputs required no post-production dubbing review.
Result: Localization cost reduced significantly. The agency can now deliver market-specific video variants from the same creative brief, each with accurate lip-sync, through single API calls per variant.
Case Study 3: Short-Form Content Studio — High-Volume Social Content
Team: A content studio managing social channels for 15 clients, producing 200+ short clips per month.
Problem: At that volume, per-minute billing from BytePlus was unsustainable — a 5-second clip billed as 60 seconds makes the math unworkable. The team also needed multiple model options depending on clip type.
**Solution:** Our per-second billing and unified API solved both problems. Seedance 2.0 Fast tier handles face-forward clips at $0.081/s. Wan 2.7 handles B-roll and style-transfer content. The single API key means their generation pipeline routes to the appropriate model based on clip type without separate auth handling.
Result: Billing normalized to actual video duration, not minimum intervals. Multi-model access without multi-account management.
The Developer Integration Path
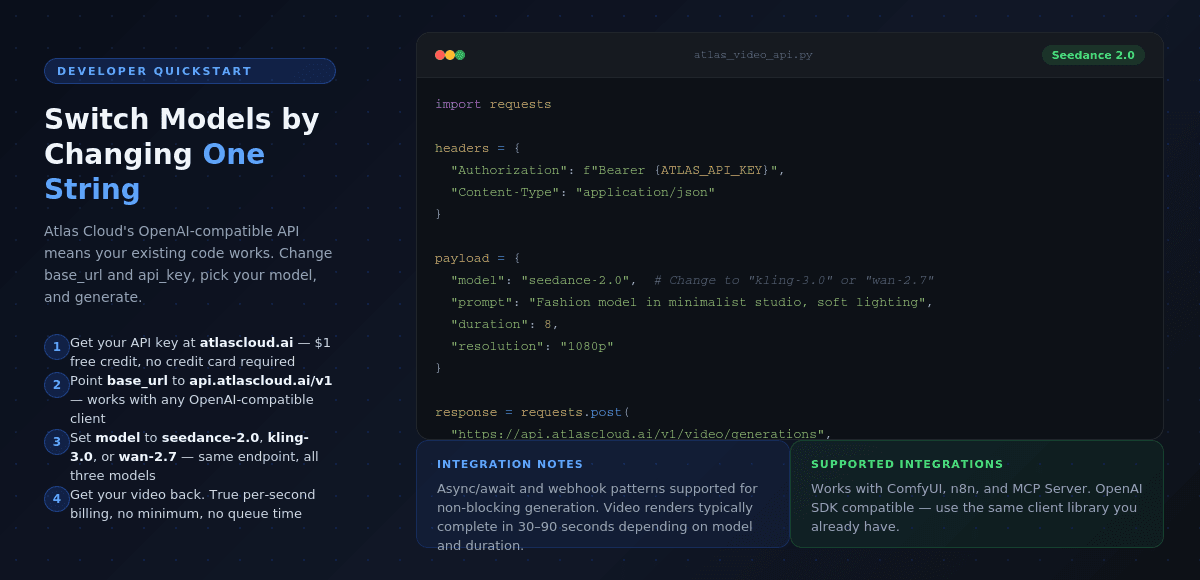
All three models are accessible through our unified API, which is OpenAI-compatible. Here's a minimal Python example for Seedance 2.0 text-to-video:
plaintext1import os 2import requests 3 4headers = { 5 "Authorization": f"Bearer {os.environ['ATLAS_API_KEY']}", 6 "Content-Type": "application/json" 7} 8 9payload = { 10 "model": "seedance-2.0", 11 "prompt": "A fashion model walks through a minimalist studio, soft directional lighting, 9:16 vertical", 12 "duration": 8, 13 "resolution": "1080p" 14} 15 16response = requests.post( 17 "https://api.atlascloud.ai/v1/video/generations", 18 headers=headers, 19 json=payload 20) 21 22video_url = response.json()["data"]["url"]
To switch to Kling 3.0, change model to "kling-3.0". To switch to Wan 2.7, change it to "wan-2.7". The rest of your integration stays the same. This is the practical value of a unified API: you can A/B test models, route different clip types to different models, or migrate entirely without refactoring your pipeline.
Frequently Asked Questions
Q: Which model has the best quality overall?
Kling 3.0 holds the highest ELO benchmark score as of April 2026. But benchmark score and "best for my use case" are different questions. Seedance 2.0 outperforms Kling 3.0 on face fidelity and precise motion control. Wan 2.7 outperforms both on video editing and open-weight economics.
Q: Is Seedance 2.0 available without the content restrictions from ByteDance's platform?
Yes. Our version of Seedance 2.0 supports realistic human face generation without the restrictions that apply on Jimeng (ByteDance's own platform). This is one of the key reasons developers choose us over the native endpoint.
Q: Can I access all three models with a single API key?
Yes. We provide a single API key and a single endpoint for all 300+ models on the platform, including Wan 2.7, Seedance 2.0, and Kling 3.0.
Q: How does Atlas Cloud pricing compare to the native platforms?
For Seedance 2.0, our per-second billing is 6–12x cheaper than BytePlus's per-minute billing for short-form content. For Kling 3.0, we eliminate queue times and subscription friction. Current pricing is available at atlascloud.ai/pricing.
Q: Do failed generations cost money on Atlas Cloud?
We do not charge for failed generations, unlike Kling's native platform.
Q: What if I need Wan 2.7 for self-hosted deployment?
As an open-weight model, Wan 2.7 can be deployed on your own GPU infrastructure. We also offer GPU cloud access if you need managed self-hosting without the Alibaba Cloud dependency.
Summary Decision Table
| If you need... | Use |
|---|---|
| Best face fidelity | Seedance 2.0 |
| Precise motion from reference | Seedance 2.0 |
| Longest clip duration (up to 60s) | Seedance 2.0 |
| Highest volume, lowest cost per usable clip | Seedance 2.0 Fast |
| Cinematic storytelling and scene planning | Kling 3.0 |
| Motion transfer from reference footage | Kling 3.0 |
| Text legibility within video | Kling 3.0 |
| 4K native output | Kling 3.0 |
| Video editing / style transfer | Wan 2.7 |
| Open-weight self-hosting option | Wan 2.7 |
| Multiple generation modes, one model | Wan 2.7 |
| All three models, one API key | Atlas Cloud |
Access Wan 2.7, Seedance 2.0, and Kling 3.0 through a single unified API at atlascloud.ai. First deposit: 20% bonus (up to $100). Plus earn rewards when you refer friends. No waitlist, instant access.
Pricing information in this article reflects rates as of April 2026 and is subject to change. Always verify current pricing at atlascloud.ai/pricing before building production pipelines.






