
Las APIs de generación de imágenes definitivamente no son todas iguales. Vale la pena evaluarlas antes de empezar a desarrollar. Aquí tienes un vistazo rápido a las seis APIs populares disponibles actualmente. Esta sencilla comparación te ayudará a elegir la correcta para tu infraestructura técnica y te ahorrará tiempo.
| Modelo | Velocidad est. | Costo / imagen | Mejor caso de uso |
| GPT Image 2 | ~8–10s | USD0.01 | Renderizado de texto y diseños complejos |
| Grok-3 Image | ~6–9s | ~USD0.02-0.07 | Creatividad sin filtros y tendencias sociales |
| Flux | ~5–8s | ~USD0.003-0.03 | Fotorrealismo cinematográfico |
| Seedream v5.0 (Lite) | ~3–5s | ~USD0.032 | Contenido de gran volumen a escala |
| Nano Banana Pro | ~1–3s | ~USD0.14-0.15 | Vistas previas ultrarrápidas y tareas por lotes |
| Ideogram v3 | ~8–12s | ~USD0.03-0.06 | Tipografía líder en la industria |
Nota: Las cifras de velocidad se basan en pruebas de producción empíricas; los precios se basan en Atlas Cloud (a excepción de Grok e Ideogram v3).
Conclusión clave: Cada tarea tiene un modelo ideal, por lo que no existe uno solo. Antes de escribir una línea de código de integración, ajusta la API a tus necesidades de salida.
Fase 1: Elegir tu motor — Coincidencia de intenciones
Elegir una API de generación de imágenes sin considerar tu tipo de salida específico es como comprar un auto deportivo para remolcar un bote. Enfócate en la tarea, no solo en el motor. Tu elección debe depender de tres puntos principales: qué tan bien maneja el texto en las imágenes, el equilibrio entre borradores rápidos y alta calidad, y la forma específica en que la empresa te cobra.
El problema del "texto en la imagen"
La mayoría de las APIs de imágenes aún fallan cuando el prompt contiene texto legible; piensa en maquetas de UI, copys de logotipos o titulares de carteles. Las letras se difuminan, las palabras se mezclan y el resultado es inutilizable en cualquier contexto comercial.
Ideogram v3 renderiza texto con una precisión superior al 95% en prompts estándar, mientras que Midjourney aún falla en cadenas de varias palabras aproximadamente el 40% de las veces. Ideogram v3 maneja de manera confiable cadenas largas, nombres de marca y diseños complejos, lo que lo convierte en la elección clara para cualquier flujo de trabajo que implique señalización, empaque de productos o copys incrustados.
Si la tipografía no es una prioridad, esta restricción no te afectará. Pero si lo es, elegir la API incorrecta te costará más en correcciones de posproducción que cualquier ahorro por suscripción.
Fotorrealismo vs. Velocidad: Ajustando el modelo al momento
No todas las generaciones necesitan calidad de estudio. La siguiente tabla asigna los casos de uso al nivel de modelo adecuado:
| Caso de uso | Nivel recomendado | Modelos de ejemplo |
| Imágenes de marketing hero | Alta fidelidad | Flux 2 Pro, Imagen 4 Ultra |
| Generación en tiempo real para el usuario | Turbo / Lightning | Nano Banana 2, Z-Image Turbo (~1s) |
| Redes sociales y contenido a escala | Rango medio | Seedream v5.0 Lite, Flux 2 Dev |
| Diseños con mucho texto | Especialista | Ideogram v3, GPT Image 2 |
Flux 2 lidera en fotorrealismo y cumplimiento de prompts, mientras que Imagen 4 domina en precisión de renderizado de texto y velocidad de generación. Los modelos enfocados en la velocidad sacrifican algo de fidelidad, pero son la única opción viable cuando la latencia es parte de la experiencia del producto.
Verificación de la realidad de los precios: Ya no es por imagen
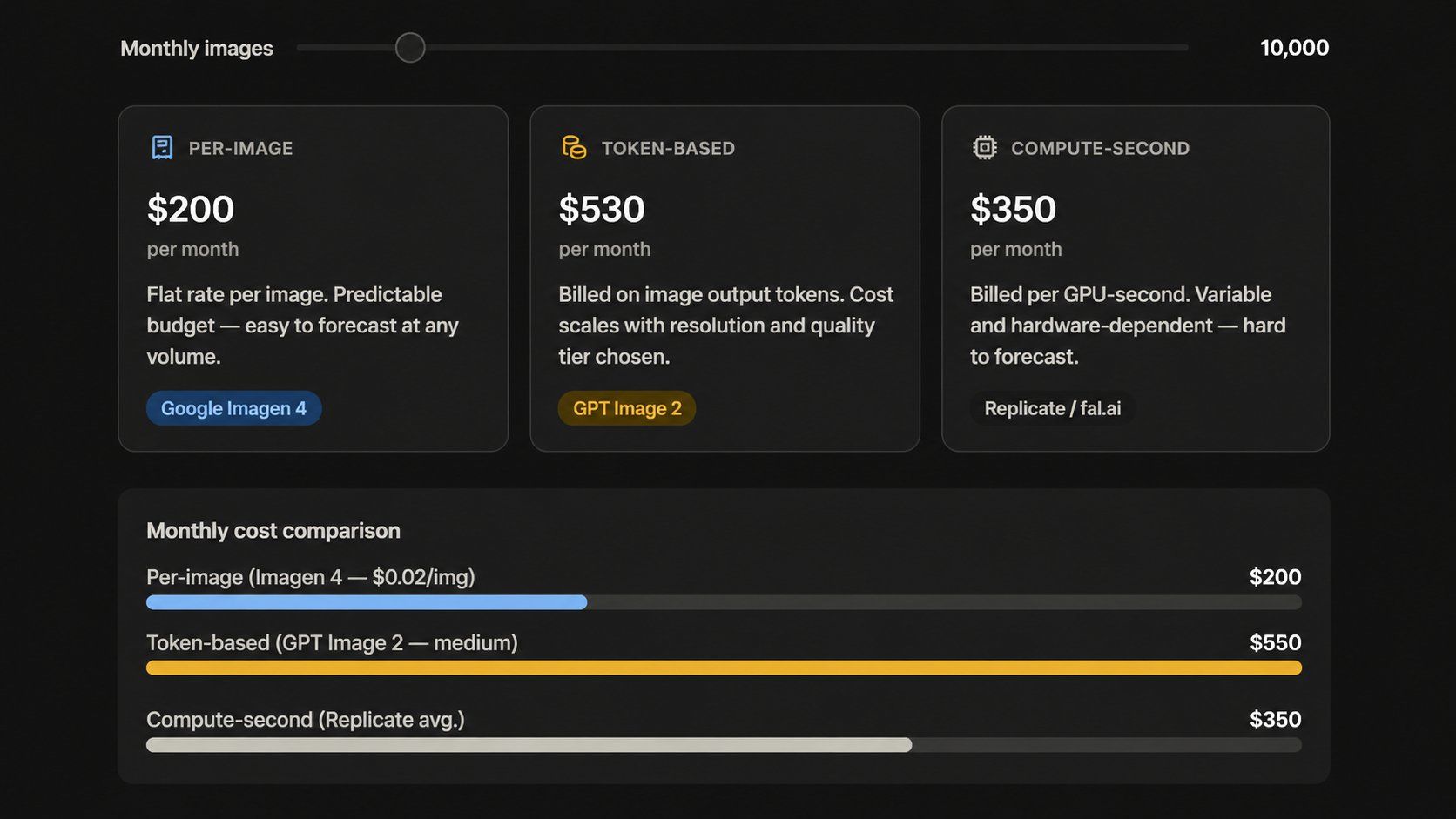
El modelo de "tarifa plana por imagen" está desapareciendo. Las principales APIs actuales cobran de formas muy distintas:
- Basado en tokens (OpenAI):GPT Image 2 factura a USD8.00 por cada millón de tokens de entrada y USD30.00 por un millón de tokens de salida a través de la API. Las estimaciones web suelen variar porque no son los precios oficiales de lista.
- Por imagen (Google Imagen): Google Imagen 4 cuesta entre USD0.02 y USD0.06 por cada imagen. Este modelo facilita mucho la planificación de un presupuesto para proyectos de gran volumen.
- Por segundo (Replicate): Replicate factura por el tiempo de GPU real utilizado por tarea. Esto funciona bien para cargas de trabajo variables, aunque dificulta predecir tus costos mensuales totales.
Un equipo podría pensar que está pagando USD0.05 por imagen, pero descubrir que el costo real es USD0.11. Esto sucede debido a cargos adicionales por resolución, niveles de calidad y ediciones. Prueba siempre tu carga de trabajo mensual en la herramienta de precios de cada empresa antes de firmar cualquier contrato.
Fase 2: Integración técnica — El factor "Hoy"
Puedes obtener tu primera imagen desde una API en menos de 15 minutos. La configuración básica es bastante sencilla. La mayoría de los desarrolladores solo tienen problemas con los permisos de inicio de sesión o la gestión de los datos finales. Aquí tienes qué hacer, en orden.
Configuración del entorno
Instala el SDK oficial para tu lenguaje de elección. Ambas opciones a continuación te ofrecen todo lo necesario para una solicitud de generación de imágenes estándar.
Python
plaintext1pip install openai
Node.js
plaintext1npm install openai
La generación de texto a imagen básica no requiere ninguna otra dependencia. Si deseas trabajar con datos binarios o guardar archivos, las herramientas están integradas. Python utiliza el módulo base64 y Node utiliza la clase Buffer. Ambos funcionan perfectamente sin necesidad de nuevas instalaciones.
El estándar de autenticación: Más allá de las claves API simples
Pegar una clave API en bruto directamente en el código de la aplicación sigue siendo uno de los errores de seguridad más comunes (y evitables). Para cualquier despliegue en producción en 2026, sigue estas prácticas:
| Por qué es importante | Práctica |
| Mantiene los secretos fuera del control de fuentes | Almacena claves en variables de entorno |
| Centraliza la rotación y la auditoría de acceso | Usa un administrador de secretos (AWS Secrets Manager, HashiCorp Vault) |
| Limita el alcance si una clave es filtrada | Limita las claves a los permisos mínimos requeridos |
| Reduce el tiempo de exposición ante fugas no detectadas | Rota las claves en un cronograma fijo |
| Obligatorio al actuar en nombre de usuarios finales | Usa OAuth2 para flujos delegados por el usuario |
OAuth2 se vuelve relevante específicamente cuando tu aplicación genera imágenes en nombre de usuarios individuales con sus propias cuentas de proveedor. Para llamadas servidor a servidor utilizando tu propia clave API, una variable de entorno bien gestionada con rotación regular cubre la mayoría de los casos de uso en producción de forma segura.
El código base
Lo siguiente es una solicitud limpia y funcional al endpoint gpt-image-2 de OpenAI, lista para copiar y pegar tanto en Python como en Node.js.
Python
plaintext1import os 2import base64 3from openai import OpenAI 4 5client = OpenAI(api_key=os.environ["OPENAI_API_KEY"]) 6 7response = client.images.generate( 8 model="gpt-image-2", 9 prompt="A clean product shot of a ceramic coffee mug on a white marble surface, studio lighting", 10 size="1024x1024", 11 quality="medium", 12 n=1, 13) 14 15# Decodificar y guardar la imagen 16image_bytes = base64.b64decode(response.data[0].b64_json) 17with open("output.png", "wb") as f: 18 f.write(image_bytes) 19 20print("Image saved to output.png")
Node.js
plaintext1import OpenAI from "openai"; 2import fs from "fs"; 3 4const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY }); 5 6const response = await client.images.generate({ 7 model: "gpt-image-2", 8 prompt: "A clean product shot of a ceramic coffee mug on a white marble surface, studio lighting", 9 size: "1024x1024", 10 quality: "medium", 11 n: 1, 12}); 13 14// Decodificar y guardar la imagen 15const imageBuffer = Buffer.from(response.data[0].b64_json, "base64"); 16fs.writeFileSync("output.png", imageBuffer); 17 18console.log("Image saved to output.png");
Ambas partes de código extraen tu clave API de la configuración de tu sistema. Solicitan una imagen estándar de 1024×1024 y guardan el archivo final en tu computadora. Cuando solo estés haciendo pruebas, cambia la configuración de calidad a "low". Esto mantiene tu costo en alrededor de USD0.006 por intento mientras trabajas en refinar tus prompts.
Fase 3: Resolviendo los puntos críticos de los desarrolladores en 2026
Hacer que la API funcione es solo la mitad del trabajo. Lo que separa un prototipo de una función de producción es cómo manejas los prompts débiles, las entradas inseguras y los tiempos de generación lentos. Estas tres áreas representan la mayoría de las correcciones pos-lanzamiento que enfrentan los equipos después de integrar una API de generación de imágenes.
Ingeniería de prompts vs. Mejora de prompts
Los usuarios escriben entradas cortas y vagas. Las APIs premian las detalladas y ricas. La brecha entre ambos afecta directamente la calidad del resultado, y culpar al modelo a menudo solo oculta un prompt débil.
Dos enfoques cierran esa brecha:
Funciones nativas de "Magic Prompt": La API de Ideogram ofrece un interruptor de mejora de prompts integrado que reescribe entradas simples antes de generar. Pasa magic_prompt_option: "ON" en tu solicitud y la API se encarga de la mejora automáticamente. Este es el enfoque de menor esfuerzo y funciona muy bien para aplicaciones orientadas al consumidor donde los usuarios no deberían tener que aprender sintaxis de prompts.
Patrón de puerta de enlace LLM: Dirige la entrada sin procesar del usuario a través de una llamada LLM primero, luego pasa el resultado enriquecido a la API de imágenes. Esto te da un control preciso sobre la lógica de mejora y funciona con cualquier proveedor.
plaintext1from openai import OpenAI 2client = OpenAI() 3 4# Paso 1: Mejorar el prompt 5enhancement = client.chat.completions.create( 6 model="gpt-4.1-mini", 7 messages=[{ 8 "role": "user", 9 "content": f"Rewrite this image prompt with cinematic detail, lighting, and style: '{user_input}'" 10 }] 11) 12enhanced_prompt = enhancement.choices[0].message.content 13 14# Paso 2: Generar la imagen 15image = client.images.generate( 16 model="gpt-image-2", 17 prompt=enhanced_prompt, 18 size="1024x1024", 19 quality="medium" 20)
La capa de seguridad: Moderación de contenido automatizada
Permitir que los usuarios generen imágenes arbitrarias sin un paso de moderación es una responsabilidad. Como mínimo, implementa dos puntos de control:
| Capa | Qué detecta | Herramienta |
| Filtrado de entrada | Prompts de texto dañinos antes de la llamada API | OpenAI Moderation API (gratis), Azure Content Safety |
| Filtrado de salida | Imágenes que violan políticas después de la generación | Google Cloud Vision SafeSearch, AWS Rekognition |
La mayoría de los principales proveedores de API de imágenes también aplican sus propios filtros del lado del servidor, pero estos deben tratarse como una última línea de defensa, no como la única. Crea tu propio paso de filtrado de entrada para que puedas rechazar solicitudes antes de gastar créditos de generación en contenido que será bloqueado de todos modos.
Manejo asíncrono: Usa Webhooks, no sondeo (polling)
La generación de imágenes de alta fidelidad puede tomar de 5 a 20 segundos. Hacer que un usuario mire un spinner durante una solicitud síncrona es una mala experiencia de usuario y una arquitectura frágil; si la conexión se cae a mitad de la espera, el resultado se pierde.
El patrón correcto es un flujo asíncrono impulsado por webhooks:
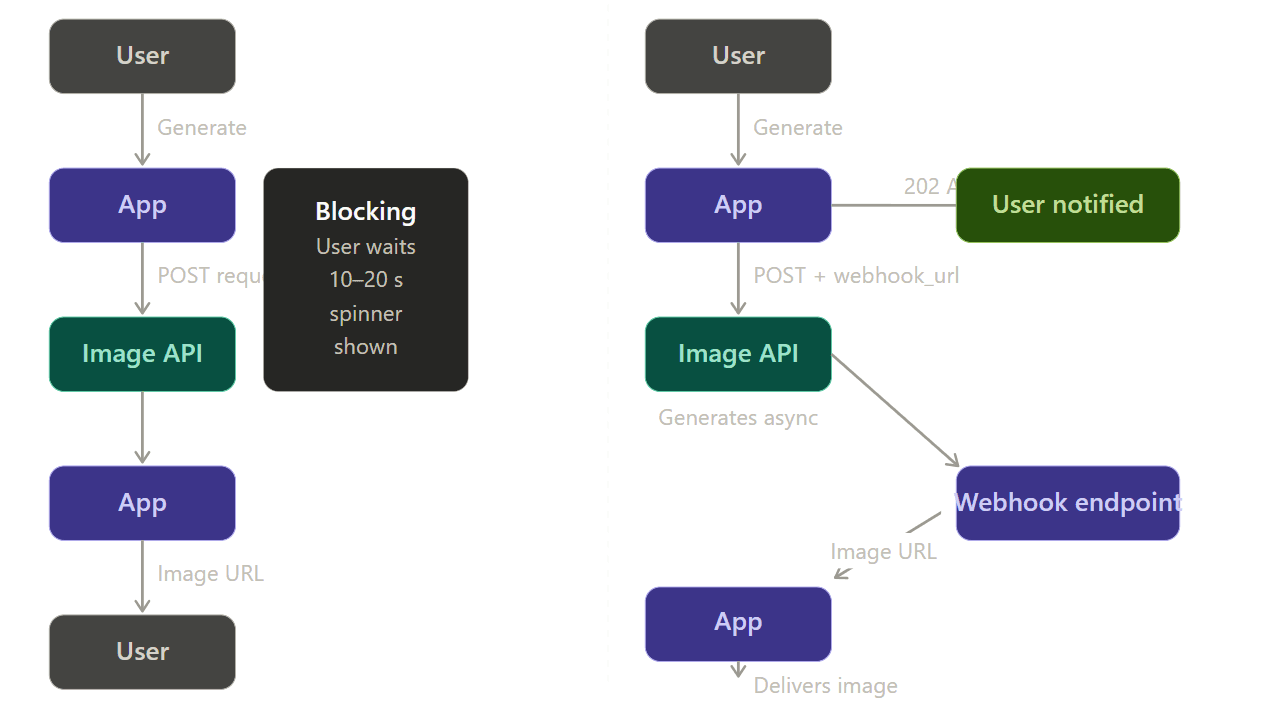
Tu aplicación le da al usuario un ID de trabajo y un estado 202 Accepted cuando usa un patrón de webhook. Cuando el servicio de imágenes termina, envía el archivo final a tu servidor mientras trabaja en segundo plano. Esto detiene las conexiones agotadas y la pérdida de datos. En tu sitio, solo ejecuta una verificación rápida contra tu propia base de datos para ver si el trabajo está hecho. También puedes usar un WebSocket para enviar la actualización al instante. Ambas formas son mucho más seguras que esperar que una sola conexión web permanezca abierta durante 15 segundos.
Optimización avanzada: Coherencia de marca — El "foso" defensivo
Cualquier desarrollador puede configurar una llamada básica de texto a imagen en una tarde. Lo que los competidores no pueden replicar fácilmente es un sistema visual que produzca imágenes específicas de tu marca cada vez. La personalización LoRA y los endpoints de edición de imágenes son donde la API de generación de imágenes pasa de ser una función básica a un diferenciador genuino del producto.
Integración LoRA: Enseñando tu estilo a la API
LoRA es una forma inteligente de ajustar un modelo de IA sin empezar de cero. Solo entrenas una pequeña capa que se coloca sobre el motor principal. Esto crea un archivo .safetensors pequeño que puedes usar con tus solicitudes de imagen. Ayuda a mantener un aspecto constante siempre. Úsalo para ceñirte al estilo artístico específico de tu marca, las vibras de tus productos o temas visuales únicos.
Cómo se ve el flujo de trabajo en la práctica (Atlas Cloud + Flux):
Paso 1 — Entrenar el LoRA
plaintext1import { atlas } from "@atlas-cloud/sdk"; 2 3// Atlas Cloud aprovecha clusters H100 para un ajuste fino rápido 4const training = await atlas.models.train({ 5 type: "lora", 6 base_model: "flux-dev", 7 dataset_url: "https://your-storage.com/brand-set.zip", 8 trigger_word: "brandstyle", 9 config: { 10 rank: 16, 11 learning_rate: 0.0001, 12 max_steps: 1200 13 } 14}); 15 16const loraId = training.id; // Usa este ID en tus llamadas de generación
Paso 2 — Generar con tu estilo personalizado
plaintext1const generateResponse = await fetch("https://api.atlascloud.ai/api/v1/model/generateImage", { 2 method: "POST", 3 headers: { 4 "Authorization": `Bearer ${process.env.ATLAS_API_KEY}`, 5 "Content-Type": "application/json" 6 }, 7 body: JSON.stringify({ 8 model: "black-forest-labs/flux-dev-lora", // Endpoint LoRA especializado 9 prompt: "A product shot of a ceramic mug, brandstyle, studio lighting", 10 loras: [ 11 { 12 // Soporta: <propietario>/<nombre-modelo> (Hugging Face) o una URL HTTPS directa 13 path: "https://api.atlascloud.ai/weights/user-123/brandstyle.safetensors", 14 scale: 0.85 // El control de "influencia" (0.0 a 1.5) 15 } 16 ], 17 size: "1024x1024", 18 num_inference_steps: 30, // Optimizado para Flux-Dev 19 output_format: "png" 20 }) 21}); 22 23const { id: predictionId } = await generateResponse.json();
El entrenamiento cuesta USD2 por ejecución (escalando linealmente con los pasos), y los LoRAs entrenados se despliegan inmediatamente en los endpoints de generación sin necesidad de configurar infraestructura adicional.
Parámetros clave a ajustar:
| Parámetro | Rango recomendado | Efecto |
| scale | 0.5 – 1.5 | Controla qué tan fuerte anula el estilo al modelo base |
| steps | 800 – 1500 | Más pasos = captura de estilo más fuerte, pero riesgo de sobreajuste (overfitting) |
| Imágenes de entrenamiento | 15 – 30 imágenes | La calidad importa más que la cantidad; los ejemplos inconsistentes producen resultados inconsistentes. |
Imagen a imagen e Inpainting: Editar, no solo generar
Pasar de texto a imagen a capacidades de imagen a imagen desbloquea una categoría completamente diferente de funciones de usuario: permitir que las personas modifiquen fotos existentes en lugar de generar desde cero.
El endpoint images.edit en GPT Image 2 acepta una o más imágenes de referencia más un prompt, y soporta inpainting y outpainting con máscara; las regiones no enmascaradas se conservan mientras el modelo aplica cambios solo al área especificada.
Casos de uso comunes que esto desbloquea para tu aplicación:
- Reemplazo de fondo: cambia fondos de fotos de productos a escala sin un estudio fotográfico.
- Eliminación de objetos: permite a los usuarios limpiar elementos no deseados de las imágenes cargadas.
- Outpainting: extiende el lienzo de una imagen existente para que se ajuste a nuevas relaciones de aspecto.
plaintext1import openai, base64, pathlib 2 3client = openai.OpenAI() 4 5image_bytes = pathlib.Path("product.png").read_bytes() 6mask_bytes = pathlib.Path("background-mask.png").read_bytes() 7 8result = client.images.edit( 9 model="gpt-image-2", 10 image=image_bytes, 11 mask=mask_bytes, 12 prompt="Replace the background with a clean white studio backdrop", 13 size="1024x1024", 14 quality="medium" 15) 16 17output = base64.b64decode(result.data[0].b64_json) 18pathlib.Path("edited.png").write_bytes(output)
La imagen de máscara es un PNG en escala de grises donde los píxeles blancos indican las regiones que el modelo puede regenerar y los píxeles negros marcan las áreas a conservar exactamente. No se necesita una tubería de inpainting separada; el endpoint de edición lo maneja en una sola llamada.
Conclusión y próximos pasos
Cada sección de esta guía apunta a la misma verdad subyacente: integrar una API de generación de imágenes ya no es un proyecto de investigación, es una tarea de ingeniería de rutina. Las herramientas son maduras, la documentación es sólida y los precios han bajado a un punto en el que incluso los productos en etapa temprana pueden absorber los costos de generación sin que los errores de redondeo se conviertan en problemas reales. ¿Listo para construir? Comienza tu primera integración con la API de OpenAI GPT Image 2.
Preguntas frecuentes
¿Puedo usar imágenes generadas por IA para productos comerciales?
Sí, pero debes entender la diferencia entre poseer un archivo y tener derechos de autor. OpenAI te otorga derechos totales sobre tus resultados para cosas como anuncios, productos y ventas. En el mundo real, esto significa que puedes usar el arte con fines de lucro, pero no puedes evitar que un rival use la misma imagen. Para proteger tu marca, debes agregar tu propio toque humano. Intenta editar el trabajo, cambiar el diseño o usar configuraciones personalizadas. Estos pasos te ayudan a crear un aspecto único para tu negocio incluso si no tienes derechos de autor legales.
¿Cómo manejo las "alucinaciones" en imágenes con mucho texto?
Usa un modelo diseñado específicamente para renderizado de texto. Ideogram v3 renderiza texto con una precisión superior al 95% para prompts estándar, mientras que los modelos de propósito general aún fallan significativamente en cadenas de varias palabras. Para GPT Image 2, coloca cualquier texto que deba aparecer exactamente como está escrito entre comillas dentro de tu prompt, y agrega una instrucción explícita de que debe aparecer una vez y solo como está escrito; esto reduce significativamente la duplicación y los errores de ortografía.
¿Cuál es la forma más barata de escalar a 10,000 usuarios?
Rutea por tarea en lugar de comprometerte con un solo proveedor. Un enfoque escalonado práctico:
| Volumen / Caso de uso | Modelo recomendado | Costo estimado |
| Borradores y vistas previas | GPT Image 2 | ~USD0.01 / imagen |
| Redes sociales y marketing estándar | Seedream v5.0 Lite | ~USD0.032 / imagen |
| Activos hero de alta fidelidad | Flux o Imagen 4 Ultra | ~USD0.003–0.06 / imagen |
| Tiempo real / alto rendimiento | Z-Image Turbo | ~USD0.01 / imagen |
Nota: Los precios se basan en Atlas Cloud.
Para los desarrolladores de gran volumen, la brecha de precios entre las opciones más baratas y las más caras alcanza una diferencia de 33 veces; elegir la API correcta para cada tipo de tarea puede ahorrar miles de dólares al mes. Combina esta estrategia de enrutamiento con el manejo de webhooks asíncronos y la selección de niveles de calidad según el destino de la salida, y los costos escalarán de forma predecible con tu base de usuarios.






