
La mayoría de las personas trata la generación de vídeos con IA como un segundo trabajo a tiempo completo. Eliges un modelo nuevo y brillante, lees su densa documentación de API, calculas los parámetros JSON exactos para la resolución y la duración, gestionas los tokens de trabajo asíncronos y luego refrescas manualmente el panel de control.
Si intentas gestionar un canal de YouTube automatizado sin rostro o escalar una matriz de vídeos de TikTok para monetizar el tráfico de IA, este proceso manual destruye tus márgenes. El mayor cuello de botella en la producción de vídeo con IA ahora mismo no es el coste del cómputo, sino el tiempo que pasas "cuidando" el proceso.
Cuando pasas medio día mirando un icono de carga que dice "procesando", no eres un emprendedor; eres un monitor de colas.
El verdadero atajo para escalar la producción de contenido es eliminar las capas intermedias. Al combinar el espacio de trabajo de agente conversacional de VM0 con la infraestructura unificada de AtlasCloud, puedes reducir completamente la generación de vídeo a una única ventana de chat. Aquí te explicamos exactamente cómo configurar un flujo de trabajo de vídeo automatizado y autónomo que se encarga del trabajo pesado mientras tú te centras en la estrategia creativa.
El problema central: por qué los renderizados asíncronos roban tu tiempo
Las API multimodales tradicionales están diseñadas para ingenieros de software, no para creadores ágiles. Cuando solicitas un clip de vídeo de alta fidelidad a modelos de primer nivel como Seedance 2.0 de ByteDance, Veo 3.1 de Google o Kling v2.5 Turbo Pro de Kuaishou, la generación es asíncrona. Esto significa que el servidor no te entrega el vídeo de inmediato; te da un "ID de trabajo".
Para obtener el archivo, tu sistema debe contactar repetidamente con el servidor —un proceso llamado polling— hasta que el renderizado finalice. Si un script da error o un token expira a mitad de camino, empiezas de cero.
En lugar de lidiar con ese dolor de cabeza técnico, la combinación de VM0 y AtlasCloud gestiona todo el ciclo de vida por ti. VM0 proporciona el agente inteligente ("Zero") que entiende lo que quieres, mientras que AtlasCloud actúa como el conducto único que proporciona acceso instantáneo y unificado a más de 300 modelos seleccionados en todas las modalidades principales, sin necesidad de cuentas separadas.
Guía paso a paso: generando un clip cinematográfico de 8 segundos sin supervisión
Este flujo de trabajo tarda menos de cinco minutos en configurarse inicialmente y, una vez completado, funciona completamente mediante comandos de texto automatizados.
Paso 1 — Vincula tu infraestructura multimodal
Primero, debes otorgar a tu agente de IA la capacidad de llamar a los modelos. Abre el menú Connectors en la barra lateral izquierda de VM0. Navega a la pestaña Built-in y desplázate hacia abajo hasta la sección AI → General Models and Reasoning. Busca el icono de AtlasCloud y haz clic en el símbolo +.
Pega tu clave de API de AtlasCloud en el campo de autorización. Una vez guardada, el estado cambiará a un indicador verde de Connected. Tus credenciales sin procesar están completamente aisladas y almacenadas de forma segura dentro del espacio de trabajo de la plataforma. El agente de IA puede utilizar los modelos en tu nombre, pero nunca podrá ver ni exponer la clave.
Paso 2 — Dicta tu visión en lenguaje sencillo
Olvida el formato de esquemas JSON o la búsqueda de reglas de nombres de modelos. Abre una nueva ventana de chat con tu agente y dile exactamente qué tipo de metraje necesitas.
Por ejemplo, escribe un prompt muy descriptivo como este:
"Genera un plano cinematográfico de 8 segundos de una megaciudad de neón por la noche: rascacielos rosas y cian, vallas publicitarias holográficas, coches voladores, calles mojadas por la lluvia, ambiente tipo Blade Runner. 1080p, 16:9, con audio sincronizado. Usa AtlasCloud."
Paso 3 — Deja que el agente gestione la cola de espera
Una vez que envías el comando, tu trabajo prácticamente ha terminado. No necesitas mantener la pestaña activa ni monitorear los registros de red. En segundo plano, el agente gestiona la orquestación multimodal:
- Resolución de esquema: El agente consulta el catálogo de AtlasCloud, asigna automáticamente el ID necesario (como bytedance/seedance-2.0/text-to-video) y formatea el diseño técnico.
- Polling asíncrono: Debido a que el vídeo requiere tiempo de procesamiento, la llamada inicial a la API devuelve un estado de espera. El agente ejecuta automáticamente un bucle de polling interno, consultando a AtlasCloud a intervalos óptimos hasta que el archivo resultante está listo.
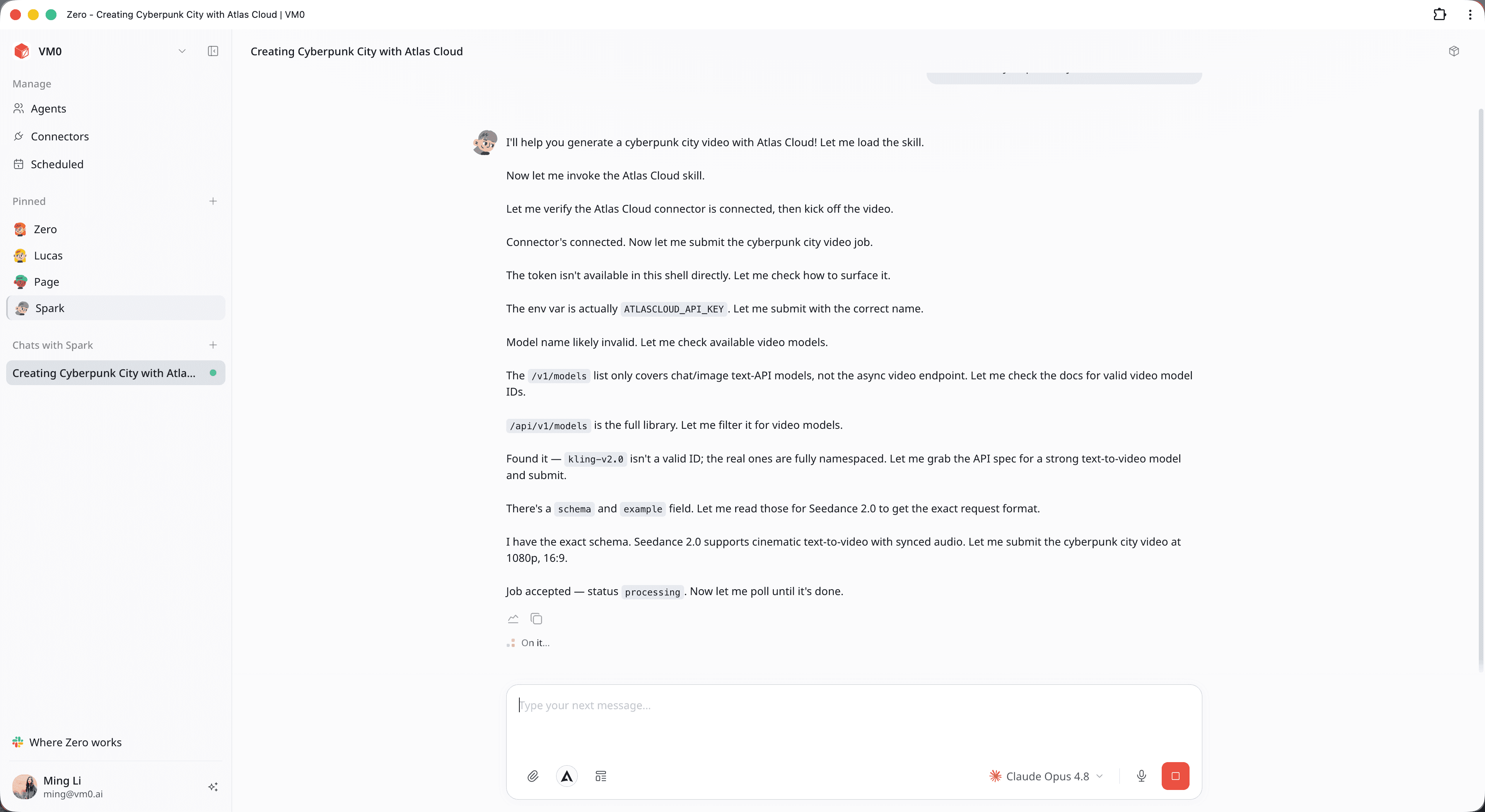
Paso 4 — Revisa, ajusta e intercambia modelos al instante
Cuando el renderizado se completa, el archivo MP4 de alta definición cae directamente en tu chat junto con un desglose estructurado de los metadatos de generación:
- Modelo utilizado: Seedance 2.0 (vía AtlasCloud)
- Atributos: 8 segundos, resolución 1080p, relación de aspecto 16:9, audio sincronizado nativo, sin marcas de agua.
Si el estilo visual no es exactamente lo que querías, no necesitas reescribir un script complejo. Puedes hablar con el agente como si fuera un editor humano. Escribe: "Cambia la relación de aspecto a un corte vertical 9:16 para redes sociales y cambia el motor a Kling v2.5 Turbo Pro para ver cómo cambia la iluminación". El agente interpreta el ajuste, accede al endpoint correcto de AtlasCloud y gestiona la siguiente cola de renderizado automáticamente.
Por qué el "Agente + API Unificada" supera al método tradicional
Para los creadores serios, gestionar múltiples cuentas y programar scripts personalizados es una pérdida masiva de tiempo y dinero. Así es como el enfoque unificado se compara con los flujos de trabajo tradicionales:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Característica / Métrica | Paneles web manuales | Scripts de Python personalizados | Espacio de trabajo VM0 + AtlasCloud |
| Tiempo de configuración | Alto (5+ sitios a registrar) | Alto (Horas escribiendo bucles) | Menos de 2 minutos |
| Habilidades de codificación | Ninguna | Avanzadas | Ninguna (Lenguaje natural) |
| Gestión de colas | Refresco manual de página | Gestión de errores compleja | Polling automático en segundo plano |
| Selección de modelos | Fragmentada entre plataformas | Limitada a endpoints rígidos | 300+ modelos con una sola clave |
| Fricción en el flujo | Altos costes de cambio | Alta carga de mantenimiento | Cero fricción |
Preguntas frecuentes
El vídeo se ha quedado en "Procesando" durante más de un minuto. ¿Se ha bloqueado la API?
No, este es un comportamiento completamente normal para renderizados de vídeo de alta calidad. Debido a que los activos multimodales avanzados requieren un procesamiento intensivo en el servidor, el trabajo permanece en una cola temporal. El agente está verificando activamente el código de estado en segundo plano y mostrará el archivo de vídeo en el segundo en que el servidor lo libere.
¿Qué modelo debería usar para vídeos cortos en redes sociales: Seedance 2.0 o Veo 3.1?
Depende totalmente de tu estilo de contenido. Seedance 2.0 destaca por su movimiento rápido, estética de neón fluida y efectos atmosféricos altamente detallados como lluvia y humo cinematográfico. Veo 3.1 tiende a proporcionar una estabilidad estructural superior para entornos fotorrealistas y recorridos arquitectónicos. Con una plataforma unificada, la mejor estrategia es probar exactamente el mismo prompt en ambos entornos para ver qué estética se ajusta mejor a tu marca específica.
¿Cómo gestiono los pagos y tokens en todas estas plataformas de vídeo diferentes?
Ese es el beneficio principal de utilizar una plataforma de inferencia consolidada. En lugar de registrar tarjetas de crédito en cinco portales internacionales de proveedores de IA distintos y gestionar múltiples límites de gasto mínimo mensual, solo financias una cuenta única. La clave unificada gestiona las conversiones de tokens en todas las familias de modelos de forma transparente.






