OpenAI LLM Models
OpenAI’s premier GPT model family leads the industry, highlighted by the GPT OSS 120B which achieves near-parity with OpenAI o4-mini on core reasoning benchmarks while running efficiently on a single 80GB GPU. Perfectly optimized for vibecoding and complex logic operations, this model balances top-tier intelligence with hardware accessibility for modern developers and AI-driven web development.
Modelos próximos a lanzarse
Estamos dando los toques finales a esta colección — mientras tanto, explora colecciones similares a continuación.
Explorar Más Series
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
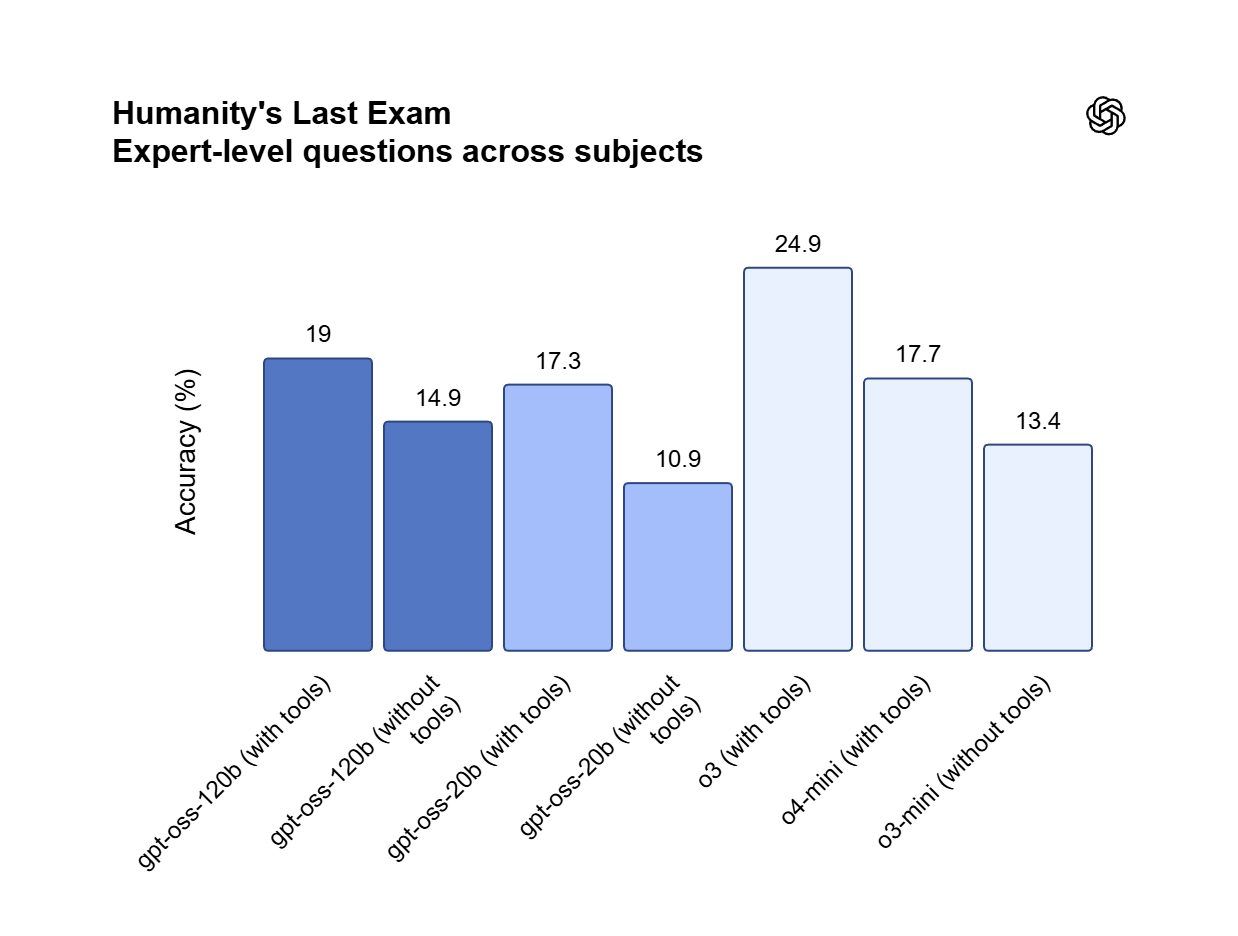
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Happy Horse 1.0
HappyHorse-1.0 is a unified multimodal AI video generation model that climbed to the top of the Artificial Analysis Video Arena blind-test leaderboard for both text-to-video and image-to-video generation. CNBC Alibaba Group confirmed ownership of HappyHorse, developed under its Alibaba Token Hub (ATH) business unit, where it leads benchmarks outperforming ByteDance's Seedance 2.0 and others. Caixin Global Led by Zhang Di — the former VP of Kuaishou who architected Kling AI — the 15-billion parameter model generates 1080p video with synchronized audio in a single pass using a unified transformer architecture that bypasses the multi-stage pipelines used by every major competitor.
Seedance 2.0 Models
Seedance 2.0(by Bytedance) is a multimodal video generation model that redefines "controllable creation," moving beyond the limitations of text or start/end frames. It supports quad-modal inputs—text, image, video, and audio—and introduces an industry-leading "Universal Reference" system. By precisely replicating the composition, camera movement, and character actions from reference assets, Seedance 2.0 solves critical issues with character consistency and physical coherence, empowering creators to act as true "directors" with deep control over their output.
GPT Image 2 Models
GPT Image 2 is a state-of-the-art multimodal foundation model engineered for exceptional text-to-image generation with unprecedented photorealism and creative versatility. Developed by OpenAI as the evolution of the DALL-E lineage, it transforms detailed natural language descriptions into hyper-realistic imagery at up to 4K resolution. With proprietary "Neural Rendering Engine" technology for precise visual control, GPT Image 2 delivers studio-quality results with accurate anatomy, lighting, and composition—making it the premier AI tool for professional creators, enterprises, and developers demanding production-ready visual assets.
Wan2.7 Models
Launching this March, Wan2.7 is the latest powerhouse in the Qwen ecosystem, delivering a massive upgrade in visual fidelity, audio synchronization, and motion consistency over version 2.6. This all-in-one AI video generator supports advanced features like first-and-last frame control, 3x3 grid synthesis, and instruction-based video editing. Outperforming competitors like Jimeng, Wan2.7 offers superior flexibility with support for real-person image inputs, up to five video references, and 1080P high-definition outputs spanning 2 to 15 seconds, making it the premier choice for professional digital storytelling and high-end content marketing.
Veo3.1 Models
Google DeepMind’s Veo 3.1 represents a paradigm shift in AI video generation, empowering creators with director-level narrative control and cinematic-grade audio quality that seamlessly integrates with its enhanced visual realism. By bridging the gap between imaginative concepts and photorealistic execution, this advanced model offers a transformative solution for a wide range of application scenarios, from professional filmmaking and high-end advertising to immersive digital content creation.
ERNIE Image Models
ERNIE-Image is an open-weight text-to-image model developed by the ERNIE-Image Team at Baidu, built on a single-stream Diffusion Transformer (DiT) with 8B parameters and paired with a lightweight Prompt Enhancer that rewrites short prompts into richer, more structured descriptions before passing them to the diffusion backbone. NYU Shanghai RITS Released on April 15, 2026 under the Apache 2.0 license, it transforms natural language descriptions into detailed imagery with particular strength in text rendering and structured layout generation. ERNIE-Image is designed not only for strong visual quality, but for controllability in practical generation scenarios where accurate content realization matters as much as aesthetics — making it well-suited for commercial posters, comics, multi-panel layouts, and other content creation tasks that require both visual quality and precise control.
GPT Image Models
The GPT Image Family is OpenAI's latest suite of multimodal image generation and editing models, built on the powerful GPT architecture. This family includes three tiers — GPT Image-1, GPT Image-1.5, and GPT Image-1 Mini — each available in both Text-to-Image and Image-to-Image variants. Combining GPT's world-class language understanding with DALL·E-class visual synthesis, these models deliver exceptional prompt adherence, photorealistic rendering, and creative versatility across illustration, photography, design, and visualization tasks. The series offers flexible pricing and quality tiers to match any workflow — from rapid prototyping and high-volume content production to professional-grade final deliverables. Whether you need ultra-fast iterations at minimal cost or maximum quality for brand campaigns, the GPT Image Family has a solution tailored to your needs.
Nano Banana2 Models
Nano Banana 2 (by Google), is a generative image model that perfectly balances lightning-fast rendering with exceptional visual quality. With an improved price-performance ratio, it achieves breakthrough micro-detail depiction, accurate native text rendering, and complex physical structure reconstruction. It serves as a highly efficient, commercial-grade visual production tool for developers, marketing teams, and content creators.
Seedream5.0 Models
Seedream 5.0, developed by ByteDance’s Jimeng AI, is a high-performance AI image generation model that integrates real-time search with intelligent reasoning. Purpose-built for time-sensitive content and complex visual logic, it excels at professional infographics, architectural design, and UI assistance. By blending live web insights with creative precision, Seedream 5.0 empowers commercial branding and marketing with a seamless, logic-driven workflow that turns sophisticated data into stunning, high-fidelity visuals.
Kling3.0 Models
Kuaishou’s flagship video generation suite, Kling 3.0, features two powerhouse models—Kling 3.0 (Upgraded from Kling 2.6) and Kling 3.0 Omni (Kling O3, Upgraded from Kling O1)—both offering high-fidelity native audio integration. While Kling 3.0 excels in intelligent cinematic storytelling, multilingual lip-syncing, and precision text rendering, Kling O3 sets a new standard for professional-grade subject consistency by supporting custom subjects and voice clones derived from video or image inputs. Together, these models provide a comprehensive solution tailored for cinematic narratives, global marketing campaigns, social media content, and digital skit production.
GLM LLM Models
GLM is a cutting-edge LLM series by Z.ai (Zhipu AI) featuring GLM-5, GLM-4.7, and GLM-4.6. Engineered for complex systems and long-horizon agentic tasks, GLM-5 outperforms top-tier closed-source models in elite benchmarks like Humanity’s Last Exam and BrowseComp. While GLM-4.7 specializes in reasoning, coding, and real-world intelligent agents, the entire GLM suite is fast, smart, and reliable, making it the ultimate tool for building websites, analyzing data, and delivering instant, high-quality answers for any professional workflow.
Open AI Model Families
Explore OpenAI’s language and video models on Atlas Cloud: ChatGPT for advanced reasoning and interaction, and Sora-2 for physics-aware video generation.
Qué Hace Destacar a OpenAI LLM Models
Atlas Cloud le proporciona los modelos creativos líderes en la industria más recientes.

Frontier Research
Cutting-edge models that set global benchmarks in reasoning, multimodality, and AI safety.

Cost-Efficient Performance
Optimized families like GPT-4.1 mini and GPT-5 nano balance accuracy, speed, and cost.

Developer Ecosystem
APIs powering millions of daily requests across diverse platforms and industries.

Flexible Model Sizes
Choice of flagship, mini, and nano models for every workload and budget.

Enterprise Reliability
SLAs, monitoring, and compliance-ready logging trusted by Fortune 500 companies.

Open Model Options
Access to open-source models (gpt-oss-20b, gpt-oss-120b) for transparency and customization.
Velocidad máxima
Costo más bajo
| Modelo | Descripción |
|---|---|
| GPT OSS 120B | GPT OSS 120B es un LLM de alto rendimiento centrado en el razonamiento, que integra una arquitectura optimizada con una robusta capacidad de procesamiento de contexto de 131.07K; logrando una paridad casi total con OpenAI o4-mini en una sola GPU de 80 GB, sirve como motor para el desarrollo iterativo rápido, incluyendo vibecoding y la ejecución de flujos de trabajo complejos impulsados por lógica. |
Nuevas funciones de OpenAI LLM Models + Showcase
La combinación de modelos avanzados con la plataforma acelerada por GPU de Atlas Cloud ofrece velocidad, escalabilidad y control creativo inigualables para la generación de imágenes y videos.
Cumplimiento preciso de instrucciones mediante GPT OSS 120B
GPT OSS 120B exhibe una capacidad de dirección excepcional, adhiriéndose estrictamente a prompts de sistema complejos para garantizar una fiabilidad de salida absoluta. Al aprovechar su arquitectura de alineación ajustada (fine-tuned), los usuarios pueden imponer formatos específicos, restricciones y matices estilísticos con cero deriva de caracteres. Es la elección definitiva para agentes autónomos, extracción de datos estructurados y entornos de producción de misión crítica.
Soberanía comercial bajo la licencia Apache 2.0
GPT OSS 120B se distribuye bajo la licencia Apache 2.0, lo que permite un uso comercial sin restricciones y un ajuste fino (fine-tuning) privado sin tarifas por token. A diferencia de las API de código cerrado, permite el alojamiento local en una sola GPU de 80 GB para mantener los datos propietarios sensibles totalmente on-premise. Este marco proporciona la libertad legal y técnica para construir, modificar y escalar pilas de software impulsadas por IA.
Lógica de alta eficiencia y Vibecoding con GPT OSS 120B
Logrando casi la paridad con OpenAI o4-mini, este modelo de 120B de parámetros sobresale en el manejo de síntesis de código compleja y demostraciones matemáticas. Los desarrolladores pueden aprovechar su motor de razonamiento para el "vibe coding": traducir ideas en lenguaje natural directamente a aplicaciones web funcionales mediante prompting iterativo. Es una solución de alta velocidad para depurar lógica anidada y orquestar flujos de trabajo sofisticados de programación de tareas.
Qué Puedes Hacer con OpenAI LLM Models
Descubra casos de uso prácticos y flujos de trabajo que puede crear con esta familia de modelos — desde creación de contenido y automatización hasta aplicaciones de nivel producción.
Depuración de lógica profunda y prototipado con el GPT OSS 120B
El GPT OSS 120B permite a los ingenieros resolver desafíos de "vibecoding" traduciendo ideas arquitectónicas de alto nivel en componentes de Python o React listos para producción. Su motor de razonamiento maneja las dependencias anidadas y los casos extremos que a menudo hacen fallar a los mini-modelos, asegurando que la síntesis de código de múltiples pasos siga siendo funcional. Al admitir pruebas algorítmicas y programación de tareas complejas, es la herramienta perfecta para crear MVP técnicos, scripts de QA automatizados y aplicaciones web intensivas en datos.
Herramientas propietarias sin conexión utilizando GPT OSS 120B
Bajo la licencia Apache 2.0, los equipos pueden alojar GPT OSS 120B en una sola GPU de 80 GB para procesar datos internos confidenciales sin riesgos de fuga en la nube. Esta configuración permite el ajuste fino (fine-tuning) local permanente en bases de código internas especializadas o registros médicos sin costes recurrentes de API por token. Ideal para herramientas internas de alta seguridad y asistencia de IA offline, el modelo proporciona soberanía total de los pesos, soportando sistemas RAG privados y pilas de software propietario personalizadas.
Extracción de datos con esquema perfecto mediante GPT OSS 120B
El GPT OSS 120B permite a los desarrolladores convertir documentos desordenados y no estructurados en JSON o Markdown estrictamente formateados sin "desviación de instrucciones". Al anclar la ventana de contexto de 131.07K con reglas de sistema rígidas, el modelo garantiza que los campos nunca se alucinen ni se omitan durante el procesamiento de formato largo. Ideal para la automatización de CRM y el etiquetado de contenido automatizado, mantiene barreras lógicas en conjuntos de datos masivos, lo que admite integraciones de API confiables y población de bases de datos.
Comparación de Modelos
Vea cómo se comparan los modelos de diferentes proveedores — compare rendimiento, precios y fortalezas únicas para tomar una decisión informada.
| Modelo | Contexto | Salida máxima | Entrada | Posicionamiento |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Texto | LLM de razonamiento de alta eficiencia |
| GLM-5 | 202.75K | 202.75K | Texto | Modelo fundacional insignia |
| DeepSeek V3.2 | 163.84K | 163.84K | Texto | Insignia general |
| MiniMax-M2.5 | 204.8K | 196.6K | Texto | Programación agéntica SOTA |
How to Use OpenAI LLM Models on Atlas Cloud
Get started in minutes — follow these simple steps to integrate and deploy models through Atlas Cloud’s platform.
Create an Atlas Cloud Account
Sign up at atlascloud.ai and complete verification. New users receive free credits to explore the platform and test models.
Por Qué Usar OpenAI LLM Models en Atlas Cloud
Combina modelos avanzados de OpenAI LLM Models con la plataforma acelerada por GPU de Atlas Cloud, proporcionando rendimiento, escalabilidad y experiencia de desarrollo incomparables.
Rendimiento y Flexibilidad
Baja Latencia:
Inferencia optimizada por GPU para respuestas en tiempo real.
API Unificada:
Una sola integración para acceder a OpenAI LLM Models, GPT, Gemini y DeepSeek.
Precios Transparentes:
Facturación por Token, soporta modo Serverless.
Empresa y Escala
Experiencia del Desarrollador:
SDK, análisis de datos, herramientas de ajuste fino y plantillas todo en uno.
Confiabilidad:
99.99% de disponibilidad, control de permisos RBAC, registros de cumplimiento.
Seguridad y Cumplimiento:
Certificación SOC 2 Type II, cumplimiento HIPAA, soberanía de datos en EE.UU.
Preguntas Frecuentes sobre OpenAI LLM Models
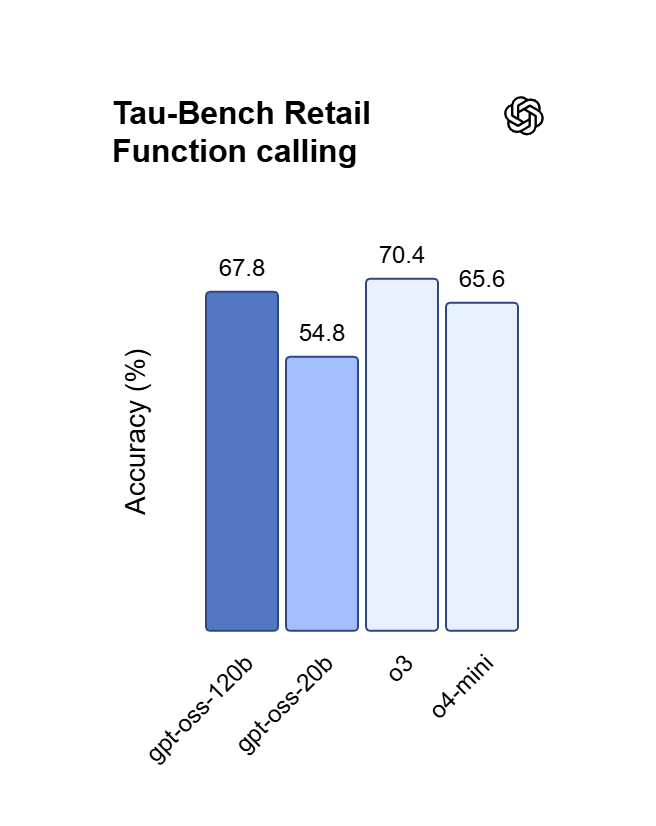
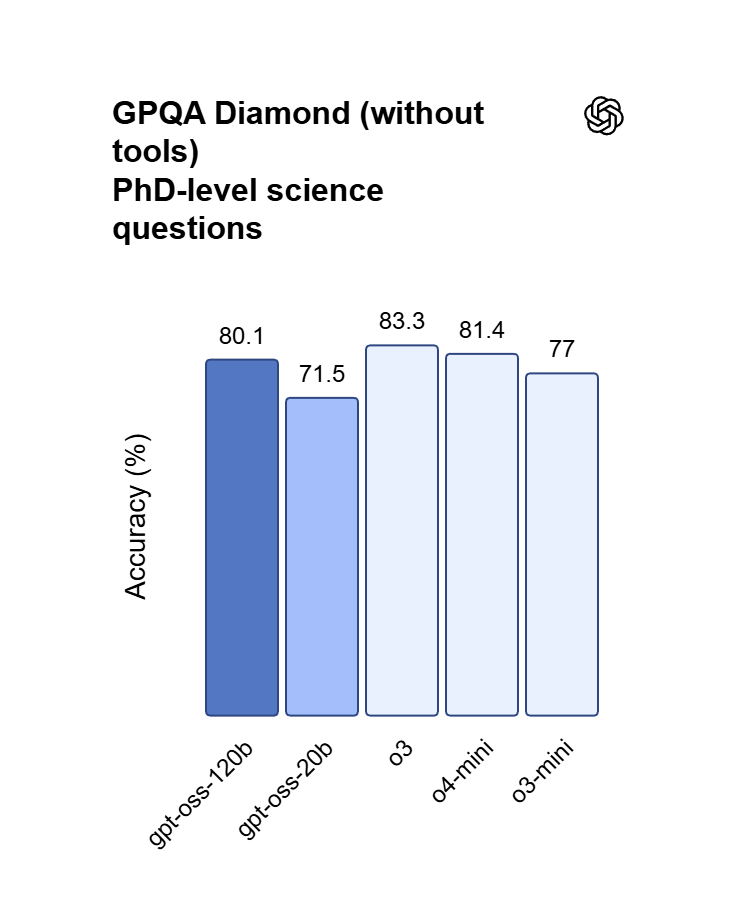
Logra una casi paridad con OpenAI o4-mini en los benchmarks de razonamiento central y matemáticas. Mientras que o4-mini es una API cerrada, OSS 120B ofrece una profundidad lógica comparable con el beneficio añadido del acceso completo a los pesos del modelo.
El modelo está optimizado para una sola GPU de 80 GB, evitando la complejidad de múltiples nodos. Sin embargo, para una escalabilidad instantánea y cero mantenimiento, recomendamos acceder a él a través de la API en Atlas Cloud.
Sí. Se publica bajo la licencia Apache 2.0, que permite el uso comercial, la modificación y la distribución sin restricciones, sin tarifas de licencia por token ni dependencia de un proveedor (vendor lock-in).
La ventana de contexto de 131.07K está diseñada para una precisión de recuperación tipo "aguja en un pajar". Puede procesar directorios de proyectos enteros o manuales técnicos de más de 100 páginas manteniendo la coherencia lógica en toda la entrada.
Extremadamente. Su motor de razonamiento está ajustado para la síntesis de código iterativa. Gestiona componentes React anidados y backends complejos en Python con mayor fiabilidad que los modelos estándar de clase 70B, lo que lo hace ideal para flujos de trabajo de lenguaje natural a aplicación.


