
ChatGPT API for Frontier GPT 5.6 Reasoning
La API de ChatGPT en Atlas Cloud reúne la familia GPT 5.6 más reciente de OpenAI en una sola integración, que abarca Sol para razonamiento avanzado de frontera, Terra para cargas de trabajo de producción con respuestas fundamentadas y Luna para conversaciones naturales y generación de contenido. Dirige todos los modelos mediante una única clave compatible con OpenAI, cuenta con disponibilidad de nivel de producción y paga tarifas transparentes de pago por uso desde $1 por millón de tokens de entrada. Empieza a crear hoy mismo.
Explorar Modelos Líderes
Atlas Cloud le proporciona los últimos modelos creativos líderes en la industria.
Elige el modelo de la API de ChatGPT adecuado: comparación de todos los endpoints
Cinco endpoints de generación de texto que abarcan desde razonamiento de frontera hasta conversación económica, todos servidos mediante una única clave compatible con OpenAI y con precios transparentes de pago por uso.
| Modalidad | Descripción |
|---|---|
| GPT 5.6 Sol API (Texto a texto) | Diseñado para cargas de trabajo de IA de frontera, GPT 5.6 Sol convierte prompts de texto complejos en resultados de razonamiento profundo y de varios pasos para resolver problemas ambiciosos. El precio estándar es de $5 por millón de tokens de entrada y $30 por millón de tokens de salida, lo que lo posiciona como la opción insignia cuando la calidad de la respuesta pesa más que el costo. |
| GPT 5.6 Terra API (Texto a texto) | ¿Necesitas una opción predeterminada fiable para producción? GPT 5.6 Terra convierte prompts en texto fundamentado y práctico para flujos de trabajo reales y pipelines de análisis a $2.50 de entrada y $15 de salida por millón de tokens. Los equipos lo implementan en aplicaciones orientadas al cliente donde la consistencia importa más que la profundidad experimental. |
| GPT 5.6 Luna API (Texto a texto) | Dirige el tráfico conversacional y creativo a GPT 5.6 Luna, un modelo de texto ajustado para diálogo natural, generación de contenido y experiencias de IA personalizadas. A $1 de entrada y $6 de salida por millón de tokens, es el punto de entrada más económico de esta línea de API de ChatGPT, muy adecuado para productos de chat y generación de textos de alto volumen. |
| GPT 5.4 API (Texto a texto) | GPT 5.4 procesa instrucciones de texto para generar código fiable, contenido de formato largo y resultados estructurados de resolución de problemas con gran precisión. Diseñado como un modelo multimodal avanzado, se sitúa en una franja de precio intermedia de $2.50 de entrada y $15 de salida por millón de tokens, una opción práctica para asistentes de programación y plataformas de contenido. |
| GPT 5.5 API (Texto a texto) | Cuando los problemas difíciles justifican una inversión premium, GPT 5.5 ofrece razonamiento avanzado, programación y generación de contenido desde un único endpoint de texto. Con un precio de $5 de entrada y $30 de salida por millón de tokens, está orientado a cargas de trabajo complejas y críticas en fiabilidad, como la orquestación de agentes y el análisis técnico. |
La API de ChatGPT: niveles GPT 5.x y pesos abiertos
Accede a toda la línea GPT 5.x y al GPT OSS 120B de pesos abiertos mediante una única API de ChatGPT, ajusta el esfuerzo de razonamiento de low a xhigh, combina texto, imágenes y archivos en una sola llamada e invoca herramientas nativas con búsqueda web en vivo usando una clave compatible con OpenAI.
Texto, imágenes y archivos en una sola llamada a la API de ChatGPT
Una única solicitud a la API de ChatGPT puede combinar texto sin formato, URLs de imágenes y archivos de documentos en un solo mensaje. Esto elimina la necesidad de servicios separados de OCR o visión, para que puedas resumir contratos escaneados o leer capturas de pantalla de una sola pasada.
Fidelidad a las instrucciones en la API de ChatGPT
GPT OSS 120B respeta los prompts de sistema por capas, manteniendo formatos, restricciones y tono estables en las salidas sin desviaciones. Esa fiabilidad es ideal para agentes autónomos, extracción estructurada y pipelines de producción donde la salida debe obedecer las reglas.
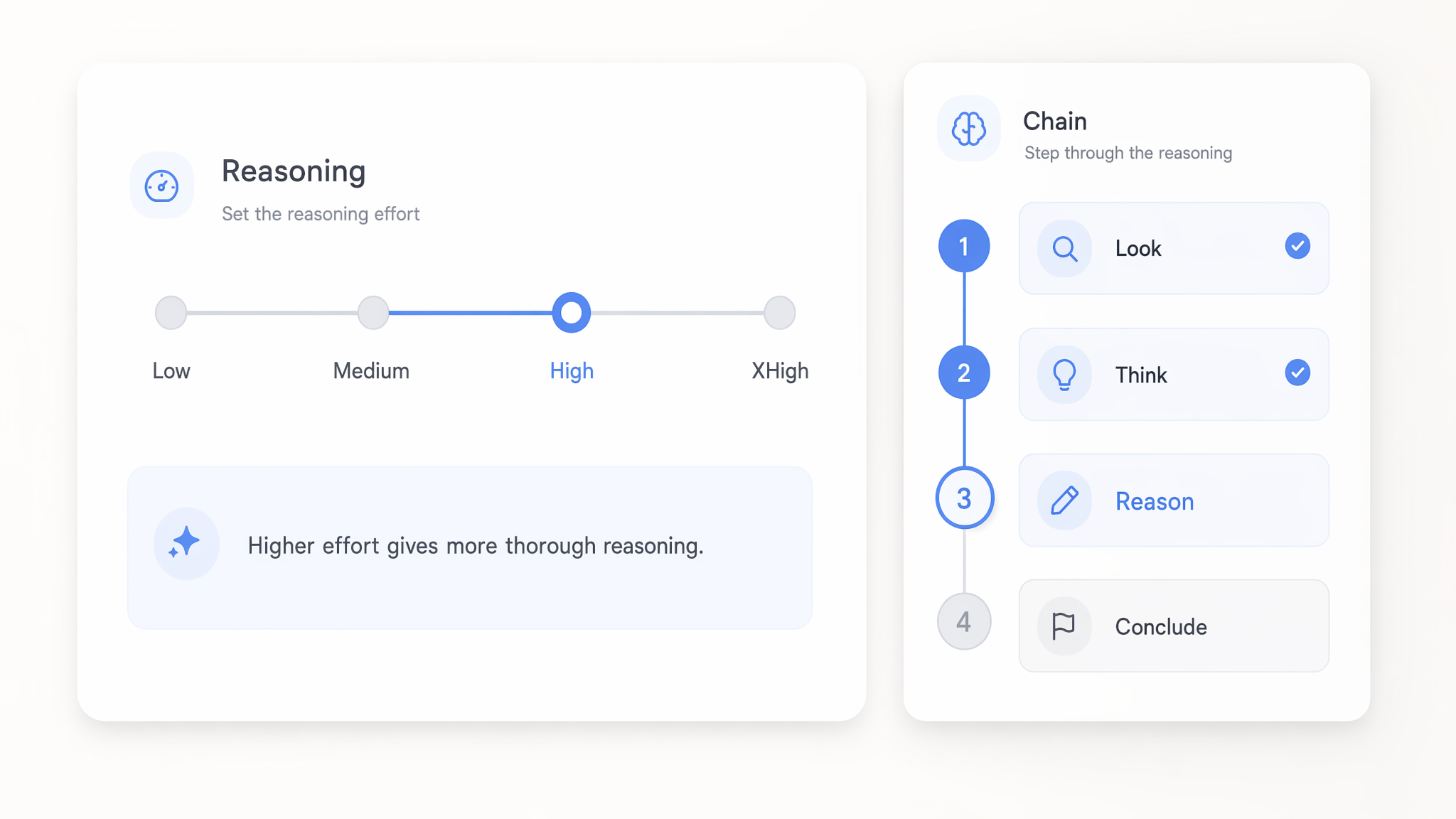
Ajusta el esfuerzo de razonamiento de low a xhigh
Define el esfuerzo de razonamiento en los modelos GPT 5.x desde low hasta xhigh para controlar qué tan profundamente piensan antes de responder. Los ajustes low responden llamadas simples de forma rápida y económica, mientras que xhigh dedica más cómputo a la lógica compleja de varios pasos.
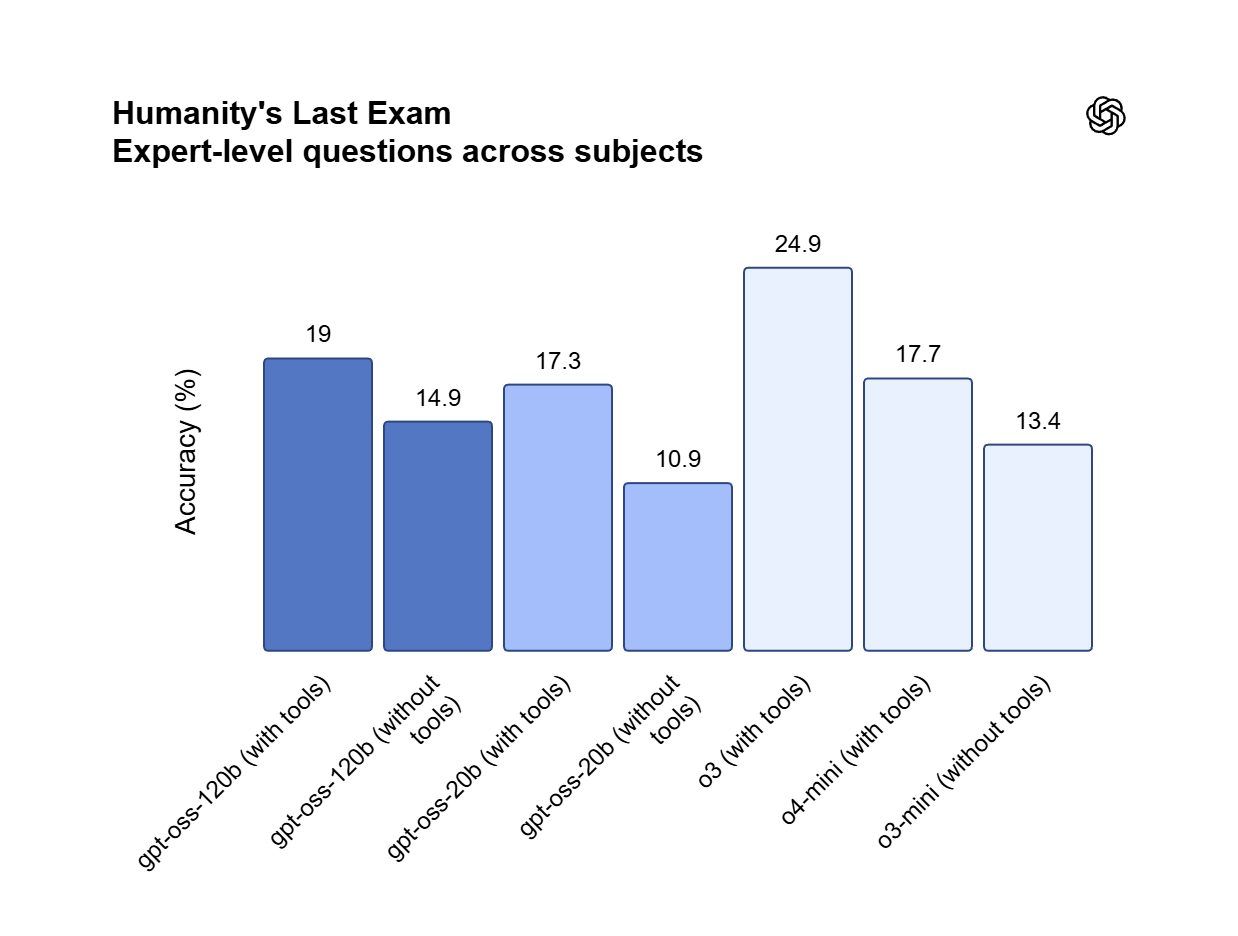
Pesos Apache 2.0 que son totalmente tuyos
Distribuido bajo la licencia Apache 2.0, GPT OSS 120B permite uso comercial y ajuste fino privado en una sola GPU de 80GB. Alójalo on-premises para mantener los datos propietarios dentro de tu organización y evitar por completo las tarifas por token.

Cinco niveles GPT, una sola API de ChatGPT
Una sola API de ChatGPT sirve toda la línea GPT 5.x, con precios desde Luna a $1 hasta Sol a $5 por millón de tokens de entrada. Asigna cada llamada al nivel que requieran su costo y demanda de inteligencia, sin cambios de endpoint.
Razonamiento ajustado para vibecoding
Con una paridad cercana a OpenAI o4-mini, GPT OSS 120B puede manejar síntesis de código de varios pasos y demostraciones matemáticas. Convierte ideas en lenguaje natural en aplicaciones web funcionales, depura lógica anidada y orquesta flujos complejos de programación de tareas.

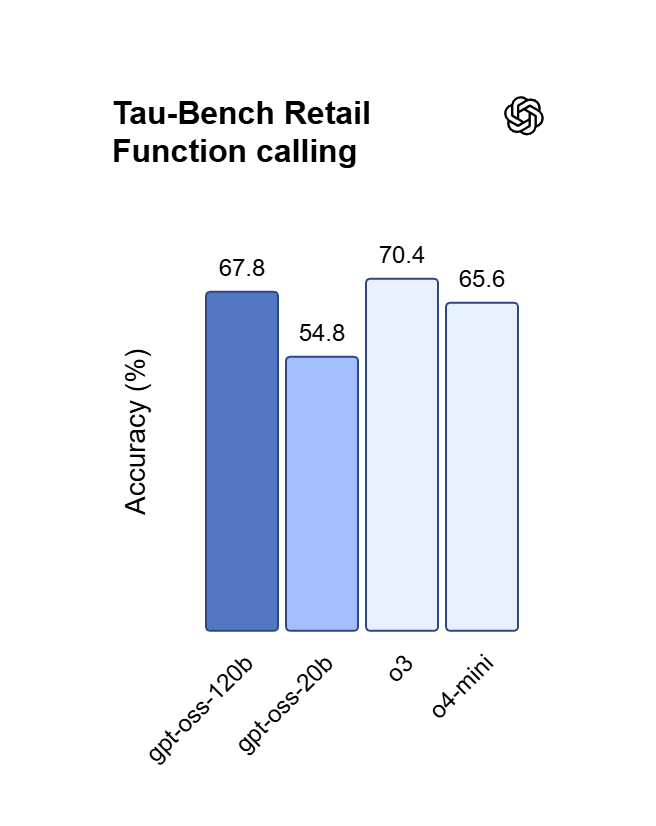
Llamadas a funciones con búsqueda web en vivo
Los modelos GPT 5.x admiten llamadas a funciones con selección automática de herramientas, además de una búsqueda web integrada que obtiene resultados actuales. Transmite respuestas como server-sent events mientras el almacenamiento en caché de prompts reduce la entrada en caché de GPT 5.6 Sol a $0.5 por millón de tokens.
Un prompt, tres contendientes: ChatGPT API frente a frente
Pasamos exactamente la misma instrucción de construcción a modelos mediante la ChatGPT API y a dos buques insignia rivales; luego renderizamos cada respuesta HTML sin procesar y sin modificar para que puedas comparar lado a lado la profundidad del razonamiento, la calidad del código y el criterio de diseño.
Crea un único archivo HTML autocontenido (solo CSS y JavaScript en línea; absolutamente sin bibliotecas externas, CDNs, frameworks, fuentes ni URLs de imágenes) que se abra directamente en cualquier navegador moderno y ejecute un simulador vivo y autoexpansivo de ecosistema de invernadero de cristal, renderizado por completo como ilustración vectorial plana en Canvas/SVG. La escena a pantalla completa es un invernadero victoriano abovedado: una cúpula curva de vidrio cruza la parte superior como elemento de encuadre, con paneles dibujados como polígonos translúcidos de verde jade, reflejos especulares suaves y finos contornos de montantes; una franja de tierra de cultivo oscura recorre la parte inferior. La dirección de arte es una ilustración vectorial limpia: hojas y tallos dibujados con líneas de nervadura nítidas y rellenos superpuestos semitransparentes, una paleta basada en verde salvia brumoso y marrón musgoso, con luz solar ámbar y acentos de vidrio jade; nada de fotorrealismo, nada de degradados usados como texturas; mantén un aspecto gráfico y de ilustración hecha a mano. Interacción principal: al hacer clic en cualquier punto de la tierra se planta una semilla en ese lugar, y la planta crece en tiempo real usando un L-system real: implementa una gramática de reescritura recursiva (axioma más reglas de producción con corchetes de ramificación y variación aleatoria de ángulo/longitud por instancia para que no haya dos plantas idénticas) y anima la derivación para que las ramas se extiendan, se bifurquen y desplieguen hojas progresivamente durante unos segundos, en lugar de aparecer ya formadas. Los helechos tropicales y las enredaderas deben doblarse y enroscarse fototrópicamente hacia un sol arrastrable: renderiza un disco solar ámbar brillante que el usuario pueda agarrar y arrastrar a cualquier punto del cielo, y cada ápice en crecimiento debe reorientar continuamente su dirección de crecimiento hacia la posición actual del sol, de modo que al arrastrar el sol se vea claramente cómo todo el jardín se inclina y trepa. Las plántulas se despliegan con una animación easing, y se forman gotas de condensación sobre el vidrio que se deslizan lentamente hacia abajo en bucle. Controla todo con un ciclo día-noche vinculado a la posición del sol: la luz ambiental y el baño de color del cielo se desplazan suavemente por un gradiente de dorado cálido a azul frío; la ubicación del sol define la dirección y longitud de las sombras suaves de las plantas proyectadas sobre el suelo y de las manchas de luz a la deriva sobre el vidrio; y al anochecer aparecen luciérnagas como pequeños puntos de luz pulsantes que flotan entre el follaje. La composición irradia el crecimiento de las plantas desde la base hacia arriba y hacia el centro, contenida por el arco de la cúpula. Usa requestAnimationFrame para un bucle de animación continuo y de respiración tranquila; mantén un rendimiento fluido con muchas plantas en pantalla a la vez. Incluye controles sutiles y discretos (por ejemplo, un slider o un interruptor de avance automático para la hora del día, y un botón de reiniciar/limpiar) con estilo acorde a la estética ilustrada, además de una pista de una línea que indique al usuario que haga clic en la tierra para plantar y arrastre el sol para guiar el crecimiento. Hazlo adaptable a cualquier tamaño de ventana, y dale un tono emocional calmo, quieto y vivo: la primera luz de la mañana entrando en diagonal mientras brotes tiernos se abren juntos. Es una simulación generativa, no un juego ni un dashboard: prioriza el algoritmo de crecimiento recursivo genuino, el bucle de animación y la física de luz/sombra/fototropismo.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.5 on Atlas Cloud
Crea una página HTML completa de un solo archivo que contenga un dashboard interactivo de financiación global de startups, con datos ficticios pero internamente coherentes para 8 sectores industriales a lo largo de 5 años. Todo el CSS y JavaScript debe estar en línea, con cero dependencias externas, sin bibliotecas de gráficos, sin CDNs y sin imágenes. Renderiza tres visualizaciones programadas a mano en canvas o SVG: un gráfico de barras animado que se reordene con easing cuando el usuario elija un año desde un slider, un gráfico de líneas con tooltips al pasar el cursor que muestren valores exactos y una guía vertical de seguimiento, y un gráfico de dona cuyos segmentos se expandan al pasar el cursor con una animación de resorte. Incluye una UI moderna oscura con una paleta de acentos de violeta a teal, contadores numéricos animados en cuatro tarjetas KPI, una fila de filtros por sector con chips conmutables que actualicen al instante todos los gráficos, y un selector de tema claro/oscuro con transiciones de color suaves. El layout debe ser responsivo, colapsar a una sola columna por debajo de 768px, y cada interacción debe responder en tiempo real sin recargas de página.
Generated with GPT 5.6 Sol on Atlas Cloud
Generated with Grok 4.5 on Atlas Cloud
Generated with GPT 5.4 on Atlas Cloud
Todas las cargas de trabajo que puede impulsar la ChatGPT API
Desde programación agéntica y extracción estructurada hasta chat de soporte con respuestas fundamentadas y contenido de alto volumen, la ChatGPT API en Atlas Cloud dirige cada tarea al nivel de GPT 5.6 adecuado mediante una única clave compatible con OpenAI.

Lanza herramientas de programación agéntica con la ChatGPT API
Dirige refactorizaciones complejas y síntesis de código en varios archivos a GPT 5.6 Sol, el nivel de razonamiento profundo de la familia, creado para cargas de trabajo de ingeniería de vanguardia. Los equipos que crean copilotos de programación, bots de revisión automatizada y generadores de pruebas obtienen lógica de nivel producción.

Generación de contenido alineado con la marca a escala
GPT 5.6 Luna, el nivel creativo de la familia, redacta entradas de blog, descripciones de productos y textos localizados con un tono natural y resultados personalizados. Los equipos de contenido y las plataformas de ecommerce producen textos de gran volumen sin sacrificar la voz de la marca.

Impulsa asistentes de soporte con la ChatGPT API
¿Necesitas un chatbot que se mantenga fiel al guion? GPT 5.6 Terra ofrece respuestas fiables y fundamentadas, diseñadas para conversaciones en producción, de modo que los equipos de soporte y los productos SaaS puedan automatizar tickets y resolver consultas repetitivas de forma confiable.

Sistemas de conocimiento con recuperación aumentada
Introduce manuales de políticas completos o archivos de investigación en un modelo de contexto largo y obtén respuestas fundamentadas con fidelidad a las fuentes. Los equipos legales, médicos y de búsqueda interna obtienen un motor fiable para responder preguntas con recuperación aumentada.

Extracción de datos estructurados mediante la ChatGPT API
Facturas, correos electrónicos y PDF desordenados se convierten en JSON limpio en el que los sistemas posteriores pueden confiar. El seguimiento fiable de instrucciones mantiene intactos los esquemas y da servicio a pipelines de datos, automatización de CRM y flujos de análisis que no pueden tolerar desviaciones.

Asigna cada tarea al nivel de modelo adecuado
Cuando el presupuesto y la latencia importan, cambia entre Sol, Terra y Luna mediante una única clave compatible con OpenAI. Las startups y los desarrolladores independientes crean prototipos rápidamente con precios de pago por uso y luego escalan la misma integración a producción.
| Modelo | Contexto | Salida máxima | Entrada | Posicionamiento |
|---|---|---|---|---|
| GPT OSS 120B | 131.07K | 131.07K | Texto | LLM de razonamiento de alta eficiencia |
| GLM-5 | 202.75K | 202.75K | Texto | Modelo fundacional insignia |
| DeepSeek V3.2 | 163.84K | 163.84K | Texto | Modelo general insignia |
| MiniMax-M2.5 | 204.8K | 196.6K | Texto | Codificación agéntica SOTA |
Cómo usar ChatGPT en Atlas Cloud
Empieza en minutos — sigue estos sencillos pasos para integrar y desplegar modelos a través de la plataforma de Atlas Cloud.
Crea una cuenta en Atlas Cloud
Regístrate en atlascloud.ai y completa la verificación. Los nuevos usuarios reciben créditos gratuitos para explorar la plataforma y probar modelos.
Por Qué Usar ChatGPT en Atlas Cloud
Combina modelos avanzados de ChatGPT con la plataforma acelerada por GPU de Atlas Cloud, proporcionando rendimiento, escalabilidad y experiencia de desarrollo incomparables.
Rendimiento y Flexibilidad
Baja Latencia:
Inferencia optimizada por GPU para respuestas en tiempo real.
API Unificada:
Una sola integración para acceder a ChatGPT, GPT, Gemini y DeepSeek.
Precios Transparentes:
Facturación por Token, soporta modo Serverless.
Empresa y Escala
Experiencia del Desarrollador:
SDK, análisis de datos, herramientas de ajuste fino y plantillas todo en uno.
Confiabilidad:
99.99% de disponibilidad, control de permisos RBAC, registros de cumplimiento.
Seguridad y Cumplimiento:
Certificación SOC 2 Type II, cumplimiento HIPAA, soberanía de datos en EE.UU.
ChatGPT API: preguntas de desarrolladores respondidas
ChatGPT API permite a los desarrolladores enviar prompts a los modelos GPT de OpenAI y recibir completions de forma programática, en lugar de hacerlo mediante la interfaz de chat. En Atlas Cloud accedes a toda la línea GPT 5.6, junto con GPT 5.4 y GPT 5.5, a través de un único endpoint compatible con OpenAI. Cada llamada se factura por token con precios transparentes de pago por uso, así que solo pagas por lo que generas.
Cinco modelos cubren el espectro que va desde el razonamiento profundo hasta el chat cotidiano. GPT 5.6 Sol está orientado a la resolución de problemas ambiciosos y cargas de trabajo de frontera, GPT 5.6 Terra gestiona flujos de producción fiables, y GPT 5.6 Luna está ajustado para conversaciones naturales y generación de contenido. GPT 5.4 y GPT 5.5 añaden razonamiento multimodal y programación para equipos que buscan un rendimiento generalista probado.
Genera una API key, apunta tu base URL a https://api.atlascloud.ai/v1 y define el ID del modelo, por ejemplo openai/gpt-5.6-terra. Como ChatGPT API aquí es totalmente compatible con OpenAI, el código existente con el OpenAI SDK funciona cambiando solo la base URL y la clave. No hay lista de espera ni suscripción, y las nuevas versiones llegan con acceso Day-0, así que puedes enviar tu primera solicitud el mismo día.
El precio escala según el modelo que elijas. GPT 5.6 Luna es el más económico, con $1 por millón de tokens de entrada y $6 por millón de tokens de salida; GPT 5.6 Terra cuesta $2.5 y $15; y GPT 5.6 Sol se sitúa en $5 y $30. El almacenamiento en caché de prompts reduce el coste de la entrada repetida, y la facturación sigue siendo de pago por uso, así que solo se te cobran los tokens que utilizas.
Sí. El endpoint sigue el formato de OpenAI Chat Completions, por lo que los SDK oficiales de OpenAI, LangChain y la mayoría de las bibliotecas compatibles con OpenAI funcionan en cuanto sustituyes la base URL y la clave. Esto significa que una integración existente con ChatGPT API puede migrarse sin reescribir la lógica de tus solicitudes.
Tanto el streaming como el function calling funcionan igual que en la implementación de OpenAI, así que puedes definir stream como true para obtener salida token a token y pasar un array tools para activar llamadas a funciones. Las respuestas JSON estructuradas siguen el mismo formato de solicitud compatible con OpenAI, lo que mantiene predecibles la orquestación de agentes y los pipelines de extracción de datos.
Estos modelos aceptan prompts grandes para flujos de trabajo con documentos extensos y repositorios completos. El precio se divide en niveles a partir de la marca de 272,000 tokens, con una tarifa estándar para prompts por debajo de ese umbral y una segunda tarifa para prompts que superan los 272,000 tokens. Así puedes proporcionar un contexto amplio en una sola solicitud y saber exactamente cómo cambia la tarifa a medida que crece el prompt.
Elige el modelo según la tarea. Usa GPT 5.6 Sol cuando necesites razonamiento de frontera y resolución de problemas ambiciosos, elige GPT 5.6 Terra para análisis fundamentados y aptos para producción, y usa GPT 5.6 Luna para trabajo conversacional o creativo donde el coste sea lo más importante. GPT 5.4 y GPT 5.5 siguen siendo opciones multimodales sólidas para programación y razonamiento general.
Atlas Cloud ejecuta ChatGPT API sobre infraestructura gestionada que escala con tu tráfico, para que evites el aprovisionamiento de GPU y la orquestación de nodos propios del self-hosting. Las nuevas versiones de modelos llegan con acceso Day-0, manteniéndote al día sin trabajo de migración. Si tus necesidades crecen, la misma clave compatible con OpenAI cubre todos los modelos de la familia, así que escalar nunca implica una integración nueva.
Explorar Más Series
Seedance 2.0
La API de Seedance 2.0 le ofrece acceso de producción al modelo de video multimodal de ByteDance: entradas cuatrimodales (texto, imagen, video, audio) y un sistema "Universal Reference" líder en la industria que bloquea la composición, el movimiento de la cámara y las acciones de los personajes en diferentes tomas. Integre un control de nivel de director con una sola llamada a la API, una tarifa fija de $0.09/s, clave instantánea y sin lista de espera, todo respaldado por un tiempo de actividad y cumplimiento de nivel empresarial. ¡Seedance 2.0 Native 4K ya está disponible!
Grok Imagine
La Grok Imagine API ofrece a los desarrolladores la generación de imágenes, video y audio de xAI en una sola suite. Produce imágenes de hasta 2K con renderizado de texto multilingüe, además de videos de hasta 15 segundos con audio nativo y sincronizado, y edición basada en referencias. En Atlas Cloud, una sola clave ejecuta cada modo de Grok Imagine, por lo que puede alternar entre imagen, video y audio sin configuraciones separadas, desde $0.02 por imagen y $0.05 por segundo.
Gemini Omni Flash
La Gemini Omni API lleva a tu stack el modelo multimodal de generación y edición de vídeo de Google DeepMind, presentado en Google I/O 2026. Gemini Omni fusiona el motor de razonamiento de Gemini con los medios generativos y acepta cualquier combinación de texto, imágenes, vídeo y audio para producir resultados coherentes y fundamentados en conocimiento. Refina los resultados mediante conversación natural: sustituye objetos, reescribe escenas y cambia de estilo mientras la física, los personajes y la continuidad permanecen intactos. Atlas Cloud ofrece toda la gama Gemini Omni Flash —texto a vídeo, imagen a vídeo con hasta 7 imágenes de referencia y referencia a vídeo— a través de una única API unificada, con precios transparentes por segundo desde $0.112 y sin suscripción. Empieza a construir hoy mismo.
GPT Image 2
La API de GPT Image 2 ofrece a los desarrolladores acceso al último modelo de imágenes de OpenAI, el sucesor de GPT Image 1.5. Genera y edita imágenes con una representación de texto precisa en caracteres latinos y CJK, además de una sólida composición para carteles, maquetas e infografías. En Atlas Cloud, puede acceder a ella a través de una API unificada junto con más de 300 modelos, con créditos gratuitos, un tiempo de actividad del 99,99% y sin necesidad de verificación de organización de OpenAI.
Los modelos creativos más potentes de Google están todos disponibles en Atlas Cloud. Veo 3.1 ofrece generación de video cinematográfico, Nano Banana 2 impulsa la creación de imágenes de alta fidelidad y Gemini aporta inteligencia multimodal a cada flujo de trabajo. Acceda a la suite completa de modelos de Google a través de una sola API key con disponibilidad Day-0 y precios de pago por uso (pay-as-you-go).
Seedance 2.0 Mini
Seedance 2.0 Mini lleva la generación de video multimodal de ByteDance a los flujos de trabajo donde la velocidad y el costo son más importantes. Ofrece las capacidades principales de Seedance 2.0 con un menor consumo de recursos: generación más rápida, menor costo por video y la misma integración de API que ya utiliza. Para los equipos que ejecutan pipelines de alto volumen o crean prototipos a escala, Mini es la opción predeterminada práctica.
ByteDance
Desde la generación de video cinematográfico hasta la creación de imágenes de alta fidelidad, los modelos más potentes de ByteDance están disponibles en Atlas Cloud. Ejecute Seedance y Seedream a gran escala con los precios de inferencia más bajos y cero gastos generales de infraestructura.
Alibaba
Atlas Cloud reúne toda la línea de modelos de Alibaba bajo una sola API: Qwen para tareas de lenguaje e imagen, y Wan para la generación de video hasta 1080p. Acceda a cada modelo con pago por uso sin suscripciones. La API de Alibaba está disponible a través de una única URL base utilizando su cliente compatible con OpenAI existente.
OpenAI
Atlas Cloud le ofrece acceso a la línea completa de la API de OpenAI, desde GPT Image 2 para la generación de imágenes hasta Sora 2 para video. Cada modelo está disponible bajo la modalidad de pago por uso sin compromiso mensual. Intégrelo cambiando simplemente la URL base mediante la API compatible con OpenAI.
xAI
Construya pipelines completos de imágenes y video utilizando la xAI API en Atlas Cloud. Genere en 2K, edite con imágenes de referencia y anime imágenes en clips sincronizados con audio.
Kwaivgi
La API de Kwaivgi a un 15% por debajo del precio estándar. Atlas Cloud ofrece acceso Day-0 a los nuevos lanzamientos de Kling con precios de pago por uso y sin límites de puestos. Una cuenta, una clave, todos los modelos de Kling desde el nivel estándar hasta el nivel maestro.
Seedream 5.0 Pro
La API de Seedream 5.0 Pro ofrece a los desarrolladores el modelo de edición de imágenes controlable de ByteDance en Atlas Cloud. Sitúa las ediciones con precisión mediante anclajes y coordenadas, separa las imágenes en capas editables, fusiona múltiples referencias y empareja colores y materiales exactos, con texto multilingüe a 2K y 3K. ¡En Atlas Cloud puede acceder a él mediante una sola clave!


