Gemini Omni Flash API for Conversational Video Editing
La Gemini Omni API lleva a tu stack el modelo multimodal de generación y edición de vídeo de Google DeepMind, presentado en Google I/O 2026. Gemini Omni fusiona el motor de razonamiento de Gemini con los medios generativos y acepta cualquier combinación de texto, imágenes, vídeo y audio para producir resultados coherentes y fundamentados en conocimiento. Refina los resultados mediante conversación natural: sustituye objetos, reescribe escenas y cambia de estilo mientras la física, los personajes y la continuidad permanecen intactos. Atlas Cloud ofrece toda la gama Gemini Omni Flash —texto a vídeo, imagen a vídeo con hasta 7 imágenes de referencia y referencia a vídeo— a través de una única API unificada, con precios transparentes por segundo desde $0.112 y sin suscripción. Empieza a construir hoy mismo.
Explorar Modelos Líderes
Atlas Cloud le proporciona los últimos modelos creativos líderes en la industria.







Cuatro formas de generar con Gemini Omni Flash API
Elija el endpoint de la API de Gemini Omni Flash que se adapte al trabajo, desde texto a video e imagen a video, hasta la generación basada en referencias y la edición conversacional.
| Modalidad | |
|---|---|
| Gemini Omni Flash Text-to-Video API (T2V) | ¿Solo tiene un prompt de texto? La API Gemini Omni Flash Text-to-Video lo transforma en un clip de 720p con audio sincronizado en un solo paso, siguiendo una dirección impulsada por el razonamiento sobre la escena, el movimiento y la cámara para clips de hasta 10 segundos. |
| Gemini Omni Flash Image-to-Video API (I2V) | La API Image-to-Video de Gemini Omni Flash anima una imagen estática dándole movimiento, fijando la fuente original como el fotograma inicial. Con movimientos naturales y audio sincronizado, da vida a fotografías de productos, retratos y conceptos a una resolución de 720p. |
| Gemini Omni Flash Reference-to-Video API (R2V) | Guíe una generación con hasta siete imágenes de referencia y tres clips de video cortos utilizando la Gemini Omni Flash Reference-to-Video API. Mantiene la coherencia de los personajes, el estilo y la escena en todo el clip, ideal para contenido de marca y de series. |
| Gemini Omni Flash Video Edit API | Cuando un clip necesita cambios, la Gemini Omni Flash Video Edit API aplica instrucciones en lenguaje natural a través de una Interactions API con estado. Intercambia elementos, ajusta la iluminación y cambia el estilo de las escenas, mientras mantiene intacto el resto del metraje a lo largo de los turnos de interacción. |
Build Video by Conversation with the Gemini Omni Flash API
Every Gemini Omni Flash API request can take any mix of text, image, video, and audio, generate synchronized sound, model real-world physics, and refine the result through conversation.

Conversational Editing
Refine a clip through natural language and the Gemini Omni Flash API applies the change while preserving the rest of the scene. Its stateful Interactions API remembers each turn, so edits build on one another.

Native Multimodal Input
The Gemini Omni Flash API accepts any mix of text, image, video, and audio in a single prompt. This anything-from-anything input lets you drive a generation from whatever source material you already have.

Synchronized Audio in One Pass
Sound is generated with the picture in one inference pass, so dialogue, effects, and ambience stay locked to the action. The Gemini Omni Flash API needs no separate audio step afterward.

World Modeling
Grounded in a model of real-world physics, the Gemini Omni Flash API renders believable reflections, gravity, lighting, and weather. Scenes hold together visually instead of drifting into artifacts, even in dynamic shots.
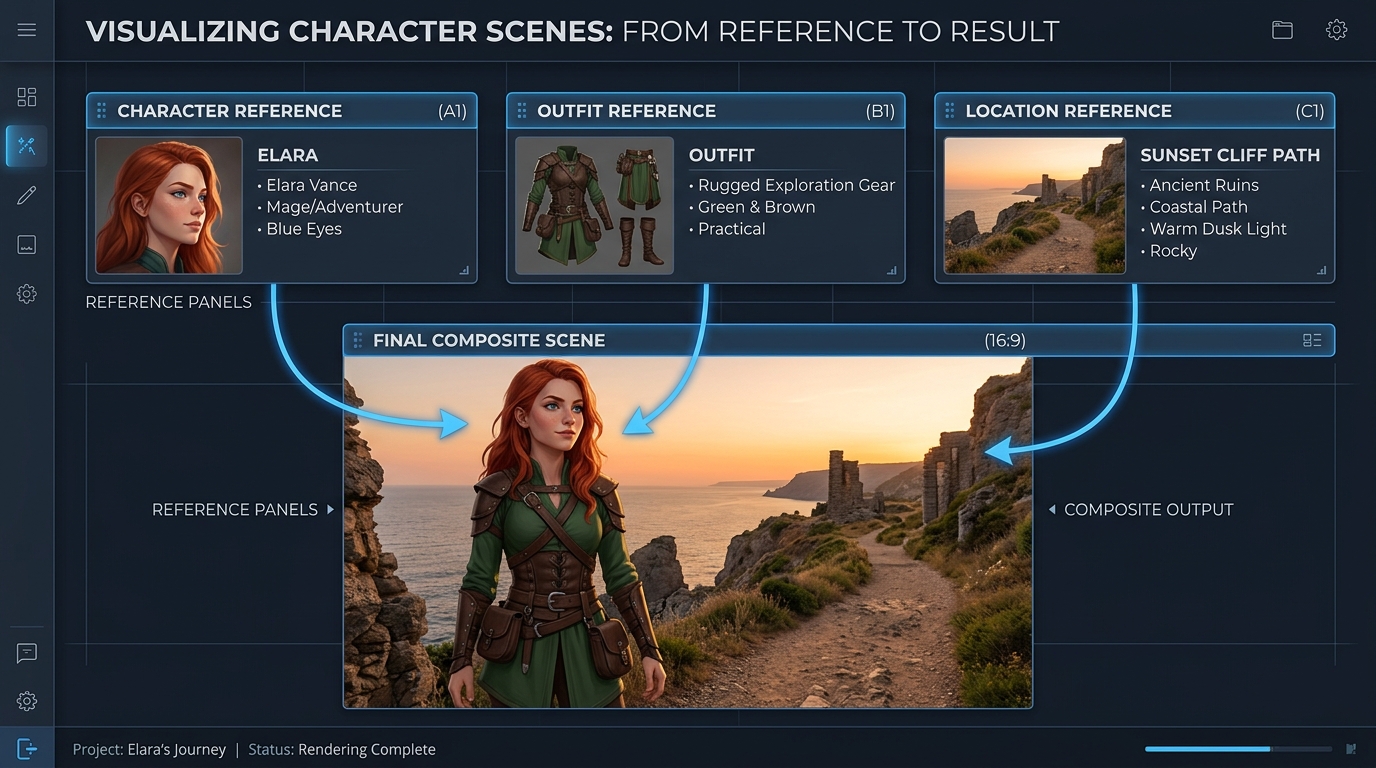
Multimodal Referencing
Guide a generation with up to seven reference images and three short video clips, and the Gemini Omni Flash API keeps subjects, style, and scene consistent. This holds identity steady across edits and shots.
Gemini Omni vs Other Models - One Prompt
The same prompt, generated by Gemini Omni and other leading video models: Multi-shot and high-end commercial film
Generate a 3-scene continuous video: Scene 1: The woman stands under neon lights in a rainy street in Tokyo. Reflections on wet ground, cinematic depth of field, handheld camera movement. Scene 2: The camera slowly transitions to a closer shot. She speaks softly in sync with the provided voice, her lip movements perfectly matched. Background traffic continues seamlessly. Scene 3: She enters a subway station. The environment remains consistent in lighting, weather, and mood. The camera follows her from behind, maintaining identity consistency. Constraints: - Maintain identical facial identity across all scenes - Preserve lighting continuity (rain, neon reflections) - Ensure physical realism (rain interaction, wet surfaces) - Ensure audio-visual synchronization with voice input - No scene reset between transitions; continuous world state Style: high-end cinematic realism, film grain, anamorphic lens, shallow depth of field, 4K film look
Gemini Omni
Wan 2.7
Kling v3.0
Generate a 4-scene continuous video: Scene 1: A small white robot sits motionless on a wooden desk in a dim apartment at midnight. Moonlight enters through the window. The robot’s eyes slowly light up, and a faint mechanical hum begins. Scene 2: The robot climbs down from the desk carefully. Its small metal feet make soft clicking sounds on the wooden floor. The camera follows at a low angle, keeping the robot’s size and shape consistent. Scene 3: The robot walks into the kitchen. Reflections from the refrigerator door and the tiled floor respond naturally to its movement. The same moonlight and quiet nighttime atmosphere continue from the previous scene. Scene 4: The robot stops near a window and looks outside at the city lights. The camera slowly pushes in from behind, preserving the robot’s identity, material, scale, lighting, and sound continuity. Requirements: - Maintain the exact same robot design across all scenes - Preserve one continuous apartment layout, with no scene reset - Keep lighting consistent from room to room - Match footsteps and mechanical humming to the robot’s motion - Use physically realistic reflections, shadows, and object interactions - Smooth transitions between scenes, as if one continuous world is being filmed Style: cinematic realism, quiet sci-fi atmosphere, soft moonlight, detailed materials, realistic camera movement, shallow depth of field, high-end commercial film look
Gemini Omni
Kling V3.0
Pixverse v6
Where Teams Use the Gemini Omni Flash API
Production and marketing teams reach for the Gemini Omni Flash API to make ads, edit finished clips by conversation, produce social and training video, animate product shots, and power generative media apps.
Advertising & Marketing Video
The Gemini Omni Flash API turns a product image or brand visual into a finished ad with motion and synchronized audio. Marketing teams ship social campaigns and branded stories without a production crew.
Conversational Video Post-Production
Feed in a finished clip and refine it by conversation, adding B-roll, swapping elements, or restyling scenes without regenerating. The Gemini Omni Flash API keeps the rest of the footage intact across every edit.
Social & Short-Form Content
When social teams need volume, the Gemini Omni Flash API pulls the strongest short segments from raw footage and adds transitions and styled end cards. It keeps a daily cadence without switching tools.
Educational & Explainer Video
Learning platforms use the Gemini Omni Flash API to turn abstract ideas into short animated lessons with narration. A workflow, a science concept, or a comparison becomes a clear visual explainer in minutes.
E-Commerce & Product Video
The Gemini Omni Flash API animates a single product photo into a lifestyle teaser or hero shot, and can swap garments or backgrounds. Online stores build consistent product video across a full catalog.
Generative Media Apps
Build video generation and conversational editing into your own product with the Gemini Omni Flash API through one integration. Creator tools and media apps ship an in-app editor without running a pipeline.
Cómo se compara la API Gemini Omni Flash
Vea cómo se comparan los modelos de diferentes proveedores — compare rendimiento, precios y fortalezas únicas para tomar una decisión informada.
| Model | Best for | Native audio | Conversational editing | Input types |
|---|---|---|---|---|
| Gemini Omni Flash | Edición de video terminado mediante conversación | Yes | Sí, con estado | Texto, imagen, vídeo, audio |
| Veo 3.1 | Clips cinematográficos con extensión de escena | Yes | No | Texto, imagen, referencia |
| Seedance 2.0 | Vídeo controlado por referencia de calidad superior | Yes | No | Texto, imagen, vídeo, audio |
| Kling 3.0 | Narrativa de múltiples tomas dirigida por IA | Yes | No | Texto, imagen, referencia |
Cómo usar Gemini Omni Flash en Atlas Cloud
Empieza en minutos — sigue estos sencillos pasos para integrar y desplegar modelos a través de la plataforma de Atlas Cloud.
Crea una cuenta en Atlas Cloud
Regístrate en atlascloud.ai y completa la verificación. Los nuevos usuarios reciben créditos gratuitos para explorar la plataforma y probar modelos.
Por Qué Usar Gemini Omni Flash en Atlas Cloud
Combina modelos avanzados de Gemini Omni Flash con la plataforma acelerada por GPU de Atlas Cloud, proporcionando rendimiento, escalabilidad y experiencia de desarrollo incomparables.
Rendimiento y Flexibilidad
Baja Latencia:
Inferencia optimizada por GPU para respuestas en tiempo real.
API Unificada:
Una sola integración para acceder a Gemini Omni Flash, GPT, Gemini y DeepSeek.
Precios Transparentes:
Facturación por Token, soporta modo Serverless.
Empresa y Escala
Experiencia del Desarrollador:
SDK, análisis de datos, herramientas de ajuste fino y plantillas todo en uno.
Confiabilidad:
99.99% de disponibilidad, control de permisos RBAC, registros de cumplimiento.
Seguridad y Cumplimiento:
Certificación SOC 2 Type II, cumplimiento HIPAA, soberanía de datos en EE.UU.
Preguntas frecuentes sobre Google Gemini Omni Flash API
The Gemini Omni Flash API gives developers Google DeepMind's video generation and editing model on Atlas Cloud through one key. It creates video from text, image, video, or audio, produces synchronized audio in a single pass, and lets you refine results through conversation. It entered public preview in mid-2026.
The Gemini Omni Flash API accepts any combination of text, image, video, and audio in a single prompt. For consistency, it takes up to seven reference images and up to three short video clips to guide a generation.
Yes. The Gemini Omni Flash API supports conversational editing through a stateful Interactions API, so you can describe a change in natural language and it applies the edit while keeping the rest of the clip intact. Edits build on one another across turns.
Gemini Omni Flash API outputs 720p video in landscape or portrait, with clips currently up to 10 seconds. The 10-second cap is a launch-time deployment limit rather than a hard model limit.
Yes. The Gemini Omni Flash API generates video and audio together in a single inference pass, so dialogue, effects, and ambience stay aligned to the action. There is no separate audio step to run afterward.
On Atlas Cloud the Gemini Omni Flash API is billed per second of video, starting at $0.112 per second, with lower developer-tier rates available. Pricing is transparent and usage-based, so you only pay for the video you generate.
No. Going to Google directly routes Gemini Omni Flash through the Gemini API or Vertex AI, which involves a Google Cloud project. With the Gemini Omni Flash API on Atlas Cloud you only need an Atlas Cloud account and one key.
Yes. All Gemini Omni Flash output carries Google's SynthID watermark, an embedded marker that identifies content as AI-generated, and it cannot be disabled. The watermark does not affect visible quality or your ability to use the video commercially.
Yes. Atlas Cloud exposes an OpenAI-compatible API, so you can point the OpenAI SDK at the Atlas Cloud base URL, add your Atlas key, and call the Gemini Omni Flash API with your existing code. You can make your first request in minutes without a new integration.
Explorar Más Series
Seedance 2.0
La API de Seedance 2.0 le ofrece acceso de producción al modelo de video multimodal de ByteDance: entradas cuatrimodales (texto, imagen, video, audio) y un sistema "Universal Reference" líder en la industria que bloquea la composición, el movimiento de la cámara y las acciones de los personajes en diferentes tomas. Integre un control de nivel de director con una sola llamada a la API, una tarifa fija de $0.09/s, clave instantánea y sin lista de espera, todo respaldado por un tiempo de actividad y cumplimiento de nivel empresarial. ¡Seedance 2.0 Native 4K ya está disponible!
Grok Imagine
La Grok Imagine API ofrece a los desarrolladores la generación de imágenes, video y audio de xAI en una sola suite. Produce imágenes de hasta 2K con renderizado de texto multilingüe, además de videos de hasta 15 segundos con audio nativo y sincronizado, y edición basada en referencias. En Atlas Cloud, una sola clave ejecuta cada modo de Grok Imagine, por lo que puede alternar entre imagen, video y audio sin configuraciones separadas, desde $0.02 por imagen y $0.05 por segundo.
Gemini Omni Flash
La Gemini Omni API lleva a tu stack el modelo multimodal de generación y edición de vídeo de Google DeepMind, presentado en Google I/O 2026. Gemini Omni fusiona el motor de razonamiento de Gemini con los medios generativos y acepta cualquier combinación de texto, imágenes, vídeo y audio para producir resultados coherentes y fundamentados en conocimiento. Refina los resultados mediante conversación natural: sustituye objetos, reescribe escenas y cambia de estilo mientras la física, los personajes y la continuidad permanecen intactos. Atlas Cloud ofrece toda la gama Gemini Omni Flash —texto a vídeo, imagen a vídeo con hasta 7 imágenes de referencia y referencia a vídeo— a través de una única API unificada, con precios transparentes por segundo desde $0.112 y sin suscripción. Empieza a construir hoy mismo.
GPT Image 2
La API de GPT Image 2 ofrece a los desarrolladores acceso al último modelo de imágenes de OpenAI, el sucesor de GPT Image 1.5. Genera y edita imágenes con una representación de texto precisa en caracteres latinos y CJK, además de una sólida composición para carteles, maquetas e infografías. En Atlas Cloud, puede acceder a ella a través de una API unificada junto con más de 300 modelos, con créditos gratuitos, un tiempo de actividad del 99,99% y sin necesidad de verificación de organización de OpenAI.
Los modelos creativos más potentes de Google están todos disponibles en Atlas Cloud. Veo 3.1 ofrece generación de video cinematográfico, Nano Banana 2 impulsa la creación de imágenes de alta fidelidad y Gemini aporta inteligencia multimodal a cada flujo de trabajo. Acceda a la suite completa de modelos de Google a través de una sola API key con disponibilidad Day-0 y precios de pago por uso (pay-as-you-go).
Seedance 2.0 Mini
Seedance 2.0 Mini lleva la generación de video multimodal de ByteDance a los flujos de trabajo donde la velocidad y el costo son más importantes. Ofrece las capacidades principales de Seedance 2.0 con un menor consumo de recursos: generación más rápida, menor costo por video y la misma integración de API que ya utiliza. Para los equipos que ejecutan pipelines de alto volumen o crean prototipos a escala, Mini es la opción predeterminada práctica.
ByteDance
Desde la generación de video cinematográfico hasta la creación de imágenes de alta fidelidad, los modelos más potentes de ByteDance están disponibles en Atlas Cloud. Ejecute Seedance y Seedream a gran escala con los precios de inferencia más bajos y cero gastos generales de infraestructura.
Alibaba
Atlas Cloud reúne toda la línea de modelos de Alibaba bajo una sola API: Qwen para tareas de lenguaje e imagen, y Wan para la generación de video hasta 1080p. Acceda a cada modelo con pago por uso sin suscripciones. La API de Alibaba está disponible a través de una única URL base utilizando su cliente compatible con OpenAI existente.
OpenAI
Atlas Cloud le ofrece acceso a la línea completa de la API de OpenAI, desde GPT Image 2 para la generación de imágenes hasta Sora 2 para video. Cada modelo está disponible bajo la modalidad de pago por uso sin compromiso mensual. Intégrelo cambiando simplemente la URL base mediante la API compatible con OpenAI.
xAI
Construya pipelines completos de imágenes y video utilizando la xAI API en Atlas Cloud. Genere en 2K, edite con imágenes de referencia y anime imágenes en clips sincronizados con audio.
Kwaivgi
La API de Kwaivgi a un 15% por debajo del precio estándar. Atlas Cloud ofrece acceso Day-0 a los nuevos lanzamientos de Kling con precios de pago por uso y sin límites de puestos. Una cuenta, una clave, todos los modelos de Kling desde el nivel estándar hasta el nivel maestro.
Seedream 5.0 Pro
La API de Seedream 5.0 Pro ofrece a los desarrolladores el modelo de edición de imágenes controlable de ByteDance en Atlas Cloud. Sitúa las ediciones con precisión mediante anclajes y coordenadas, separa las imágenes en capas editables, fusiona múltiples referencias y empareja colores y materiales exactos, con texto multilingüe a 2K y 3K. ¡En Atlas Cloud puede acceder a él mediante una sola clave!


