
Vous connaissez ce sentiment.
Il est tard. Vous en êtes à votre quatrième révision d'une campagne de marque. L'IA vient de générer un éclairage parfait sur le plan principal, mais le visage de votre modèle a subtilement changé pour la troisième fois ce soir. Même tenue. Personne différente. Impossible de livrer ça. Impossible de corriger. Vous recommencez tout.
À minuit, vous ne faites plus du montage vidéo. Vous jouez à la roulette russe.
Pour quiconque tente de construire une continuité narrative — une démo produit avec le même mannequin d'un plan à l'autre, un tutoriel avec le même professeur sur plusieurs scènes, un clip musical avec le même chanteur à travers les coupes — la dérive des personnages (character drift) a été le tueur silencieux de tous les outils vidéo par IA. C'est pourquoi la vidéo par IA est restée dans le purgatoire des « démos sympas » au lieu de devenir une solution commerciale.

Le 19 mai, lors de la conférence I/O 2026, Gemini Omni de Google a démontré que cette époque touche à sa fin.
Toute la promesse se résume à une ligne sur la page produit de Google DeepMind : « Chaque modification que vous apportez s'appuie sur la précédente, maintenant une scène cohérente et constante. »
La démo du violoniste en trois étapes qui est entrée dans l'histoire
Le moment le plus important de l'annonce lors de l'I/O n'était pas la bille qui roule, ni la sculpture de bulles. C'était un violoniste.
Voici la séquence exacte montrée par Google sur scène et publiée sur son blog :
- Étape 1 : Une vidéo de base d'un violoniste jouant un morceau sur scène.
- Étape 2 : Prompt — « Transporter le violoniste dans l'environnement de l'image. » Résultat : le joueur est déplacé dans un nouveau décor, mais le visage, la posture, la tenue de l'archet et même l'angle du poignet restent identiques.
- Étape 3 : Un autre prompt — « Changer l'angle de caméra pour qu'il soit au-dessus de l'épaule du violoniste. » Résultat : nouveau cadrage. Même violoniste. Même identité. Même performance.
Trois tours. Un seul sujet. Zéro dérive.
Si vous avez passé un peu de temps avec les outils vidéo IA actuels, cela ressemble à de la triche. Ce n'est pas le cas. C'est la première preuve publique que le raffinage multi-tours — le flux de travail attendu par les cinéastes, les publicitaires et les enseignants — est techniquement réel et prêt à être déployé.
Pourquoi la cohérence multi-tours est le talon d'Achille de la vidéo par IA
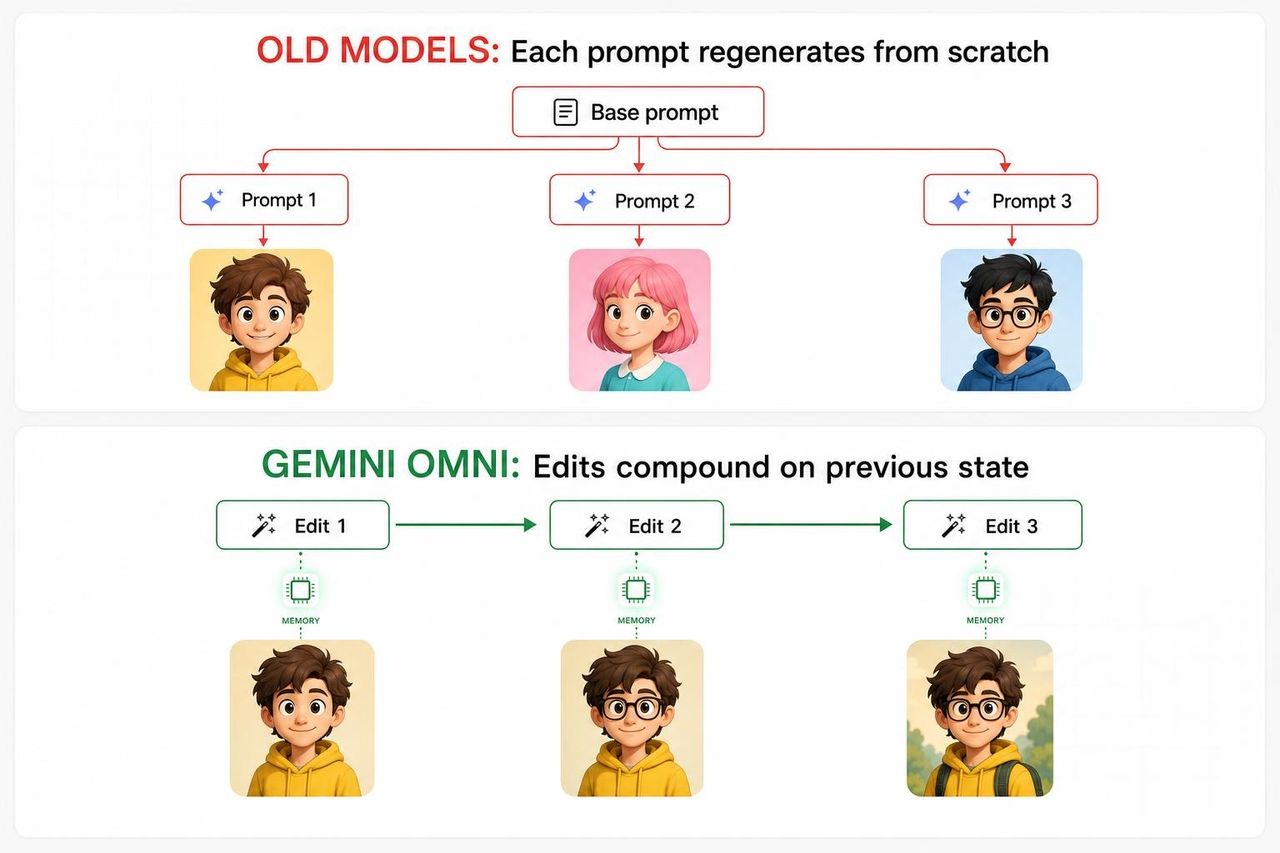
Pour comprendre pourquoi la démo du violoniste est importante, il faut comprendre ce qui fait échouer tous les autres modèles vidéo par IA.
Dans les pipelines de vidéo générative traditionnels, chaque nouveau prompt régénère essentiellement la scène à partir de zéro, en utilisant le prompt original combiné au nouveau comme entrées. Le modèle n'a pas de réelle continuité interne entre les tours. Les visages dérivent. Les accessoires de fond disparaissent. L'éclairage change. Au troisième tour, le résultat s'est tellement éloigné de la vision originale que les créateurs abandonnent et recommencent.
La cause profonde est architecturale. La plupart des modèles vidéo ont été entraînés comme des générateurs « one-shot », et non comme des agents multi-tours. Ils étaient optimisés pour produire un résultat unique à partir d'un prompt, et non pour se souvenir de ce qu'ils ont produit précédemment. Demander de « modifier » revenait à demander de recommencer avec un contexte supplémentaire, et le calcul de cette opération produisait une dérive cumulée, plutôt qu'un raffinage cumulé.
L'approche d'Omni est différente. Il a été conçu comme un éditeur à état (stateful editor) : chaque tour met à jour une représentation persistante de la scène plutôt que de la régénérer de toutes pièces.
Ce que signifie réellement « La scène se souvient »
La presse technologique anglophone en est arrivée à la même conclusion.
Decrypt a décrit la percée le plus simplement : « Google affirme qu'Omni peut conserver la cohérence des personnages, des arrière-plans et des mouvements même après que les utilisateurs ont modifié une vidéo — ce avec quoi de nombreux modèles de vidéo par IA ont du mal. »
Android Central a relevé le détail technique clé : « L'entreprise indique également que le modèle se souvient des commandes précédentes lors des révisions multi-étapes, ce qui pourrait rendre le montage itératif beaucoup moins chaotique. »
TechRadar a présenté cela de manière cinématographique : « Les personnages restent reconnaissables. Les scènes conservent leur continuité. Le mouvement reste cohérent au lieu de se réinitialiser à chaque changement de prompt. »
Et Phandroid a résumé toute la capacité en une phrase : « La scène se souvient de ce qui a précédé. »
C'est là tout l'enjeu. La scène se souvient. Cette simple propriété est la différence entre la vidéo par IA comme jouet et comme véritable outil.
Comment Omni se positionne face à Sora, Veo et Seedance sur la cohérence
Voici la comparaison des principaux modèles vidéo par IA sur la cohérence multi-tours en mai 2026 :
| Modèle | Édition multi-tours | Raffinage conversationnel | Cohérence des personnages | Statut actuel |
| Gemini Omni Flash | À état (stateful), multi-tours | Chat natif | (3/5) | Disponible depuis le 19 mai 2026 |
| Sora 2 (OpenAI) | Régénération "one-shot" | Limité | Discontinué | App fermée ; API fermée en sept. 2026 |
| Veo 3.1 (Google) | Partiel | Texte + image seulement | Inférieur à Omni | Disponible, remplacé par Omni |
| Seedance 2.0 (ByteDance) | Basé sur références, pas itératif | Limité | (4/5) | Disponible ; n°1 sur l'Artificial Analysis Video Arena |
Lecture honnête : Omni est le seul modèle doté d'une édition multi-tours véritablement à état. Seedance obtient un meilleur score sur la cohérence brute des personnages en utilisant jusqu'à 9 images de référence par génération, mais ne peut pas maintenir cette cohérence au cours d'une session de montage. Sora quitte le marché grand public. Veo est en train d'être absorbé.
De « relancer » à « raffiner » — Ce que ce changement de flux débloque

La vraie valeur ici n'est pas la démo, c'est la transformation du flux de travail.
Blockchain.news a parfaitement résumé l'implication commerciale : « Le montage par lots permet des modifications simultanées sur plusieurs segments vidéo pour accélérer la production tout en maintenant des normes de qualité dans le contenu généré par IA. Les créateurs de films, de publicité et de contenu pédagogique bénéficient d'avantages significatifs grâce à la réduction des coûts et à une fiabilité narrative accrue. »
Cette dernière expression — fiabilité narrative — est ce qui devrait compter pour quiconque travaille dans le contenu.
Jusqu'à présent, la vidéo par IA pouvait fournir un bon clip. Elle ne pouvait pas livrer une campagne : une série de clips avec le même protagoniste, les mêmes éléments de marque et le même langage visuel sur plusieurs livrables. Chaque édition était un coup de poker. Désormais, les modifications se cumulent.
TechTimes a résumé l'ensemble des capacités démontrées publiquement comme « l'édition d'actions et d'objets dans des séquences filmées par l'utilisateur, le transfert de style entre des aspects réalistes et animés, le raffinage multi-tours et la génération de vidéos explicatives. »
Et l'avis de DataCamp a confirmé que le comportement multi-tours tient la route : « Omni prend en charge l'édition multi-tours, vous permettant d'affiner les détails, les environnements et les angles de caméra étape par étape tout en gardant la scène cohérente. »
Le changement de workflow semble minime sur le papier. En pratique, il est énorme : générer → régénérer → régénérer → abandonner devient générer → raffiner → raffiner → livrer.
Les développeurs le remarquent. Sur le forum chinois V2EX, un ingénieur ayant testé Omni le jour du lancement a écrit : « La vitesse de génération et la cohérence ont dépassé mes attentes. »
Lorsque des ingénieurs IA et des créateurs de terrain arrivent au même constat quelques heures après le lancement, nous sommes face à un véritable saut technologique.
Le scepticisme honnête — Omni n'est pas encore parfait
Avant de déclarer le problème de la cohérence résolu, une mise en garde.
Un critique chez AI Analytics Diaries sur Medium a comparé Omni à Seedance 2.0 de ByteDance et a attribué à la cohérence des personnages d'Omni une note de 3 sur 5.
La phrase à épingler sur le moniteur de tout chef de produit vidéo IA : « Les deux modèles ont du mal avec la cohérence des personnages à travers plusieurs coupes — cela reste la plaie ouverte de la vidéo par IA. »
Traduction : Omni est nettement meilleur que tout autre modèle public pour le raffinage multi-tours au sein d'une seule session de montage. Le problème n'est pas encore résolu à l'échelle de la catégorie.
Où se situe l'écart restant ?
- La cohérence multi-tours à scène unique fonctionne extrêmement bien (démo du violoniste).
- La cohérence inter-coupes (même personnage, scènes différentes, éclairages différents, cadrages différents) est encore imparfaite.
- Les caractéristiques subtiles — détails du visage, articulation des mains, textures spécifiques des vêtements — peuvent encore dériver après de nombreuses éditions.
- La limite actuelle de 10 secondes sur Omni Flash signifie que la cohérence multi-tours n'a pas encore été testée rigoureusement dans des travaux narratifs longs.
Pour 80 % des cas d'utilisation — raffinage de scène unique, contenu pour réseaux sociaux, supports marketing — Omni est déjà assez performant pour être déployé. Pour les 20 % restants — le travail cinématographique où la continuité du personnage doit survivre à une séquence de 30 plans — une étape de nettoyage éditorial est encore nécessaire.
Ce que cela change concrètement — Industrie par industrie
Si la cohérence multi-tours est désormais résolue (ou presque, au sein d'une même session), voici ce qui se débloque :
Pour les annonceurs : Continuité de campagne. Une marque de mode peut enfin générer dix variantes du même mannequin héroïne dans dix décors différents, sans re-shooting, sans trouver de nouveaux talents, sans payer dix retouches manuelles. Les calculs de production créative sur les réseaux sociaux changent d'ordre de grandeur.
Pour les créateurs de tutoriels et enseignants : Cohérence des séries. Un présentateur généré par IA peut animer un cours entier — de l'épisode 1 à 12 — sans que l'audience ne remarque qu'il est synthétique. Le problème du « visage cohérent » avait tué les éducateurs IA. C'est désormais corrigé.
Pour les cinéastes : Prévisualisation à grande échelle. Le même acteur sur plusieurs propositions de scènes, éclairages et angles de caméra — le tout généré dans une seule session, raffinable de manière itérative. L'écart entre « j'ai une idée » et « je peux montrer le concept au réalisateur » passe de plusieurs jours à quelques minutes.
Pour les équipes e-commerce : Des plans produits qui correspondent à travers les variantes. Même mannequin, six tenues, plans lifestyle, plans studio, plans en environnement — tout est cohérent, livrable et généré depuis la même session multi-tours.
Pour les développeurs de jeux : Des PNJ qui ressemblent au même personnage à travers les cinématiques. Le talon d'Achille des cinématiques IA en jeu était que le protagoniste se transformait subtilement. L'édition à état d'Omni rend le verrouillage des personnages commercialement viable.
La tension sur la provenance — Les faux cohérents plus difficiles à détecter
Il y a une implication plus sombre à cette avancée.
Une meilleure cohérence multi-tours signifie des faux plus difficiles à détecter. Les signes classiques qui trahissaient une vidéo générée par IA — un visage qui se déforme au montage, des mains changeant de forme, des cheveux qui changent de couleur — sont précisément ce que la cohérence corrige. À mesure qu'Omni et ses successeurs s'améliorent, l'écart entre « évidemment synthétique » et « indiscernable du réel » se réduit rapidement.
C'est précisément pourquoi chaque clip généré par Omni est accompagné du watermark invisible SynthID de Google et des Content Credentials C2PA intégrés au moment de la génération. Vérifiables dans l'application Gemini, Chrome et la Recherche. Ce n'est pas optionnel. Ce n'est pas une fonctionnalité désactivable.
C'est aussi pourquoi Google a délibérément retenu l'édition de la parole et de l'audio dans les vidéos existantes : « Nous travaillons encore à tester cela et à mieux comprendre comment nous pouvons apporter cette capacité aux utilisateurs de manière responsable. » Traduction : le risque de deepfake d'un visage cohérent + une voix modifiée est trop élevé pour être déployé sans garanties.
Pour les marques et les créateurs, le calcul change. Comme la détection humaine des contenus « faux » devient peu fiable, la provenance cryptographique devient la nouvelle norme d'authenticité. Chaque gain en cohérence s'accompagne d'une obligation de provenance.
Le nouveau goulot d'étranglement n'est pas la qualité, mais la prolifération des modèles
Voici ce que cela signifie stratégiquement pour quiconque construit des produits sur la vidéo IA.
L'écart de capacité entre les modèles leaders se réduit rapidement, tout en se fragmentant tout aussi vite. À la mi-2026 :
- Gemini Omni mène sur la cohérence multi-tours et l'édition conversationnelle.
- Seedance 2.0 mène sur le mouvement cinématographique et l'animation stylisée, avec une cohérence de personnage basée sur des références plus forte.
- D'autres spécialistes mènent sur la génération longue, le contrôle fin des personnages, la synchronisation audio ou le traitement par lots à faible coût.
Le modèle le plus cohérent ce trimestre n'est probablement pas celui qui sera le meilleur en mouvement cinématographique le trimestre prochain. Le modèle avec la meilleure physique aujourd'hui ne sera pas forcément celui avec la meilleure synchro audio dans six mois. Et chacun d'eux est livré avec son propre SDK, flux d'authentification, tarification, limites de débit et conditions contractuelles. Votre équipe peut facilement brûler un sprint d'ingénierie par intégration — et un autre par dépréciation.
C'est exactement le problème de fragmentation qu'Atlas Cloud a été conçu pour résoudre. Nous offrons aux développeurs un point de terminaison unifié pour accéder à plus de 300 modèles : chaque modèle de fondation majeur, les sorties open-source leaders et les spécialistes agiles en image, vidéo, audio et raisonnement. L'accès à Gemini Omni arrive sur Atlas Cloud dans les prochaines semaines, donc dès que vous serez prêt à changer votre stack pour le tester, l'intégration sera déjà faite pour vous.
En pratique pour votre équipe :
- Changez de modèle avec une seule ligne de code — fini de réécrire les intégrations SDK à chaque nouvelle avancée.
- Effectuez des évaluations comparatives sur des prompts identiques — découvrez quel modèle gagne réellement pour votre cas d'utilisation avant d'engager votre budget.
- Déployez le meilleur modèle pour chaque capacité — le leader de la cohérence multi-tours aujourd'hui, le leader du mouvement cinématographique demain, le leader de l'efficacité des coûts le trimestre prochain.
- Un tableau de bord unique pour la facturation, l'observabilité et les limites — au lieu de douze comptes séparés à gérer.
Pour les constructeurs de produits vidéo IA en 2026, l'appel architectural intelligent n'est pas de « miser sur Omni ». C'est de « construire sur une couche d'abstraction qui vous permet de basculer vers celui qui gagne ». Lorsque Gemini Omni arrivera sur Atlas Cloud, vous pourrez le tester face à Seedance, face au prochain modèle révolutionnaire, face à tout ce qui suivra — sans changer une seule ligne de code d'intégration.
Sur un marché où la cohérence, la physique, le mouvement cinématographique et la fidélité audio sont menés par des modèles différents, s'enfermer dans l'un d'eux est la pire dette technique possible. Atlas Cloud est la couche d'abstraction qui transforme cette fragmentation en un avantage concurrentiel.
Une API unifiée pour la génération vidéo de production
Alors que Google déploie Gemini Omni Flash dans l'application Gemini et Google Flow pour les utilisateurs finaux, les développeurs et les équipes produit qui souhaitent intégrer le même moteur vidéo multimodal dans leurs propres flux de travail ont besoin d'une couche API stable et prévisible.
Atlas Cloud sert Gemini Omni Flash via une API unifiée compatible avec OpenAI, aux côtés de plus de 300 autres modèles d'image, vidéo et LLM — vous pouvez donc intégrer le modèle multimodal natif de Google sans jongler avec des comptes fournisseurs séparés, des portails de facturation ou des SDK.
Les deux variantes de Gemini Omni Flash sont disponibles sur Atlas Cloud :
| Variante | Idéal pour | Entrées | Résolution | Durée | Prix de départ |
| Gemini Omni Flash Text-to-Video (Developer) | Génération cinématographique pure | Texte (jusqu'à 20 000 car.) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/sec |
| Gemini Omni Flash Image-to-Video (Developer) | Vidéo cohérente depuis références réelles | Texte + jusqu'à 7 images ref. | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/sec |
Démarrage rapide — Générez une vidéo Gemini Omni Flash en 5 lignes :
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
L'API renvoie immédiatement un ID de prédiction — interrogez /api/v1/model/prediction/{id} pour obtenir l'URL du MP4 rendu. Le schéma complet, des exemples de code dans 7 langages et un Playground sans code sont disponibles sur les pages des modèles liées ci-dessus.
Insights clés
La raison pour laquelle la cohérence multi-tours est importante n'est pas la démo. C'est l'opportunité qu'elle débloque.
Pendant cinq ans, chaque conversation sur le thème « quand la vidéo par IA deviendra-t-elle commerciale ? » s'est heurtée au même mur : le moment où les modèles pourront garder un personnage cohérent à travers les éditions. Ce mur vient de bouger.
La démo du violoniste n'est pas une prouesse publicitaire. C'est la première fois qu'un laboratoire majeur présente un flux de montage multi-tours réel et fonctionnel sur scène. La prochaine fois qu'une équipe marketing demandera à un outil vidéo IA de produire six clips du même produit dans six scénarios, elle devrait s'attendre à six résultats utilisables — pas à six visages sans rapport.






