Google a lancé Gemini Omni lors de la conférence I/O 2026 : un modèle multimodal capable de modifier une vidéo par le biais d'une simple conversation en langage naturel, sans passer par des timelines ou des images clés. Les démos devenues virales (la sculpture en bulles, le miroir liquide, le violoniste) illustrent un changement majeur : il ne s'agit plus seulement de texte vers vidéo, mais de texte pour modifier la vidéo que vous possédez déjà. C'est le moment « iPhone » pour la création vidéo. La parole, le montage audio et une offre Pro manquent à l'appel, et ce n'est pas un hasard.
Il est 1 h du matin. Cela fait quatre heures que vous montez un clip de 30 secondes. Votre projet compte 47 calques. Vous avez déplacé des images clés jusqu'à en avoir mal au poignet. Le client vient d'envoyer un message : « est-ce qu'on peut essayer avec un éclairage plus chaud ? ». Et vous, le professionnel, vous vous apprêtez à tout recommencer.
C'était ça, le travail. C'était ça, le travail.
Le 19 mai 2026, Google a discrètement mis fin à cette ère.
Lors de la conférence I/O 2026, l'entreprise a dévoilé Gemini Omni, un modèle multimodal qui transforme le montage vidéo en quelque chose que nous pensions encore à une décennie de distance : une conversation normale.
La promesse fondamentale : arrêtez de manipuler la vidéo. Commencez à lui parler.
Voici le concept résumé en une phrase : vous ne manipulez plus la vidéo, vous lui dites ce que vous voulez.
L'annonce de Google est directe : « Chaque instruction s'appuie sur la précédente. Vos personnages restent cohérents, la physique est respectée et la scène se souvient de ce qui s'est passé avant. »
Il ne s'agit pas d'une mise à jour de Veo. La page produit de Google DeepMind propose une définition plus claire : « Considérez Gemini Omni comme Nano Banana, mais pour la vidéo. » L'année dernière, Nano Banana a rendu l'édition photo aussi simple que d'écrire ce que l'on souhaitait. Omni fait désormais de même pour les images en mouvement.
Le premier modèle de la gamme, Gemini Omni Flash, est déjà disponible dans l'application Gemini, Google Flow et YouTube Shorts.
Et voici la phrase qui devrait changer votre vision decette catégorie : dans une interview accordée à TechCrunch par l'équipe de DeepMind, l'ingénieur de recherche Gabe Barth-Maron a décrit les créations réalisées avec Omni comme des « mèmes personnalisés ».
C'est là tout l'enjeu. La création vidéo vient de passer de l'artisanat à l'expression pure — la même transition que la photographie a connue lorsque l'iPhone a brisé le monopole des reflex.
Les démos qui enflamment Twitter
On peut lire des argumentaires marketing toute la journée, mais ce sont les démos qui ont fait le succès de ce lancement. Trois d'entre elles sont omniprésentes :
- La sculpture en bulles. Vous donnez à Omni un clip d'une sculpture en pierre, tapez « transforme la sculpture en bulles », et le rendu suivant conserve la même composition, le même éclairage et les mêmes ombres, mais la sculpture devient du savon translucide captant la lumière ambiante.
- Le miroir liquide. Une main touche un miroir ; l'invite demande à Omni de « faire onduler le miroir comme s'il s'agissait de liquide, et transformer le bras de la personne en matériau réfléchissant ». Comme l'a documenté Windows Report, les ondulations se propagent physiquement vers l'extérieur et le chrome du bras reflète réellement la pièce.
- Les modifications en chaîne. La démo du violoniste montre un même sujet à travers trois séquences : scène → environnement transporté → angle de caméra par-dessus l'épaule. Trois modifications. Une seule personne. Le visage, la posture, la prise en main de l'instrument : tout reste cohérent.

Il ne s'agit pas de texte vers vidéo. C'est du texte pour modifier la vidéo que vous avez déjà. La distinction semble mineure. Elle change pourtant tout.
Pourquoi les créateurs sont conquis
Si cette sortie a un impact plus fort que les autres lancements de modèles, c'est simple : Omni élimine la boucle infernale de la vidéo générative.
Ancienne boucle : générer → détester le résultat → réécrire tout le prompt → attendre 90 secondes → résultat toujours mauvais → recommencer.
Nouvelle boucle : générer → « change l'éclairage pour une "golden hour" » → terminé → « maintenant, ralentis le zoom caméra » → terminé.
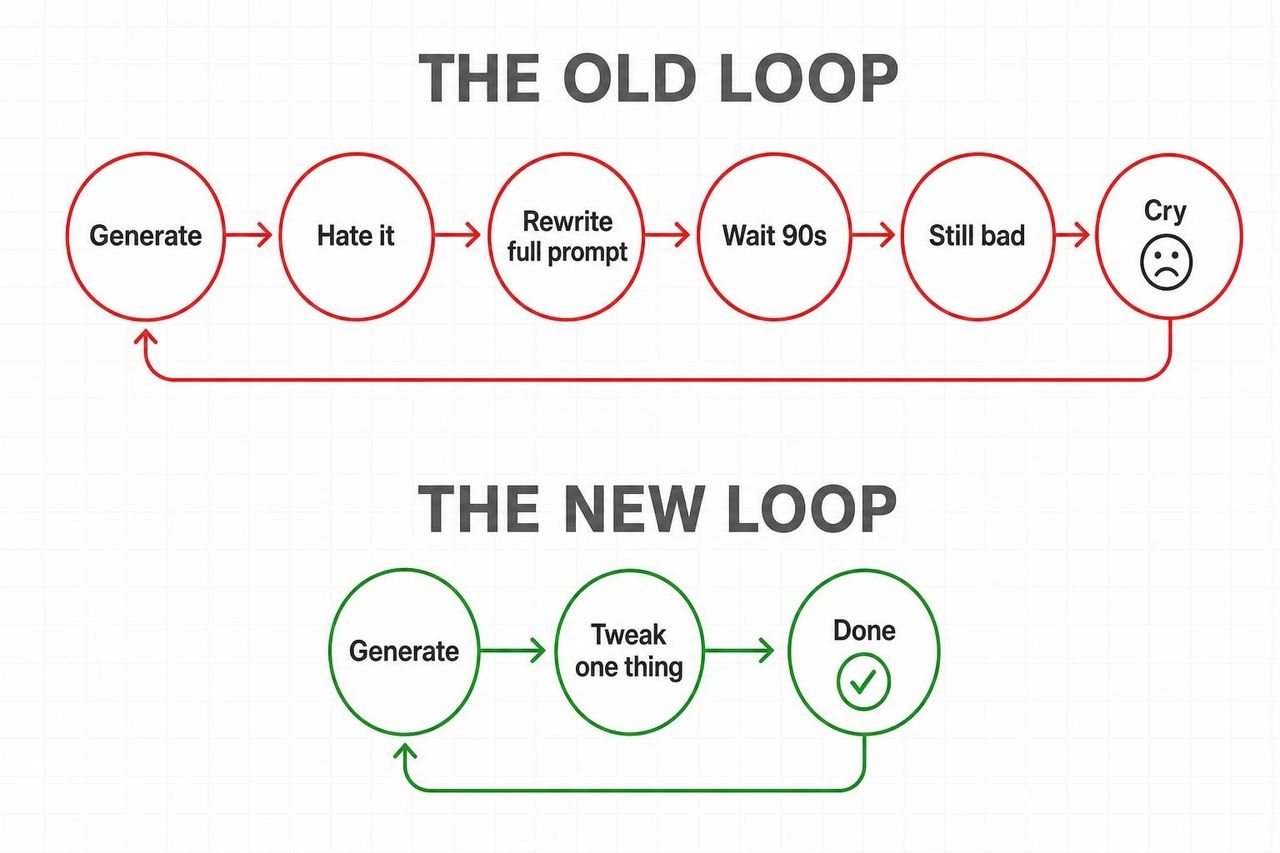
Android Central ne mâche pas ses mots : « Gemini Omni pourrait rendre les applications de montage vidéo traditionnelles archaïques. » TechRadar a exprimé le même constat avec plus de nuance, soulignant que le mouvement reste désormais cohérent entre les modifications, au lieu de se réinitialiser à chaque nouveau prompt.
Les développeurs sont déjà à pied d'œuvre. Sur le forum V2EX, un développeur chinois l'a testé le jour même du lancement et a posté : « la modification par chat d'objets dans une vidéo, ce type d'interaction est clairement la direction à suivre. La vitesse et la cohérence ont dépassé mes attentes. » Sur X, l'immunologiste et commentateur IA Dr. Derya Unutmaz a tweeté quelques minutes après la keynote : « Wow ! Google DeepMind vient de sortir une nouvelle IA multimodale géniale appelée Gemini Omni. Les vidéos sont vraiment réussies ! Il faut essayer dès que possible ! »
Lorsque l'intelligentsia de l'IA sur Twitter et les forums de développeurs chinois s'accordent en quelques heures, nous sommes face à une véritable inflexion.
Ce que Google retient discrètement
Il serait irresponsable d'écrire une lettre d'amour sans apporter quelques bémols.

Engadget a souligné le problème majeur : « le principal problème de Veo 3.1 et d'autres générateurs vidéo est l'aspect "vallée de l'étrange", souvent rejeté par les utilisateurs. Il sera intéressant de voir si la qualité de sortie correspond aux promesses dithyrambiques de Google. »
De plus, les tests pratiques de DataCamp ont déjà révélé un bug physique réel : un trébuchet lançant sa charge vers l'arrière. Le testeur a également noté que le modèle manque encore de scores de référence publiés, ce qui signifie qu'une vérification indépendante prendra encore quelques semaines.
Il y a aussi une omission délibérée : l'édition de la parole et de l'audio au sein de vidéos existantes. Comme Google l'a reconnu, l'entreprise « travaille encore à tester cela pour mieux comprendre comment proposer cette capacité aux utilisateurs de manière responsable. » En clair : le risque de deepfake est bien réel et ils conservent la fonctionnalité la plus sensible en coulisses.
Chaque clip Omni est accompagné du filigrane invisible SynthID de Google ainsi que des informations d'identification de contenu C2PA — une provenance vérifiable dans l'application Gemini, Chrome et la Recherche. Ce n'est pas optionnel. C'est désormais la norme minimale.
Ce que cela signifie réellement pour votre flux de travail
Si l'on écarte le battage médiatique, on obtient quelque chose de réellement nouveau :
- L'outil, c'est la conversation. Pas de timeline, pas de calques, pas d'images clés. Juste des mots.
- La boucle de feedback s'effondre. Ce qui prenait 90 secondes de régénération ne prend plus que 10 secondes de réglages.
- Le fossé professionnel se réduit. Quand n'importe qui ayant du goût peut itérer sur une vidéo aussi rapidement qu'il envoie un message Slack, le goulot d'étranglement se déplace de l'exécution vers les idées.
Pour les équipes marketing, les créateurs indépendants, les enseignants et tous ceux qui ont un jour eu besoin de « juste un petit clip de 10 secondes », c'est le point de bascule. Non pas parce que le modèle est parfait, mais parce que le modèle d'interaction est enfin le bon.
Le montage vidéo de demain ne nécessitera pas de logiciel. Il nécessitera du vocabulaire.
Une API unifiée pour la génération vidéo de production
Alors que Google déploie Gemini Omni Flash dans l'application Gemini et Google Flow pour les utilisateurs finaux, les développeurs et les équipes produit souhaitant intégrer le même moteur vidéo multimodal dans leurs propres flux de travail ont besoin d'une couche API stable et prévisible.
Atlas Cloud propose Gemini Omni Flash via une API unifiée, compatible avec OpenAI, aux côtés de plus de 300 autres modèles d'image, de vidéo et de LLM. Vous pouvez ainsi intégrer le modèle multimodal natif de Google sans jongler avec des comptes fournisseurs, des portails de facturation ou des SDK distincts.
Les deux variantes de Gemini Omni Flash sont disponibles sur Atlas Cloud :
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Variante | Idéal pour | Entrées | Résolution | Durée | Prix de départ |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Développeur) | Génération cinématique basée sur un prompt | Texte (jusqu'à 20 000 car.) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/sec |
| Gemini Omni Flash Image-to-Video (Développeur) | Vidéo cohérente à partir de références réelles | Texte + jusqu'à 7 images de référence | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/sec |
Démarrage rapide — Générez une vidéo Gemini Omni Flash en 5 lignes :
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
L'API renvoie immédiatement un ID de prédiction — interrogez /api/v1/model/prediction/{id} pour obtenir l'URL du MP4 généré. Le schéma complet, des exemples de code dans 7 langages et un Playground sans code sont disponibles sur les pages des modèles liées ci-dessus.
Un dernier mot — pour ceux qui développent avec ces outils
Voici la réalité gênante derrière chaque lancement de modèle de ce type : au prochain trimestre, trois autres annonces du « meilleur modèle vidéo au monde » seront faites. Chacune aura un SDK différent, un flux d'authentification différent, des limites de débit différentes et un modèle de tarification différent. Votre équipe perdra une semaine à intégrer chacun d'entre eux. Puis une autre semaine à déprécier le précédent.
C'est exactement le problème que Atlas Cloud résout.
Nous donnons aux développeurs un point d'accès unique vers plus de 300 modèles — tous les grands modèles fondamentaux, les meilleures versions open-source et les spécialistes de pointe en image, vidéo et raisonnement. Changez de modèle avec une seule ligne de code. Effectuez des benchmarks côte à côte sans réintégrer de SDK. Déployez le modèle le plus performant aujourd'hui, passez à celui qui sera à la mode le mois prochain, sans rien réécrire.
Car la seule certitude actuelle concernant l'IA, c'est que le classement change tous les mardis. Préparez-vous à cela.






