
Un clip vidéo cinématographique généré par IA — éclairage magnifique, une personne marchant dans Tokyo la nuit — et soudain, à mi-parcours, son pied traverse le trottoir. Ou la pluie s'arrête en plein milieu du cadre. Ou une tasse de café se contient elle-même pendant un bref instant.
L'illusion était parfaite pendant exactement six secondes, jusqu'à ce que la physique vienne interrompre le spectacle.
Pendant trois ans, cela a été le bug indéfectible au cœur de la vidéo générative. Les modèles savaient simuler l'apparence. Ils ne savaient pas simuler le monde.
Le 19 mai dernier, lors de la conférence I/O 2026, Gemini Omni de Google a démontré que ce bug est enfin réparable — et a discrètement proposé à l'audience une simple démo qui a prouvé ce point mieux que n'importe quel benchmark.
La démo de la bille qui a retourné la communauté IA sur X
La démo : une simple bille en verre roulant sur un parcours complexe à réaction en chaîne. Elle rebondit sur des plaques. Déclenche des clochettes. Glisse sur des inclinaisons. Fait basculer des dominos qui en renversent d'autres. Chaque contact produit une force de réaction crédible. Chaque atterrissage est accompagné d'un son synchronisé.
La couverture de 9to5Google ne cachait pas sa surprise : "La vidéo de la bille qui roule est un excellent exemple, avec une physique crédible pour la balle et des effets sonores convaincants pour chaque rebond et tintement de cloche."
Cette phrase peut sembler banale. En réalité, il s'agit d'une étape historique pour l'industrie.
La démo est devenue virale en quelques heures. Même les poids lourds de l'IA n'ont pas pu rester silencieux — l'immunologiste et commentateur en IA Dr. Derya Unutmaz a tweeté quelques minutes après la keynote : "Wow ! Google DeepMind vient de sortir une nouvelle IA multimodale incroyable appelée Gemini Omni. Les vidéos sont superbes ! Il faut essayer ça au plus vite !"
Pourquoi "faire rouler une bille" était impossible depuis trois ans
Pour comprendre pourquoi une démo de bille mérite d'être qualifiée d'étape majeure, il faut regarder les échecs de la vidéo IA depuis 2023.
À l'ère de Sora, la qualité visuelle était déjà là. Un modèle pouvait générer un clip cinématographique 4K d'une personne marchant dans Tokyo la nuit. Mais :
- L'eau des fontaines coulait vers le haut
- Une cuillère traversait un bol de céréales
- La jambe d'un personnage devenait brièvement transparente pendant sa marche
- La gravité fonctionnait... la plupart du temps
Les visuels étaient réussis à 90 %. Le modèle du monde, à 50 %. Et dès qu'un spectateur repérait une faille physique, il ne pouvait plus s'en détacher. Toute l'illusion s'effondrait.
Pour les créateurs professionnels, il ne s'agissait pas d'un problème de finition, mais d'un frein à l'utilisation. Impossible de livrer une vidéo IA à des clients sans vérifier manuellement chaque image à la recherche de ruptures physiques. Ce qui explique pourquoi la plupart des équipes en entreprise ont totalement ignoré ce média.
Le positionnement de Google avec Omni s'attaque directement à ce fossé. La page officielle de lancement le résume en une phrase : "Omni possède une compréhension intuitive améliorée des forces telles que la gravité, l'énergie cinétique et la dynamique des fluides, vous permettant de créer des scènes plus réalistes."
Hassabis a dit tout haut ce que tout le monde pensait tout bas
La phrase la plus révélatrice à l'I/O 2026 n'est pas venue d'une slide marketing. Elle est venue du CEO de DeepMind, Demis Hassabis, sur scène : il a décrit Omni comme "un pas vers l'intelligence artificielle générale (AGI)."
Comme l'a rapporté Decrypt, Hassabis a explicitement lié la simulation physique à l'ambition plus large de l'AGI — qualifiant Gemini de "modèle de monde IA capable de comprendre et de simuler le monde."
C'est ce cadrage qui doit attirer l'attention. Hassabis ne prétend pas qu'Omni est un meilleur jouet vidéo. Il dit : un modèle qui comprend réellement la physique est un modèle capable, à terme, d'agir dans le monde physique. Ce qui est exactement ce dont les robots ont besoin.
L'angle de la robotique que personne en dehors de la Chine n'a relevé
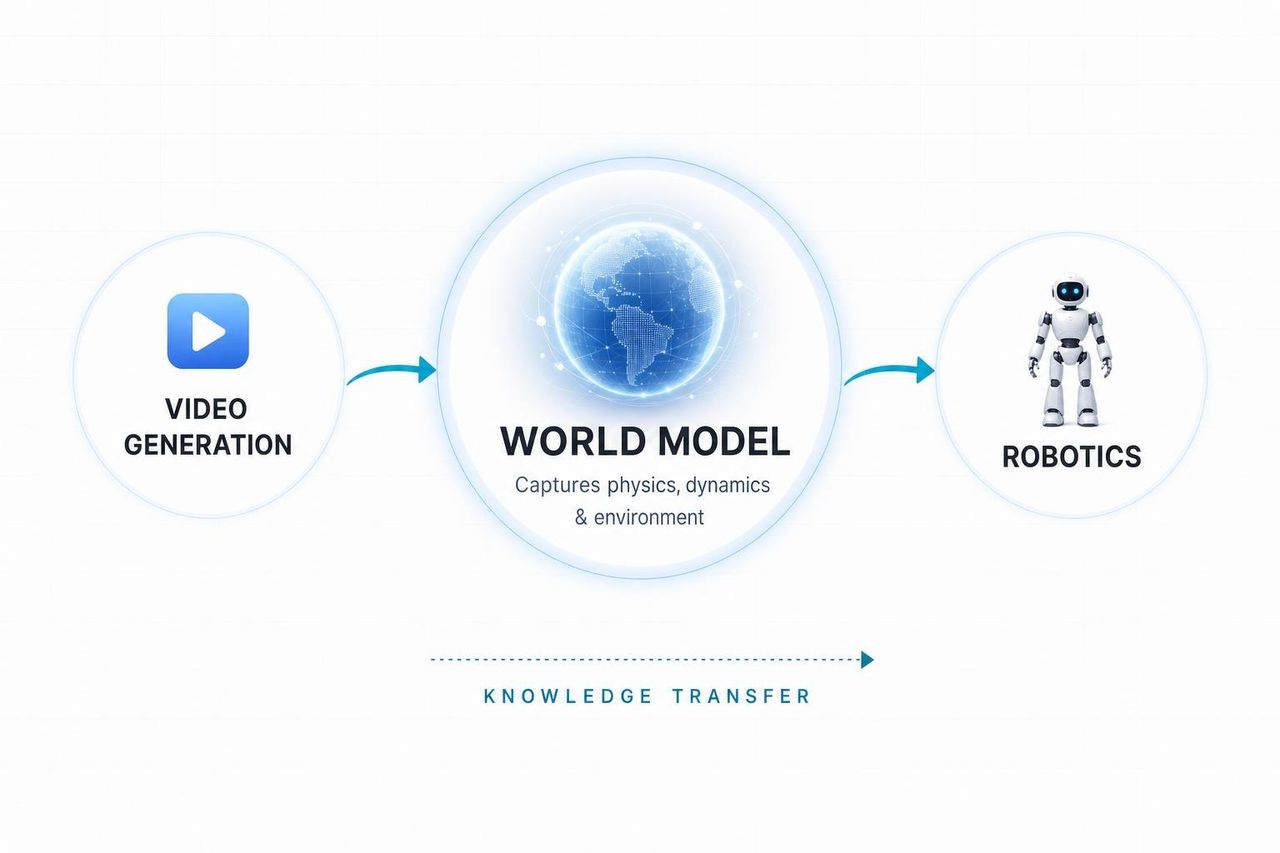
Voici un angle que la plupart de la couverture médiatique anglophone a totalement manqué. La presse technologique chinoise l'a repéré en premier.
Selon un rapport de Sina Finance citant le CTO de DeepMind, Koray Kavukcuoglu, la compréhension physique d'Omni "a été directement appliquée à l'entraînement de la robotique de pointe."
Technobezz a confirmé cette analyse : Omni possède "beaucoup plus de connaissances sur le monde que Veo" car il hérite des données d'entraînement sous-jacentes de Gemini — qui incluent désormais d'énormes quantités de simulations physiques.
Traduction : la démo de la bille n'est pas un tour de magie pour créateurs de contenu. C'est un avant-goût public du simulateur que Google utilise pour apprendre aux robots à saisir, lancer, équilibrer et réagir. Le modèle vidéo est la partie émergée d'un iceberg bien plus grand, dédié à la modélisation du monde — allant de la génération vidéo à la compréhension physique, jusqu'à l'IA incarnée.
Soudainement, la bille qui roule prend un sens différent. Ce n'est plus "Google a fait une démo de physique sympa", mais plutôt "Google a montré au monde que leur pipeline d'entraînement robotique est opérationnel."
La preuve cachée que tout le monde a manquée : la démo du tableau noir
Voici un second élément de preuve physique qui circule discrètement dans les forums technologiques chinois.
Quelques jours avant l'I/O 2026, une démo d'Omni a fuité : un professeur devant un tableau noir, écrivant une démonstration trigonométrique complète. Comme détaillé par 36Kr, la formule était mathématiquement correcte, les étapes cohérentes, et l'écriture naturelle — tout cela généré à partir d'un simple prompt en anglais.
Cela ressemble à une prouesse de rendu de texte. C'est en fait, en filigrane, une prouesse physique.
Une écriture correcte nécessite que l'IA modélise :
- La mécanique du mouvement de la main pour former chaque caractère
- La séquence logique dans laquelle une démonstration est normalement écrite
- La pression physique de la craie sur le tableau
- La logique temporelle des étapes de dérivation
Sora, en revanche, générait des textes sur tableau qui, selon l'article de 36Kr, "ressemblaient à de l'écriture, mais à y regarder de plus près, c'était du charabia complet."
Il s'agit de la même capacité fondamentale — la cohérence physique et temporelle — appliquée à un domaine différent. La bille rebondit correctement. La craie frappe le tableau correctement. Les deux sont la preuve d'un même modèle du monde s'exprimant à travers différents tests de surface.
Mais ne couronnons personne trop vite
Il serait irresponsable d'écrire une lettre d'amour sans quelques astérisques.
Le test pratique de DataCamp a déjà pris Omni en flagrant délit de rupture physique. Le testeur a demandé le lancement d'un trébuchet — et le projectile a volé vers l'arrière. Le bug était bien réel. Il était simplement plus drôle que tragique car le testeur avait choisi un style visuel de tapisserie, ce qui a permis à l'imperfection de se fondre dans le style artistique médiéval.
Engadget a tempéré l'enthousiasme général : "Le problème majeur avec Veo 3.1 et d'autres générateurs vidéo est que le rendu a un effet 'vallée de l'étrange', souvent rejeté par les utilisateurs finaux. Il sera intéressant de voir si la qualité de sortie égale les affirmations audacieuses de Google."
Trois autres rappels à la réalité :
- Aucun benchmark publié. Google n'a pas diffusé d'évaluations chiffrées lors du lancement. Les benchmarks indépendants n'arriveront que dans quelques semaines.
- Limite de 10 secondes. Selon l'interview de TechCrunch avec DeepMind, Omni Flash est actuellement limité à des clips de 10 secondes. Des durées plus longues arrivent, mais pour l'instant, c'est le domaine du court format.
- Édition audio/voix bridée.Google a lui-même reconnu que l'entreprise "travaille encore à tester et à mieux comprendre comment apporter cette capacité aux utilisateurs de manière responsable" — le risque de deepfake dans l'édition vocale est réel et Google a délibérément choisi de ne pas proposer cette fonctionnalité pour l'instant.
Chaque clip Omni est également doté du watermark SynthID invisible de Google, ainsi que des accréditations de contenu C2PA, vérifiables dans l'application Gemini, Chrome et la Recherche. Il est important de noter : à mesure que la physique devient plus crédible, le besoin de provenance cryptographique se fait encore plus sentir. Plus le faux paraît vrai, plus il est nécessaire de pouvoir l'identifier comme tel.
Comment Omni se compare à Sora, Veo et Seedance sur la physique
Voici comment les principaux modèles vidéo IA se situent spécifiquement sur la physique et la compréhension du monde en mai 2026 :
| Modèle | Réalisme Physique | Connaissances du monde | Édition conversationnelle | Statut |
|---|---|---|---|---|
| Gemini Omni Flash | Nouveau leader (annoncé) | Meilleur — hérite des données Gemini | Oui, multi-tour | Disponible depuis le 19 mai 2026 |
| Sora 2 (OpenAI) | Amélioré mais encore instable | Limité | Non | Application Sora arrêtée ; API fermée en sept. 2026 |
| Veo 3.1 (Google) | Correct, pas de connaissance du monde | Limité | Texte + image seulement | Actif, en cours de remplacement par Omni |
| Seedance 2.0 (ByteDance) | Fort sur le mouvement | Bon | Limité | Actif ; classé n°1 au Artificial Analysis Video Arena |
Lecture honnête : Omni fait les promesses les plus agressives en matière de physique, Seedance possède le benchmark public le plus solide, Sora quitte la course grand public, et Veo est discrètement absorbé.
Ce que cela change réellement — secteur par secteur
Si la physique est désormais maîtrisée (ou presque), voici ce qui se débloque :
Pour les cinéastes et publicitaires : Fini le contrôle qualité physique image par image. Le micro-nettoyage qui consommait une journée de travail d'un monteur — corriger un objet qui glitche, réanimer un mauvais rebond — disparaît. Le storyboarding de pré-production devient radicalement plus rapide, et l'écart entre le concept et l'animatique se réduit, passant de semaines à quelques minutes.
Pour les enseignants : Des explications scientifiques précises sans avoir besoin d'animateur. La démo de pliage de protéines en pâte à modeler montrée par Hassabis à l'I/O n'est pas un gadget — c'est un aperçu de ce que chaque professeur de physique au lycée pourra bientôt créer pour moins de 20 USD de puissance de calcul. Parcours à réaction en chaîne, dynamique des fluides, mouvement planétaire : tout devient explicable à la demande.
Pour les équipes robotiques : Confirmation que DeepMind dispose de simulateurs physiques opérationnels à grande échelle. Même si vous n'utilisez pas la stack de Google, l'existence d'une physique de niveau Omni issue d'un laboratoire majeur modifie le calendrier de l'IA incarnée pour toute l'industrie.
Pour les studios de jeux : Des cinématiques générées par IA qui ne brisent pas l'immersion. Les cinématiques de jeux ont toujours été l'endroit où la fidélité physique comptait le plus — et où les outils vidéo IA échouaient le plus lourdement. La barre placée par Omni change la donne.
Pour les annonceurs : Des vidéos de produits qui ne paraissent pas fausses. La raison pour laquelle les marques évitaient la vidéo IA n'est pas la qualité, ce sont les ruptures étranges. Lorsqu'une boisson se verse correctement dans un verre, lorsqu'une semelle de basket se plie de façon réaliste à l'impact, la vidéo IA devient commercialement exploitable.
La nouvelle ligne de démarcation — et pourquoi dépendre d'un seul modèle est risqué
Voici la conclusion importante pour quiconque construit des produits IA en 2026.
L'ancien benchmark pour la vidéo IA était la qualité visuelle. Le nouveau benchmark est la compréhension du monde. Alors que ce changement s'opère, le paysage des modèles se fragmente en leaders hyper-spécialisés :
- Gemini Omni revendique désormais la couronne de la physique et du raisonnement
- Seedance de ByteDance reste en tête sur le mouvement cinématographique et l'animation de personnages
- D'autres modèles mènent sur la génération longue durée, l'édition en temps réel, la synchronisation audio ou la sortie par lots à faible coût
Pour les développeurs, cette fragmentation est un casse-tête opérationnel. Le modèle le plus performant en physique ce trimestre ne sera pas forcément le meilleur en cohérence des personnages le trimestre suivant. Le modèle le plus efficace en 4K aujourd'hui ne sera peut-être pas celui avec le meilleur rapport coût-génération dans six mois. Et chacun d'entre eux est fourni avec son propre SDK, son flux d'authentification, son modèle de tarification et ses limites de débit. Votre équipe peut facilement perdre un sprint d'ingénierie complet par intégration de modèle — et un autre par dépréciation.
C'est exactement le fossé que Atlas Cloud a été conçu pour combler. Nous donnons aux développeurs un point de terminaison unique avec accès à plus de 300 modèles — tous les modèles de fondation majeurs, les meilleures versions open-source et les spécialistes en mouvement sur l'image, la vidéo, l'audio et le raisonnement. Passez d'un modèle à l'autre avec une seule ligne de code. Exécutez des évaluations côte à côte sans reconstruire votre intégration. Déployez le modèle le plus fort pour la capacité spécifique dont vous avez besoin maintenant, et basculez vers le nouveau leader dès que le classement change — sans réécrire une seule ligne de code.
Le calcul est simple : dans un monde où la physique, la cohérence des personnages, le mouvement cinématographique et le rendu de texte sont chacun dominés par un modèle différent, la pire décision architecturale est de vous enfermer avec l'un d'entre eux.
Atlas Cloud est la couche d'abstraction qui rend le paysage fragmenté des modèles navigable, plutôt que de devenir un poids pour votre équipe.
Une API unifiée pour la génération vidéo de production
Alors que Google déploie Gemini Omni Flash dans l'application Gemini et Google Flow pour les utilisateurs finaux, les développeurs et les équipes produit qui souhaitent intégrer le même moteur vidéo multimodal dans leurs propres workflows ont besoin d'une couche API stable et prévisible.
Atlas Cloud propose Gemini Omni Flash via une API unifiée compatible avec OpenAI, aux côtés de 300+ autres modèles d'image, vidéo et LLM — afin que vous puissiez intégrer le modèle multimodal natif de Google sans gérer des comptes fournisseurs, portails de facturation ou SDK séparés.
Les deux variantes de Gemini Omni Flash sont disponibles sur Atlas Cloud :
| Variante | Idéal pour | Entrées | Résolution | Durée | Prix de départ |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Dev) | Génération cinématographique par prompt | Texte (jusqu'à 20k car.) | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/sec |
| Gemini Omni Flash Image-to-Video (Dev) | Vidéo cohérente depuis références | Texte + 7 images ref. | 720p / 1080p / 4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/sec |
Démarrage rapide — Générez une vidéo Gemini Omni Flash en 5 lignes :
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
L'API renvoie immédiatement un ID de prédiction — interrogez /api/v1/model/prediction/{id} pour l'URL de la vidéo MP4 générée. Le schéma complet, les exemples de code en 7 langages et un Playground no-code sont disponibles sur les pages des modèles liées ci-dessus.
Le vrai constat
L'ère du "quelle IA vidéo produit les plus belles images" se termine plus vite que la plupart des gens ne le pensent.
Ce qui commence, c'est l'ère du "quelle IA vidéo comprend réellement le monde." Et dans cette course, une seule bille qui roule — rebondissant de manière prévisible, faisant tinter une cloche au bon moment, atterrissant là où la physique le dicte — s'avère être une démo plus importante que n'importe quel paysage photoréaliste que Google aurait pu rendre.
Les pixels esthétiques, c'est fini. Place aux modèles du monde.
Les trois prochaines années de la vidéo IA se joueront ici.






