Qu'est-ce que GLM-5.1 ? Le modèle de codage autonome de Zhipu AI
Le modèle GLM 5.1 arrive bientôt sur Atlas Cloud !
- Qu'est-ce que GLM-5.1 : GLM 5.1 est le modèle open-source le plus avancé de Zhipu AI, affichant les capacités de programmation les plus puissantes parmi les modèles ouverts, rivalisant avec Opus 4.6 !
- Fonctionnalités clés : GLM 5.1 bénéficie de capacités de codage de premier ordre. Il automatise les tâches jusqu'à huit heures, avec une résolution de problèmes adaptative pour garantir des flux de travail fluides et des résultats entièrement fonctionnels.
- Date de lancement : Ce mois-ci.
Fonctionnalités principales de GLM-5.1
Performance de codage : Niveau Opus 4.6
GLM-5.1 obtient les meilleurs résultats sur les benchmarks de codage, égalant les performances de Claude Opus 4.6. Il se classe au sommet parmi les modèles open-source sur les principaux benchmarks publics.
Comparaison avec Claude 3.5 Sonnet :
- Claude 3.5 Sonnet : Solides capacités de codage, largement adopté pour le développement
- GLM-5.1 : Égale les performances de niveau Opus 4.6, tarification compétitive
Comparaison avec DeepSeek V3.2** :**
- DeepSeek V3.2 : Excellent modèle de codage open-source avec des capacités étendues
- GLM-5.1 : Supérieur sur les benchmarks de codage spécialisés, exécution longue durée unique
Exécution de tâches sur le long terme : 8 heures d'autonomie
GLM-5.1 va bien au-delà du simple dialogue. Confiez-lui un véritable projet d'ingénierie, et il planifiera le flux de travail, écrira le code, lancera les tests, changera de stratégie en cas de blocage, corrigera les problèmes en cas d'erreur, et continuera de travailler jusqu'à 8 heures pour fournir un résultat complet. Peu de modèles possèdent cette capacité.
Comparaison avec GPT-4o :
- GPT-4o : Excellent pour les conversations multi-tours et les tâches courtes
- GLM-5.1 : Conçu pour une exécution autonome étendue avec gestion d'état
Comparaison avec Qwen2.5** :**
- Qwen2.5 : Forte performance sur des tâches diverses
- GLM-5.1 : Spécialisé pour les flux de travail d'ingénierie complexes et de longue durée
Réflexion entrelacée et préservée
- Réflexion entrelacée
Permettre à GLM de raisonner entre et après les appels d'outils permet une pensée étape par étape : interpréter les résultats, enchaîner les appels et prendre des décisions précises basées sur les résultats intermédiaires.
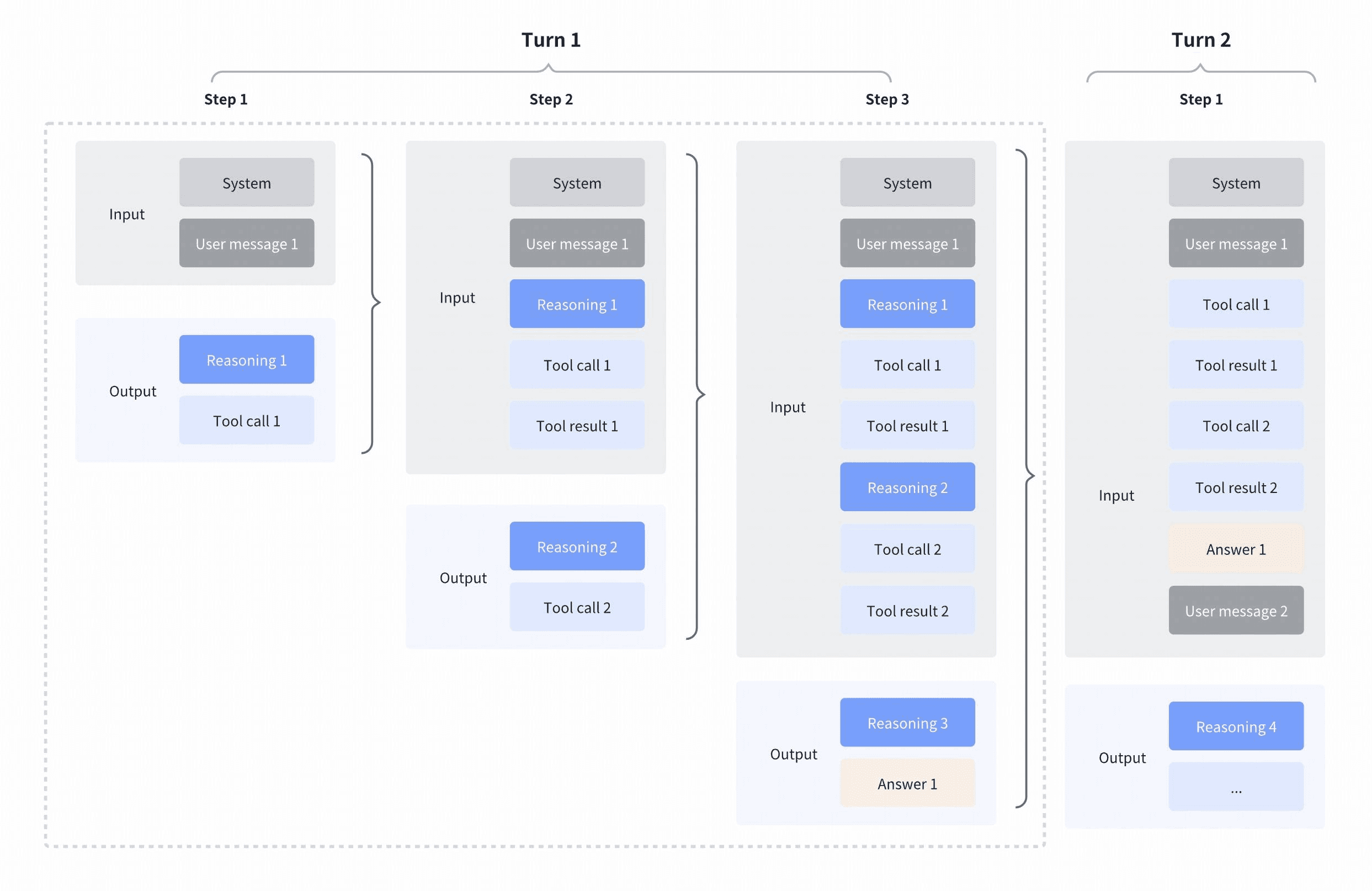
- Réflexion préservée
GLM-5.1 conserve le raisonnement des tours précédents, garantissant la continuité, améliorant les performances, augmentant les taux de mise en cache et économisant des jetons (tokens) lors des tâches réelles.
Cas d'utilisation de GLM-5.1 : Migration de code, développement de fonctionnalités, débogage
Simplification de la migration de code
GLM-5.1 prend en charge les tâches chronophages de migration de code, transformant des semaines d'effort en quelques jours. Il examine la base de code, crée une stratégie, édite les fichiers à grande échelle et effectue des tests approfondis. Cela a rendu les projets courants, comme la mise à niveau des versions Python ou la modernisation des frameworks, jusqu'à 70 % plus rapides et plus faciles.
Développement de fonctionnalités de bout en bout
Des idées initiales aux applications entièrement construites, GLM-5.1 gère l'ensemble du processus. Il planifie l'architecture, construit les systèmes backend et frontend, écrit des tests et gère même la documentation. Sans nécessiter une supervision constante, il fournit des solutions complètes prêtes pour le déploiement, incluant la sécurité, les bases de données et les configurations de production.
Débogage plus intelligent
Lorsque des bugs complexes apparaissent dans de grands systèmes, GLM-5.1 effectue le travail difficile. Il traque les problèmes de manière persistante, qu'il s'agisse de conditions de concurrence ou de fuites de mémoire, et applique des correctifs basés sur des tests rigoureux. Chaque étape est documentée, laissant aux développeurs des solutions sur lesquelles ils peuvent s'appuyer.
Pourquoi utiliser GLM-5.1 sur Atlas Cloud ?
Qu'est-ce qu'Atlas Cloud ?
C'est une plateforme qui simplifie l'IA en vous donnant accès à plus de 300 modèles de pointe en un seul endroit : texte, images, vidéo, et plus encore.
Pour qui ?
• Développeurs souhaitant un accès simple et abordable à l'IA. • Équipes gérant des projets nécessitant l'IA dans plusieurs domaines. • Entreprises ayant besoin d'une IA fiable pour des tâches critiques. • Utilisateurs d'outils comme ComfyUI et n8n.
Pourquoi le choisir ?
• Une API unique pour tout utiliser : une seule clé. • Tarification claire, sans surprise, et à faible coût. • Conçu pour l'entreprise : stable, sécurisé et soutenu par des experts. • Fonctionne avec les outils que vous utilisez déjà. • Vos données restent sécurisées et conformes aux besoins de conformité.
Comment se compare-t-il ?
• Fal.ai : Atlas propose plus de modèles et de meilleurs prix. • Wavespeed : Atlas coûte moins cher et inclut un support entreprise. • Kie.ai : Atlas est plus transparent sur les prix et offre une sélection plus large. • Replicate : Bibliothèque plus restreinte et coûts plus élevés. • Autres fournisseurs (comme OpenAI) : Atlas combine tout sur une seule plateforme simple.
Comment utiliser GLM-5.1 sur Atlas Cloud
Atlas Cloud vous permet d'utiliser les modèles côte à côte — d'abord dans un playground, puis via une API unique.
Méthode 1 : Utilisation directe dans le playground Atlas Cloud
Méthode 2 : Accès via API
Étape 1 : Obtenez votre clé API
Créez une clé API dans votre console et copiez-la pour une utilisation ultérieure.


Étape 2 : Consultez la documentation API
Passez en revue le point de terminaison, les paramètres de requête et la méthode d'authentification dans notre documentation API.
Étape 3 : Effectuez votre première requête (exemple Python)
Exemple : générer une vidéo avec GLM-5-Turbo
python1import os 2from openai import OpenAI 3 4client = OpenAI( 5 api_key=os.getenv("ATLASCLOUD_API_KEY"), 6 base_url="https://api.atlascloud.ai/v1" 7) 8 9response = client.chat.completions.create( 10 model="zai-org/glm-5-turbo", 11 messages=[ 12 { 13 "role": "user", 14 "content": "hello" 15 } 16], 17 max_tokens=1024, 18 temperature=0.7 19) 20 21print(response.choices[0].message.content)
FAQ : Foire aux questions sur GLM-5.1
Q : Comment GLM-5.1 se situe-t-il par rapport à Claude 3.5 Sonnet pour le codage ?
A : GLM-5.1 égale Claude Opus 4.6 sur les benchmarks de codage, surpassant Claude 3.5 Sonnet. Sa capacité à gérer des tâches étendues le distingue nettement.
Q : Qu'est-ce qui différencie "l'exécution de tâches sur le long terme" ?
A : Les modèles de chat classiques répondent à des invites individuelles. GLM-5.1, cependant, peut rester concentré sur une tâche pendant 8 heures, en s'adaptant et en s'auto-corrigant tout au long du processus.
Q : GLM-5.1 est-il open source ?
A : Oui, il est entièrement open source. Développé par Zhipu AI, vous pouvez trouver les détails de licence dans la documentation officielle.
Q : Est-il prêt pour une utilisation en production ?
A : Absolument ! GLM-5.1 offre une fenêtre de contexte de 128K et fonctionne sur l'infrastructure fiable d'Atlas Cloud, ce qui le rend prêt pour la production.
Q : Comment intégrer sa capacité d'exécution de 8 heures ?
A : Pour les tâches longues, utilisez un webhook ou une configuration de polling. Atlas Cloud gère le backend et votre application reçoit le résultat final une fois la tâche terminée.
Q : Pour quelles tâches GLM-5.1 est-il le mieux adapté ?
A : Il est idéal pour les projets stimulants tels que la migration de code, le débogage de systèmes complexes et le développement logiciel full-stack.






