DeepSeek v4 : Tout ce qu'il faut savoir – Fonctionnalités, date de sortie et comment y accéder sur Atlas Cloud
Introduction : Qu'est-ce que DeepSeek v4 ?
Atlas Cloud enrichit son arsenal d'IA générative avec l'arrivée imminente de DeepSeek v4.
- Qu'est-ce que c'est : Le nouveau fer de lance de l'équipe DeepSeek. Si DeepSeek v3.2 fait figure de référence pour les modèles de code open-source rentables, la v4 repousse les limites de la logique et de la mémoire grâce à ses technologies propriétaires Manifold-Constrained Hyper-Connections (mHC) et Engram Memory.
- Avantage clé : Bien au-delà de la simple génération de fragments de code, la v4 agit comme un architecte senior, capable de comprendre des structures de dépôts entières pour un raisonnement inter-fichiers et une correction de bugs complexe.
- Statut : Sortie prévue (attendue pour mi-février 2026 — lisez notre analyse approfondie sur ce qu'il faut attendre de DeepSeek V4).
Pourquoi sommes-nous convaincus que DeepSeek v4 va changer la donne ? Parce qu'il résout le problème majeur du secteur : l'IA doit être capable de mémoriser et de comprendre la logique d'un projet.
📣 Mise à jour — 24 avril 2026 : DeepSeek-V4 est officiellement lancé. Découvrez notre couverture complète des fonctionnalités, y compris la nouvelle architecture d'attention creuse (sparse attention), le contexte de 1M de jetons et les résultats sur les benchmarks d'agents dans DeepSeek-V4 Preview Launch.
Plongée technique : Fonctionnalités clés
Pour défier Claude Opus 4.5, DeepSeek a entièrement reconstruit son modèle. Les documents ayant fuité indiquent un changement fondamental dans la gestion de la mémoire et la stabilité logique. Voici les quatre piliers de cette mise à jour.
Architecture : Un raisonnement logique supérieur
-
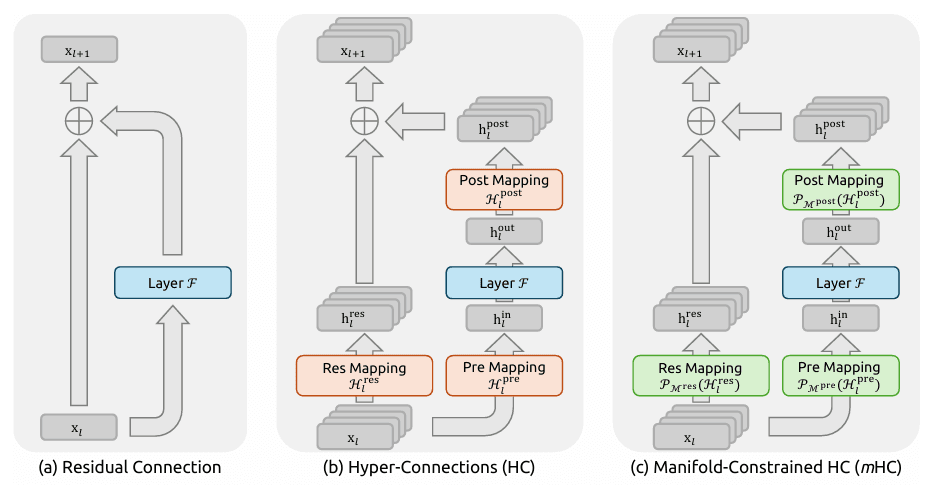
Manifold-Constrained Hyper-Connections (mHC)
- Le concept : DeepSeek v4 invente une nouvelle méthode de « câblage neuronal ». Les connexions traditionnelles perdent souvent des informations dans les réseaux profonds, mais le mHC agit comme une « autoroute logique » pour le cerveau de l'IA.
- Le résultat : Lors du traitement de logiques complexes et massives (comme le refactoring de milliers de lignes de code), le modèle apprend plus vite et conserve mieux la logique. Cela élimine les « hallucinations logiques » et les incohérences courantes dans la génération à long contexte.
Efficacité : Réduction des coûts d'inférence
-
Mixture-of-Experts (MoE) 2.0
- Le concept : Bien que la v4 soit un géant en termes de paramètres (plusieurs centaines de milliards), elle utilise une architecture MoE optimisée pour n'activer que les « experts » les plus pertinents pour chaque jeton.
- Le résultat : Un équilibre parfait entre haute capacité (base de connaissances massive) et mise à l'échelle efficace (aussi fluide qu'un modèle plus petit).
-
Sparse Attention (Attention creuse)
- Le concept : Fini le scan systématique de tout le texte ; le modèle se concentre désormais intelligemment uniquement sur les informations clés. Cela réduit drastiquement les coûts de calcul et accélère le traitement des longs contextes.
Mémoire : Gestion intelligente du contexte
-
Engram Memory (Stockage et rappel sélectifs)
- Le concept : L'IA ne se contente plus d'apprendre par cœur, elle « comprend ». Elle reconnaît les structures de projet, suit les conventions de nommage (snake_case vs camelCase) et identifie les patterns de codage (imitant les habitudes de votre équipe).
- Le résultat : Un codage digne d'un développeur chevronné.
-
Multi-Head Latent Attention (MLA)
- Le concept : Imaginez un système de « sténographie ultra-performante ». Là où d'autres modèles ont besoin de 100 jetons pour stocker une information, le MLA la compresse en 10 symboles clés.
- Le résultat : Lorsque le rappel est nécessaire, le modèle reconstruit mathématiquement le sens original sans perte, conservant un niveau de détail incroyable avec une utilisation de VRAM significativement réduite.
Application : Ingénierie réelle
- Compréhension au niveau du repo et correction de bugs
- L'objectif n'est pas seulement d'écrire une fonction, mais de maîtriser la base de code. Dans les tests SWE-bench, DeepSeek v4 vise à résoudre plus de 80,9 % des problèmes complexes du monde réel en comprenant les dépendances inter-fichiers.
Cas d'usage : Réduire les coûts et booster l'efficacité
DeepSeek v4 est taillé pour l'ingénierie de pointe. Voici comment il se compare à la concurrence :
Refactoring de code legacy
Pour les systèmes legacy chaotiques et non documentés, l'architecture mHC est une bouée de sauvetage. Elle retrace les dépendances logiques à longue distance pour un refactoring sécurisé.
- VS GPT-4o : GPT-4o souffre souvent d'« hallucinations logiques » (inventant des appels de fonctions inexistants) lorsque le contexte dépasse 10 000 jetons. DeepSeek v4 maintient une cohérence logique de 100 % sur de longs contextes.
- VS Claude 3.5 Sonnet : Bien que Sonnet soit de grande qualité, il est lent et coûteux pour les travaux de refactoring massifs. L'architecture MoE de DeepSeek v4 offre des vitesses d'inférence environ 40 % plus rapides à un coût moindre sur Atlas Cloud.
Développement de fonctionnalités au niveau du repo
Lors de l'ajout d'une nouvelle API à un projet mature, la v4 utilise sa « Engram Memory » pour saisir instantanément le contexte global.
- VS Autocomplete traditionnel : Les outils standards ignorent souvent les normes spécifiques au projet, introduisant des incohérences de style. DeepSeek v4 imite si bien votre base de code existante que l'on croirait à un copier-coller de votre meilleur développeur.
Suivi de bugs complet
Viser un taux de réussite de 80,9 % sur SWE-bench signifie gérer des bugs qui s'étendent du frontend au backend en passant par les bases de données.
- VS Claude Opus 4.5 (Attendu) : Opus 4.5 sera probablement puissant mais à un tarif premium. DeepSeek v4 offre des performances proches du SOTA à un prix permettant des boucles de « réflexion et correction » itératives sans exploser le budget.
📉 Le bilan : ROI pour les équipes
Pour les startups et les équipes de dev, le combo DeepSeek v4 + Atlas Cloud offre un ROI tangible :
- Productivité : Réduction du temps de codage pour les développeurs seniors de 30 à 50 %.
- Coût : Par rapport à la location de serveurs double RTX 4090 ou aux frais d'API propriétaires, l'API intégrée d'Atlas Cloud peut permettre aux équipes d'économiser plus de 60 % sur les coûts de calcul globaux.
La ligne rouge du matériel : Héberger en local ? Réfléchissez-y à deux fois.
Vous pourriez être tenté de faire tourner ce « dieu du code » sur votre machine locale. Mais soyons réalistes : la performance a un prix.
- Entrée de gamme : Double RTX 4090
- Traduction : Vous achetez deux des GPU grand public les plus chers du marché pour les coupler. Le coût des GPU seul équivaut approximativement à 3x iPhone 17 Pro Max (ou une bonne voiture d'occasion).
- Recommandé : RTX 5090 (Flagship 2026)
- Traduction : C'est la « Ferrari » des GPU. Non seulement le prix sera exorbitant à cause des revendeurs, mais la disponibilité sera très limitée.
Avec des prix de GPU qui restent élevés, demandez-vous : est-ce vraiment rentable de dépenser des milliers d'euros et de gérer le bruit des ventilateurs, la chaleur et la configuration de l'environnement juste pour faire tourner un modèle ?
La solution intelligente : Accès Jour 0 sur Atlas Cloud
Vous n'avez pas besoin d'être riche pour utiliser DeepSeek v4 ; vous devez juste être malin. Au lieu d'acheter des « briques électroniques » qui perdent de leur valeur, choisissez le cloud.
Atlas Cloud est prêt pour le lancement :
-
Notre promesse : Profitez de vos vacances. Laissez-nous le travail fastidieux du déploiement. Nous surveillons les canaux de sortie officiels 24h/24 et 7j/7.
-
Avantages principaux :
- Accès instantané : Dès que les poids open-source sont disponibles, notre intégration API est mise en ligne.
- Zéro barrière : Pas de matériel coûteux, pas d'enfer de dépendances CUDA. Apportez simplement votre prompt.
- Expérience sans compromis : Nous offrons une prise en charge complète du contexte, garantissant que le mécanisme de mémoire « Engram » fonctionne à 100 % de sa capacité sans perte liée à la quantification.
Comment utiliser sur Atlas Cloud
Atlas Cloud vous permet d'utiliser les modèles côte à côte — d'abord dans un playground, puis via une API unique.
Méthode 1 : Utilisation directe dans le playground Atlas Cloud
Méthode 2 : Accès via API
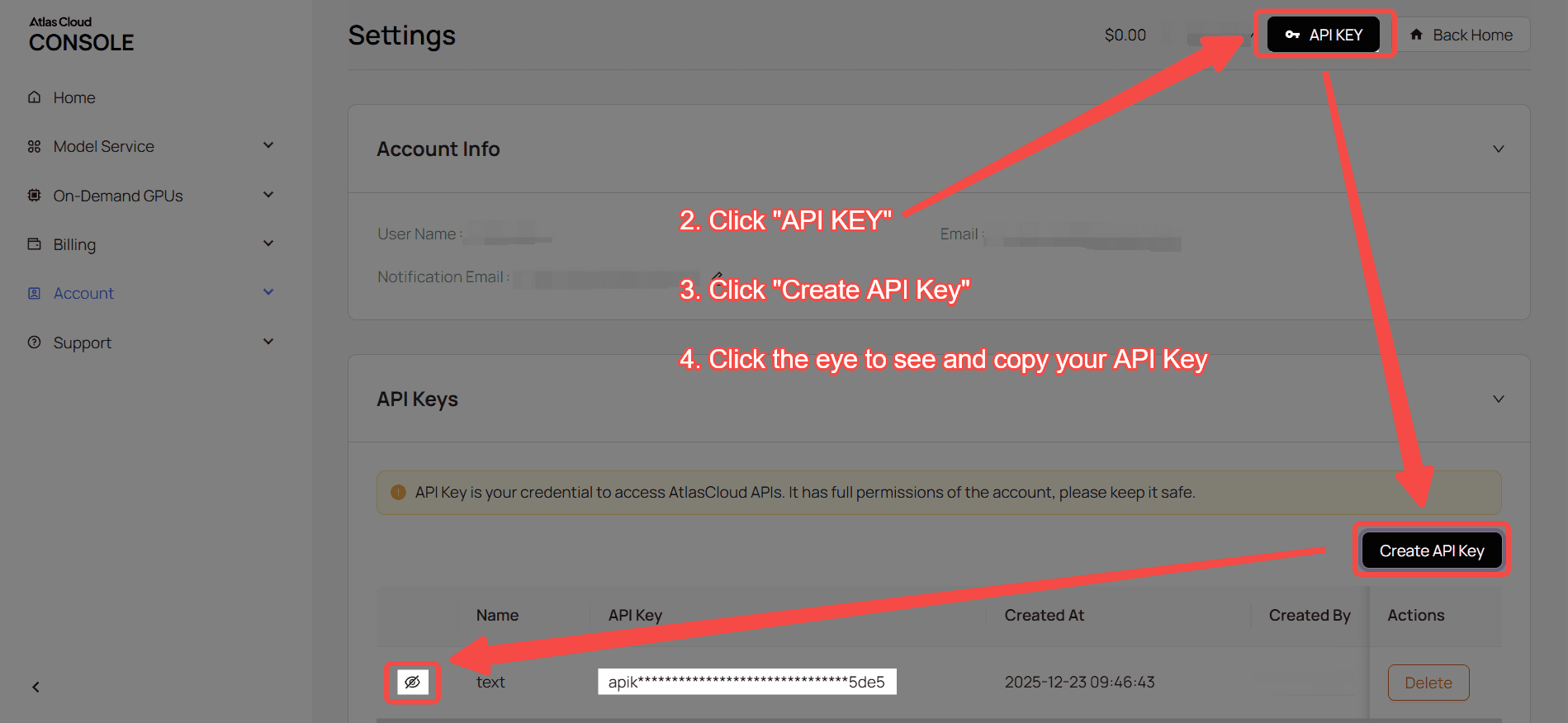
Étape 1 : Obtenez votre clé API
Créez une clé API dans votre console et copiez-la pour une utilisation ultérieure.
Étape 2 : Consultez la documentation de l'API
Vérifiez le point de terminaison (endpoint), les paramètres de requête et la méthode d'authentification dans notre documentation API.
Étape 3 : Faites votre première requête (exemple en Python)
Exemple : générer une réponse avec DeepSeek v3.2 :
python1import requests 2 3url = "https://api.atlascloud.ai/v1/chat/completions" 4headers = { 5 "Content-Type": "application/json", 6 "Authorization": "Bearer $ATLASCLOUD_API_KEY" 7} 8data = { 9 "model": "deepseek-ai/deepseek-v3.2", 10 "messages": [ 11 { 12 "role": "user", 13 "content": "quelle est la différence entre http et https" 14 } 15 ], 16 "max_tokens": 32768, 17 "temperature": 1, 18 "stream": True 19} 20 21response = requests.post(url, headers=headers, json=data) 22print(response.json())






