
Les laboratoires d'IA chinois ont discrètement mis au point certains des modèles de codage open source les plus performants disponibles à ce jour. Pour les développeurs qui n'ont suivi que le marché d'Anthropic et d'OpenAI, l'étendue de ce qui est désormais proposé par DeepSeek, Moonshot, Zhipu, MiniMax et Alibaba est véritablement surprenante.
La question à se poser en 2026 n'est pas de savoir si ces modèles sont bons. C'est de savoir lequel correspond à quelle charge de travail, ce qu'il en coûte de les exécuter à grande échelle et comment les intégrer aux outils que vous utilisez déjà. Ce guide couvre ces trois points : un profil par laboratoire, un tableau complet des spécifications et des coûts, un guide pratique de routage selon les cas d'usage, ainsi que les configurations de réglage pour Claude Code, Codex et OpenClaw.
![]()
Pourquoi les meilleurs LLM de codage open source attirent sérieusement l'attention
Le tournant a été DeepSeek V3, publié en décembre 2024. Il a obtenu un score de 89,1 % sur HumanEval et 42,0 % sur SWE-bench Verified, rivalisant avec Claude 3.5 Sonnet et GPT-4o à l'époque, bien qu'il soit open source et utilise une architecture "Mixture of Experts" (MoE) qui n'activait que 37 milliards de ses 671 milliards de paramètres totaux par passe directe (Rapport technique DeepSeek-V3, décembre 2024). L'efficacité induite par cette architecture explique pourquoi les coûts d'inférence étaient si nettement inférieurs.
Ce résultat a attiré l'attention des développeurs vers l'écosystème open source chinois dans son ensemble. Il s'est avéré que DeepSeek n'était pas une anomalie. La série Kimi K2 de Moonshot AI dominait discrètement les benchmarks sur les contextes longs. La série Qwen2.5-Coder d'Alibaba était en tête des classements spécifiques au code. La gamme GLM-5 de Zhipu produisait des sorties structurées précises, essentielles pour les pipelines agents.
Conséquence pratique pour les développeurs : cinq laboratoires distincts proposent désormais des modèles capables de gérer des charges de travail de codage en production, avec des poids ouverts ou un accès API commercial, à des tarifs bien inférieurs aux alternatives propriétaires.
Les laboratoires derrière les meilleurs LLM de codage open source
DeepSeek : conception axée sur le code et efficacité MoE
DeepSeek AI, fondé en 2023 et soutenu par High-Flyer Capital (un fonds spéculatif quantitatif chinois), a intégré son orientation vers le codage dans le modèle dès le départ. DeepSeek-Coder a été l'un des premiers modèles dédiés à la génération de code à attirer sérieusement l'attention de la communauté open source. Les séries V3 et V4 ont élargi cette approche au raisonnement général tout en conservant une forte performance sur les benchmarks de code.
L'architecture MoE mérite d'être comprise, car elle explique la tarification. En activant seulement une fraction des paramètres par jeton, le coût de calcul par requête est nettement inférieur à celui d'un modèle dense de qualité équivalente. Cette efficacité est répercutée sur la tarification de l'API, ce qui explique pourquoi le tarif d'entrée de 0,23 crédit pour mille jetons du DeepSeek V4 Flash est réalisable sans sacrifier la qualité sur des tâches plus simples.
Moonshot AI (Kimi), Zhipu AI (GLM), MiniMax et Alibaba (Qwen)
Moonshot AI (fondé en 2023, Pékin) s'est bâti une réputation sur l'inférence à contexte long. La série Kimi K2 dispose d'une fenêtre de contexte de 262 000 jetons et est conçue pour les tâches lourdes en documents et en code où il est crucial de faire tenir une grande base de code dans un seul appel.
Zhipu AI (fondé en 2019, issu du laboratoire KEG de l'université Tsinghua) est l'une des plus anciennes entreprises chinoises d'IA. La série GLM a connu cinq générations, chaque itération améliorant la fiabilité de la sortie structurée et le respect des instructions. GLM-5.1 reflète des années de travail d'alignement sur l'exécution précise des tâches.
MiniMax (fondé en 2021) est passé de travaux multimodaux à des modèles de codage avec la série M2. Les MiniMax M2.5 et M2.7 couvrent une gamme coût-qualité qui complète bien le segment intermédiaire.
L'équipe Qwen d'Alibaba a construit Qwen3.6-plus sur la base d'une solide lignée de modèles axés sur le code. La série a été constamment performante sur la génération de code multilingue, et sa fenêtre de contexte de plus de 256 000 jetons se situe dans le haut de gamme des options disponibles (GitHub QwenLM, 2025).
Comparaison des meilleurs LLM de codage open source : contexte, coût et spécifications
Voici le tableau complet des modèles actuels triés par taux d'entrée, afin que la structure des coûts soit immédiatement lisible :
| Modèle | Labo | Contexte | Taux Entrée | Taux Sortie | Écriture Cache | vs Officiel |
| DeepSeek V4 Flash | DeepSeek AI | 1M | 0,23 | 0,46 | 0,046 | -50% |
| DeepSeek V3.2 | DeepSeek AI | 160K | 0,42 | 0,62 | 0,193 | -55% |
| MiniMax M2.5 | MiniMax | 200K | 0,65 | 2,18 | 0,109 | -45% |
| Kimi K2.5 | Moonshot AI | 262K | 1,09 | 5,45 | 0,182 | -45% |
| Kimi K2.6 | Moonshot AI | 262K | 1,72 | 7,26 | 0,290 | -45% |
| GLM-5 | Zhipu AI | 200K | 1,82 | 5,81 | 0,363 | -45% |
| MiniMax M2.7 | MiniMax | 200K | 2,36 | 4,00 | 0,109 | -45% |
| GLM-5.1 | Zhipu AI | 200K | 2,54 | 7,99 | 0,472 | -45% |
| DeepSeek V4 Pro | DeepSeek AI | 1M | 2,87 | 5,75 | 0,231 | -50% |
| Qwen3.6-plus | Alibaba | 256K+ | 3,30 | 9,90 | 0,660 | -50% |
Les tarifs sont en crédits pour 1 000 jetons. "vs Officiel" correspond à l'économie réalisée par rapport au tarif API direct de chaque modèle.
Quelques points ressortent. Premièrement, DeepSeek V4 Flash à 0,23 en entrée et V4 Pro à 2,87 proviennent du même laboratoire, ce qui représente un multiplicateur de 12,5x entre le niveau le moins cher et le plus performant au sein d'une même famille de modèles. Deuxièmement, Kimi K2.5 à 1,09 en entrée offre une fenêtre de contexte de 262 000 jetons à un prix intermédiaire, ce qui le rend attractif pour les travaux à long contexte sans passer au tarif V4 Pro complet. Troisièmement, le taux de sortie de Qwen3.6-plus à 9,90 est le plus élevé du groupe, ce qui suggère des complétions plus longues et plus exhaustives comme caractéristique de conception.
Où chaque LLM de codage open source chinois est le plus pertinent
Ceci est la section pratique. Les tarifs ci-dessus se traduisent par des décisions de routage réelles lors de l'exécution d'une session de codage par agent.
Tâches légères et en arrière-plan : DeepSeek V4 Flash
Docstrings, renommage de variables, complétions simples, conversions de format et tous les appels utilitaires qu'un agent de codage effectue automatiquement en arrière-plan. À 0,23 en entrée et 0,46 en sortie, c'est le modèle le moins cher du groupe avec une large marge. Lorsque Claude Code dirige les tâches d'arrière-plan vers l'emplacement du modèle Haiku, orienter ce slot vers DeepSeek V4 Flash permet de garder le bruit de fond bon marché tandis que votre session principale utilise un modèle plus performant.
Codage économique avec des performances solides : DeepSeek V3.2 et MiniMax M2.5
DeepSeek V3.2 embarque l'architecture V3 avec une réduction de 55 % sur les tarifs officiels et une fenêtre de contexte de 160 000 jetons. Pour les développeurs qui souhaitent une capacité de codage solide sans payer les prix complets du V4 Pro, V3.2 est une option pratique. MiniMax M2.5 à 0,65 en entrée occupe une place similaire avec une fenêtre de 200 000 jetons, utile lorsque le contexte compte plus que le prix le plus bas possible.
Charges de travail à contexte long : Kimi K2.5 et K2.6
Les deux modèles Kimi offrent des fenêtres de contexte de 262 000 jetons. Pour transmettre de larges portions d'une base de code, analyser de longs historiques de conversation ou effectuer des tâches de refactorisation multi-fichiers où vous avez besoin que tout soit dans un seul contexte, Kimi K2.5 à 1,09 en entrée vous offre cette fenêtre sans payer les prix des modèles phares. K2.6 (1,72 en entrée) ajoute de la performance à l'avantage du contexte de K2.5 pour les cas où la qualité importe plus que le coût pur.
Sortie structurée et précision des instructions : GLM-5 et GLM-5.1
Les modèles GLM de Zhipu AI ont une force particulière dans le respect des instructions. Pour les pipelines nécessitant une sortie structurée fiable (schémas JSON spécifiques, artefacts de code formatés, formes de réponse API cohérentes), GLM-5 à 1,82 et GLM-5.1 à 2,54 valent la peine d'être testés par rapport à d'autres modèles sur ces tâches. Leurs taux de sortie sont dans le haut de la fourchette, ce qui reflète leur tendance à des complétions exhaustives et détaillées.
Raisonnement de pointe : DeepSeek V4 Pro et Qwen3.6-plus
Pour les décisions d'architecture complexes, le débogage d'interactions multi-systèmes ou les tâches où la qualité de la première génération importe (car les mauvais premiers brouillons provoquent des boucles de réessai coûteuses), V4 Pro et Qwen3.6-plus sont au sommet. La fenêtre de contexte de 1M de V4 Pro est sa spécification phare ; Qwen3.6-plus à 256 000+ se situe dans le haut de gamme en dehors de la famille DeepSeek.
Routage de modèles : la stratégie de LLM de codage open source la plus sous-utilisée
L'optimisation la plus efficace pour les développeurs utilisant l'un de ces LLM de codage open source chinois n'est pas de choisir le meilleur modèle unique. C'est de router différents types de tâches vers différents niveaux au sein de la même session.
Considérez une session de codage agentique typique : planification de l'approche (complexe, nécessite V4 Pro), écriture d'un algorithme central (complexe, V4 Pro), génération de cas de test (niveau intermédiaire, MiniMax M2.5 ou Kimi K2.5), rédaction de docstrings pour de nouvelles fonctions (léger, V4 Flash), exécution d'observations de lecture de fichiers (léger, V4 Flash). Si vous utilisiez V4 Pro pour tout, chacune de ces étapes de niveau "flash" coûterait 12,5 fois plus cher que nécessaire.
Le calcul devient vite concret. Supposons que 60 % de vos 50 appels API de session soient des tâches simples à une moyenne de 2 000 jetons d'entrée + 500 jetons de sortie chacune. Les exécuter sur V4 Flash :
- Coût : 30 appels × (2 000 × 0,23 + 500 × 0,46) = 30 × (460 + 230) = 20 700 crédits
Exécuter les 30 mêmes appels sur V4 Pro :
- Coût : 30 appels × (2 000 × 2,87 + 500 × 5,75) = 30 × (5 740 + 2 875) = 258 450 crédits
C'est une différence de 12,5x sur ces 30 appels seulement. Le routage de modèles s'amortit immédiatement.
Comment choisir le meilleur LLM de codage open source pour votre flux de travail
Un arbre de décision qui couvre la plupart des situations de développement :
Vous avez besoin d'un contexte maximal par requête : DeepSeek V4 Pro (1M) ou Qwen3.6-plus (256K+). Les deux gèrent les entrées de grandes bases de code sans découpage.
Le coût est la contrainte principale : DeepSeek V4 Flash pour les tâches simples, DeepSeek V3.2 ou MiniMax M2.5 pour les travaux de complexité moyenne.
Vous avez besoin d'une sortie structurée fiable : Commencez avec GLM-5.1 et testez-le par rapport à vos exigences de schéma spécifiques.
Vous construisez un pipeline agentique en plusieurs étapes : Routez selon la complexité de l'étape. Utilisez Flash pour les étapes utilitaires, Kimi K2.5 ou GLM-5 pour le raisonnement de niveau intermédiaire, V4 Pro pour la planification et le débogage.
Vous voulez un seul modèle pour essayer en premier : DeepSeek V4 Pro est le choix par défaut naturel pour les développeurs évaluant les LLM chinois pour la première fois. Il est bien documenté, bénéficie de la plus large couverture communautaire sur (r/LocalLLaMA) et offre une qualité de codage de premier plan.
Le piège pratique : router efficacement entre les modèles nécessite qu'ils soient tous derrière la même clé API et la même URL de base. Maintenir dix comptes API séparés n'est pas réalisable. C'est ce qu'une passerelle unifiée résout : un point de terminaison, une clé, la sélection du modèle est un paramètre.
Exécuter le meilleur LLM de codage open source dans vos outils de codage
Le plan de codage Atlas Cloud regroupe les dix modèles couverts dans ce guide derrière une seule clé API et une seule URL de base, à 45-55 % en dessous de leurs tarifs API directs. La configuration pour chaque outil de codage majeur suit.
La note sur l'URL de base pour vous éviter une session de débogage : Claude Code utilise https://api.atlascloud.ai sans le suffixe /v1. Tous les autres outils (Codex, OpenClaw, OpenCode, Cursor) utilisent https://api.atlascloud.ai/v1 avec le suffixe. Se tromper à ce niveau produit des erreurs d'authentification qui ne pointent pas directement sur la cause.
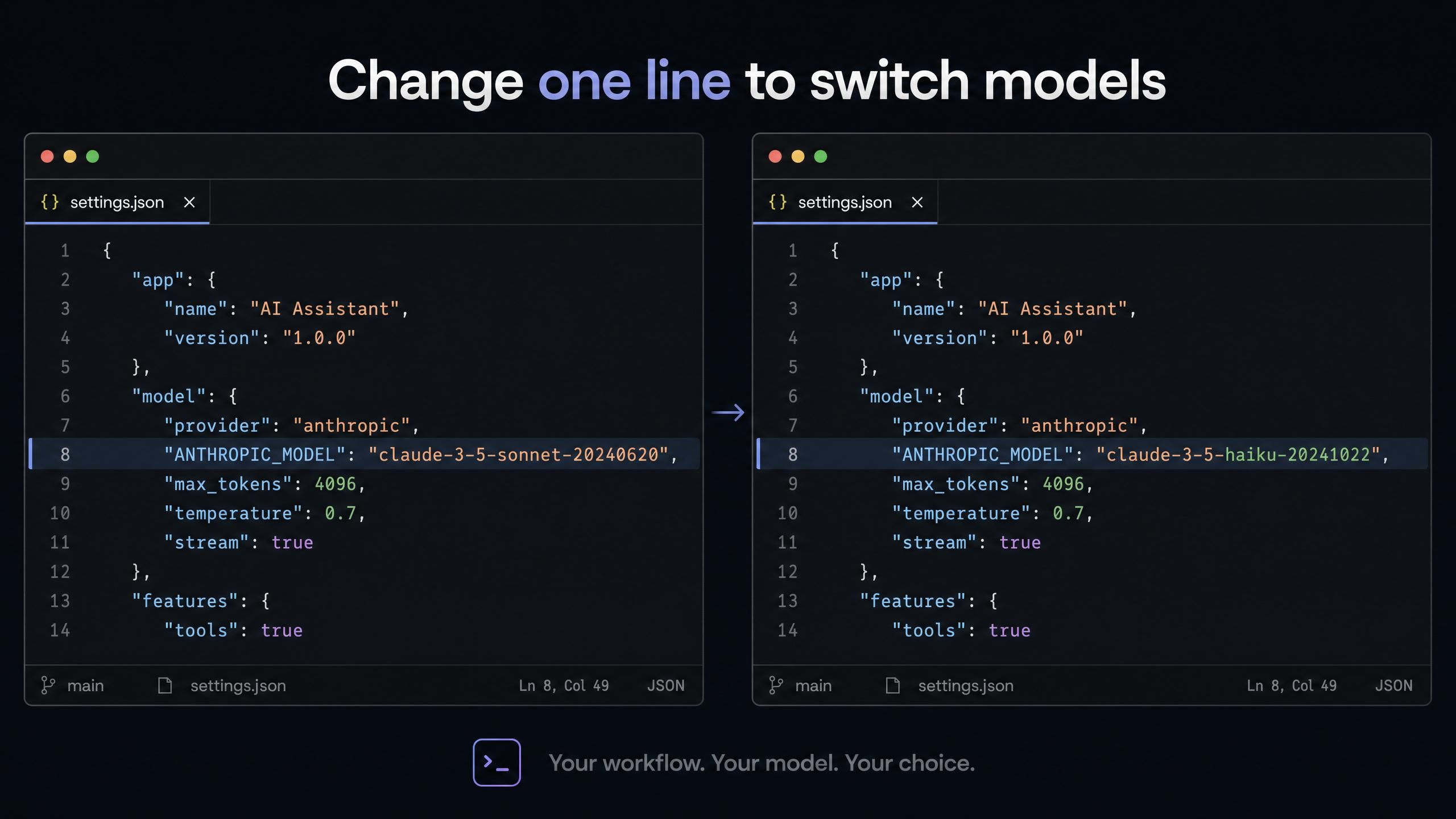
Claude Code (~/.claude/settings.json sur macOS/Linux) :
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "votre-clé-api-atlas", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "deepseek-ai/deepseek-v4-pro", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "deepseek-ai/deepseek-v4-flash", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "deepseek-ai/deepseek-v4-pro", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
Le champ ANTHROPIC_DEFAULT_HAIKU_MODEL correspond à l'emplacement de tâche d'arrière-plan de Claude Code. Mettre DeepSeek V4 Flash ici signifie que tous les appels utilitaires automatiques (lectures de fichiers, vérifications de statut, observations) utilisent le modèle le moins cher disponible. Vos invites principales utilisent V4 Pro. Vous obtenez un routage automatique sans aucune logique de routage.
Pour passer à GLM-5.1 au lieu de V4 Pro, remplacez deepseek-ai/deepseek-v4-pro par zai-org/glm-5.1 dans les deux champs Sonnet/main.
Codex (~/.codex/config.toml + ~/.codex/auth.json) :
plaintext1model_provider = "atlas_coding_plan" 2model = "deepseek-ai/deepseek-v4-pro" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
plaintext1{ 2 "OPENAI_API_KEY": "votre-clé-api-atlas" 3}
OpenClaw : Exécutez openclaw onboard, sélectionnez QuickStart, puis Custom Provider. Entrez https://api.atlascloud.ai/v1 comme URL de base, collez votre clé, puis entrez l'ID du modèle (par exemple moonshotai/kimi-k2.5) et choisissez le protocole compatible OpenAI.
Changer de modèle dans l'une de ces configurations est une modification d'une seule ligne. La clé API et l'URL de base restent les mêmes, quel que soit le modèle sélectionné.
Meilleur LLM de codage open source : questions courantes
DeepSeek est-il réellement le meilleur LLM de codage open source ?
Pour la plupart des développeurs débutants, DeepSeek V4 Pro est le premier choix naturel basé sur la couverture communautaire, l'historique des benchmarks et la combinaison d'une fenêtre de contexte de 1M avec une tarification compétitive. Mais le "meilleur" dépend fortement de votre type de tâche. Pour le travail à long contexte, Kimi K2.5 ou K2.6 offre 262 000 jetons à un tarif inférieur. Pour les tâches de sortie structurée, GLM-5.1 mérite d'être testé. Le point est que le "meilleur" change en fonction de ce que vous construisez.
Comment ces modèles se comparent-ils à Claude Sonnet ou GPT-4o sur le codage ?
Sur les benchmarks de codage standard, l'écart entre les meilleurs modèles open source et les modèles propriétaires américains s'est considérablement réduit depuis 2024. DeepSeek V3 a égalé Claude 3.5 Sonnet sur plusieurs benchmarks lors de sa sortie. Là où les modèles propriétaires gardent un avantage, c'est sur l'interprétation nuancée des instructions et les tâches qui bénéficient d'un réglage RLHF étendu. Pour la grande majorité des tâches de génération, de refactorisation et de débogage de code, la différence pratique pour la plupart des développeurs est minime.
Puis-je utiliser plusieurs LLM de codage open source dans le même pipeline ?
Oui. Lorsque tous les modèles partagent une URL de base et une clé API via une passerelle, vous pouvez spécifier un ID de modèle différent par requête. En pratique, cela signifie que vous pouvez utiliser DeepSeek V4 Flash pour une étape, Kimi K2.5 pour une autre et V4 Pro pour une troisième, le tout dans un seul flux de travail automatisé, sans gérer plusieurs comptes ou contextes d'authentification.
Quel modèle dois-je essayer en premier si je n'ai jamais utilisé de LLM open source ?
Commencez avec DeepSeek V4 Pro. Il possède la documentation la plus complète, la discussion communautaire la plus large et le profil de performance le plus clair. Une fois que vous avez établi une base de référence sur vos tâches réelles, testez Kimi K2.5 sur les étapes à contexte important et DeepSeek V4 Flash sur les appels utilitaires en arrière-plan. La différence de coût entre ces deux tests vous montrera si le routage de modèle est pertinent pour votre flux de travail.
Les LLM open source sont-ils sûrs pour le code d'entreprise ?
Cela dépend de votre modèle de déploiement. Pour un accès basé sur API via une passerelle tierce, les politiques de traitement des données de cette passerelle s'appliquent. Les modèles à poids ouverts qui peuvent être auto-hébergés vous donnent un contrôle total sur l'endroit où va votre code. Les développeurs sur r/LocalLLaMA ont discuté de cela de manière approfondie, et le consensus est que l'utilisation basée sur API nécessite le même examen du traitement des données que celui que vous appliqueriez à n'importe quelle API tierce, et non une catégorie de préoccupation spéciale.
L'essentiel sur les meilleurs LLM de codage open source
Cinq laboratoires proposent désormais des modèles capables de gérer un travail de codage en production sérieux, et ils couvrent une gamme de coûts et de capacités suffisamment large pour qu'une sélection de modèle universelle vous fasse perdre de l'argent.
Le playbook pratique : choisissez une passerelle qui vous donne accès à tous ces modèles sous une seule clé, établissez votre base de référence sur DeepSeek V4 Pro, puis utilisez le guide de routage ci-dessus pour déplacer les tâches plus simples vers des niveaux moins chers. Pour la plupart des développeurs effectuant des sessions de codage agentiques, ce routage seul réduit considérablement les coûts sans modifier la qualité de sortie sur les tâches qui comptent.
Spécifications et tarifs des modèles basés sur la documentation du plan de codage Atlas Cloud en mai 2026. Chiffres des benchmarks DeepSeek V3 issus du rapport technique DeepSeek-V3, décembre 2024. Les tarifs sont sujets à changement ; vérifiez les chiffres actuels auprès de chaque fournisseur avant de prendre une décision de facturation.






