
Si vous évaluez des modèles open-source pour le développement, le raisonnement ou les pipelines agentiques, Kimi K2.6 et GLM 5.1 figureront tous deux sur votre liste de présélection. Issus de laboratoires d'IA chinois de premier plan, ils fonctionnent tous deux avec des API compatibles avec OpenAI et sont performants sur les types de tâches complexes qui importent réellement aux développeurs.
Le problème, c'est qu'ils ne sont pas interchangeables. Ils possèdent des fenêtres de contexte différentes, des structures de coûts variées et des points forts qui se révèlent dans des cas d'usage spécifiques. Choisir le mauvais modèle pour votre charge de travail signifie soit sacrifier la performance, soit payer trop cher pour une capacité dont vous n'avez pas besoin.
Cet article détaille les véritables différences entre les deux modèles : ce que signifient concrètement les spécifications, où chaque modèle excelle (ou non), et à quoi ressemblent les chiffres lorsque vous les exécutez à grande échelle.

Kimi K2.6 vs GLM 5.1 : Le résumé rapide
Kimi K2.6 est le dernier modèle de Moonshot AI dans sa série K2, qui représente sa gamme phare actuelle. Moonshot est l'entreprise derrière l'assistant Kimi, et K2.6 est leur pari sur le raisonnement à long contexte et une tarification compétitive. Sa fenêtre de contexte de 262K est l'une de ses caractéristiques majeures.
GLM 5.1 provient de Zhipu AI, l'une des organisations de recherche en IA les plus établies en Chine. La série GLM (General Language Model) a évolué sur plusieurs générations, et 5.1 est l'offre haut de gamme actuelle de Zhipu. Elle jouit d'une solide réputation dans la communauté open-source pour la précision du suivi des instructions et la qualité de ses sorties structurées.
Les deux modèles exposent une API compatible avec OpenAI, ce qui facilite leur connexion à des outils comme Claude Code, Codex ou OpenClaw. Le choix entre les deux se résume à trois facteurs réels : la quantité de contexte dont vous avez besoin par requête, le coût des jetons selon votre volume attendu, et l'adéquation de vos tâches aux forces relatives de chaque modèle.
Les modèles derrière les noms
Comparaison des fenêtres de contexte : Kimi K2.6 vs GLM 5.1
La fenêtre de contexte est l'un des facteurs de différenciation les plus clairs et les plus objectifs. Kimi K2.6 prend en charge une fenêtre de contexte de 262K jetons, tandis que GLM 5.1 en supporte 200K. Il s'agit d'un écart de 31 % en capacité d'entrée maximale.
Pour les tâches de codage classiques, aucun modèle n'atteint ces limites au quotidien. Une revue de code standard, une session de débogage ou une requête de génération de documentation tiendront confortablement dans les deux fenêtres. L'écart devient significatif dans des scénarios précis :
- Analyse de bases de code volumineuses : passer des dizaines de milliers de lignes dans une seule requête pour du refactoring ou une revue d'architecture.
- Longues sessions agentiques : des conversations qui accumulent un contexte substantiel au fil de nombreux tours et appels d'outils.
- Pipelines documentaires lourds : tâches de recherche, de synthèse ou d'analyse nécessitant de gros blocs de texte dans un seul appel.
Si votre charge de travail approche régulièrement les limites de contexte avec d'autres modèles, la fenêtre de 262K de Kimi K2.6 vous offre une marge de manœuvre supplémentaire avant d'avoir à implémenter une logique de découpage (chunking) ou de résumé de contexte. Si vos requêtes habituelles sont inférieures à 50K jetons, les deux modèles offrent une capacité plus que suffisante et la différence de fenêtre n'est plus un facteur décisif.

Points forts en codage et raisonnement
Les deux modèles sont capables en matière de codage, bien que leurs priorités de conception entraînent des comportements différents en pratique.
Kimi K2.6 est conçu pour la compréhension de longs contextes. Cela le rend bien adapté au refactoring multi-fichiers, à la compréhension des impacts des changements sur différentes parties d'une base de code, et aux chaînes de raisonnement étendues où le modèle doit maintenir un état important sur de nombreuses étapes. Moonshot AI a positionné K2.6 spécifiquement autour de ces cas d'usage.
GLM 5.1 reflète l'accent mis par Zhipu AI sur le suivi précis des instructions et les sorties structurées. Des tâches comme générer du code à partir d'une spécification détaillée, produire des formats structurés à partir du langage naturel ou gérer des schémas d'appels d'outils complexes jouent en sa faveur. Le tarif de sortie légèrement plus élevé (7,99 vs 7,26) suggère également une tendance du modèle à fournir des complétions plus approfondies et détaillées.
Pour la plupart des développeurs, la différence de performance sur les tâches de codage habituelles est plus faible que ce que la marque pourrait laisser croire. Les différenciateurs les plus clairs résident dans les spécifications et les coûts, où les chiffres sont concrets.
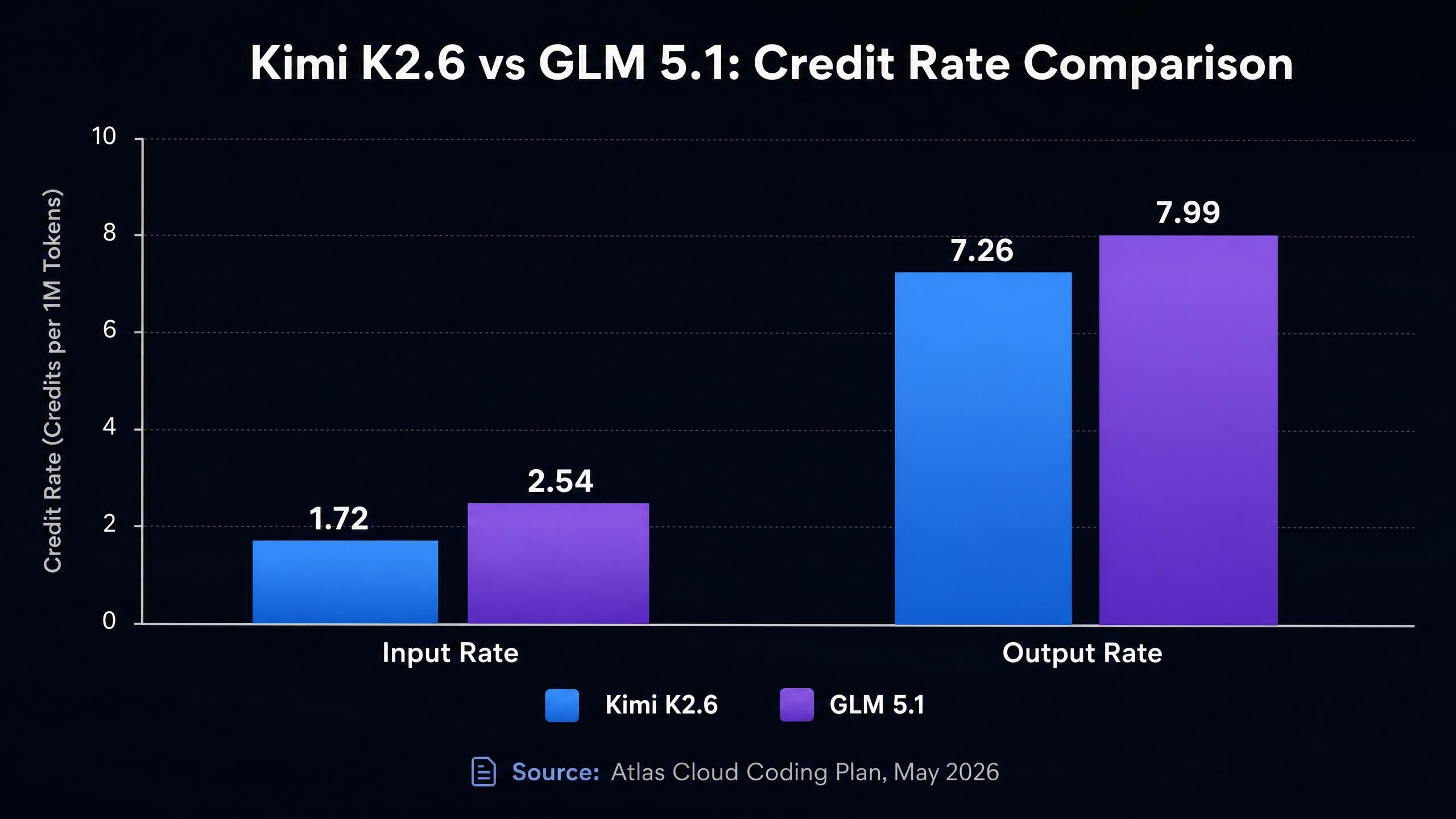
Kimi K2.6 vs GLM 5.1 : Coûts des jetons et taux de crédit
C'est ici que la comparaison devient précise. Les deux modèles sont disponibles via le Atlas Cloud Coding Plan (mai 2026) :
| Modèle | Contexte | Taux Entrée | Taux Sortie | Cache Write | vs. Officiel |
|---|---|---|---|---|---|
| Kimi K2.6 | 262K | 1.72 | 7.26 | 0.290 | 45% moins cher |
| GLM 5.1 | 200K | 2.54 | 7.99 | 0.472 | 45% moins cher |
Quelques points ressortent :
Le taux d'entrée de GLM 5.1 (2.54) est environ 48 % plus élevé que celui de Kimi K2.6 (1.72). Dans les contextes de codage où vous transmettez le contenu de fichiers, des historiques de code volumineux ou de longues conversations, les jetons d'entrée constituent souvent la majeure partie de vos coûts. Un pipeline exécutant 1 000 requêtes par jour avec 10K jetons d'entrée par requête coûterait environ 48 % de plus en entrée avec GLM 5.1 qu'avec Kimi K2.6.
Les tarifs de sortie sont plus proches mais favorisent toujours Kimi K2.6 (7,26 vs 7,99, environ 10 % d'écart). Les tarifs d'écriture en cache favorisent également Kimi K2.6 (0,290 vs 0,472), ce qui devient significatif dans les flux de travail utilisant le prompt caching pour des instructions système répétitives ou un contexte statique.
Pour comparer : pour une requête avec 5 000 jetons d'entrée et 1 000 jetons de sortie, les coûts en crédits sont :
- Kimi K2.6 : (5 000 × 1,72) + (1 000 × 7,26) = 8 600 + 7 260 = 15 860 crédits
- GLM 5.1 : (5 000 × 2,54) + (1 000 × 7,99) = 12 700 + 7 990 = 20 690 crédits
Kimi K2.6 est environ 23 % moins cher par requête selon ce ratio entrée/sortie. À haut volume, la différence budgétaire devient réelle.
Les deux modèles sont facturés 45 % en dessous de leurs tarifs API officiels via la passerelle.
Kimi K2.6 vs GLM 5.1 dans les flux de travail de codage agentique
Les outils agentiques amplifient chaque différence de coût et de capacité entre les modèles.
Dans un agent de codage multi-étapes, chaque appel d'outil est une requête API distincte. Chaque requête transporte le contexte d'entrée de la conversation accumulée, génère une sortie qui alimente l'étape suivante, et ajoute au coût de calcul total. Un flux de travail de 40 appels API ne coûte pas seulement 40 fois le prix d'une requête unique ; il accumule aussi rapidement du contexte, ce qui pousse les requêtes vers des nombres de jetons d'entrée plus élevés.
Où Kimi K2.6 tend à être plus performant : les longues sessions où le contexte accumulé devient important, les tâches impliquant la lecture et la modification de gros fichiers de code, et les pipelines où il est crucial de maintenir des coûts raisonnables. La fenêtre de contexte plus large signifie moins de réinitialisations de session.
Où GLM 5.1 tend à être plus performant : les pipelines où chaque étape nécessite une sortie précise et bien structurée et où la précision des instructions sur chaque appel individuel compte plus que la profondeur du contexte sur toute la session. Si votre agent doit générer du code selon des schémas de types stricts ou gérer des signatures de fonctions complexes, les forces de GLM 5.1 sont plus pertinentes.
Les deux modèles fonctionnent parfaitement avec Claude Code, Codex, OpenClaw et Cursor via des configurations compatibles OpenAI standards. L'intégration est identique ; seul l'identifiant du modèle change.
Comment tester les deux et choisir celui qui vous convient
Choisir sans deviner
La manière la plus fiable de décider n'est pas de lire des comparatifs, mais de tester les deux sur vos propres tâches. La bonne nouvelle est que c'est simple lorsque les deux modèles utilisent la même clé API et la même URL de base.
Le Atlas Cloud Coding Plan propose Kimi K2.6 et GLM 5.1 sur le même point de terminaison. Passer de l'un à l'autre est un changement de configuration d'une ligne.
Pour Claude Code sur macOS ou Linux, la configuration complète se trouve dans ~/.claude/settings.json. Configurez-le d'abord pour Kimi K2.6 :
plaintext1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "votre-cle-api-atlas", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "moonshotai/kimi-k2.6", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "moonshotai/kimi-k2.6", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "moonshotai/kimi-k2.6", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
Pour passer à GLM 5.1, remplacez moonshotai/kimi-k2.6 par zai-org/glm-5.1 dans les trois champs de modèle. Notez que l'URL de base de Claude Code est https://api.atlascloud.ai sans suffixe /v1.
Pour Codex, la configuration est divisée en deux fichiers. ~/.codex/config.toml :
plaintext1model_provider = "atlas_coding_plan" 2model = "moonshotai/kimi-k2.6" 3 4[model_providers.atlas_coding_plan] 5name = "atlascloud" 6base_url = "https://api.atlascloud.ai/v1" 7wire_api = "chat" 8requires_openai_auth = true
~/.codex/auth.json :
plaintext1{ 2 "OPENAI_API_KEY": "votre-cle-api-atlas" 3}
Pour OpenClaw, lancez openclaw onboard, choisissez QuickStart, puis Custom Provider. Entrez https://api.atlascloud.ai/v1 comme URL de base, collez votre clé Atlas et sélectionnez l'identifiant du modèle souhaité.
Questions fréquentes
Quel modèle coûte moins cher à grande échelle ? Kimi K2.6 est moins cher par jeton, tant en entrée qu'en sortie. L'écart est plus marqué sur l'entrée, ce qui est déterminant pour les flux de codage intensifs en contexte.
Quel modèle gère mieux le chinois ? Les deux ont de solides capacités, conformes à leurs origines. GLM 5.1 a un historique particulièrement établi sur les tâches en langue chinoise. Kimi K2.6 excelle également, orienté par la stratégie de Moonshot AI. Pour des tâches principalement en chinois, les deux sont robustes, avec un léger avantage pour GLM 5.1.
Puis-je mélanger les modèles dans le même pipeline ? Oui. Via une passerelle unifiée, vous pouvez router différentes étapes vers différents modèles en modifiant simplement le paramètre de modèle par requête. Vous pourriez utiliser Kimi K2.6 pour l'analyse à gros contexte et GLM 5.1 pour la génération de sorties structurées.
La différence de 262K vs 200K de contexte est-elle importante ? Pour la plupart des tâches de codage, non. La différence devient pertinente si vos sessions accumulent régulièrement 150-200K jetons, si vous passez de très gros fichiers ou si vous exécutez de longues sessions agentiques sans réinitialisation.
Verdict final : Kimi K2.6 vs GLM 5.1
Le choix dépend davantage de votre charge de travail que d'un vainqueur absolu.
Kimi K2.6 est l'option la plus rentable par défaut. Il est moins cher par jeton, gère plus de contexte et est parfaitement adapté aux tâches d'agents de codage gourmandes en données. Si vous optimisez les coûts à grande échelle, c'est le choix le plus fort.
GLM 5.1 justifie son prix légèrement plus élevé par sa précision dans le suivi des instructions et la cohérence de ses sorties structurées. Si votre pipeline nécessite une précision rigoureuse à chaque étape de génération, testez-le face à vos cas concrets.
L'approche pratique : commencez par Kimi K2.6 pour l'avantage tarifaire et la fenêtre de contexte, puis comparez avec GLM 5.1 si vous avez des besoins spécifiques en matière de structuration. Avec les deux modèles accessibles via Atlas Cloud Coding Plan à -45 % des tarifs officiels, le coût de comparaison est suffisamment faible pour laisser la performance guider votre décision.






