Les API de génération de vidéo par IA ont la réputation d'être capricieuses — et ce, pour une bonne raison. Les complétions de texte échouent immédiatement avec une erreur 400 en cas de problème. Le rendu vidéo est différent et plus imprévisible. Un job peut rester indéfiniment dans une file d'attente GPU sans avertissement. Il peut ne renvoyer que la moitié des clips demandés. Parfois, le rendu se termine parfaitement, mais la vidéo finale semble physiquement impossible ou déformée.
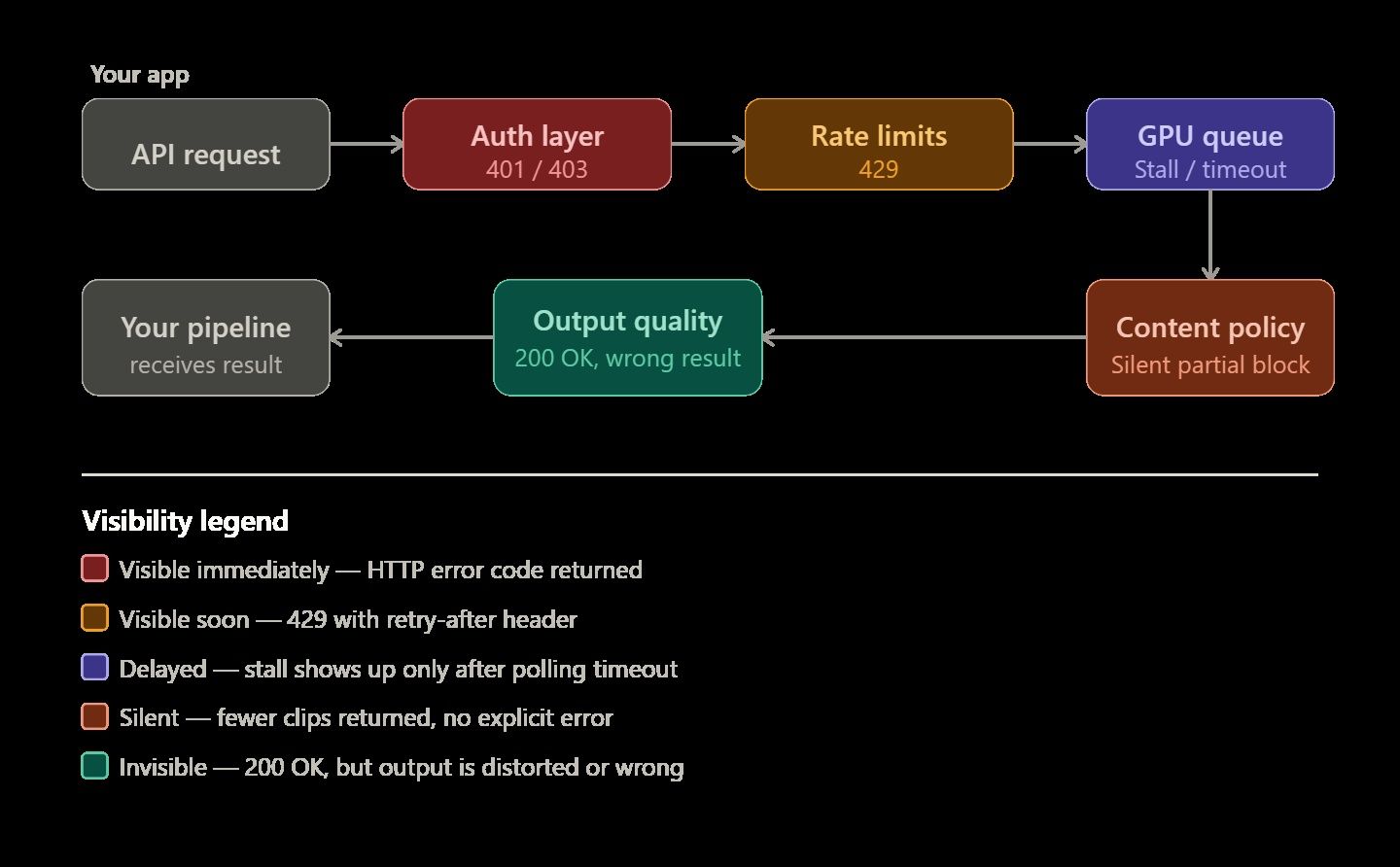
Vous devez comprendre pourquoi ces erreurs spécifiques surviennent pour construire un système fiable. Cette connaissance est la différence principale entre une simple démo et un pipeline vidéo qui fonctionne réellement pour des utilisateurs finaux.
Ce guide passe en revue les modes de défaillance les plus courants, explique comment lire les réponses API avec précision et présente des stratégies concrètes pour bâtir un pipeline de rendu vidéo moins coûteux et plus stable. Les exemples de code utilisent l'Atlas Cloud API, une plateforme d'inférence unifiée offrant un accès à plus de 300 modèles vidéo et multimodaux via un point de terminaison unique — ce qui en fait une référence utile pour les modèles multi-modèles.
Les cinq catégories d'erreurs d'API vidéo IA
Les erreurs de pipeline vidéo IA se répartissent généralement en cinq groupes spécifiques. Connaître la bonne catégorie vous aide à résoudre les problèmes plus rapidement, qu'il s'agisse de corriger votre code, de réécrire votre prompt ou simplement de patienter.
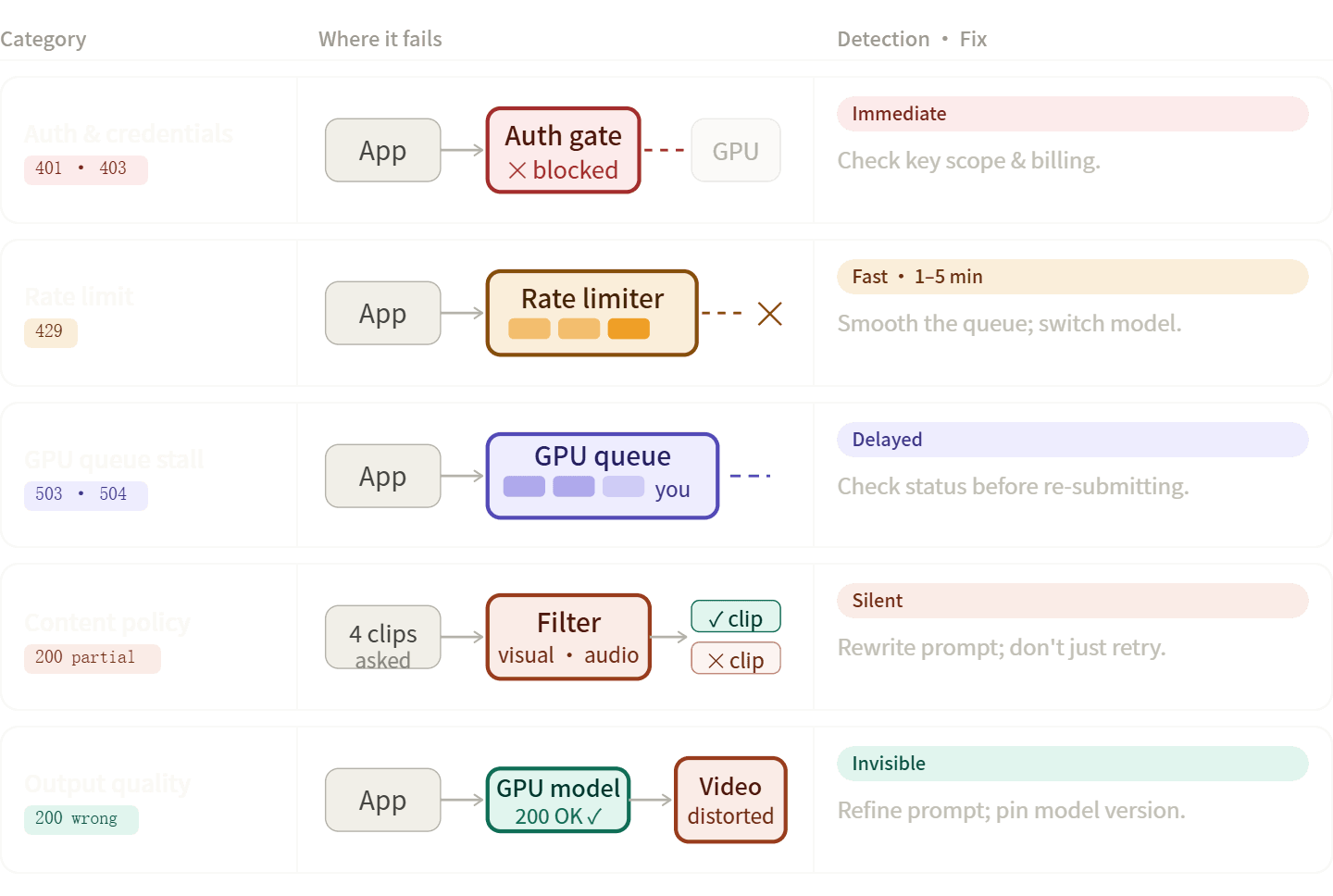
Erreurs d'authentification et d'identifiants (401, 403)
| Code | Cause typique | Correctif |
| 401 Unauthorized | En-tête Authorization: Bearer <key> manquant ou mal formé | Vérifiez que la clé est chargée depuis des variables d'env, pas codée en dur |
| 403 Forbidden (quota) | Crédits API épuisés | Ajoutez des fonds ou passez à un plan supérieur |
| 403 Forbidden (permission) | La clé n'a pas accès au modèle demandé | Régénérez une clé avec les permissions correctes |
Les utilisateurs sont souvent confus ici. Une erreur 403 pour dépassement de quota et une 403 pour droits insuffisants utilisent le même code mais nécessitent des solutions différentes. Ne vous contentez pas du numéro de statut. Lisez toujours le message d'erreur complet dans le corps de la réponse pour comprendre ce qui a échoué.
Sur des plateformes comme Atlas Cloud, une seule clé API couvre tous les modèles — ce qui signifie que la dérive d'authentification, où les clés du fournisseur A fonctionnent mais celles du fournisseur B ont expiré, n'existe tout simplement pas.
Erreurs de limitation de débit (429)
Les limites de débit dans les API vidéo sont plus punitives que dans les API de texte, car chaque requête monopolise un slot GPU pendant 30 à 90 secondes. Quelques requêtes simultanées peuvent saturer une limite qui semble généreuse sur le papier.
Distinctions clés à vérifier en premier :
- RPM (Requêtes par minute) : Les modèles de production sur l'API Veo 3.1 de Google autorisent 50 RPM ; les modèles en préversion plafonnent à 10 RPM avec un maximum de 10 requêtes simultanées par projet.
- Limites de requêtes simultanées : Même dans votre budget RPM, atteindre le plafond de simultanéité déclenche une erreur 429.
- TPM (Tokens par minute) : Moins courant pour la vidéo, mais pertinent sur les plateformes avec facturation unifiée entre les modalités.
Ce qui fonctionne réellement :
| Approche | Quand cela fonctionne | Quand cela ne fonctionne pas |
|---|---|---|
| Exponential back-off + retry | Erreurs 429 dues à des pics momentanés | Quand la simultanéité est le plafond réel |
| Lissage des pics / file d'attente | Pipelines de traitement par lots (batch) | UX interactive sensible à la latence |
| Planification hors pic (batchs nocturnes) | Flux de pré-génération de contenu | Génération en temps réel |
| Routage vers une variante moins chargée | Plateformes unifiées avec modèles équivalents | Configurations monoparavideur |
Rejets par les filtres de sécurité et politiques de contenu
Ces erreurs sont faciles à mal diagnostiquer car la réponse API n'est pas toujours une erreur claire — il se peut simplement que vous obteniez moins de clips que demandé. La documentation de Veo (Google) note explicitement que si le nombre de vidéos retournées est inférieur à celui demandé, certains résultats ont pu être bloqués par des filtres de sécurité plutôt que par une erreur de transport.
Deux surfaces de déclenchement distinctes :
- Prompts visuels : Sujet, contexte de la scène ou violence/contenu explicite implicite.
- Prompts audio/dialogue : Le contenu parlé, les demandes de chansons et les paysages sonores denses déclenchent des piles de filtrage distinctes.
Si votre clip échoue uniquement lorsque de l'audio fait partie du prompt, déboguez l'audio séparément de la scène visuelle. Réessayer un prompt bloqué par une politique de sécurité ne résout rien — il faut modifier le prompt.
Erreurs de transport et d'infrastructure (500, 503, 504)
| Code | Temps de résolution typique | Que faire |
|---|---|---|
| 429 RESOURCE_EXHAUSTED | 1 à 5 minutes | Back-off et réessayer |
| 503 Service Unavailable | 30 à 120 minutes | Attendre ; vérifier le dashboard d'état |
| 504 Gateway Timeout | Variable | Vérifier si le rendu est toujours en cours avant de soumettre |
| 500 Internal Server Error | Dépend du cas | Loguer l'ID de prédiction ; ne pas réessayer automatiquement sans vérifier le statut |
La règle critique pour les erreurs 500/504 : vérifiez si votre rendu est toujours en cours avant de soumettre à nouveau. Des tentatives aveugles sur une 504 peuvent entraîner des rendus en double et des coûts doublés.
Échecs de qualité de sortie
Ce ne sont pas des erreurs HTTP — l'API renvoie 200, mais la sortie est incorrecte. Formes courantes :
- Artefacts visuels ou imprécisions géométriques : La vidéo IA est probabiliste. Le modèle interprète les entrées au lieu de les calculer physiquement.
- Audio manquant sur les modèles compatibles : Généralement un problème de prompt ou de paramètre, pas une défaillance d'infrastructure.
- Durée ou résolution incorrectes : Déclenché par des combinaisons non prises en charge — tous les modèles ne supportent pas tous les couples durée/résolution.
- Pertes silencieuses dans le pipeline : Certains pipelines d'encodage rejettent discrètement des vidéos sous certains formats, ce qui n'apparaît qu'au moment du contrôle qualité (QA).
Lecture des réponses asynchrones : IDs de prédiction et sondage d'état (polling)
La génération de vidéo IA est asynchrone par conception. Le cycle requête-réponse comporte deux phases :
- POST sur le point de terminaison de génération → réception d'un
prediction_id - GET sur le point de terminaison de résultats avec cet ID → sondage (polling) jusqu'à un état terminal
Le schéma de réponse d'Atlas Cloud illustre ce à quoi ressemble une prédiction terminée :
plaintext1{ 2 "id": "pred_abc123", 3 "status": "completed", 4 "model": "bytedance/seedance-2.0/text-to-video", 5 "outputs": ["https://storage.atlascloud.ai/outputs/result.mp4"], 6 "metrics": { "predict_time": 45.2 }, 7 "created_at": "2025-01-01T00:00:00Z", 8 "completed_at": "2025-01-01T00:00:45Z" 9}
Les trois états terminaux :
| Statut | Signification | Action |
|---|---|---|
| completed | Rendu réussi ; sorties disponibles | Télécharger avant expiration |
| failed | Rendu échoué ; consulter le champ d'erreur | Loguer l'erreur ; décider d'une nouvelle tentative |
| expired | Sorties indisponibles | Soumettre à nouveau si besoin |
L'erreur de polling la plus courante
Les développeurs vérifient régulièrement si status === "failed" mais ne lisent jamais le champ error qui suit. C'est là que se trouve l'information exploitable — sans elle, vous savez qu'un rendu a échoué, mais pas si vous devez corriger le prompt, vérifier votre quota ou attendre que l'infrastructure se rétablisse.
Modèle de polling prêt pour la production
plaintext1import time 2import requests 3 4def poll_prediction(prediction_id: str, api_key: str, max_wait: int = 600) -> dict: 5 url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 6 headers = {"Authorization": f"Bearer {api_key}"} 7 terminal_states = {"completed", "failed", "expired"} 8 wait = 5 9 10 for _ in range(max_wait // wait): 11 resp = requests.get(url, headers=headers).json() 12 status = resp.get("status") 13 14 if status in terminal_states: 15 if status == "failed": 16 print(f"Le rendu a échoué: {resp.get('error')}") 17 return resp 18 19 time.sleep(wait) 20 wait = min(wait * 1.5, 60) # plafonner le back-off à 60s 21 22 raise TimeoutError(f"La prédiction {prediction_id} n'a pas été terminée en {max_wait}s")
Loguez metrics.predict_time à chaque rendu terminé. Les pics dans cette valeur sont un indicateur précoce de dégradation de l'infrastructure — un signal utile avant même de voir apparaître des erreurs franches.
Structuration d'un pipeline de rendu résilient
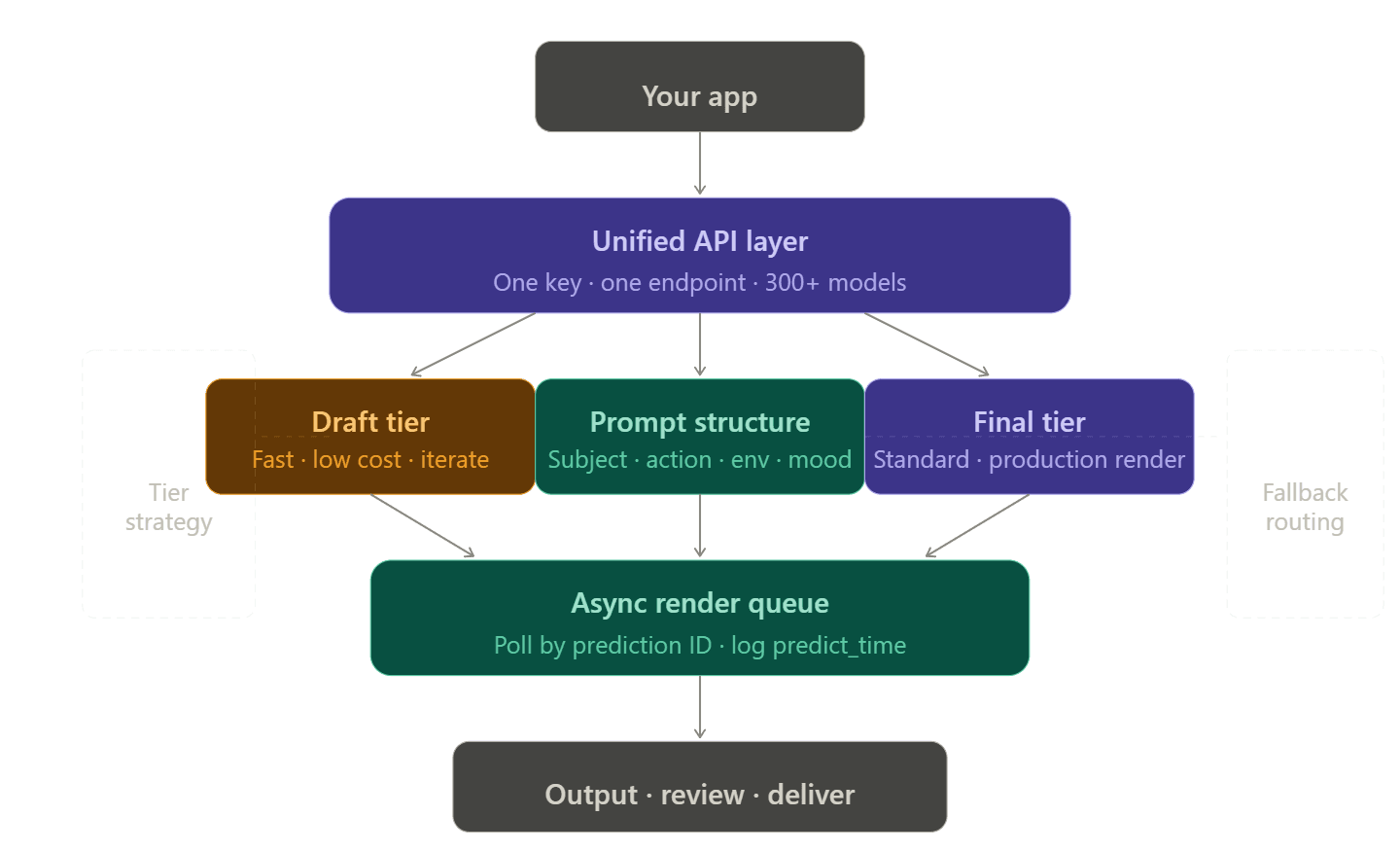
Architecture API unique vs multi-fournisseurs
Gérer plusieurs comptes, jetons et pages de facturation pour chaque fournisseur vidéo est un vrai cauchemar. Les développeurs appellent cela la "taxe d'intégration". Cela empire rapidement. Si un modèle atteint une limite, vous avez besoin d'une solution de secours. Cette solution nécessite alors sa propre clé API, sa propre configuration de facturation et du code personnalisé pour gérer les erreurs.
Les plateformes API unifiées éliminent cela en routant plusieurs fournisseurs via un point de terminaison unique. Sur Atlas Cloud, passer de openai/sora-2/text-to-video à bytedance/seedance-2.0/text-to-video nécessite de changer une seule chaîne de caractères — les en-têtes, l'authentification et la facturation restent identiques.
Hiérarchisation : du brouillon au rendu final
L'un des leviers les plus puissants pour améliorer les coûts et la fiabilité est simplement de choisir le niveau de modèle adapté à chaque étape du workflow :
| Étape | Niveau recommandé | Pourquoi ? |
|---|---|---|
| Exploration de prompt / tests de concept | Niveau Rapide / Économique | -78% de coût vs Standard ; erreurs détectées à moindre frais |
| Brouillons pour revue interne | Niveau Rapide | Suffisant pour la validation des parties prenantes |
| Rendu final de production | Niveau Standard / Pro | La différence de qualité justifie le coût |
| Contenu par lots (réseaux sociaux) | Niveau Rapide | Le volume rend l'écart de coût significatif |
Sur Atlas Cloud, le niveau Fast de Seedance 2.0 coûte 0,081 $/sec contre 0,10 $/sec pour le Standard — une différence qui s'additionne rapidement à grande échelle. Une équipe générant 200 clips de 10 secondes par mois dépenserait 162 $ en Fast contre 200 $ en Standard pour le même jeu de prompts.
Le prompt engineering comme prévention des erreurs
Les prompts vagues sont une source sous-estimée de défaillances de pipeline. Un prompt comme « une personne qui marche » force le modèle à faire trop de choix arbitraires, produisant un résultat incohérent qui nécessite plus de tentatives.
Une structure de prompt fiable en 4 composants :
plaintext1[Sujet + détail] + [Action + style de mouvement] + [Environnement + éclairage] + [Caméra + ambiance] 2 3Exemple : 4"Une femme en manteau rouge marchant d'un pas vif dans une rue de Tokyo sous la pluie la nuit, 5reflets néon sur le pavé mouillé, plan de suivi moyen, cinématographique et tendu"
Lors de l'utilisation de modèles supportant l'entrée multimodale — Seedance 2.0 accepte jusqu'à 12 fichiers de référence (images, clips vidéo et audio) — fournir des références visuelles réduit l'ambiguïté qui conduit à des échecs de qualité de sortie.
Choisir le bon modèle
Tous les outils de vidéo IA n'échouent pas pour les mêmes raisons, car ils sont conçus pour des objectifs différents. Utiliser le mauvais modèle pour votre tâche spécifique est une erreur majeure. Cela conduit à des résultats médiocres qui ressemblent à des bugs techniques, alors que le modèle n'est simplement pas fait pour ce travail.
Référence des capacités des modèles
| Modèle | Point fort | Attention à | Prix (Atlas Cloud) |
|---|---|---|---|
| Wan 2.7 | Simulation physique, interaction réaliste | Référence image unique seulement ; coût plus élevé | 0,1 $/sec |
| Kling 3.0 | Sortie haute résolution ; synchro labiale native ; niveau gratuit | Temps de génération plus longs en résolution max | 0,071–0,143 $/sec |
| Veo 3.1 | Qualité cinématographique ; conformité sécurité stricte | Limites de débit du modèle en preview (10 RPM) | 0,05–0,20 $/sec |
| Seedance 2.0 | Contrôle via références multiples ; audio natif | Nécessite une construction de prompt plus soignée | 0,081–0,10 $/sec |
| Wan 2.6 | Coût le plus bas ; contenu haut volume | Pas d'audio natif ; max 1080p | 0,018–0,07 $/sec |
Tarifs issus de la documentation Atlas Cloud, avril 2026. Pour les tarifs spécifiques, veuillez consulter le site officiel.
Quand changer de modèle vs corriger la requête
Changez de modèle si :
- Les clips échouent systématiquement uniquement lorsque l'audio ou le dialogue est dans le prompt ; le modèle manque peut-être de capacités audio.
- La qualité de la physique ou de l'interaction objet est le point d'échec, pas le prompt.
- Vous êtes sur un modèle en preview atteignant des limites de débit qu'un modèle de production n'atteindrait pas.
Corrigez le prompt si :
- La sortie est stylistiquement décalée mais structurellement correcte.
- Les filtres de sécurité se déclenchent sur un langage spécifique.
- Les paramètres de durée ou de résolution sont rejetés.
Fixez une chaîne de version spécifique (par ex. kling-v3.0-std et non kling-latest). Les mises à jour silencieuses des modèles peuvent introduire des régressions de qualité quasi impossibles à déboguer sans verrouillage de version.
Votre boîte à outils de débogage
Que loguer à chaque étape ?
Le logging est le moyen le plus rapide de réduire de moitié le temps de débogage. Un log efficace capture à minima :
Lors de la requête :
- ID et version du modèle
- Hash du prompt (pas le prompt complet — garde les logs compacts)
- Paramètres de durée, résolution et mode
- Timestamp
À la réponse :
- ID de prédiction
- Statut initial
- Tout message d'erreur immédiat
À la fin du sondage :
- Statut final
predict_timeissu des métriques- Contenu du champ erreur (si échec)
- URL de sortie (si terminé)
Distinction entre erreurs d'infrastructure et d'application
Lorsqu'une génération échoue, une séquence de diagnostic rapide fait gagner du temps :
- Vérifiez le dashboard de santé de l'API — si la plateforme est dégradée, vous déboguez le mauvais problème.
- Lisez les en-têtes de réponse
x-deny-reason— les refus de proxy en sortie apparaissent ici et ressemblent à des erreurs de modèle sans cet en-tête. - Vérifiez les erreurs CORS si vous appelez depuis un frontend — elles produisent les mêmes symptômes que les erreurs d'auth dans les DevTools du navigateur.
- Vérifiez les contraintes de fichiers avant de supposer une erreur de modèle — la plupart des plateformes imposent une taille de fichier d'entrée maximale (souvent 16 Mo) et un jeu limité de formats acceptés.
Le panneau de monitoring d'Atlas Cloud affiche le statut de mise à l'échelle automatique (auto-scaling) et les données d'usage par requête, ce qui aide à distinguer une journée d'infrastructure lente d'un problème de prompt ou de code.
Optimisation des coûts
Les trois leviers
Le coût de rendu est le produit de trois variables. Optimiser les trois simultanément — plutôt que de simplement choisir un modèle moins cher — produit les économies les plus importantes :
| Levier | Choix économique | Choix coûteux | Multiplicateur typique |
|---|---|---|---|
| Niveau modèle | Fast | Standard/Pro | 3–5× |
| Durée | 4–5 secondes | 12–15 secondes | 3× |
| Résolution | 720p | 4K | 2–4× |
Un seul rendu 4K Standard de 8 secondes peut coûter 6 à 8 fois plus cher qu'un équivalent 720p Fast de même durée. Si votre canal de distribution est les






