Google Gemini Omni est un modèle d'IA tout-en-un conçu par Google DeepMind, présenté lors de la conférence Google I/O le 19 mai 2026. Sa plus grande avancée est la multimodalité native. Cela signifie qu'il traite et crée du texte, des images, du son et de la vidéo au sein d'un seul et même système, plutôt que de connecter différents outils entre eux. Il est conçu pour les créateurs, les développeurs et les entreprises qui souhaitent réaliser et monter des vidéos via une simple conversation, sans changer d'application.
Un aperçu des fonctionnalités de Gemini Omni repose sur une idée simple : créer n'importe quoi à partir de n'importe quelle entrée. Contrairement aux outils d'IA de text-to-video classiques, Omni combine la capacité de raisonnement de Gemini avec un rendu multimédia avancé en une seule passe.
Vue d'ensemble des capacités clés
| Fonctionnalité | Détail |
|---|---|
| Entrées acceptées | Texte, image, audio, vidéo |
| Sortie principale | Vidéo (images et audio bientôt disponibles) |
| Style de montage | Conversationnel, requêtes multi-tours |
| Premier modèle | Gemini Omni Flash |
| Disponibilité | Abonnés Google AI Plus, Pro & Ultra |
Comment y accéder
- Application Gemini — Abonnés AI Plus/Pro/Ultra dans le monde entier
- Google Flow — flux de travail complets pour les courts-métrages
- YouTube Shorts / YouTube Create — création de contenu court
- API développeur — disponible d'ici quelques semaines
Qu'est-ce que Google Gemini Omni et comment fonctionne-t-il ?
Google Gemini Omni représente un bond en avant considérable. Il s'agit du principal modèle d'IA créative tout-en-un de Google DeepMind. Révélé lors de la Google I/O 2026, le système traite simultanément le texte, les images, le son et la vidéo pour produire du contenu vidéo de haute qualité. Il remplace officiellement Veo au sein de l'écosystème Gemini.
Le moteur principal : explication de la multimodalité native
La plupart des outils vidéo par IA précédents suivaient un pipeline séquentiel : conversion de l'entrée en descriptions textuelles, puis envoi de ces descriptions vers un moteur de rendu vidéo distinct. Gemini Omni fonctionne différemment. Il repose sur un modèle multimodal natif, capable de traiter tous les types de médias simultanément au sein d'un seul moteur central, plutôt que de les faire transiter par des étapes isolées.
C'est essentiel, car l'absence de couches de conversion permet au modèle de conserver un contexte plus riche. Lorsque vous fournissez une photo de référence avec un prompt textuel, Omni raisonne sur les deux éléments simultanément, préservant ainsi des détails visuels qui seraient normalement perdus lors d'une étape de conversion en texte.
À quoi ressemble l'entrée multimodale de Gemini Omni en pratique ?
L'entrée multimodale de Gemini Omni prend en charge les combinaisons suivantes dans un seul prompt :
| Type d'entrée | Exemple d'utilisation |
|---|---|
| Texte uniquement | Décrire une scène à partir de rien |
| Image + Texte | Animer une photo fixe avec une instruction écrite |
| Vidéo + Texte | Modifier un clip existant de manière conversationnelle |
| Audio + Texte | Guider le ton parallèlement à un prompt visuel |
| Mixte (les quatre) | Combiner clips de référence, images de style et narration |
Traitement en temps réel et contrôle conversationnel
Comme le raisonnement s'effectue au sein d'un seul modèle, le traitement en temps réel des instructions de montage devient concret. Omni affine les résultats via une conversation multi-tours : changez un arrière-plan, ajustez l'éclairage ou stabilisez un plan en décrivant simplement le changement souhaité. Aucune nouvelle génération à partir de zéro n'est requise.
Nicole Brichtova, de Google DeepMind, l'a décrit comme "bien plus qu'une simple mise à jour de Veo" : c'est la fusion du raisonnement de Gemini et du rendu média en un seul système cohérent.
IA de montage vidéo conversationnel : comment utiliser Gemini Omni pour une modification avancée des éléments
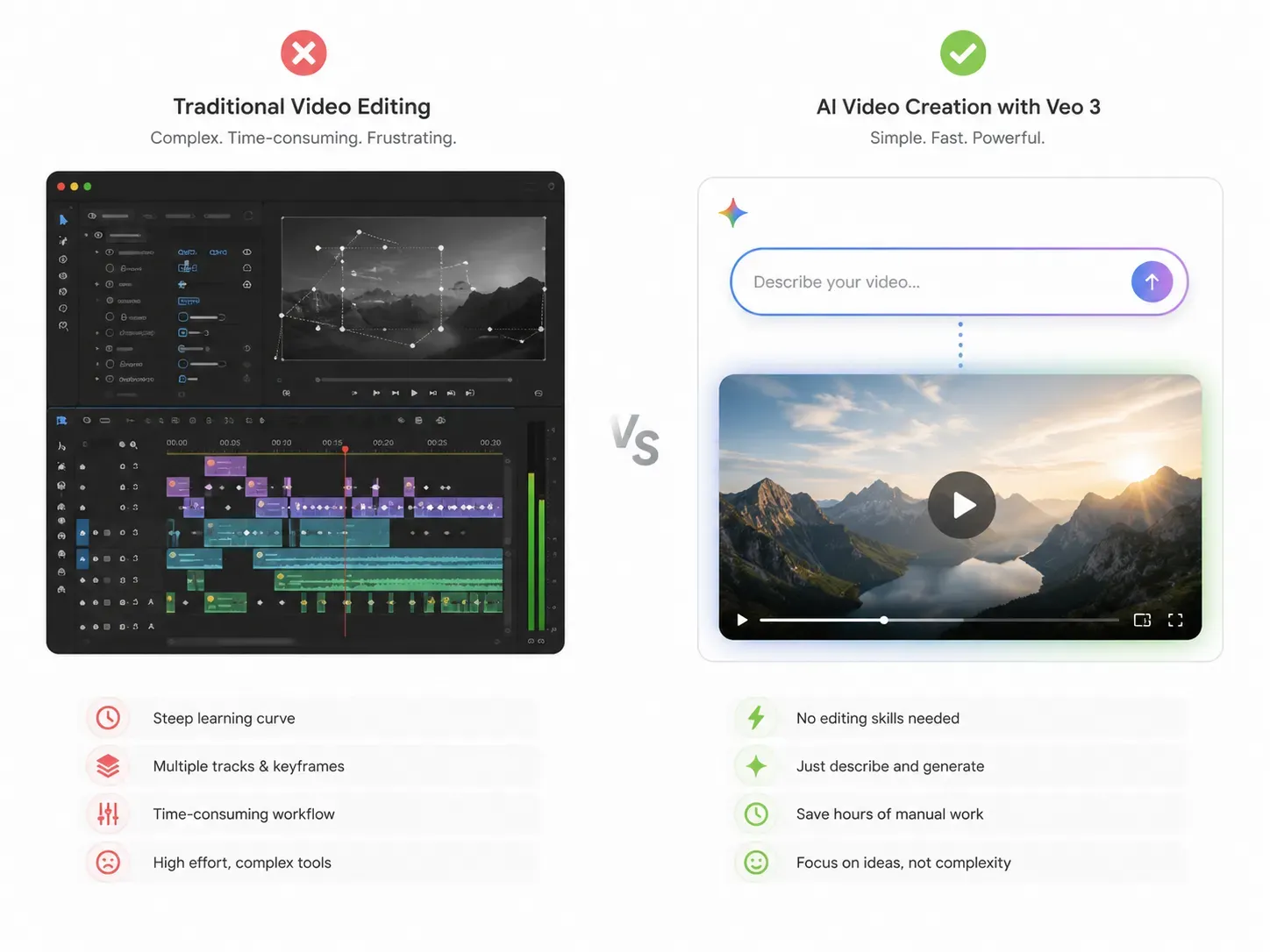
Comprendre l'architecture est une chose, la mettre en pratique en est une autre. C'est là que la capacité d'IA de montage vidéo conversationnel de Gemini Omni se distingue des outils conventionnels.
Les éditeurs vidéo traditionnels exigent des timelines, des calques et une image-clé manuelle. Gemini Omni remplace entièrement ce flux de travail. Importez vos images, tapez ou dites ce qui doit être modifié, et le modèle effectue le rendu du clip. Pas de plugins. Pas de logiciels externes.
Gemini Omni peut-il gérer le remplacement complexe d'éléments vidéo par IA ?
Oui, et c'est l'une de ses fonctionnalités les plus pratiques. Selon la documentation officielle de Google, les tâches de modification d'actifs vidéo prises en charge incluent :
- Changement d'arrière-plan — remplacez l'environnement derrière un sujet tout en préservant le personnage.
- Changements de style et de garde-robe — modifiez les vêtements ou transférez un style visuel sur tout un clip.
- Substitution d'objets — échangez un élément spécifique dans une scène en milieu de plan.
- Ajustements d'éclairage — changez l'ambiance ou l'intensité de l'éclairage via une seule instruction.
- Stabilisation vidéo — adoucissez des images tremblantes grâce à un prompt en langage clair.
- Changement de personnage — remplacez un sujet par un autre en utilisant une image de référence.
Montage vidéo interactif via conversation multi-tours
Ce qui rend ce montage vidéo interactif — par opposition à une génération unique — est la boucle multi-tours. Chaque instruction de modification s'appuie sur la précédente, permettant au modèle de maintenir la cohérence de la scène (même arrière-plan, logique d'éclairage et identité du personnage) au fil des itérations.
Par exemple, un créateur peut d'abord demander : "remplace l'arrière-plan par une rue urbaine", puis ajouter "rend l'éclairage plus chaud", et enfin "stabilise le plan" — tout cela sans jamais relancer la génération.
Remplacement d'éléments vidéo par IA : à quoi s'attendre aujourd'hui
Le remplacement d'éléments vidéo par IA dans le modèle actuel Gemini Omni Flash cible des clips de 10 secondes. Des modifications d'actifs vidéo plus complexes sur des formats plus longs — ainsi que des types de sorties supplémentaires comme des images et de l'audio isolés — sont prévus pour les prochaines versions.
Maîtrisez la boucle multi-tours : guide de prompting pour Gemini Omni
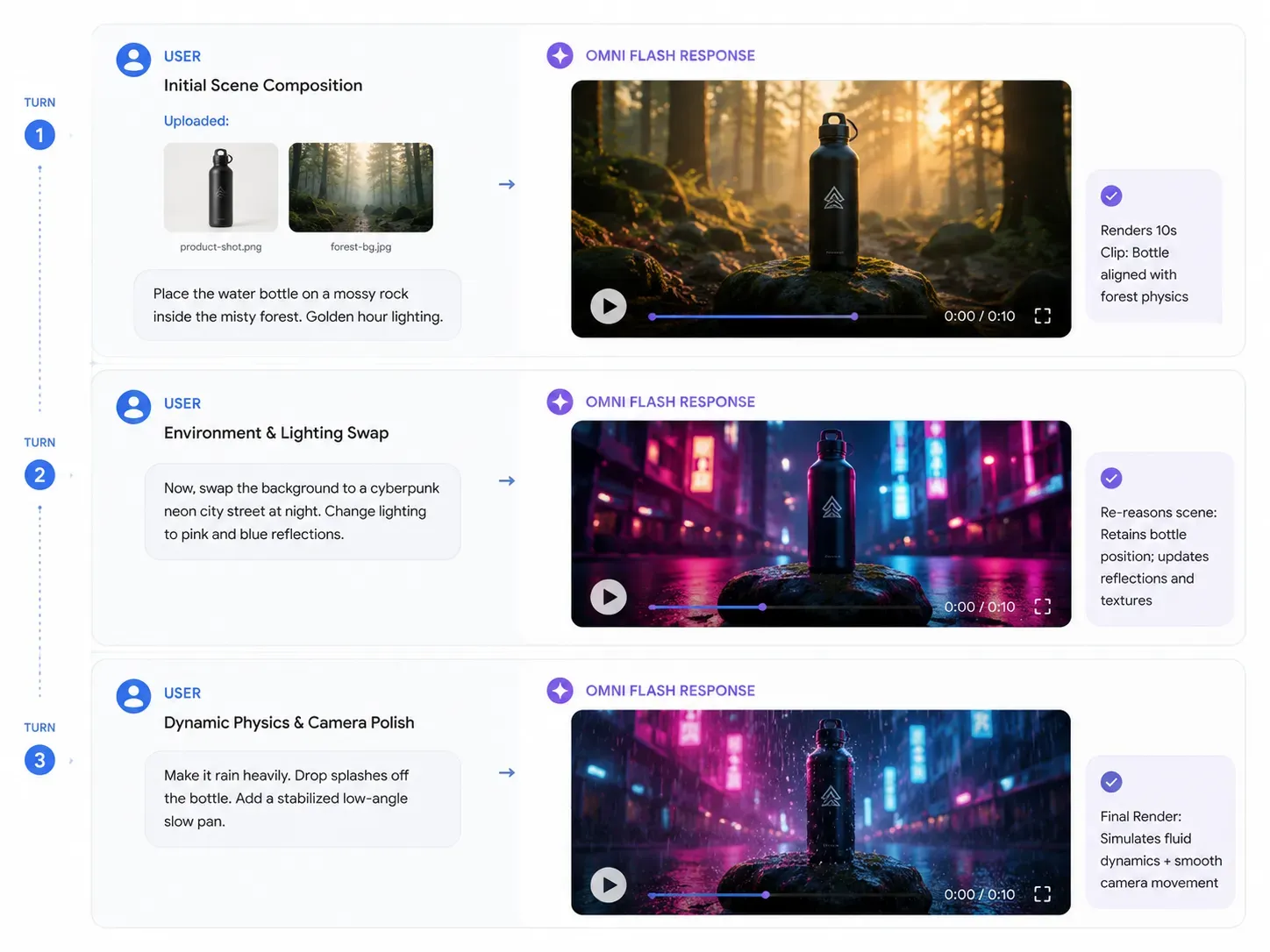
Pour libérer tout le potentiel de la multimodalité native de Gemini Omni, votre stratégie de prompting doit passer de la génération unique à une conversation continue. Comme le moteur de physique du modèle conserve la logique environnementale, vous pouvez superposer les instructions étape par étape.
Voici un blueprint prêt à l'emploi pour un flux de travail de création commerciale type :
Tour 1 : L'entrée de référence initiale
Actifs d'entrée : Téléchargez brand-product-shot.png (une bouteille d'eau métallique) et background-reference.jpg (une forêt brumeuse).
Prompt : "Génère une vidéo promotionnelle cinématographique de 10 secondes. Place la bouteille d'eau métallique de l'image produit sur un rocher couvert de mousse dans la forêt brumeuse. Règle l'éclairage sur une lumière dorée du petit matin."
Sortie IA attendue : Omni raisonne sur les deux images simultanément, plaçant la bouteille de manière réaliste sur le rocher avec un poids et des ombres portées cohérents avec les lois de la physique.
Tour 2 : La modification dynamique des actifs
Contexte d'entrée : Discussion continue au sein de la même session (aucun réimport nécessaire).
Prompt : "Maintenant, change l'arrière-plan. Remplace la forêt brumeuse par une rue de ville cyberpunk minimaliste avec des néons de nuit. Change l'éclairage pour des reflets néon bleu froid et rose vif sur la surface métallique de la bouteille."
Sortie IA attendue : L'environnement change instantanément. Point crucial : la position de la bouteille sur le rocher reste cohérente, mais les reflets sur sa surface s'ajustent dynamiquement pour refléter les nouvelles sources lumineuses.
Tour 3 : La finition physique
| Action de prompt | Commande cible |
|---|---|
| Ajout de physique environnementale | "Fais commencer une pluie battante dans la scène. Assure-toi que les gouttes d'eau éclaboussent de façon réaliste le haut de la bouteille et que des rides se forment sur le sol." |
| Contrôle de caméra | "Panote lentement la caméra d'un angle bas vers le haut et applique une stabilisation vidéo en langage courant pour fluidifier la transition." |
Bien que la maîtrise de la boucle multi-tours dans Google Flow optimise votre pipeline de prompts, les développeurs qui gèrent des flux multi-modèles nécessitent souvent une plus grande flexibilité. L'implémentation d'API d'IA multimodale unifiée permet à des plateformes comme Atlas Cloud de servir plus de 300 modèles — incluant des moteurs avancés de vidéo, d'image et de raisonnement LLM — sous une seule couche d'orchestration.
Simulation de la réalité : le pouvoir du moteur physique du modèle mondial de Gemini Omni
Le montage conversationnel ne produit de bons résultats que lorsque le modèle comprend pourquoi une scène a l'aspect qu'elle a. C'est là que la couche de physique du modèle mondial de Gemini Omni devient critique.
Lors de la Google I/O 2026, le PDG de Google DeepMind, Demis Hassabis, a décrit Gemini Omni non pas comme un simple générateur vidéo, mais comme un modèle mondial — un système qui construit une compréhension interne de la réalité et raisonne sur ce qui devrait se produire ensuite dans n'importe quelle scène donnée.
Ce que signifie "modèle mondial" en pratique

La plupart des anciens outils d'IA vidéo prédisaient l'image suivante en faisant correspondre des pixels à grande échelle. Ils produisaient des séquences qui semblaient réelles mais ne se comportaient pas de manière cohérente : les personnages se transformaient entre les coupes, les ombres ignoraient les sources lumineuses et les fluides se déplaçaient comme des textures plutôt que comme de la matière.
Gemini Omni est entraîné différemment. Selon Google, le modèle intègre une compréhension réelle de la physique, du mouvement et de l'IA de conscience spatiale pour ancrer ses sorties dans le fonctionnement réel du monde physique.
Propriétés physiques que Gemini Omni est entraîné à simuler
Google affirme que le modèle possède une compréhension intuitive des propriétés suivantes, s'appuyant sur Genie — la plateforme de simulation de mondes de jeu de DeepMind :
| Propriété physique | Effet pratique en vidéo |
|---|---|
| Gravité | Les objets tombent et atterrissent avec un poids précis |
| Énergie cinétique | L'élan est conservé lors des collisions |
| Dynamique des fluides | L'eau, la fumée et les liquides se comportent naturellement |
| Cohérence de l'éclairage | Les ombres se déplacent correctement lors des modifications |
| Anatomie spatiale | Les proportions des personnages restent cohérentes entre les coupes |
Pourquoi cela est crucial pour une génération vidéo cohérente
Lors de la keynote de l'I/O 2026, cette couche a été mise à l'épreuve en créant une animation en pâte à modeler extrêmement précise du repliement des protéines — prouvant que le modèle dépasse la simple correspondance de pixels pour comprendre la réalité scientifique et spatiale.
Cette base de modèle mondial est ce qui permet une génération vidéo cohérente lors des éditions multi-tours. Lorsqu'un utilisateur change un arrière-plan ou ajuste l'éclairage, le modèle ne se contente pas de composer une nouvelle couche : il raisonne à nouveau sur la relation physique entre le sujet, le nouvel environnement et la source lumineuse. Le résultat est une simulation de la réalité physique au niveau de la scène plutôt qu'un simple rapiéçage de pixels.
Le changement de paradigme : correspondance de pixels vs simulation mondiale
| Anciens outils d'IA vidéo (ancienne ère) | Google Gemini Omni (Modèle mondial) |
| ❌ Manque de logique ; prédit simplement la probabilité statistique du prochain groupe de pixels. | 🧠 Comprend la masse des objets, l'élan cinétique et la conservation de l'énergie des fluides. |
| ❌ Les ombres se déforment et les textures se déchirent dynamiquement dès que l'angle de caméra change. | 🧠 Simule l'éclairage global, garantissant que les rayons lumineux et les reflets réfractent naturellement. |
| ❌ L'anatomie des personnages et les structures d'arrière-plan se distordent après 3 à 5 secondes. | 🧠 Conserve un environnement unifié, une logique d'éclairage et une identité sur des éditions multi-tours. |
Avatars numériques personnalisés : Gemini Omni peut-il créer un avatar IA pour les créateurs ?
La physique du modèle mondial rend les séquences générées réalistes. La fonctionnalité d'avatar, elle, les rend conformes à votre propre image.
Gemini Omni peut-il créer un avatar IA ? Oui. Gemini Omni Flash inclut un outil dédié qui permet aux créateurs de construire une représentation numérique d'eux-mêmes — en utilisant leur propre apparence et leur voix — et de les déployer directement dans des vidéos générées sans avoir à importer de matériel de référence à chaque fois.
![]()
Comment fonctionne l'intégration d'avatar ?
Pour prévenir toute utilisation abusive, Google a ajouté une étape de vérification structurée avant la création de l'avatar. Selon TechCrunch, les utilisateurs doivent suivre un processus d'onboarding dédié qui implique de s'enregistrer en lisant une série de nombres. Cette ressemblance enregistrée est ensuite stockée et réutilisée pour les sessions futures.
Le montage vocal complet de clips tiers existants reste en cours d'examen pendant que Google travaille sur un déploiement responsable. Tous les avatars numériques personnalisés et les vidéos générées comportent le filigrane numérique Google SynthID, vérifiable via l'application Gemini, Gemini dans Chrome et la recherche Google.
Comment Gemini Omni s'intègre-t-il à YouTube Shorts et Google Flow ?
Le tableau ci-dessous indique l'accès actuel par plateforme :
| Plateforme | Niveau d'accès | Notes |
|---|---|---|
| Application Gemini | Abonnés AI Plus, Pro & Ultra | Fonctionnalités complètes d'Omni Flash, y compris avatar |
| Plateforme Google Flow | Abonnés AI | Inclut Flow Agent, traitement par lots, Flow Music |
| Outils créateur YouTube Shorts | Gratuit, sans abonnement | Déploiement la semaine de Google I/O 2026 |
| Application YouTube Create | Gratuit | Même calendrier de déploiement que Shorts |
| API développeur | Disponible dans quelques semaines | Accès entreprise et Google AI Studio |
La plateforme Google Flow a reçu des mises à jour supplémentaires aux côtés d'Omni Flash : un "Flow Agent" pour le brainstorming et la génération par lots, une fonctionnalité d'outils personnalisés pour des flux de travail sans code partageables, et la prise en charge de Flow Music pour la création complète de clips musicaux et la transformation de style.
Sécurité du contenu et origine : comment le filigrane vidéo Google SynthID protège les médias
La création d'avatars puissants et les outils de montage vidéo soulèvent une question évidente : qu'est-ce qui empêche leur utilisation pour créer du contenu trompeur ? La réponse de Google est un filigrane non optionnel et imperceptible intégré dans chaque clip produit par Gemini Omni.
Qu'est-ce que le filigrane vidéo Google SynthID ?
Le filigrane vidéo Google SynthID n'est pas un logo visible ou une balise de métadonnées amovible. Il s'agit d'un signal intégré directement dans les pixels d'une vidéo au moment de sa génération — invisible à l'œil humain, mais lisible par les outils de détection de Google. Selon la keynote de Google I/O 2026, SynthID a marqué plus de 100 milliards d'images et vidéos générées par IA depuis son lancement.
Surtout, le signal est conçu pour survivre aux opérations de post-traitement courantes qui pourraient autrement effacer un marqueur de surface :
- Compression et ré-encodage
- Redimensionnement et recadrage
- Conversion de format
Pour Gemini Omni spécifiquement, SynthID est activé par défaut et ne peut être désactivé.
Comment fonctionne la vérification de la provenance des médias IA ?
La provenance des médias IA peut être vérifiée via trois surfaces Google : l'application Gemini, Gemini dans Chrome et Google Search. Les utilisateurs importent un clip et le détecteur met en évidence les horodatages spécifiques où un signal de filigrane est trouvé — offrant une vérification contextuelle plutôt qu'un simple résultat oui/non.
SynthID comme stratégie d'atténuation des deepfakes
| Couche de sécurité | Action |
|---|---|
| Filigrane au niveau du pixel | Survit à la compression, au recadrage, au ré-encodage |
| Intégration non optionnelle | Ne peut pas être désactivé par l'utilisateur |
| Adoption multi-plateforme | OpenAI et ElevenLabs adoptent le standard C2PA |
| Barrière d'onboarding pour avatar | Nécessite une vérification vocale avant stockage de la ressemblance |
| Montage vocal restreint | Montage vocal complet retenu en attendant un déploiement responsable |
Sundar Pichai a clairement résumé le contexte lors de l'I/O 2026 : les études montrent que les gens n'identifient correctement les vidéos "deepfake" de haute qualité que dans environ un quart des cas. SynthID, couplé à la restriction du montage vocal, forme l'approche multicouche de Gemini Omni pour l'atténuation des deepfakes et les fonctionnalités de sécurité du contenu.
Gemini Omni Flash vs Pro : abonnements, prix des jetons et accès API
Maintenant que les fonctionnalités sont claires, la question est pratique : quel est le coût d'accès et quel niveau correspond à votre flux de travail ?
Comment obtenir l'accès à Gemini Omni Flash dès maintenant ?

Gemini Omni Flash a commencé son déploiement le 19 mai 2026. Les méthodes d'accès dépendent de votre usage :
| Niveau de plan | Prix mensuel | Stockage Cloud | App Gemini & Fonctionnalités clés |
|---|---|---|---|
| Google AI Plus | 7,99 USD / mois | 200 Go | Limites : 2x supérieures à celles sans plan Google AI ; accès au modèle Flash Thinking |
| Google AI Pro | 19,99 USD / mois | 5 To | Limites : 4x supérieures ; accès au modèle Pro, recherche approfondie et plus |
| Google AI Ultra | 99,99 USD / mois | 20 To | Limites : 5x supérieures au plan Pro ; accès aux fonctionnalités les plus avancées comme Deep Think |
L'accès à Gemini Omni au sein de Google Flow dépend des crédits Google Flow Omni alloués : passant de l'accès d'entrée dans AI Plus, aux pipelines de réalisation multi-tours avancés dans AI Pro, jusqu'aux limites de calcul studio dans AI Ultra.
Pour les déploiements d'applications standard, le modèle de paiement au jeton Vertex AI de Google permet de prévoir les coûts. Cependant, pour les pipelines de rendu de qualité professionnelle qui atteignent des limites rigides d'API, le passage à des modèles de tarification GPU à la demande offre un blueprint plus rentable, donnant aux équipes un contrôle matériel brut sans engagements minimaux.
Gemini Omni Flash vs Pro : quelle est la différence ?
Dans la comparaison Gemini Omni Flash vs Pro, l'un est confirmé et l'autre n'est pas encore disponible. Flash génère des clips de 10 secondes — un plafond de déploiement délibéré pour gérer la demande de calcul au lancement, et non une limite du modèle, selon Nicole Brichtova de Google DeepMind.
Omni Pro a été annoncé mais ne porte aucune date de sortie. Google affirme qu'il sera lancé lorsque l'équipe observera "un saut qualitatif au-dessus de Flash". D'ici là, Flash est le seul modèle Omni publiquement disponible.
Gemini Omni vs Google Veo : qu'est-ce qui a changé ?
Gemini Omni vs Google Veo est un changement architectural, pas une simple mise à jour de version. Veo 3.1 reste actif avec un accès API GA pour la génération texte-vidéo. Omni ajoute une couche de raisonnement, accepte les quatre types d'entrées simultanément et introduit le montage conversationnel multi-tours — aucune de ces fonctionnalités n'était prévue pour Veo.
Une API unifiée pour la génération vidéo de production
Alors que Google déploie Gemini Omni Flash au sein de l'application Gemini et de Google Flow pour les utilisateurs finaux, les développeurs et les équipes produit qui souhaitent intégrer le même moteur vidéo multimodal dans leurs propres flux de travail ont besoin d'une couche API stable et prévisible.
Atlas Cloud sert Gemini Omni Flash via une API unifiée compatible avec OpenAI, aux côtés de plus de 300 autres modèles d'images, de vidéos et de LLM — afin que vous puissiez intégrer le modèle multimodal natif de Google sans jongler avec des comptes fournisseurs, des portails de facturation ou des SDK distincts.
Les deux variantes de Gemini Omni Flash sont disponibles sur Atlas Cloud :
| Variante | Meilleur pour | Entrées | Résolution | Durée | Prix de départ |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video | Génération cinématographique pure | Texte (jusqu'à 20 000 car.) | 720p/1080p/4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/sec |
| Gemini Omni Flash Image-to-Video | Vidéo cohérente avec réf. réelles | Texte + jusqu'à 7 images | 720p/1080p/4K | 4, 6, 8, 10 s | USD0.2 + USD0.1/sec |
Démarrage rapide — Générez une vidéo Gemini Omni Flash en 5 lignes :
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
L'API renvoie immédiatement un ID de prédiction — interrogez /api/v1/model/prediction/{id} pour obtenir l'URL du fichier MP4 rendu. Le schéma complet, des exemples de code dans 7 langages et un Playground sans code sont disponibles sur les pages des modèles liées ci-dessus.
Conclusion : l'avenir du contenu multimodal
Gemini Omni représente bien plus qu'un meilleur générateur vidéo. En fusionnant le moteur de raisonnement de Gemini avec la génération multimodale native, Google a réduit ce qui nécessitait auparavant quatre outils distincts — prompt textuel, référencement d'image, rendu vidéo et montage post-production — en un seul flux conversationnel.
Les implications sont majeures. La physique du modèle mondial garantit des modifications crédibles sans composition manuelle. La provenance via SynthID signifie que la responsabilité est intégrée dès le départ. La création d'avatar permet aux créateurs de produire à grande échelle sans être devant une caméra en permanence. Avec Omni Flash déjà en ligne sur l'app Gemini, Google Flow et YouTube Shorts, la barrière à l'entrée est suffisamment basse pour les créateurs individuels comme pour les équipes d'entreprise.
Ce qui suivra — Omni Pro, accès API élargi et modalités de sortie étendues — définira l'ampleur de ce changement.
Nous voulons maintenant votre avis. Quelle fonctionnalité de Gemini Omni testerez-vous en premier dans votre flux de travail : les modifications d'arrière-plan conversationnelles, la création d'avatar ou la génération de scènes basées sur la physique ? Laissez votre réponse dans les commentaires ci-dessous.






