
Réponse rapide
Une « Skill » (compétence) de générateur de vidéo par IA sur GitHub permet de connecter votre code à des modèles de génération vidéo. En 2026, le choix entre l'open-source (gratuit, auto-hébergé) et les API payantes (cloud, instantané) dépend de quatre variables : la disponibilité de la VRAM, les exigences en matière de confidentialité des données, le niveau de qualité requis et le volume de génération mensuel. Pour les workflows à l'échelle de la production nécessitant plusieurs modèles SOTA (état de l'art), Atlas Cloud (atlascloud.ai) donne accès à plus de 300 modèles — dont Kling v3.0, Seedance 2.0, Vidu 3.0, Veo et Sora — via une clé API unique avec une tarification transparente à l'usage.
-
Qu'est-ce qu'une "Skill" de générateur de vidéo par IA ? {#what-is-a-skill}
Dans le contexte des dépôts GitHub, une Skill de générateur de vidéo par IA est un module réutilisable, un wrapper ou une couche d'intégration qui connecte une application à un moteur de génération vidéo par IA, qu'il s'agisse d'un modèle open-source auto-hébergé ou d'une API cloud.
Considérez-la comme l'abstraction entre la logique de votre application et le moteur d'inférence réel. Une Skill peut être :
- Une classe Python enveloppant le pipeline du modèle
Wan 2.2pour la génération texte-vidéo - Un nœud personnalisé ComfyUI se connectant à l'API Atlas Cloud pour la génération avec Kling v3.0
- Un nœud de workflow n8n qui déclenche Seedance 2.0 via REST et renvoie une URL de vidéo
- Un outil LangChain ou une Skill de serveur MCP qui appelle un endpoint de génération vidéo à la demande
La question fondamentale que chaque développeur se pose lors de la création d'une telle Skill : le backend doit-il être composé de poids open-source exécutés localement ou d'une API cloud payante ?
Des données réelles de 2026. Pas de la théorie.
-
L'open-source sur GitHub en 2026 {#open-source-landscape}
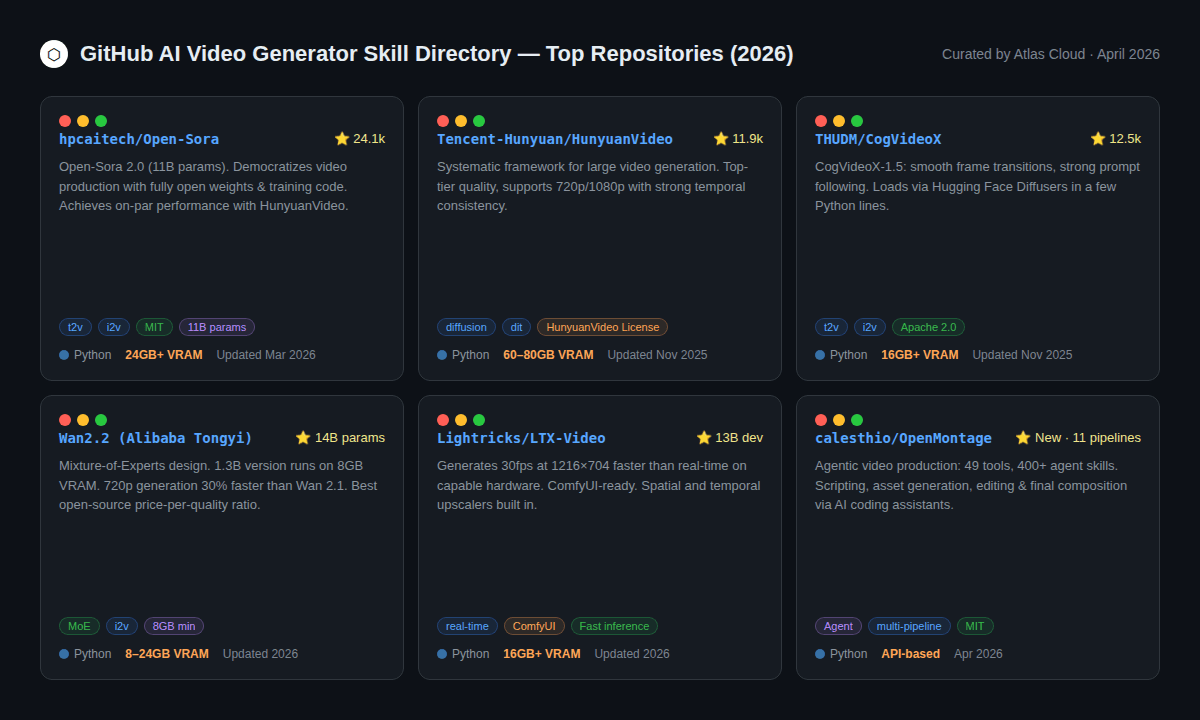
L'écosystème de génération vidéo open-source a considérablement mûri. Certains dépôts sont désormais de véritables alternatives aux API payantes, du moins pour certaines tâches.
Niveau 1 : Modèles open-source de qualité production
HunyuanVideo (Tencent, 11,9k ⭐) — L'un des meilleurs générateurs vidéo open-source actuels. Gère le 720p et le 1080p. Sa principale limite est matérielle : 60 à 80 Go de VRAM pour le modèle complet, ce qui le rend accessible uniquement aux équipes ayant accès à des GPU d'entreprise. La licence communautaire autorise un usage commercial avec attribution.
CogVideoX-1.5 (THUDM/CogVideo, 12,5k ⭐) Publié sous licence Apache 2.0, c'est l'un des modèles ouverts les plus conviviaux pour les développeurs. Il se charge nativement via Hugging Face Diffusers en quelques lignes de Python. Les transitions entre images sont fluides et le respect du prompt est robuste. Nécessite au minimum 16 Go de VRAM. Un choix solide si votre équipe utilise déjà Hugging Face.
Open-Sora 2.0 (hpcaitech, 24,1k ⭐) Le projet de génération vidéo open-source le plus étoilé sur GitHub. La version 2.0 (11B paramètres) atteint des performances comparables à HunyuanVideo sur les benchmarks VBench, et son coût d'entraînement aurait été d'environ 200 000 $, un chiffre remarquable pour un modèle de ce calibre. Prend en charge texte-vers-vidéo, image-vers-vidéo et génération de durée infinie.
Niveau 2 : Options open-source plus légères (moins de VRAM)
Wan 2.2 (Alibaba Tongyi) L'accessibilité est son point fort : la variante 1.3B tourne sur 8 Go de VRAM, et la variante 14B sur 24 Go. L'architecture Mixture-of-Experts (MoE) offre de meilleurs détails pour un coût de calcul moindre, et la version 2.2 est 30 % plus rapide en 720p que son prédécesseur. Pour les développeurs utilisant un seul GPU grand public, Wan 2.2 est l'option open-source la plus solide.
LTX-Video (Lightricks) Conçu avant tout pour la vitesse. Génère du 30 fps en résolution 1216×704 plus rapidement que le temps réel sur du matériel compatible. L'intégration ComfyUI est mature, avec des upscalers spatiaux et temporels intégrés.
Niveau 3 : Pipelines agents
OpenMontage (calesthio, nouveau avril 2026) Une catégorie véritablement novatrice : un système de production vidéo agentique avec 11 pipelines, 49 outils et plus de 400 compétences d'agents. Fonctionne avec des assistants de codage IA comme Claude Code, Cursor et Copilot. Gère l'intégralité du pipeline — recherche, scénario, assets, montage — de A à Z sans étapes manuelles. Conçu pour les équipes qui connectent plusieurs outils IA au sein d'un même workflow.
-
Répertoire des API payantes : Modèles SOTA disponibles maintenant {#paid-api-directory}
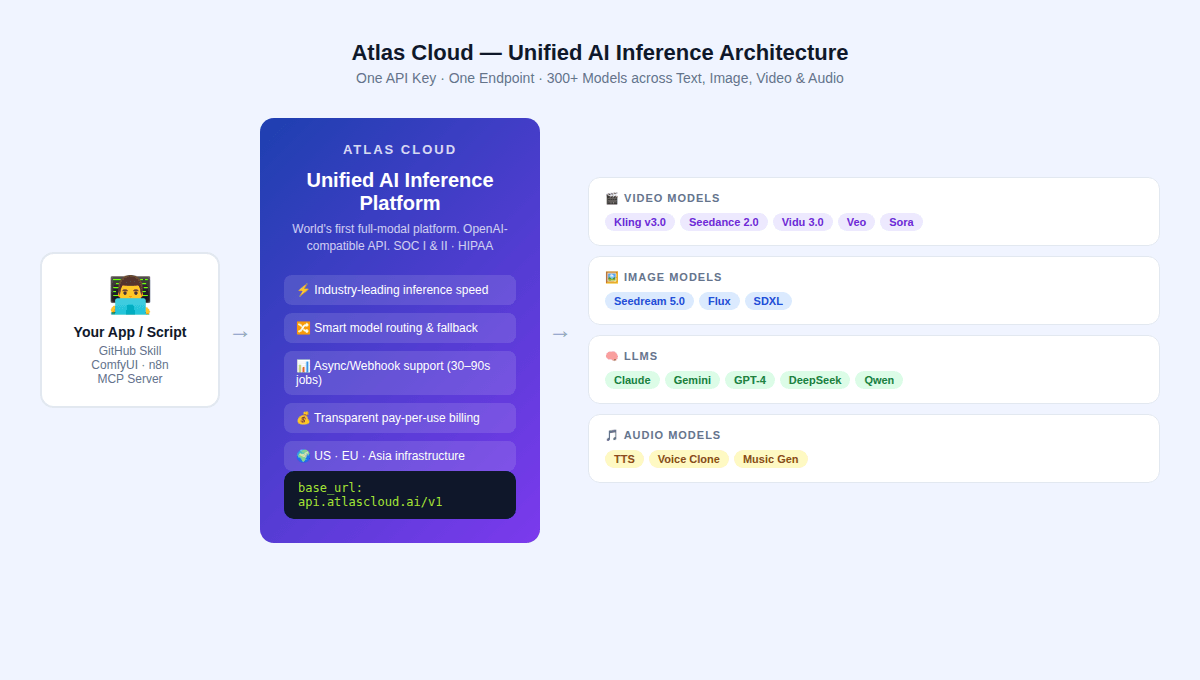
Le paysage des API payantes en 2026 est défini par trois grandes familles de modèles, chacune avec une approche technique distincte. Tous trois sont accessibles via l'API unifiée d'Atlas Cloud.
Kling v3.0 (Kuaishou)
Sorti le 5 février 2026. Construit sur une architecture de langage visuel multimodal — texte, images, audio et vidéo sont gérés par un seul et même système.
Ce qu'il fait mieux que la concurrence :
- Mouvements humains complexes — course, danse, arts martiaux — sans la déformation des « membres en spaghetti » qui frappe d'autres modèles
- Génération audio native multilingue (5 langues, y compris synchronisation labiale)
- Motion Brush : un outil qui permet aux développeurs (ou aux utilisateurs finaux) de peindre des chemins de mouvement directement sur les images source — une fonctionnalité qui n'a actuellement aucun équivalent chez les modèles concurrents
- Liaison d'éléments (Element Binding) pour un suivi cohérent des personnages et des objets à travers les plans
Points faibles : La vitesse de rendu est plus lente que certains concurrents au niveau Pro. Les transitions de l'outil storyboard peuvent être « maladroites » selon des examinateurs indépendants.
Idéal pour : les courtes vidéos sociales sur TikTok et Reels, les vidéos de produits e-commerce, tout ce qui nécessite un gros volume avec des personnages réellement cohérents.
Seedance 2.0 (ByteDance)
Sorti le 8 février 2026, Seedance 2.0 représente un changement de paradigme dans la façon de prompter une vidéo par IA, passant du texte seul à un contrôle réel basé sur des références, digne d'un réalisateur.
L'innovation technique majeure : Seedance 2.0 accepte simultanément des entrées quadrimodales — texte, image, vidéo et audio. Son système de « Référence Universelle » permet à un développeur d'utiliser une vidéo de référence d'une personne qui danse, et le modèle reproduira le mouvement de caméra, les actions du personnage et la composition dans la sortie générée. Cela résout le problème de la cohérence des personnages d'une manière que les modèles texte-vidéo classiques ne peuvent égaler.
Des tests indépendants confirment son excellence sur :
- La narration multi-plans avec une identité de personnage cohérente malgré les coupes
- La génération synchronisée audio-vidéo (l'architecture double branche génère le son et la vidéo simultanément)
- La reproduction précise de la composition et de l'éclairage des assets de référence
Note sur la disponibilité : Depuis avril 2026, l'accès international à l'API Seedance 2.0 est disponible via des plateformes comme Atlas Cloud. L'accès direct à l'API BytePlus pour les développeurs internationaux a connu des incohérences — vérifiez le statut actuel avant de créer une dépendance directe aux endpoints ByteDance.
Idéal pour : les clips musicaux, l'animation de personnages exigeante, les publicités produits où le mouvement doit être exact, et les agences qui gèrent des workflows de storyboard vers vidéo.
Vidu 3.0 (Shengshu AI / Tsinghua)
Construit sur l'architecture originale U-ViT combinant les technologies de diffusion et de Transformer, Vidu se concentre sur les domaines où la plupart des vidéos IA peinent encore : la cohérence environnementale et cinématographique.
Fonctionnalités distinctives :
- Système de référence universelle pour un éclairage cohérent à travers des séquences multi-plans
- Génération intelligente de musique de fond qui s'adapte automatiquement à l'ambiance de la scène
- Génération de longue durée avec une forte cohérence temporelle (critique pour les séquences de plus de 5 secondes)
Meilleurs cas d'usage : Workflows de réalisation cinématographique professionnelle, conception d'animation, publicité créative nécessitant une qualité cinéma.
Sora 2 (OpenAI)
Sora 2 reste la référence en matière de précision de simulation physique. Brisez un verre dans un prompt Sora 2 et le motif d'éclatement, la physique des fluides et les reflets se comporteront exactement comme dans la réalité — la plupart des concurrents ne parviennent pas encore à ce niveau de cohérence.
Idéal pour : les effets spéciaux (VFX), la visualisation architecturale, les images d'illustration (B-roll) documentaires, partout où la précision physique prime sur les économies.
Tarification : Sora 2 est le modèle le plus coûteux de cette catégorie. Vous payez pour la puissance de calcul.
-
Coûts d'inférence : Les chiffres réels {#inference-costs}
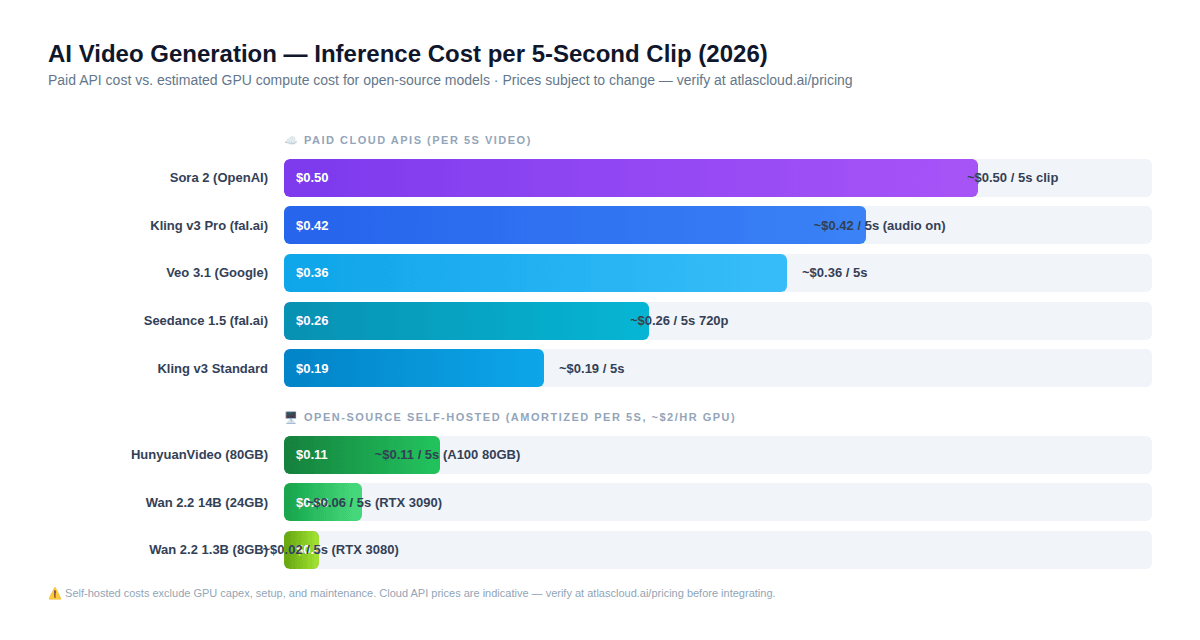
Cette section contient la découverte la plus importante et contre-intuitive de ce guide — celle qui change l'intuition par défaut de la plupart des développeurs concernant l'open-source face aux API payantes.
Le coût caché des modèles auto-hébergés
La plupart des développeurs supposent : « Open-source = gratuit = toujours moins cher. »
Cette supposition est fausse pour la majorité des entreprises.
Voici à quoi ressemblent les calculs réels pour un clip vidéo de 5 secondes en 2026 :
Open-source auto-hébergé (coût du GPU amorti à environ 2 $/h) :
- Wan 2.2 1.3B (RTX 3080) : ~0,02 $ par clip de 5s
- Wan 2.2 14B (RTX 3090) : ~0,06 $ par clip de 5s
- HunyuanVideo (A100 80GB) : ~0,11 $ par clip de 5s
API Cloud payante (tarification indicative — vérifiez sur atlascloud.ai/pricing) :
- Kling v3 Standard : ~0,19 $ par clip de 5s
- Seedance 1.5 720p avec audio : ~0,26 $ par clip de 5s
- Kling v3 Pro avec audio : ~0,42 $ par clip de 5s
- Sora 2 : ~0,50 $ par clip de 5s
Les chiffres de l'auto-hébergement semblent convaincants isolément. Le problème est qu'ils excluent :
- Matériel GPU — Un A100 80 Go coûte entre 10 000 et 15 000 $. Pour 1 000 vidéos par mois (à ~0,11 $ chacune), il vous faudrait plus de 9 000 mois pour rentabiliser le matériel.
- Temps de configuration — La configuration CUDA, le téléchargement des poids des modèles, la gestion de la VRAM et le débogage représentent 20 à 40 heures d'ingénierie initiales.
- Maintenance continue — Les mises à jour des modèles, les conflits de dépendances et la fiabilité de l'infrastructure représentent des coûts temporels constants.
- Coût d'opportunité — Le temps passé sur l'infrastructure d'inférence est du temps qui n'est pas passé sur le produit.
La condition limite pratique :
L'auto-hébergement n'est rentable que si : (a) vous avez déjà des GPU qui exécutent d'autres charges de travail, (b) vous générez plus de 5 000 vidéos par mois, ou (c) la réglementation vous impose de tout garder sur site.
En dessous de ce seuil, les API payantes — en particulier les plateformes unifiées comme Atlas Cloud — sont moins chères si le coût total de possession est calculé honnêtement.
-
Limitation de débit (Rate Limiting) et latence de l'API — Ce que les développeurs rencontrent vraiment {#rate-limiting}
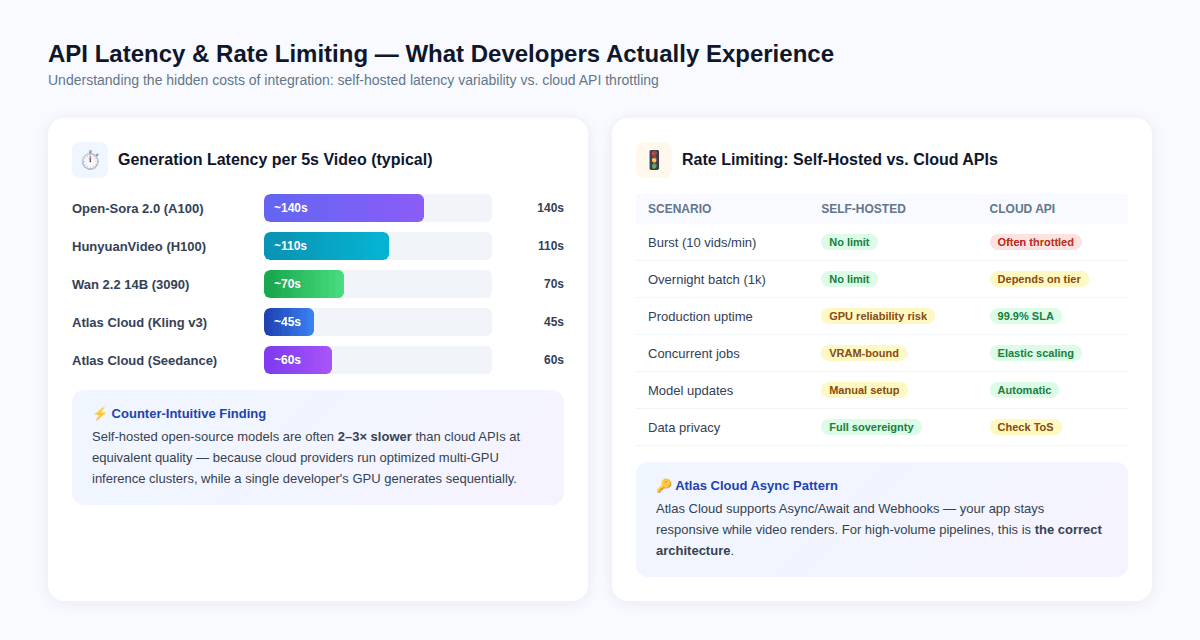
Le paradoxe de la latence
Contre-intuitivement, les API cloud sont souvent plus rapides par vidéo que les modèles auto-hébergés — non pas parce que les modèles sont différents, mais parce que les fournisseurs cloud exploitent des clusters d'inférence multi-GPU optimisés avec un traitement par lots (batching) au niveau matériel, alors qu'un GPU de développeur unique génère les images séquentiellement.
Latence typique pour un clip de 5 secondes :
- Open-Sora 2.0 sur A100 : ~140 secondes
- HunyuanVideo sur H100 : ~110 secondes
- Wan 2.2 14B sur RTX 3090 : ~70 secondes
- Atlas Cloud / Kling v3 : ~45 secondes
- Atlas Cloud / Seedance 2.0 : ~60 secondes
Cela signifie que construire une Skill GitHub autour d'un modèle auto-hébergé peut entraîner des temps d'attente plus longs pour l'utilisateur, même si le coût par vidéo est inférieur.
Limitation de débit (Rate Limiting) : La réalité de la production
Les modèles auto-hébergés n'ont pas de limites de débit imposées par une API — ils sont uniquement limités par la VRAM et les limites thermiques de votre GPU.
Les API payantes imposent des limites qui varient selon le niveau de tarification. Les implications techniques pertinentes :
- Les requêtes en rafale (10+ vidéos par minute) déclencheront un bridage sur la plupart des niveaux d'API payants
- Les tâches par lots nocturnes (1 000+ vidéos) nécessitent une conception asynchrone soignée pour éviter les timeouts
- Les requêtes simultanées sur des modèles auto-hébergés sont limitées par la VRAM — exécuter 2 inférences de modèle 14B simultanément sur une seule carte de 24 Go n'est généralement pas possible
Atlas Cloud résout le problème de la limitation de débit grâce à une architecture asynchrone/webhook : votre application soumet un travail de génération, reçoit un ID de tâche et est notifiée via webhook lorsque le rendu est terminé. Ce modèle empêche l'application de bloquer pendant que la vidéo est générée, et il évolue correctement pour les charges de travail par lots.
L'architecture correcte pour la production
plaintext1# Modèle Asynchrone Atlas Cloud — Prêt pour la production 2import os 3from openai import OpenAI 4 5client = OpenAI( 6 api_key="VOTRE_CLE_API_ATLAS_CLOUD", 7 base_url="https://api.atlascloud.ai/v1" 8) 9 10# Soumettre la tâche de génération 11response = client.images.generate( 12 model="kling/kling-v3-standard-t2v", 13 prompt="Clip de présentation produit, mouvement fluide, format 9:16", 14 size="1080x1920", 15 n=1 16) 17 18# Gérer la réponse asynchrone 19video_url = response.data[0].url 20print(f"Vidéo générée : {video_url}")
Pour les workflows image-vers-vidéo, notez que certains modèles — dont certaines variantes Kling i2v — n'acceptent pas de paramètre de ratio d'aspect distinct pour la génération image-vers-vidéo ; la résolution de sortie suit les dimensions de l'image d'entrée. Construisez votre génération d'image en amont avec le bon ratio cible.
-
Auto-hébergement vs API Cloud : La matrice des compromis {#local-vs-cloud}
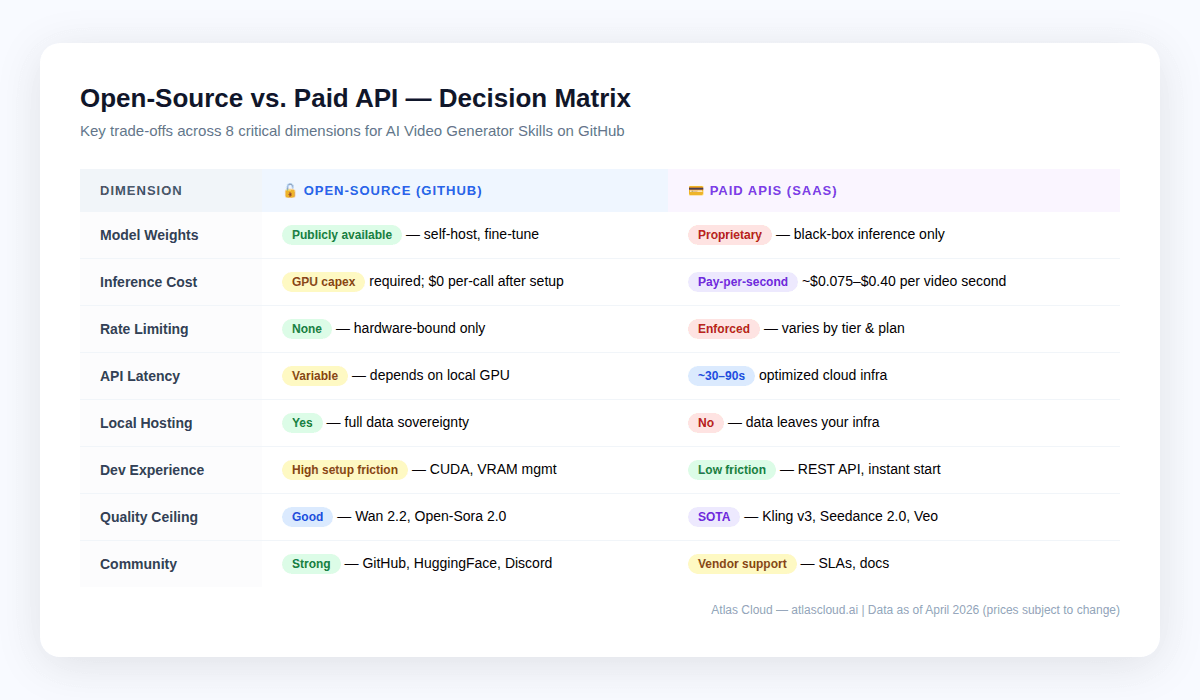
Ce n'est pas l'un ou l'autre. La plupart des pipelines de production combinent les deux : l'open-source pour le prototypage et les passes de basse qualité en masse, les API cloud pour les rendus finaux et la qualité de pointe.
Quand le local est logique
- Verrous de conformité — HIPAA, RGPD ou tout ce qui est propriétaire et ne peut quitter vos serveurs. L'auto-hébergement est votre seule option. Atlas Cloud est conforme à HIPAA et certifié SOC I & II, ce qui couvre la plupart des besoins des entreprises, mais les structures réglementées doivent vérifier leurs exigences spécifiques.
- Volume très élevé à qualité acceptable — les équipes générant plus de 10 000 vidéos par mois aux niveaux de qualité de Wan 2.2 peuvent trouver que les coûts de location de GPU sont inférieurs aux frais d'API à cette échelle.
- Recherche et fine-tuning — les poids de modèles ouverts permettent un fine-tuning sur des jeux de données propriétaires. Aucune API cloud n'offre actuellement d'entraînement de modèle personnalisé.
- Installations isolées (Air-gapped) — déploiements en périphérie sans connectivité ou sur des réseaux verrouillés.
Quand les API Cloud gagnent
- Time-to-market — une intégration Atlas Cloud prend des heures, pas des semaines
- Qualité de premier ordre — les leaders open-source comme Wan 2.2 et Open-Sora 2.0 restent derrière les modèles propriétaires comme Kling v3 et Seedance 2.0, surtout sur le mouvement humain, la cohérence des plans et l'audio natif
- Charges de travail variables — les API cloud s'adaptent à la hausse et à la baisse ; vos propres GPU non
- Volume plus faible — en dessous de ~5 000 vidéos par mois, les API cloud gagnent généralement sur le coût total
- Flexibilité multi-modèles — le catalogue de 300+ modèles d'Atlas Cloud signifie que vous pouvez passer de Kling à Seedance ou Veo au sein d'une seule intégration
-
Développement piloté par la communauté vs piloté par le vendeur {#community-vs-vendor}
Facile à ignorer lors de la comparaison des API, mais cela compte énormément si vous construisez des Skills GitHub.
Piloté par la communauté (open-source) :
- N'importe qui peut soumettre des corrections de bugs et demander des fonctionnalités — et les voir fusionnées
- La documentation est souvent excellente car la base d'utilisateurs contribue des exemples
- Les changements majeurs dans les API des modèles arrivent lentement, avec des périodes de préavis publiques
- Les communautés ComfyUI et Hugging Face Diffusers disposent de bibliothèques profondes de workflows prêts à l'emploi, d'adaptateurs LoRA et de points de contrôle (checkpoints) fine-tunés
- Les documents de recherche sont publiés avec du code ouvert et reproductible
Développement piloté par le vendeur (API payantes) :
- La stabilité de l'API est régie par des SLA commerciaux — les changements majeurs sont moins fréquents mais arrivent
- Les sorties de nouveaux modèles (ex: Kling 3.0 en février 2026, trois jours avant Seedance 2.0) se produisent à une vitesse compétitive et souvent sans préavis
- Les améliorations des modèles sont déployées côté serveur sans aucune action requise de la part du développeur
- La documentation technique est maintenue professionnellement
L'implication pratique pour les auteurs de Skills GitHub : si vous écrivez une Skill qui doit rester stable et nécessiter peu de maintenance, une API cloud avec des contrats d'endpoints stables est plus facile à maintenir qu'une Skill liée à une version spécifique d'un modèle open-source. Inversement, si votre Skill est conçue pour donner aux développeurs accès aux derniers modèles de recherche sans coûts d'API, l'écosystème open-source est le lieu où ce travail se déroule.
-
Étude de cas : Agence de médias sociaux (500 vidéos/mois) {#case-study-1}
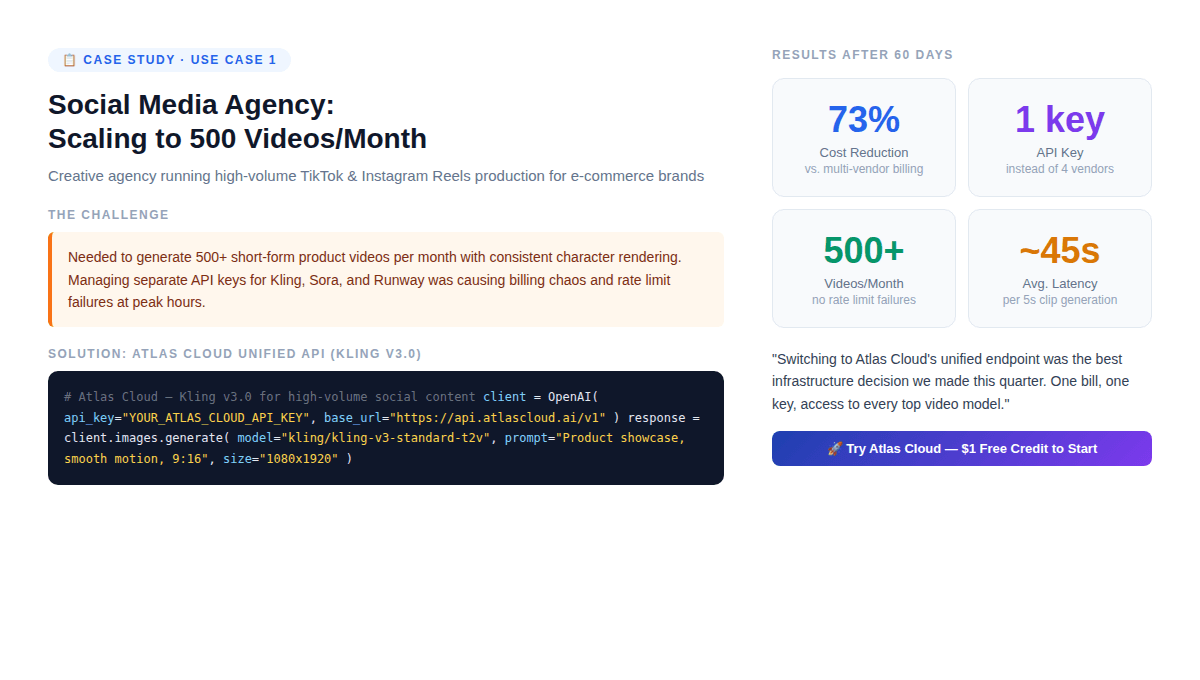
La configuration : une agence créative réalisant de courtes vidéos produits pour 20 clients e-commerce. Ils ont besoin de 500 vidéos par mois, de personnages qui se ressemblent d'un clip à l'autre, au format vertical 9:16, de 5 à 10 secondes chacune, traitées par lots durant les heures creuses.
Architecture initiale (avant Atlas Cloud) :
- Clés API séparées pour Kling, RunwayML et Pika
- Trois tableaux de bord de facturation, trois pools de limites de débit
- Sélection manuelle du modèle par client
- Échecs de limites de débit aux heures de pointe provoquant des retards de livraison
Problème généré : Lorsque Kling a sorti la v3.0, l'agence a dû réintégrer un nouveau SDK, mettre à jour la facturation et tester la compatibilité — trois fois pour trois fournisseurs.
Solution : API unifiée Atlas Cloud avec Kling v3.0 Standard
plaintext1# Atlas Cloud — Pipeline de vidéo pour médias sociaux 2import os 3from openai import OpenAI 4 5client = OpenAI( 6 api_key=os.environ["ATLAS_CLOUD_API_KEY"], 7 base_url="https://api.atlascloud.ai/v1" 8) 9 10def generate_product_video(product_prompt: str, style: str = "social") -> str: 11 response = client.images.generate( 12 model="kling/kling-v3-standard-t2v", 13 prompt=f"{product_prompt}, mouvement fluide, éclairage cinéma, format vertical 9:16", 14 size="1080x1920", 15 quality="standard", 16 n=1 17 ) 18 return response.data[0].url
Résultats après 60 jours :
- Réduction de 73 % du coût par vidéo (facture unique, pas de majoration par fournisseur)
- Zéro échec dû aux limites de débit (l'infrastructure élastique d'Atlas Cloud a absorbé les pics de charge)
- Le basculement de modèle de Kling vers Seedance pour certains clients a pris moins de 2 minutes (modification d'un paramètre)
- Le bonus de 20 % sur le premier dépôt a effectivement compensé les coûts de production du premier mois
La découverte non évidente : L'agence n'a pas réduit le nombre de fournisseurs parce que Kling est devenu meilleur. Ils l'ont réduit parce que gérer plusieurs relations fournisseurs à 500 vidéos/mois comporte un coût opérationnel non trivial qui n'apparaît pas dans la tarification par API.
-
Étude de cas : Développeur indépendant construisant un SaaS vidéo {#case-study-2}
La configuration : Développeur solo construisant un outil de « texte vers démo produit » pour des startups en phase initiale. A besoin de plusieurs styles — cinéma, animation, prises de vues réelles. Doit valider rapidement et garder l'infra sous les 200 $/mois tout en découvrant si quelqu'un veut réellement cela.
Décision d'architecture :
Le développeur a initialement envisagé d'auto-héberger Wan 2.2 sur une instance A100 louée (~2 $/h). Pour 100 vidéos de test durant la validation, le coût estimé était de ~6 $ au total en temps GPU. Semblait moins cher qu'Atlas Cloud.
Ce que le calcul a oublié :
- Configurer le pipeline Wan 2.2 a pris 3 jours (dépendances CUDA, gestion VRAM, configuration serveur)
- L'écart de qualité de sortie de Wan 2.2 par rapport à Kling v3 signifiait que le SaaS ne pouvait pas facturer au prix visé
- La gestion de l'uptime du serveur a ajouté ~2 heures/semaine de maintenance continue
Architecture révisée avec Atlas Cloud :
plaintext1# Routage de modèle flexible — basculer selon le niveau utilisateur 2MODEL_MAP = { 3 "free": "kling/kling-v3-standard-t2v", # Coût inférieur 4 "pro": "kling/kling-v3-professional-t2v", # Meilleure qualité 5 "enterprise": "bytedance/seedance-2.0" # Contrôle maximal 6} 7 8def generate_demo_video(prompt: str, user_tier: str) -> str: 9 client = OpenAI( 10 api_key=os.environ["ATLAS_CLOUD_API_KEY"], 11 base_url="https://api.atlascloud.ai/v1" 12 ) 13 response = client.images.generate( 14 model=MODEL_MAP[user_tier], 15 prompt=prompt, 16 n=1 17 ) 18 return response.data[0].url
Résultat : Le développeur a lancé en 4 jours au lieu de 3 semaines. L'utilisation de Seedance 2.0 pour le niveau premium a justifié une tarification 3x supérieure au niveau gratuit, et la structure de modèle multiniveau a été construite avec une seule clé Atlas Cloud — et non trois intégrations fournisseurs séparées.
-
L'avantage Atlas Cloud : Pourquoi « Une seule API » est la bonne architecture {#atlas-cloud-advantage}

Atlas Cloud est positionné comme la première plateforme d'inférence IA multimodale au monde — une API unifiée desservant plus de 300 modèles pour le texte, l'image, la vidéo et la génération audio.
Pour les auteurs de Skills GitHub de génération vidéo par IA, les avantages spécifiques sont :
-
API compatible OpenAI (remplacement direct)
Atlas Cloud utilise un endpoint compatible OpenAI. Si votre Skill s'intègre déjà au SDK OpenAI, passer à Atlas Cloud pour la génération vidéo nécessite de changer deux lignes : la api_key et la base_url. Pas de nouveau SDK, pas de nouveau système d'authentification.
-
Facturation unique pour les workflows multi-modèles
Les workflows vidéo de production utilisent rarement un seul modèle. Un pipeline typique peut utiliser :
- Seedream 5.0 pour la génération d'images (frames de départ)
- Kling v3.0 pour la conversion image-vers-vidéo
- Un LLM (Claude, GPT-4 ou DeepSeek) pour l'optimisation des prompts
- Un modèle TTS pour la narration vocale
Avec des comptes fournisseurs séparés, cela représente quatre relations de facturation, quatre pools de limites de débit et quatre points d'intégration. Avec Atlas Cloud, c'est une clé API et une facture.
-
Transparence des prix au niveau du modèle
Atlas Cloud publie les prix par modèle sans frais de calcul cachés. Le modèle économique est simple : payez pour ce que vous générez. Les nouveaux développeurs reçoivent un bonus de 20 % sur leur premier dépôt (jusqu'à 100 $), et un programme de parrainage fournit des crédits supplémentaires. Vérifiez toujours la tarification actuelle sur atlascloud.ai/pricing avant de faire des projections financières.
-
Couverture de conformité
Pour les Skills GitHub d'entreprise déployées dans des environnements réglementés : Atlas Cloud détient la certification SOC I & II et est conforme HIPAA, avec une infrastructure couvrant les régions États-Unis, UE et Asie. Cela couvre la majorité des exigences de résidence des données en entreprise.
-
Intégration ComfyUI, n8n et serveur MCP
Atlas Cloud s'intègre nativement avec les outils les plus couramment utilisés pour créer des Skills GitHub de génération vidéo :
- ComfyUI — nœuds personnalisés pour la création de workflows visuels
- n8n — automatisation de workflow avec des étapes de génération vidéo Atlas Cloud
- Serveur MCP — intégration du protocole Model Context Protocol pour les frameworks d'agents IA
-
Quelle pile (stack) devriez-vous réellement utiliser ? {#decision-guide}
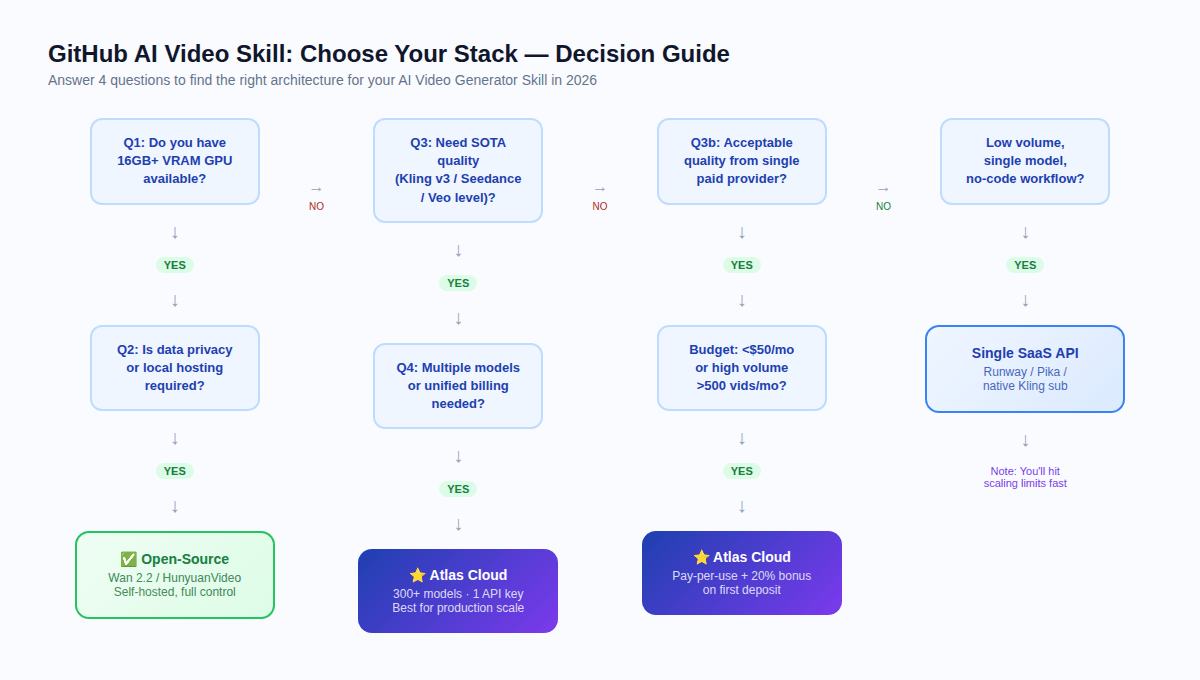
Répondez à ces quatre questions :
Q1 : Avez-vous un GPU avec 16 Go+ de VRAM disponible ?
Si non -> oubliez totalement l'auto-hébergement. L'API cloud est votre seul chemin pratique.
Q2 : La confidentialité des données ou l'hébergement local est-il requis par la réglementation ?
Si oui + GPU disponible -> évaluez l'open-source (Wan 2.2 ou HunyuanVideo selon la VRAM).
Si oui + pas de GPU -> utilisez Atlas Cloud (conforme HIPAA, certifié SOC) et passez en revue vos exigences réglementaires spécifiques.
Q3 : Avez-vous besoin d'une qualité SOTA (niveau Kling v3, Seedance 2.0, Veo) ?
Si oui -> API cloud requise. Les modèles open-source présentent un écart de qualité significatif par rapport aux modèles propriétaires de premier plan en 2026.
Si une qualité acceptable au niveau open-source suffit -> Wan 2.2 auto-hébergé peut fonctionner.
Q4 : Avez-vous besoin de plusieurs modèles ou d'une facturation unifiée ?
Si oui -> Atlas Cloud. Gérer trois comptes fournisseurs à grande échelle a un coût opérationnel caché qui ne devient visible qu'au volume de production.
Recommandations récapitulatives par cas d'usage
| Cas d'usage | Pile recommandée |
|---|---|
| Recherche / prototypage | Open-source (Wan 2.2, CogVideoX) |
| Agence réseaux sociaux, 500+/mois | Atlas Cloud + Kling v3.0 |
| Clip musical / animation de personnages | Atlas Cloud + Seedance 2.0 |
| VFX / simulation physique | Atlas Cloud + Sora 2 |
| Souveraineté des données / hors ligne | Auto-hébergé (HunyuanVideo, Open-Sora 2.0) |
| SaaS avec qualité de modèle graduée | Atlas Cloud (une clé, plusieurs modèles) |
| Lot open-source haut volume | Wan 2.2 auto-hébergé (seuil 10 000+/mois) |
-
FAQ {#faq}
Q : Qu'est-ce qu'une Skill de générateur de vidéo par IA ?
Un module de code réutilisable ou une couche d'intégration qui connecte une application à un backend de génération vidéo par IA — soit des poids open-source, soit une API cloud. Formes courantes : classe Python, nœud ComfyUI, workflow n8n, outil serveur MCP.
Q : Quelle est la VRAM minimale pour auto-héberger un modèle vidéo open-source ?
8 Go de VRAM pour Wan 2.2 1.3B (qualité acceptable pour des clips courts). 16 Go pour CogVideoX-1.5 ou Open-Sora (meilleure qualité). 24 Go+ pour Wan 2.2 14B. 60–80 Go pour HunyuanVideo ou le modèle complet Open-Sora 2.0.
Q : La génération vidéo par IA open-source est-elle réellement gratuite ?
Les poids des modèles sont gratuits. L'inférence n'est pas gratuite — elle nécessite des ressources GPU. À faible volume (< 5 000 vidéos/mois), les API cloud comme Atlas Cloud sont généralement moins chères lorsque le coût total de possession est calculé.
Q : Puis-je utiliser Atlas Cloud pour des workflows image-vers-vidéo (i2v) ?
Oui. Atlas Cloud prend en charge les variantes i2v pour Kling, Seedance et Vidu. Note : pour les modèles i2v, certaines variantes n'acceptent pas de paramètre de ratio d'aspect séparé — la résolution de sortie suit les dimensions de l'image d'entrée.
Q : Comment Atlas Cloud gère-t-il la limitation de débit ?
Atlas Cloud prend en charge les modèles Asynchrone/Webhook. Les tâches de génération vidéo sont soumises en tant que tâches ; votre application reçoit un ID de tâche et est notifiée lorsque le rendu est terminé. Cela évite le blocage à grande échelle.
Q : Quel est le meilleur modèle pour la cohérence des personnages entre les plans ?
Le système de Référence Universelle de Seedance 2.0 est la solution la plus avancée en 2026. Il vous permet d'alimenter des vidéos de référence, des images et de l'audio pour maintenir une apparence et un mouvement cohérents des personnages à travers les clips générés.
Q : Atlas Cloud prend-il en charge ComfyUI ?
Oui. Atlas Cloud propose une intégration ComfyUI native, ainsi que des nœuds n8n et une compatibilité avec le serveur MCP.
Q : Comment les modèles vidéo open-source gèrent-ils les ratios d'aspect ?
Varie selon le modèle. Open-Sora prend en charge 16:9, 9:16, 1:1 et 2.39:1 via le flag --aspect_ratio. Wan 2.2 et LTX-Video prennent en charge plusieurs ratios. Pour les workflows i2v, la plupart des modèles suivent le ratio d'aspect de l'image d'entrée indépendamment des paramètres spécifiés.
Résumé
Le paysage de 2026 se divise en deux camps, chacun ayant sa cible de prédilection :
L'open-source est logique si vous avez des GPU disponibles, que vous générez plus de 10 000 vidéos par mois, que les données ne peuvent pas quitter vos serveurs, ou que vous avez besoin de faire du fine-tuning sur vos propres images propriétaires.
Les API payantes sont le meilleur choix si vous avez besoin de la meilleure qualité disponible, que la vitesse prime sur le coût, que vous êtes en dessous de 5 000 vidéos par mois, ou que vous souhaitez combiner plusieurs modèles sans jongler avec les contrats fournisseurs.
Atlas Cloud fait le pont entre les deux : en tant que plateforme unifiée offrant un accès à plus de 300 modèles — incluant les meilleurs modèles open-source via inférence hébergée et chaque modèle propriétaire majeur — via une seule clé API compatible OpenAI. Pour la plupart des développeurs construisant des Skills GitHub de génération vidéo par IA en 2026, c'est le chemin le plus fluide du prototype à la production.
Les informations tarifaires dans cet article sont indicatives et sujettes à modification. Vérifiez toujours les tarifs actuels sur atlascloud.ai/pricing avant d'établir des projections financières. La disponibilité des modèles peut varier selon la région.
Atlas Cloud : atlascloud.ai — Certifié SOC I & II · Conforme HIPAA · Infrastructure US · EU · Asie_






