
Grok Imagine Video Generation est le système vidéo IA multimodal de pointe de xAI, et il a déjà redéfini ce que les créateurs peuvent attendre d'un simple appel API. Construit sur le moteur xAI Aurora, ce modèle utilise un réseau « mixture-of-experts » (MoE) autorégressif. Il traite simultanément les jetons de texte, d'image, de vidéo et d'audio. Cette approche remplace totalement les méthodes de diffusion-transformer que l'on trouve dans des systèmes comme Sora et Veo.
L'avantage principal réside dans la synchronisation naturelle de l'audio et de la vidéo, créée lors d'une seule étape de génération. Vous n'avez plus besoin d'un outil de doublage distinct par la suite.
En bref : Spécifications clés
| Caractéristique | Détail |
| Durée | 1–15 secondes |
| Fréquence d'images | 24 FPS |
| Résolution | 480p / 720p |
| Audio | Synchronisation labiale native, effets sonores, dialogues, musique ambiante |
| Classement | n°1 sur l'Artificial Analysis Video Arena (Elo 1404 ±6) |
Lancé fin mai 2026, Grok imagine video generation a fait ses débuts en tête du classement Image-to-Video de l'Artificial Analysis Video Arena, détrônant Seedance 2.0 de ByteDance. Pour tout flux de travail numérique moderne exigeant une vidéo rapide, prête à l'emploi et avec un son intégré, c'est la référence à battre.
Comprendre l'architecture de Grok Imagine Video Generation de xAI
Pour exploiter pleinement les fonctionnalités de Grok, nous devons d'abord regarder sous le capot. Contrairement aux modèles vidéo traditionnels qui assemblent le son et l'image a posteriori, Grok les traite comme une entité unique. Comprendre ce changement fondamental explique pourquoi son comportement face aux prompts et ses vitesses de rendu diffèrent si radicalement des alternatives du marché.
Qu'est-ce que Grok Imagine et comment fonctionne-t-il ?
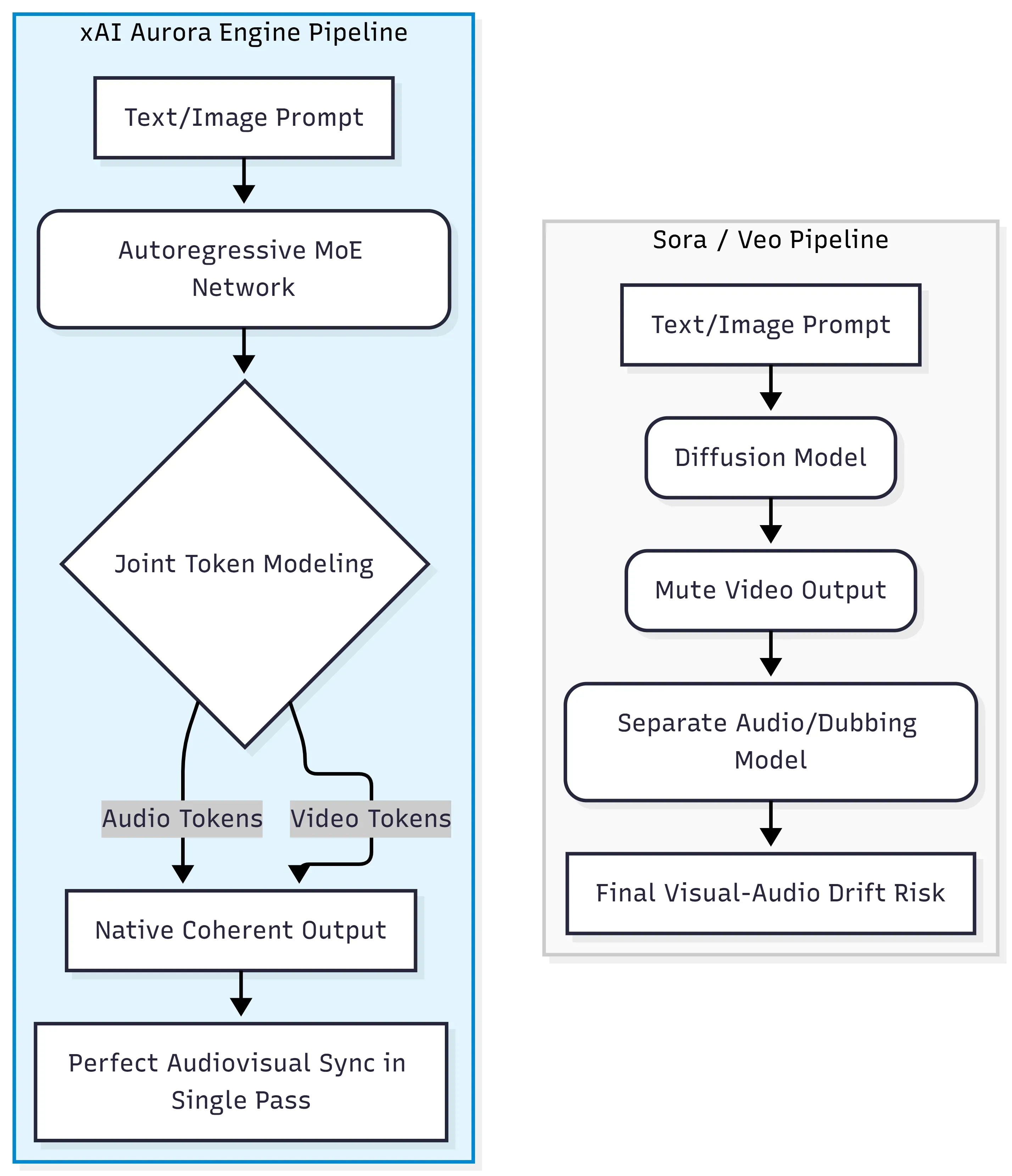
Au cœur de Grok Imagine Video Generation se trouve le moteur xAI Aurora, un réseau « mixture-of-experts » (MoE) autorégressif qui prédit le jeton suivant à travers un flux unifié de données texte, image, vidéo et audio. Cela diffère architecturalement du paradigme diffusion-transformer utilisé par Sora d'OpenAI et Veo de Google, où la vidéo et l'audio sont généralement générés ou alignés en étapes distinctes.
Le passage des modèles diffusion-transformer
Les modèles de diffusion traditionnels fonctionnent en débruitant progressivement un bruit aléatoire pour obtenir des images cohérentes. Ils excellent dans la qualité visuelle mais traitent l'audio comme une réflexion après coup, nécessitant des outils externes ou des pipelines de post-production pour ajouter du son. Aurora emprunte un chemin totalement différent.
| Approche | Architecture | Méthode audio |
| Sora / Veo | Diffusion-Transformer | Post-production / modèle séparé |
| Grok Imagine Video | MoE autorégressif | Génération native en un passage |
Traitement intercalé des jetons multimodaux
Au lieu de gérer les modalités de manière séquentielle, Aurora traite des données multimodales intercalées — ce qui signifie que les jetons audiovisuels (dialogues, effets sonores, musique ambiante) sont générés simultanément avec les images vidéo lors du même passage. Cette modélisation conjointe des jetons est précisément ce qui permet à la synchronisation labiale et aux effets sonores alignés sur l'action d'émerger du modèle lui-même, plutôt que de systèmes d'alignement séparés.
Cet échantillon de production démontre l'exécution en un seul passage d'Aurora, où la fréquence acoustique du moteur rugissant s'accorde parfaitement avec l'accélération visuelle et la physique de la friction des pneus.
Entraînement à grande échelle : Colossus
Ils ont entraîné ce modèle sur le supercalculateur Colossus de xAI. Le site géant utilise environ 555 000 GPU NVIDIA et consomme près de 2 gigawatts d'énergie. C'est officiellement le plus grand cluster d'entraînement IA sur un seul site au monde. Cette configuration massive est le secret derrière la façon dont Aurora mélange quatre types de médias différents sans réduire la qualité.
Capacités clés : Image-to-Video, paramètres de format et modes de qualité
Bien que Grok prenne en charge le text-to-video, sa véritable utilité en entreprise brille dans les flux de travail Image-to-Video (I2V). En fournissant au modèle une image de référence statique, vous verrouillez instantanément les caractéristiques du personnage, transférant le plus gros du travail d'un texte descriptif vers des contrôles mécaniques précis. Avant de vous plonger dans les modes de style, vous devez configurer les contraintes principales du pipeline.
Quelles sont les limites vidéo, les ratios d'aspect et les résolutions pour Grok Imagine ?
Transformer des images en vidéos est l'une des fonctionnalités les plus utiles de Grok Imagine. Il vous suffit de télécharger une photo fixe et de taper un prompt simple pour décrire le mouvement. Le modèle anime ensuite l'image et ajoute l'audio correspondant en même temps. Vous pouvez contrôler entièrement le format final via quatre paramètres : durée, fréquence d'images, résolution et forme.
Durée et fréquence d'images
Un contrôle granulaire de la durée vous permet de demander n'importe quelle seconde entière de 1 à 15. Cela étend la limite précédente de 10 secondes de 50 % tout en maintenant la cohérence temporelle sur la fenêtre plus longue. Toutes les sorties sont rendues à une base fixe de 24 FPS.
Options de résolution
| Résolution | Qualité | Vitesse de traitement |
| 480p | Définition standard | Plus rapide (défaut) |
| 720p | HD (résolution 720p) | Plus lent |
Pour les livrables finaux ou la distribution sur les réseaux sociaux, le 720p est le choix pratique. Utilisez le 480p pour une itération rapide et des tests de prompt.
Variations du ratio d'aspect
Sept variations de ratio d'aspect sont prises en charge :
| Ratio | Meilleur cas d'utilisation |
| 16:09 | Widescreen / YouTube (défaut) |
| 9:16 | TikTok / Instagram Reels / Stories |
| 1:01 | Miniatures sociales |
| 4:3 / 3:4 | Présentations / portraits |
| 3:2 / 2:3 | Formats photo |
Pour la génération image-à-vidéo, la sortie se règle par défaut sur le ratio d'aspect natif de l'image d'entrée, sauf indication contraire.
Directives de prompt engineering pour le mouvement cinématographique et l'identité zero-shot
Comme le moteur xAI Aurora repose sur la modélisation conjointe des jetons, votre stratégie de prompt doit évoluer. Vous n'avez plus besoin de consacrer des jetons à la description de l'apparence physique d'un personnage — l'image d'entrée s'en charge via la préservation de l'identité zero-shot. Au lieu de cela, votre prompt doit se concentrer strictement sur le mouvement directionnel, le comportement de la caméra et, crucialement, l'environnement acoustique que vous souhaitez que le moteur génère en tandem.
Comment rédiger des prompts pour Grok Imagine Video pour obtenir les meilleurs résultats ?
Le principe le plus important : comme Grok Imagine prend en charge la préservation de l'identité zero-shot, le modèle transfère l'apparence du sujet directement depuis l'image d'entrée. Vous n'avez pas besoin de redécrire la couleur des cheveux, les vêtements ou les traits du visage. Consacrez chaque mot à la dynamique du mouvement, à l'environnement et à la direction de la caméra.
La syntaxe de prompt optimale
Mélangez et associez ces blocs de jetons optimisés pour créer des environnements cinématographiques hautement contrôlés :
| Action & Mouvement | Dynamique de la caméra | Acoustique & Environnement |
| ...marche avec assurance, manteau flottant | Zoom travelling arrière lent | ...reflets néon ondulant sur pavé mouillé. SFX : Pluie battante sur l'asphalte |
| ...sprinte dans une foule dense, regard en arrière | Prise de vue en contre-plongée, rythme rapide | ...sous des néons fluorescents qui vacillent. SFX : Murmures de foule et respiration lourde |
| ...se retourne lentement, ouvre les yeux | Travelling macro de gauche à droite | ...profondeur de champ courte, poussières en suspension. SFX : Basses cinématographiques profondes |
Scénario A : Séquence de poursuite Cyberpunk, haute dynamique, synchronisation audio lourde
Prompt :
Action & Sujet : Un homme court rapidement dans une ruelle mouillée éclairée par des néons.
Dynamique de la caméra : La caméra reste basse et le suit de près. L'arrière-plan défile rapidement et des lumières vives traversent l'écran.
SFX : Une musique électronique rapide se mélange avec les pas dans les flaques d'eau et des sirènes lointaines. Les battements correspondent parfaitement aux lumières néon clignotantes.
Objectif du test : Ce test vérifie la capacité du moteur Aurora à gérer les formes lors de mouvements rapides. Il évalue également la perfection avec laquelle le moteur synchronise les sons avec le visuel, comme l'accord des battements synthétiques avec les néons clignotants.
Les points forts (ce que Grok a réussi) :
- Rétention d'identité Zero-Shot : La transition depuis l'image source statique est impeccable. La texture du cuir plissé du trench-coat et les cheveux sombres ébouriffés du personnage restent parfaitement stables sans aucune déformation d'identité.
- Cohérence physique : Grok gère le sprint à haute vélocité sans aucun dédoublement de membre ou découpage de vêtement — un point de défaillance notoire pour les rivaux de diffusion.
- Physique de l'éclairage dynamique : Les reflets néon roses et bleus sur le pavé mouillé changent précisément en synchronisation avec l'angle de suivi avant de la caméra.
Les faiblesses (les goulots d'étranglement) :
- Biais des jetons audio : Bien que la synchronisation audio native en un seul passage soit impressionnante, le moteur a fortement donné la priorité au jeton « musique synthwave », étouffant complètement les SFX localisés de « flaques d'eau ».
- Compression du mouvement : À 720p, le mouvement rapide de la caméra provoque un léger flou sur les bords et des artefacts numériques autour du texte d'arrière-plan lointain comme "MIDNIGHT DINER".
Scénario B : Dialogue cinématographique et poussée émotionnelle
Prompt :
Action & Sujet : Elle délivre un discours de film tendu, chuchotant "It ends tonight" avec une conviction totale.
Dynamique de la caméra : La caméra s'approche lentement de son visage juste au moment où une rafale de vent décoiffe ses cheveux.
SFX : Sa voix calme correspond parfaitement aux mouvements de ses lèvres, mélangée avec une rafale de vent soudaine et forte soufflant dans le micro et froissant ses vêtements.
Objectif du test : Cela sert de test de résistance définitif pour l'intégration multi-jetons du moteur xAI Aurora. Il force le modèle à exécuter une synchronisation labiale native impeccable et une mécanique musculaire faciale dynamique tout en calculant simultanément l'interaction physique chaotique du mouvement des cheveux/vêtements, le tout assorti d'effets sonores environnementaux réalistes en un seul passage d'inférence.
Les points forts (ce que Grok a réussi) :
- Synchronisation labiale native parfaite : Les mots prononcés "It ends tonight" correspondent parfaitement aux mouvements des lèvres et de la mâchoire du personnage. Cela se produit naturellement sans édition supplémentaire.
- Rétention des micro-expressions : Ses taches de rousseur, ses petits clignements d'yeux et son regard fixe restent exactement en place. Cela montre que le moteur maintient son identité stable même lors de plans rapprochés.
- Simulation de la physique du vent : Juste au moment où elle finit de parler, une brise soudaine traverse ses cheveux sombres. Les mèches bougent de manière réaliste et conservent leur volume naturel.
Les faiblesses (les goulots d'étranglement) :
- Artefacts audio : La voix générée, bien que bien calée, présente un timbre robotique légèrement compressé, manquant de la texture brute et soufflée demandée dans le prompt.
- Micro-morphing temporel : Pendant la séquence de froissement des cheveux sous le vent, un léger mélange de textures se produit autour de l'oreille et de la racine des cheveux, où le moteur peine légèrement à séparer les cheveux en mouvement de l'arrière-plan cutané statique.
Atténuation des pièges : La matrice de contre-exemple
Comme Grok Imagine ne prend pas en charge de paramètre de prompt négatif dédié dans l'endpoint public actuel, les ingénieurs de pipeline doivent s'éloigner des heuristiques de prompt traditionnelles basées sur la diffusion :
- ❌ L'approche incorrecte (état d'esprit diffusion) : "Un homme qui court, très détaillé, 4k, pas de flou, pas de distorsion, éclairage cinématographique."
- Analyse éditoriale : Cela remplit la fenêtre de contexte avec des jetons inutiles et introduit des expressions négatives comme "pas de flou". Un réseau MoE autorégressif comme Aurora peut mal interpréter ces termes comme des ancres sémantiques, générant accidentellement la distorsion que vous voulez éviter.
- ✅ L'approche correcte (état d'esprit natif Aurora) : "Foule avec assurance dynamiquement. Mise au point nette partout, textures cinématographiques immaculées, rayons divins volumétriques perçant à travers la poussière."
- Analyse éditoriale : Cela remplace les exclusions par des descriptions spatiales et physiques affirmatives et déterministes, dirigeant proprement le chemin de prédiction des jetons du moteur vers un rendu net.
Conseils de pro :
La cohérence temporelle se dégrade lorsque les prompts introduisent des instructions spatiales contradictoires, comme des commandes simultanées de zoom avant et de panoramique vers la droite. Gardez les mouvements de caméra uniques et directionnels. Pour les clips de plus de 8 secondes, ancrez le prompt autour d'un arc de mouvement continu plutôt que de multiples coupes de scène.
Intégration de l'API Grok Imagine Video Generation : Démarrage rapide avec Python et REST
Le passage de la conceptualisation créative à la mise à l'échelle en production nécessite de pousser ces paramètres via la passerelle API officielle de xAI. Selon votre infrastructure actuelle et si vous préférez un traitement automatique en arrière-plan ou une boucle personnalisée légère, xAI propose deux voies d'implémentation distinctes.
Comment appeler l'API Grok Imagine pour la vidéo ?
Il existe deux voies prises en charge pour appeler l'API Grok Imagine : le client natif xai_sdk (qui gère automatiquement le polling) et l'approche REST base_url compatible OpenAI via https://api.x.ai/v1. Les deux nécessitent une authentification par clé API définie comme variable d'environnement.
Prérequis
Avant d'écrire le moindre code, suivez ces étapes :
- Générez une clé API sur console.x.ai
- Exportez-la dans votre terminal : export XAI_API_KEY="votre-clé-ici"
- Installez le SDK : pip install xai-sdk
Voie 1 : xai_sdk natif (Recommandé)
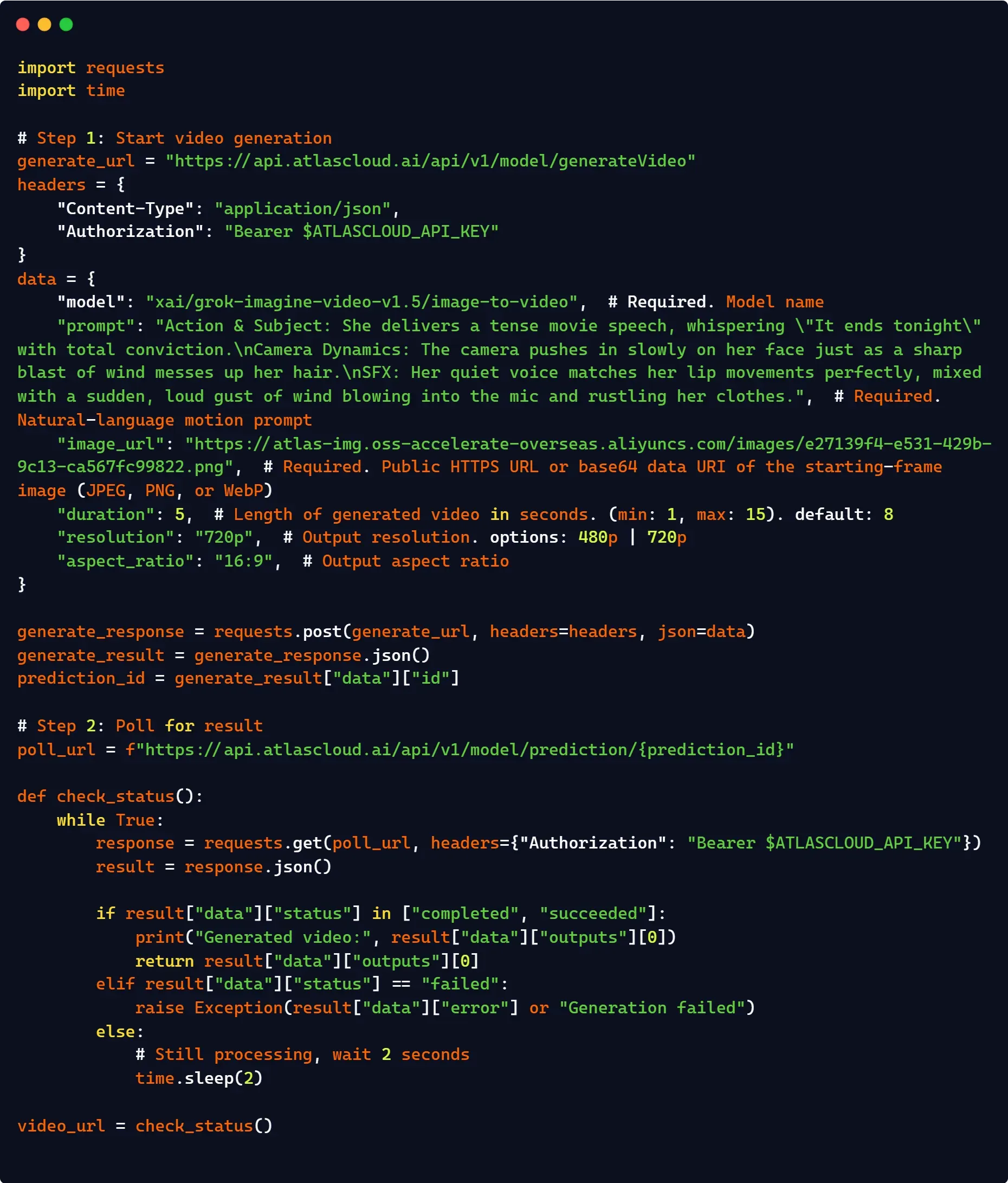
Le client xai_sdk enveloppe en interne toute la boucle de polling asynchrone, de sorte que vous recevez un objet vidéo complet avec un seul appel au endpoint video.generate :
plaintext1import os 2import xai_sdk 3 4client = xai_sdk.Client(api_key=os.getenv("XAI_API_KEY")) 5 6# Assurez-vous de passer l'image de référence pour les flux de travail Image-to-Video 7response = client.video.generate( 8 model="grok-imagine-video", 9 image="votre image", # URL requise ou base64 10 prompt="votre prompt", 11 duration=5, 12 aspect_ratio="16:9", 13 resolution="720p", 14) 15 16# CORRIGÉ : Aligné avec le schéma de réponse standard de xai_sdk 17print(f"Génération réussie. URL de la vidéo : {response.video.url}")
Aucun polling manuel n'est requis. Le SDK soumet la demande, attend la fin et renvoie l'URL.
Voie 2 : API REST standard (Boucle asynchrone personnalisée)
Pour les environnements où le SDK natif n'est pas disponible, utilisez les endpoints HTTP sous-jacents. Comme la génération vidéo est asynchrone, vous devez implémenter manuellement une séquence de polling pour suivre l'état de l'exécution :
plaintext1import os 2import time 3import requests 4 5headers = { 6 "Authorization": f"Bearer {os.environ['XAI_API_KEY']}", 7 "Content-Type": "application/json", 8} 9 10payload = { 11 "model": "grok-imagine-video", 12 "image": "votre image", 13 "prompt": "prompt", 14 "duration": 5, 15 "aspect_ratio": "16:9", 16 "resolution": "720p" 17} 18 19# 1. Soumettre la demande de génération vidéo 20res = requests.post("https://api.x.ai/v1/videos/generations", headers=headers, json=payload) 21res.raise_for_status() 22request_id = res.json()["request_id"] 23 24# 2. Interroger le statut jusqu'à ce que ce soit prêt 25while True: 26 poll = requests.get(f"https://api.x.ai/v1/videos/{request_id}", headers=headers) 27 data = poll.json() 28 29 if data["status"] == "done": 30 # CORRIGÉ : Aligné avec le schéma JSON officiel de xAI 31 print(f"Succès ! Actif disponible à : {data['video']['url']}") 32 break 33 elif data["status"] in ["expired", "failed"]: 34 print(f"La génération a échoué avec le statut : {data['status']}") 35 break 36 37 time.sleep(5) # Intervalle de limitation de débit sûr
Référence du statut de polling
L'API renvoie l'une des quatre valeurs de statut pendant la génération :
| Statut | Signification |
| pending | En cours de traitement |
| done | Vidéo prête, URL disponible |
| expired | Demande expirée |
| failed | Erreur de génération |
Interrogez toutes les 5 secondes pour rester dans des limites de débit raisonnables. Le SDK utilise par défaut des intervalles de 100 ms, mais 5 secondes sont pratiques pour les flux de production.
Alternative de production : Rationalisation via la passerelle API Atlas Cloud
Pour les pipelines d'entreprise nécessitant une concurrence avancée, une facturation unifiée ou un routage à haute disponibilité, l'intégration via une passerelle gérée par un tiers comme Atlas Cloud est une alternative de production viable. Au lieu de gérer localement vos propres boucles de polling asynchrone complexes et vérifications d'état, l'enveloppe unifiée d'Atlas Cloud gère automatiquement la mise en file d'attente côté serveur et la persistance de l'état.
De plus, elle offre un remplacement transparent en acheminant les demandes via une URL de base unifiée, minimisant les changements de code tout en débloquant des limites de débit de niveau entreprise qui dépassent généralement les seuils des niveaux publics standard de xAI.
Performances comparatives : Coût, latence et comparaisons avec les concurrents
Les sorties audiovisuelles haute fidélité ne sont viables pour les pipelines d'entreprise que si elles s'alignent sur des budgets informatiques et des exigences de latence stricts. Pour voir où se situe Grok sur le marché, des tests de résistance tiers cartographient ses vitesses de génération et ses coûts par seconde directement par rapport aux géants établis de l'industrie.
Grok Imagine Video est-il plus rapide et moins cher que les autres outils vidéo IA ?
Sur des benchmarks indépendants, la réponse est largement positive. Grok Imagine Video a fait ses débuts à la première place du classement Image-to-Video de l'Artificial Analysis Video Arena avec un classement Elo de 1404 ±6, détrônant Seedance 2.0 de ByteDance de la première position.
Comparaison directe avec les concurrents
| Modèle | Développeur | Durée Max | Résolution Max | Audio Natif |
| Grok Imagine V1.5 | xAI | 15s | 720p | Oui |
| Comparaison Seedance 2.0 | ByteDance | 4–12s | 720p | Oui |
| Veo 3.1 | 8s | 1080p | Oui | |
| Sora 2 | OpenAI | 20s | 1080p | Oui |
| Runway Gen-4 | Runway | 10s | 1080p | Partiel |
Vitesse d'inférence et latence
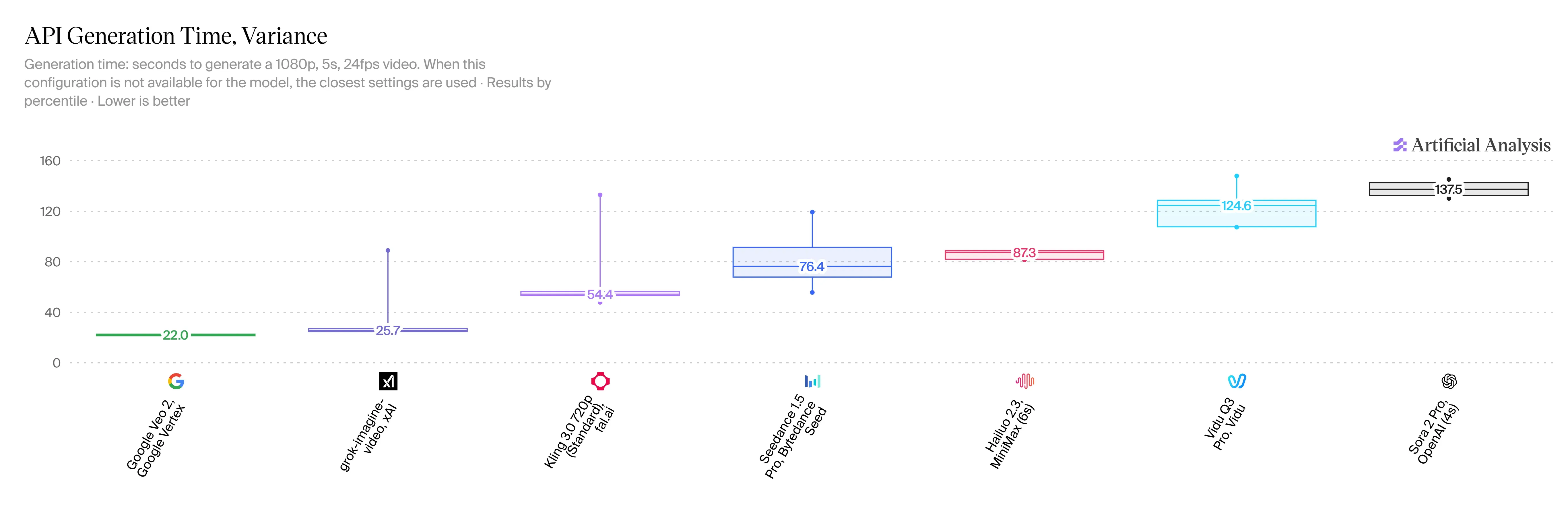
La V1.5 est incroyablement rapide, et c'est un énorme avantage pour les utilisateurs. Vous pouvez créer un clip de 5 secondes en 720p en seulement 20 à 30 secondes chrono. Par rapport à HappyHorse 2.3, cela réduit votre temps d'attente par 2 ou 3. Nous n'avons toujours pas de statistiques de vitesse officielles pour Veo 3.1, mais les gens en ligne disent qu'il faut plus d'une minute complète pour un clip similaire.
Structure de prix
La structure de prix par seconde via des passerelles API tierces telles qu'Atlas Cloud commence à environ 0,096 USD par seconde de vidéo générée. À ce tarif, un clip de 10 secondes coûte environ 0,96 USD, ce qui rend l'expérimentation rentable réellement accessible aux créateurs indépendants et aux petites équipes itérant sur plusieurs variantes de prompt avant de s'engager dans une production finale.
Sécurité d'entreprise, confidentialité des données et conformité du contenu
Le déploiement d'actifs médiatiques propriétaires ou de contenu destiné aux clients dans n'importe quel système IA basé sur le cloud soulève des questions juridiques nécessaires. Pour les maisons de production commerciale, savoir où atterrissent vos entrées génératives — et comment elles sont isolées — est tout aussi important que la qualité finale de la sortie.
xAI utilise-t-il mes données API ou mes vidéos générées pour entraîner ses modèles ?
C'est l'une des questions les plus fréquentes de la part des entreprises adoptantes, et elle mérite une réponse directe. Selon les conditions d'utilisation des développeurs de xAI, les entrées et sorties API traitées via la plateforme sont soumises à une révision des politiques de contenu pour le filtrage de sécurité, mais sont gérées selon des principes de confidentialité des données dès la conception (Privacy by Design) qui séparent les données d'inférence des pipelines d'entraînement publics.
Aperçu du cadre de conformité
Les fournisseurs de passerelles API tiers offrant un accès à Grok Imagine, tels qu'Atlas Cloud, publient leurs propres certifications de conformité indépendantes :
| Norme de conformité | Statut |
| Conformité SOC 2 Type II | Certifié |
| Résidence des données RGPD | Aligné |
| HIPAA | Éligible |
Limites de confidentialité clés pour les utilisateurs professionnels
Les professionnels évaluant Grok Imagine pour des flux de travail commerciaux doivent noter ce qui suit :
- Les sorties vidéo générées sont renvoyées sous forme d'URL hébergées temporaires et ne sont pas stockées de manière permanente par défaut.
- La révision de la politique de contenu filtre les sorties pour les violations de sécurité avant la livraison, mais ne conserve pas le contenu pour réutilisation.
- Les exclusions d'entraînement de modèle s'appliquent aux utilisateurs de l'API : vos prompts et médias générés ne sont pas réinjectés dans les boucles d'entraînement des modèles publics.
- L'alignement sur la résidence des données RGPD signifie que les pratiques de traitement des données répondent aux normes européennes pour les équipes opérant dans plusieurs juridictions.
Pour les déploiements en entreprise nécessitant des accords de traitement de données formels ou des politiques de rétention personnalisées, un engagement direct avec l'équipe entreprise de xAI via x.ai est l'étape suivante appropriée.






