
Kling 2.6 est la mise à jour la plus significative de Kling AI à ce jour, mais elle s'accompagne d'une mise en garde notable que vous devez connaître avant de vous lancer.
Cette version marque la première fois que Kling propose un modèle de synchronisation audio native. Auparavant, chaque vidéo générée était essentiellement un film muet. Les créateurs devaient ajouter manuellement les voix off, les effets sonores et le bruit de fond après la création de la vidéo. Le nouveau modèle VIDEO 2.6 change tout. Il crée simultanément les visuels, les voix off réalistes, les effets sonores correspondants et l'audio d'ambiance. Cette fonctionnalité place l'outil dans une catégorie totalement différente.
Ce qui fonctionne bien
Ce modèle excelle dans la synchronisation du son et de l'image. Le rythme de la voix, le bruit de fond et les actions à l'écran s'alignent parfaitement. Cela met fin au décalage habituel entre la vidéo et les pistes audio séparées. Les sons cinématographiques sont incroyablement réalistes. Vous pouvez entendre clairement des détails comme le crépitement d'un feu, la pluie dans la rue et le brouhaha d'une foule. Le support couvre six types audio :
| Type audio | Cas d'utilisation |
| Narration vocale | Vidéos produit, vlogs |
| Dialogue multi-personnages | Interviews, sketchs |
| Chant / Rap | Performance musicale |
| Son ambiant | Nature, scènes urbaines |
| Effets sonores d'objet/action | Impacts, bruits mécaniques |
| Son mixte | Production immersive complète |
La limite principale
Les scènes de dialogue impliquant trois interlocuteurs ou plus peuvent produire une attribution de voix incohérente. Pour obtenir la synchronisation audiovisuelle la plus fiable, les créateurs doivent s'en tenir aux échanges entre deux personnages ou envisager un cadrage alternatif.
Comparaison
La version 2.6 représente un grand bond en avant par rapport aux anciens modèles muets. Certains utilisateurs pourraient avoir besoin d'un contrôle parfait ou de résultats massifs de haute qualité. Ces utilisateurs devraient plutôt essayer Kling 3.0. Cependant, la plupart des créateurs de contenu donnent des avis très positifs sur Kling 2.6 car il offre une excellente qualité pour le prix.
Anatomie de l'audio natif de Kling : Plongée dans les dialogues, les effets sonores et l'ambiance
Kling 2.6 ne se contente pas d'ajouter de l'audio par-dessus la vidéo. Il génère les trois couches audio simultanément avec les images visuelles en un seul passage. Voici comment fonctionne chaque couche en pratique.
Dialogues et parole
La génération de dialogues de Kling AI couvre une gamme plus large que ce à quoi s'attendent la plupart des créateurs. Ce modèle gère facilement les discours en solo, les dialogues entre personnages, la narration, le chant et le rap. Il ajuste le ton émotionnel pour correspondre à chaque style. De plus, l'outil est bilingue et prend naturellement en charge les sorties vocales en anglais et en chinois. Si vous saisissez d'autres langues, le modèle les traduit automatiquement en anglais pour la génération vocale sans affecter le résultat vidéo global.
La vidéo de 8 secondes ci-dessus démontre notre sortie directe en utilisant Kling 2.6 via la plateforme d'orchestration Atlas Cloud. En téléchargeant une image de base haute résolution du locuteur et une piste vocale anglaise pré-enregistrée de 8 secondes, le moteur a traité la synchronisation labiale nativement.
Remarquez comment la synchronisation des muscles faciaux correspond parfaitement à des phonèmes complexes sans la distorsion buccale robotique habituelle de la "vallée de l'étrange". Cela sert de modèle parfait pour des actifs de porte-parole de marque générés rapidement par IA.
Règles rapides pour gagner du temps :
- Surveillez les majuscules. Utilisez des minuscules pour les mots courants. Gardez les majuscules pour les noms propres et les acronymes.
- Identifiez vos locuteurs. Donnez à chaque personne une étiquette comme [Personnage A] ou [Personnage B]. Cela empêche l'IA de mélanger leurs voix.
- Décrivez l'ambiance. Placez des notes de ton juste à côté de l'étiquette. Par exemple, écrivez [Journaliste, voix calme et assurée].
Effets sonores (SFX)
Les effets sonores vidéo par IA dans la 2.6 sont déclenchés par le contexte plutôt qu'assignés manuellement. Le modèle lit la description de la scène et en déduit les sons appropriés. L'IA génère des sons directement basés sur vos mots d'action. Elle peut créer des pas sur du gravier, du verre qui se brise, des crissements de pneus ou un bourdonnement de machine. Pour obtenir les meilleurs résultats, nommez clairement la source sonore spécifique. Par exemple, écrire [Porte en bois qui claque, bruit fort] fonctionne beaucoup mieux que de simplement dire "il y a un bruit".
Son ambiant
La synthèse audio ambiante gère la couche environnementale : murmure de café, pluie contre une vitre, vent dans un champ, arrivée d'un métro. Ces pistes d'arrière-plan se jouent sous vos dialogues et effets sonores. Elles ajoutent une réelle profondeur à votre vidéo. Vous devez nommer le cadre spécifique dans votre prompt. Par exemple, utilisez des termes comme [acoustique de petite pièce] ou [réverbération de hall ouvert]. Cela donne au modèle un objectif clair et améliore l'audio.
Durée : Sortie de 5 secondes contre 10 secondes
Ce choix affecte directement la stabilité audio. La décision entre une vidéo Kling de 5 secondes ou 10 secondes compte surtout pour le contenu riche en paroles.
| Type de contenu | Durée recommandée | Raison |
| Ambiance seule / SFX | 5s | Sortie nette et précise |
| Monologue / Narration | Au choix | Dépend de la longueur du script |
| Dialogue multi-personnages | 10s | Changement de voix plus stable |
| Chant / Rap | 10s | Évite la coupure des paroles |
Pour les scènes de chant ou de dialogue, l'utilisation du paramètre de 10 secondes est recommandée pour des résultats plus complets et stables. Les clips plus courts fonctionnent bien pour l'atmosphère pure ou l'association action-son, mais tout ce qui implique des lignes parlées bénéficie de la fenêtre plus longue pour éviter une dérive audio dans les secondes finales.
La formule de prompt parfaite pour une synchronisation audiovisuelle impeccable dans Kling 2.6
La plupart des problèmes de synchronisation dans Kling 2.6 ne viennent pas du modèle. Ils viennent de prompts qui laissent trop de place à l'interprétation. Considérez votre prompt comme les instructions d'un réalisateur : plus vous définissez précisément chaque élément, moins le moteur d'inférence a besoin de deviner, et c'est dans les suppositions que le rythme se brise.
La formule centrale
Ce modèle de prompt Kling correspond directement à la façon dont le modèle traite la génération :
Scène → Sujet → Mouvement et Caméra → Plan Audio
La structure officielle du prompt est : Scène (description de la scène) + Élément (description du sujet) + Mouvement (description du mouvement) + Audio (dialogue / chant / effets sonores / musique) + Autre (style / émotion / caméra).
Chaque bloc alimente une partie différente du pipeline de génération. Omettre l'un d'entre eux force le modèle à combler le vide, ce qui entraîne la rupture du rythme audiovisuel.
Analyse bloc par bloc
| Bloc | Que inclure | Erreur courante |
| Scène | Lieu, éclairage, moment de la journée | Trop vague : "une pièce" |
| Sujet | Apparence, rôle, position dans le cadre | Personnages sans nom ou uniquement avec des pronoms |
| Mouvement et Caméra | Séquence d'action, langage de contrôle caméra Kling (zoom lent, travelling, gros plan) | Aucune instruction de caméra |
| Plan Audio | Dialogue entre guillemets, étiquette d'émotion, étiquette SFX, couche ambiante | Dialogue noyé dans la prose descriptive |
Exemple prêt à l'emploi : L'anatomie d'un rendu parfait
En raison des contraintes d'API régionales et des goulots d'étranglement sur la plateforme native de Kling, l'utilisation du pipeline kling-v2.6-std-avatar sur Atlas Cloud est le chemin le plus fiable pour une production automatisée à haut volume. Bien que ce niveau spécifique vous limite à un format de tête parlante statique plutôt qu'à des scènes dynamiques multi-agents, il excelle particulièrement dans le mappage phonétique précis.
Pour prouver l'autorité de notre Formule Centrale, nous avons exécuté le blueprint exact ci-dessus via Kling 2.6 (niveau kwaivgi-kling-v2.6-std-avatar) via la plateforme d'orchestration Atlas Cloud. Le clip de 2 secondes ci-dessus représente la sortie commerciale brute, en un seul passage.
Décomposons pourquoi ce rendu atteint un naturalisme parfait au lieu de tomber dans la "vallée de l'étrange" :
- Verrouillage de la composition à l'image 0 : En utilisant une image initiale où l'hôte féminin est déjà positionné avec la montre connectée près de sa joue, nous avons éliminé le risque de déformation des membres. L'IA n'a pas à deviner les mécaniques osseuses complexes ; elle n'anime que les micro-expressions.
- Précision de la synchronisation labiale : Remarquez comment les mouvements des lèvres de l'hôte et le suivi dentaire correspondent parfaitement aux changements de syllabes rapides de "Zero lag. All day battery."
- Éclairage cinématographique et profondeur : La faible profondeur de champ (flou d'arrière-plan bokeh) filtre fortement les bruits de fond, forçant les pipelines de l'IA à concentrer 100 % de leur poids de calcul sur le rendu de pores de peau réalistes et de textures de vêtements nettes.
Durée et fenêtre audio
Connaître la longueur maximale des clips Kling AI est important pour la planification audio. Les sorties actuelles plafonnent à 10 secondes. Pour une démo produit comme l'exemple ci-dessus, 10 secondes est le bon choix : cela donne à la voix off l'espace nécessaire pour atterrir proprement sans couper le dernier mot. Les clips de cinq secondes conviennent à l'atmosphère pure ou aux paires action-SFX où aucune ligne parlée n'a besoin d'être terminée.
Planifiez la longueur de votre script en fonction de la longueur de votre clip avant d'écrire le prompt, pas après.
Workflow Image-vers-Vidéo : Maintenir la cohérence des personnages avec le contrôle de mouvement de Kling
Pour les créateurs professionnels, le chemin texte-vers-vidéo n'est qu'un point d'entrée. Le workflow Kling image-vers-vidéo est là où le contenu sérieux centré sur les personnages est construit, et lorsqu'il est associé au contrôle de mouvement de Kling 2.6, il vous donne un niveau de cohérence que le simple prompt textuel ne peut tout simplement pas égaler.
Comment le pipeline I2V ancre l'identité
Lorsque vous téléchargez une image de référence dans le mode Image-vers-Audiovisuel, elle agit comme un contrat visuel avec le modèle. L'image d'entrée spécifie l'apparence, la composition, le style et d'autres caractéristiques visuelles du sujet, rendant la vidéo générée plus proche de l'image originale. C'est le fondement de la cohérence des personnages IA : le modèle traite le visage, les vêtements et le cadrage téléchargés comme des contraintes fixes plutôt que comme des suggestions.
Cela compte surtout pour :
- Le contenu de porte-parole de marque nécessitant le même visage sur plusieurs clips
- Les personnages IP qui doivent conserver leur apparence entre les scènes
- Les hôtes de démo produit où l'identité visuelle fait partie de l'actif
Contrôle de mouvement : Projection de données physiques
Une image de référence verrouille l'apparence. Le contrôle de mouvement de Kling 2.6 ajoute la couche physique en projetant des données de geste, de posture et de mouvement à partir d'une référence de mouvement sur le personnage généré. La référence de mouvement agit comme un modèle de performance, le modèle transférant la mécanique corporelle tout en préservant l'identité visuelle ancrée par l'image d'entrée.
Cette séparation de l'identité (image) et du mouvement (clip de référence) est ce qui rend l'approche de la vidéo de référence pour animation IA plus fiable que la seule description du mouvement par texte.
Synchronisation labiale et alignement audio en I2V
La synchronisation labiale Kling 2.6 est gérée nativement lorsque l'audio natif est activé dans le mode Image-vers-Vidéo. La fonctionnalité de contrôle vocal vous permet de lier une voix spécifique à un personnage en utilisant le format [Personnage@NomVoix], permettant au modèle de reproduire avec précision les caractéristiques vocales pour interpréter le contenu spécifié.
| Couche d'entrée | Ce qu'elle contrôle |
| Image de référence | Visage, vêtements, cadrage, style visuel |
| Référence de mouvement | Gestes, changements de posture, rythme corporel |
| Liaison contrôle vocal | Timbre, style de débit, cohérence inter-langues |
| Bloc audio du prompt | Contenu du dialogue, étiquette d'émotion, couche ambiante |
Exemple prêt à l'emploi : Appliquer la Formule Centrale aux workflows Image-vers-Vidéo (I2V)
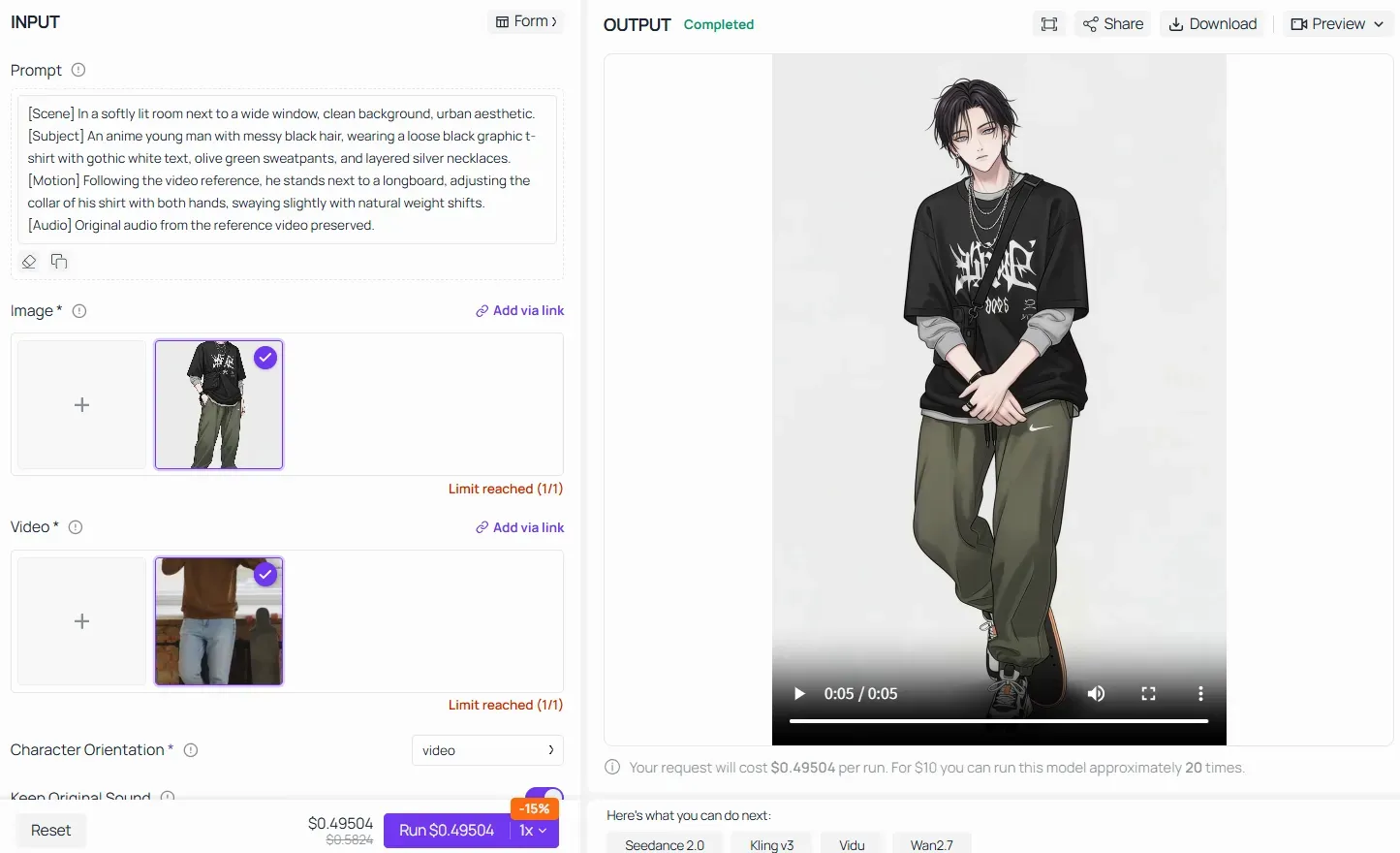
Lors de l'utilisation de fonctionnalités avancées comme la vidéo de référence / transfert de mouvement sur des plateformes comme Atlas Cloud, la Formule Centrale conserve une autorité absolue. Au lieu de donner à l'IA des instructions vagues comme "fais faire la même danse au personnage d'anime", vous devez structurer le prompt en décomposant la scène, en figeant les traits téléchargés du sujet et en verrouillant le mappage de mouvement :
En remplissant chaque bloc du pipeline, vous vous assurez que le modèle IA transfère de manière transparente la mécanique osseuse physique lourde de la vidéo du monde réel vers l'actif de personnage d'anime téléchargé sans détruire son identité visuelle.
Règle d'or pour le contrôle de mouvement dans Kling 2.6 : Votre prompt textuel n'a pas besoin de se soucier des petits détails mécaniques (comme "déplace le bras de 45 degrés"). Laissez la référence vidéo faire le gros du travail pour la cinématique. Utilisez plutôt vos blocs [Sujet] et [Scène] pour verrouiller impitoyablement le style visuel, les textures et les palettes de couleurs, en vous assurant que l'IA transfère la performance sans déformer l'identité de l'image originale.
Qualité d'image et limites pratiques
Gardez une règle majeure à l'esprit. Votre vidéo finale n'est aussi bonne que l'image que vous téléchargez.
Utilisez toujours des images haute résolution. Une image basse résolution rendra la vidéo granuleuse et floue. L'IA ne peut pas corriger ces détails désordonnés plus tard. Ce problème est vraiment visible sur les gros plans de visages.
Utilisez une image source à plus haute résolution et la cohérence de votre personnage sera maintenue sur les fenêtres de sortie de 5 et 10 secondes sans dégradation.
Dépannage technique : Résoudre les goulots d'étranglement de génération et la dérive audio
Même les créateurs expérimentés rencontrent des frictions avec Kling 2.6. Les deux problèmes les plus signalés sont les générations qui bloquent en cours de processus et les dialogues qui perdent la synchronisation après la moitié du clip. Les deux ont des causes identifiables et des correctifs pratiques.
Pourquoi Kling reste bloqué à 99 %
Si votre vidéo reste bloquée à 99 %, cela arrive généralement pour deux raisons. Premièrement, les serveurs peuvent être trop occupés. Deuxièmement, votre prompt peut être trop compliqué pour que le système le gère. L'IA essaie de construire tous les sons et visuels exactement au même moment. Si vous en mettez trop dans votre prompt, les instructions s'entrechoquent. Cette confusion ralentit le système ou le bloque complètement.
Correctifs à essayer par ordre :
- Réessayez plus tard. Actualisez votre page et soumettez le prompt pendant les heures creuses. Le petit matin fonctionne généralement mieux.
- Simplifiez. Divisez votre prompt compliqué en deux plus petits. Exécutez-les comme des générations vidéo séparées.
- Supprimez les descriptions ambiantes empilées et gardez une couche sonore dominante par clip.
- Réduisez le nombre de personnages si vous utilisez trois interlocuteurs ou plus dans une seule génération.
Comment corriger la dérive des dialogues
Corrigez la dérive des dialogues en traitant sa cause profonde : le traitement multi-locuteur du modèle se dégrade après la marque des 5-6 secondes lorsque trop d'instructions vocales sont en concurrence. Les performances peuvent se dégrader dans les scènes avec trois personnages ou plus.
| Scénario | Correctif recommandé |
| Dialogue à deux locuteurs de plus de 10s | Utilisez une durée de 10s avec des signaux clairs de changement de locuteur |
| Trois locuteurs ou plus | Divisez en clips séparés par paire de locuteurs |
| Dérive de long monologue | Raccourcissez le script pour qu'il tienne confortablement dans la fenêtre de 10s |
| Coupure du chant | Utilisez toujours le paramètre de 10s pour le contenu musical |
Réduire les artefacts et optimiser les crédits
Pour réduire les artefacts de génération, gardez les fichiers sources image-vers-vidéo en haute résolution et évitez les descriptions de scène contradictoires. Sur l'optimisation de la consommation de crédits, notez que l'audio natif activé coûte 10 crédits par seconde en mode Professionnel, contre 5 crédits par seconde avec l'audio désactivé. Faites vos brouillons sans audio, puis activez-le uniquement pour les rendus finaux afin d'étirer davantage votre budget de limitations de plateforme.
Kling 2.6 vs. Kling 3.0 vs. Wan 2.6 vs. Veo 3.1 : Comparaison frontale
N'attendez pas d'un outil vidéo IA qu'il fasse absolument tout. Lorsque vous voulez un audio intégré, le "meilleur" choix dépend simplement de votre propre budget, de votre workflow et de ce dont votre clip vidéo a réellement besoin.
Aperçu de la comparaison des fonctionnalités
| Fonctionnalité | Kling 2.6 | Kling 3.0 | Wan 2.6 | Veo 3.1 |
| Audio natif | Complet (Dialogue/SFX/Ambiance) | Complet (Sync en un passage) | Complet (Inclut Sync labiale) | Complet (Audio spatial 3D) |
| Longueur max du clip | 10s | 15s | 15s | 8s |
| Résolution max | 1080p | 4K natif | 1080p | 4K natif |
| Contrôle de mouvement | Fort (Squelettique/Réf. vidéo) | Fort (Verrouillage identité complet) | Modéré (Style/Transfert de mouvement) | Modéré (Physique dynamique des fluides) |
| Multi-shot | Non | Oui (Jusqu'à 6 plans en un passage) | Oui (Support texte long multi-scènes) | Non |
| Contrôle vocal | Oui | Oui | Non (Dépendant du prompt) | Non (Dépendant du prompt) |
| Tarification | USD0.048 - USD0.095/s | USD0.071 - USD0.357/s | USD0.018 - USD0.7/s | USD0.05 - USD0.2/s |
Note : La tarification se réfère à Atlas Cloud.
Où Kling 2.6 prend l'avantage
Kling 2.6 vs Wan 2.6 n'est pas un concours serré sur l'audio. Wan 2.6 n'a qu'un support audio partiel, tandis que Kling 2.6 offre un dialogue natif complet, des SFX et une superposition ambiante en un seul passage. Pour les créateurs qui ont besoin de clips complets et prêts à l'emploi sans post-production, Kling 2.6 est le workflow le plus propre.
Kling 2.6 coûte plus de 50 % moins cher que Veo 3.1. Si vous n'avez pas besoin d'une qualité vidéo de niveau hollywoodien, Kling est le choix bien plus intelligent. Il vous permet de créer d'énormes quantités de contenu sans exploser votre budget.
Où Veo 3.1 prend de l'avance
Veo 3.1 vs Kling video se résume au réalisme et à la spatialisation audio. Veo 3.1 génère des environnements sonores tridimensionnels où les sources audio se déplacent dans le champ stéréo, sortant en 48 kHz avec encodage AAC stéréo à 192 kbps. En mars 2026, aucun autre modèle vidéo IA majeur n'offre ce niveau de spatialisation audio. Pour des dialogues et un rendu de texte de qualité broadcast, Veo 3.1 reste le choix le plus fort.
Comparaison de la physique vidéo IA
Sur la physique vidéo IA, les modèles divergent clairement. Kling 2.6 offre une excellente fluidité de mouvement avec une simulation physique plus réaliste pour les mouvements humains, tandis que Veo 3.1 montre des incohérences physiques occasionnelles mais excelle dans l'éclairage et les textures.
Cadre de décision
- Choisissez Kling 2.6 pour : personnages contrôlés par la voix, production soucieuse du budget, contenu social, sortie audiovisuelle complète en un passage
- Choisissez Kling 3.0 pour : plans cinématographiques plus longs, storyboards multi-scènes, sortie 4K
- Choisissez Wan 2.6 pour : open-source, itération sans coût et tests de brouillon
- Choisissez Veo 3.1 pour : audio spatial, rendu de texte, publicités produit photoréalistes
Conclusion : Le nouveau rythme de la réalisation vidéo par IA
La chaîne de production vidéo traditionnelle, exporter les visuels, générer la voix off séparément, superposer les effets sonores, puis mixer le tout en post-production, ne s'applique plus lors de l'utilisation de Kling 2.6. Toute cette séquence se résume désormais à une seule soumission de prompt.
Les créateurs qui avancent le plus vite sont ceux qui traitent l'écriture de prompts comme un métier de réalisateur plutôt que comme une requête de recherche. Le vrai truc pour une vidéo de niveau pro est simple. Il vous suffit d'emballer vos plans de scène, sujet, mouvement et son dans un seul prompt clair.
En ce moment, Kling 2.6 est l'un des meilleurs outils disponibles. Il fonctionne très bien pour les grandes équipes de contenu, les créateurs solo et les studios marketing qui veulent une vidéo rapide et de haute qualité. Le plafond technique continuera de monter. Maîtriser la structure du prompt maintenant construit la base créative pour évoluer avec lui.






