
Le Google Nano Banana 2 Lite (connu sous le nom d'endpoint API gemini-3.1-flash-lite-image) est un outil d'IA compact et rapide, conçu pour une configuration d'application immédiate. Il s'agit de l'API d'image Google la plus abordable du marché. Capable de transformer du texte en images en seulement 4 secondes, cet outil est parfaitement adapté aux applications d'entreprise nécessitant une production massive et rapide de visuels.

L'attente interminable liée aux files d'attente de génération d'images automatisées constitue un goulot d'étranglement épuisant pour les développeurs concevant des applications à haute concurrence. Lorsque votre plateforme doit rendre dynamiquement des milliers de variantes de publicités localisées, d'avatars utilisateur ou de maquettes web rapides à la volée, le recours à des modèles créatifs haut de gamme fait grimper vos coûts de production et dégrade l'expérience utilisateur. La latence élevée et les frais importants par image contraignent souvent les équipes de développement à choisir entre la rapidité de l'application et leur budget opérationnel mensuel.
Google répond à cette problématique avec le dernier ajout à sa gamme de modèles créatifs. En séparant les niveaux de performance en fonction des exigences réelles de charge de travail, les développeurs peuvent désormais optimiser leurs pipelines de ressources à haute vélocité sans payer le prix fort pour des capacités de rendu inutiles. La solution réside dans un modèle de génération d'images léger et spécialisé, conçu pour un déploiement programmatique rapide.
Répondre à la demande pour l'API d'image Google la moins chère
Pour les équipes d'ingénierie gérant des flux de travail visuels à haut volume, les API de génération d'images traditionnelles représentent un défi financier majeur. Payer plusieurs centimes par image devient insoutenable à l'échelle de millions d'appels API automatisés. Cet obstacle économique a intensifié la demande pour une véritable API d'image Google au meilleur prix, capable de traiter des demandes en masse sans imposer une infrastructure complexe.
Le déploiement du modèle gemini-3.1-flash-lite-image redéfinit l'architecture de la génération d'images programmatique en abaissant le coût plancher. Au lieu de traiter chaque demande visuelle comme une œuvre d'art haut de gamme, cette architecture traite la génération d'images à haute vélocité comme une ressource utilitaire brute. Cela permet aux ingénieurs logiciels d'intégrer la création d'images fluide et en temps réel directement dans des applications multi-tenant et des logiciels sociaux interactifs, où l'efficacité des coûts est le principal indicateur opérationnel.
Analyse approfondie des performances du Nano Banana 2 Lite
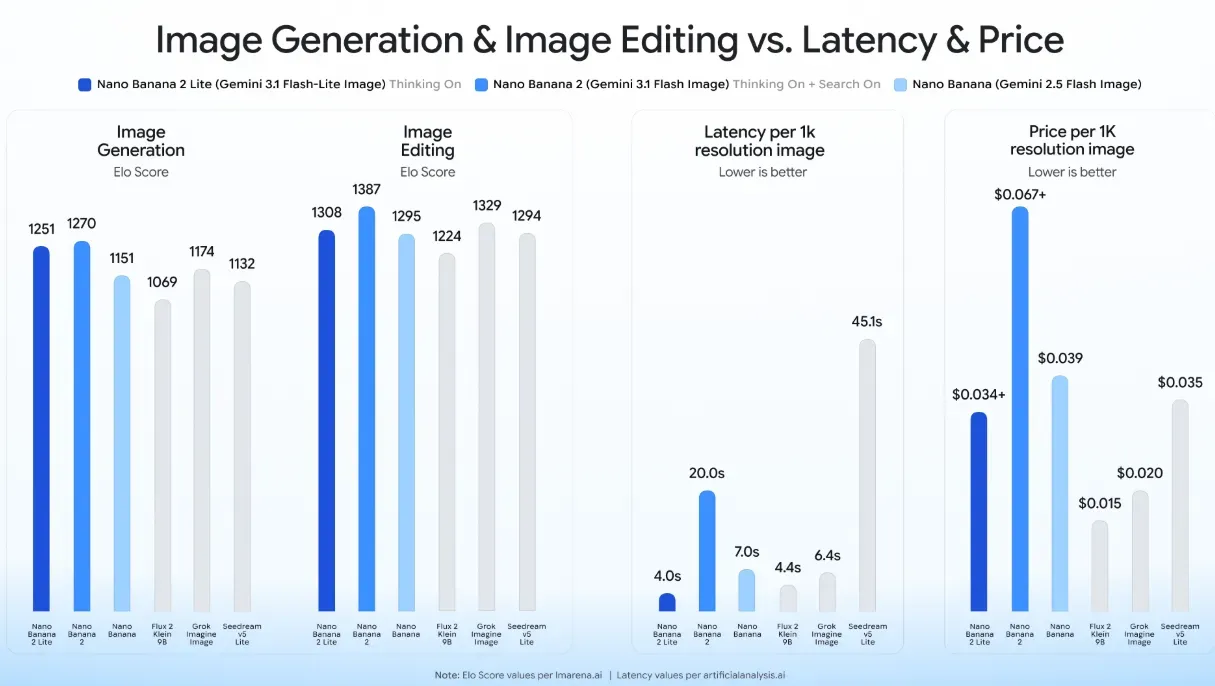
La désignation commerciale de ce modèle axé sur l'efficacité est Nano Banana 2 Lite. Ce modèle est conçu avec une attention stricte portée à la maximisation du débit de traitement et à la réduction de la latence. Les tests en conditions réelles et les spécifications officielles confirment que le modèle permet une génération texte-image en seulement 4 secondes. Ce temps de réponse rapide représente une accélération d'environ 5x par rapport aux modèles standard, transformant le flux de travail des développeurs d'une opération asynchrone basée sur des files d'attente en une expérience utilisateur synchrone quasi temps réel.
Métriques de performance du Nano Banana 2 Lite
| Dimension des paramètres | Spécification officielle / Métrique | Notes et paradigme opérationnel |
| Modalités prises en charge | Entrée : Texte, Image, Vidéo ; Sortie : Texte, Image | L'audio n'est pas pris en charge ; la vidéo est uniquement en entrée. |
| Limites de la fenêtre de contexte | Entrée max : 65 536 jetons ; Sortie max : 4 096 jetons | Optimisé pour une logique d'application rapide et à haute fréquence. |
| Capacités principales | Génération d'images, Images/texte entrelacés, Édition d'images, Édition d'image multi-tours | La génération d'images à partir d'une entrée vidéo n'est pas supportée. |
| Résolution de sortie | Strictement 1K (environ 1 Mégapixel) | Consomme exactement 1 120 jetons d'image de sortie par génération 1K. |
| Ratios d'aspect pris en charge | 1:1, 1:4, 4:1, 1:8, 8:1, 2:3, 3:2, 3:4, 4:3, 4:5, 5:4, 9:16, 16:9, 21:9 | Couvre parfaitement les besoins en e-commerce, réseaux sociaux et bannières. |
| Contraintes par prompt | Max 14 images en entrée ; Max 32 768 jetons de sortie | Le nombre de fichiers est limité par la fenêtre de contexte de 65 536 jetons. |
| Coût des jetons multimodaux | Image en entrée : 1 120 jetons/image ; Vidéo en entrée : 70 jetons/seconde (échantillonnés à 1 fps) | Des frais supplémentaires s'appliquent pour les modalités de texte. |
| Garanties de concurrence | Débit provisionné pris en charge | Crucial pour garantir une latence de 4 secondes sous une charge élevée. |
Les gains de performance du Nano Banana 2 Lite sur les anciens modèles découlent d'importantes mises à jour architecturales. Par rapport à l'ancien modèle gemini-2.5-flash-image, cette variante Lite offre des avancées techniques précises :
- Intégration des connaissances mondiales : Le modèle affiche une compréhension contextuelle très précise des lieux, des structures physiques et des mises en page spatiales abstraites, ce qui le rend très efficace pour le wireframing UI/UX rapide.
- Cohérence des personnages : Il maintient des identités de personnages stables et des détails d'objets structurels à travers des générations séquentielles. Cela permet aux ingénieurs de concevoir des logiciels de storyboarding itératifs ou des fonctionnalités d'essayage virtuel pour l'e-commerce.
- Typographie intégrée et localisation : Le système rend du texte lisible et propre directement dans les graphiques générés. Cela permet aux développeurs de construire instantanément des variantes publicitaires automatisées adaptées à différents marchés géographiques.
Décryptage de la tarification et de la mécanique des jetons du Nano Banana 2 Lite
| Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | Prix standard (/1M jetons) (<= 200K jetons entrée) |
| Entrée (texte, image, vidéo) | $0.25 |
| Sortie texte (réponse et raisonnement) | $1.50 |
| Sortie image | $30 |
Comprendre vos coûts opérationnels nécessite d'examiner attentivement la structure sous-jacente des jetons plutôt que de se fier aux moyennes marketing. Alors que les promotions de l'industrie indiquent un tarif fixe d'environ $0.034 pour 1 000 images, la facturation réelle de Google repose sur une infrastructure précise de jetons multimodaux. Les tarifs spécifiques de tarification de l'API Nano Banana 2 Lite sont répartis selon des mécanismes de transaction distincts.
Dans le cadre d'une utilisation standard via Google AI Studio ou la plateforme Gemini Enterprise Agent, les entrées texte, image ou vidéo coûtent exactement $0.25 par million de jetons. Les jetons de texte de sortie et de raisonnement structurel sont facturés à $1.50 par million. Lors de la génération d'une image standard en résolution 1K (~1 mégapixel), le système traite une charge utile de sortie fixe équivalente à $30.00 par million de jetons de sortie d'image. Cela correspond à un coût exact par image de $0.0336.
De plus, les ingénieurs peuvent optimiser massivement leur budget en utilisant l'exécution par lots asynchrone. Google offre une remise forfaitaire de 50 % pour les demandes non urgentes traitées par lots dans une fenêtre de 24 heures. Cela réduit le coût d'une image en résolution 1K à seulement $0.0168, ce qui en fait le choix définitif pour la génération de ressources en arrière-plan.
Comparaison architecturale : La famille des modèles créatifs de Google
Pour sélectionner le modèle le plus efficace pour votre pile de production, il est utile de comparer les structures de performance et de coût de la gamme complète des modèles d'image de Google. Chaque variante cible un seuil opérationnel différent.
| Métrique / Fonctionnalité | Gemini 3.1 Flash-Lite Image (Nano Banana 2 Lite) | Gemini 3.1 Flash Image (Nano Banana 2) | Gemini 3 Pro Image (Nano Banana Pro) |
| ID du modèle API | gemini-3.1-flash-lite-image | gemini-3.1-flash-image | gemini-3-pro-image |
| Prix des jetons d'entrée | $0.25 / 1M jetons | $0.50 / 1M jetons | $2.00 / 1M jetons |
| Prix jetons sortie image | $30.00 / 1M jetons | $60.00 / 1M jetons | $120.00 / 1M jetons |
| Coût image 1K standard | $0.03 | $0.07 | $0.13 |
| Coût image 1K par lots | $0.02 | Non disponible | Non disponible |
| Latence moyenne | ~4 secondes | ~6–8 secondes | ~10–12 secondes |
| Inconvénient majeur | Limite stricte 1K ; difficulté avec les textes denses et complexes. | Absence de réduction pour les opérations de masse. | Latence élevée et coûts de sortie limitant son usage en haute concurrence. |
| Cas d'usage idéal | Pipelines à haut volume, interactions en temps réel, bannières localisées. | Applications nécessitant une édition d'image conversationnelle poussée. | Création d'actifs cinématographiques, design complexe, fidélité textuelle maximale. |
Script d'intégration rapide (SDK) pour gemini-3.1-flash-lite-image
L'intégration de la génération d'images Google AI Studio dans un pipeline d'application existant peut se faire directement via le SDK natif Google GenAI. Le bloc de code ci-dessous montre comment initialiser le client et exécuter une requête asynchrone de texte à image ciblant l'endpoint gemini-3.1-flash-lite-image.
Python
python1import os 2from google import genai 3from google.genai import types 4 5def generate_bulk_asset(prompt_text: str, output_path: str):""" 6 Initialise le client Google GenAI et exécute une requête de génération 7 texte-image à faible latence utilisant le modèle optimisé gemini-3.1-flash-lite-image. 8 """# Initialiser le client ; nécessite la variable d'environnement GEMINI_API_KEY 9 client = genai.Client() 10 11 print(f"Envoi de la requête de génération pour le modèle : gemini-3.1-flash-lite-image") 12 13 try: 14 response = client.models.generate_images( 15 model='gemini-3.1-flash-lite-image', 16 prompt=prompt_text, 17 config=types.GenerateImagesConfig( 18 number_of_images=1, 19 output_mime_type="image/jpeg", 20 aspect_ratio="1:1", # Accepte les ratios standards (1:1, 16:9, 4:3) 21 person_generation="ALLOW_ADULT" 22 ) 23 ) 24 25 # Traiter et enregistrer l'image générée 26 for i, generated_image in enumerate(response.generated_images): 27 image_bytes = generated_image.image.image_bytes 28 full_path = f"{output_path}_asset_{i}.jpg" 29 with open(full_path, "wb") as f: 30 f.write(image_bytes) 31 print(f"Image 1K enregistrée avec succès : {full_path}") 32 33 except Exception as e: 34 print(f"L'exécution de l'API a échoué : {str(e)}") 35 36if __name__ == "__main__": 37 prompt = "Une maquette produit professionnelle d'un robot compagnon de bureau élégant sur un bureau propre, éclairage soigné" 38 generate_bulk_asset(prompt, "output_production")
Lors du déploiement à grande échelle, la sécurité et la conformité sont gérées automatiquement par l'infrastructure. Google intègre par défaut des filigranes SynthID invisibles et des informations d'identification C2PA dans les métadonnées de chaque image de sortie. Cela garantit la traçabilité et la conformité de toutes vos ressources générées sans nécessiter de post-traitement personnalisé.
Pérenniser votre pile de production avec des couches d'API unifiées
Bien que l'utilisation du SDK natif de Google soit parfaite pour des environnements isolés, le déploiement de ce flux de travail texte-image sur des applications d'entreprise multi-tenant nécessite souvent une couche de gestion d'API unifiée.
Les plateformes d'infrastructure comme Atlas Cloud ont décentralisé ce pipeline en fournissant des passerelles d'intégration prêtes pour la production pour cette variante de modèle spécifique. Via le hub Atlas Cloud Nano Banana 2 Lite, les développeurs peuvent désormais acheminer leurs flux de travail visuels à haute vélocité directement via une infrastructure API unifiée.
Se connecter via un hub comme Atlas Cloud permet à votre équipe technique de combiner l'outil vidéo rapide de 4 secondes avec des options de secours provenant d'autres modèles, tout en centralisant les statistiques d'utilisation et la facturation. Cela évite d'alourdir inutilement le code de vos serveurs principaux.
Dépannage des codes d'erreur API et des limites de débit
Si vous étendez votre application pour gérer des dizaines de milliers de requêtes simultanées, vous rencontrerez inévitablement des limitations. Une gestion fluide de ces embouteillages évite les plantages de votre application.
Gestion des erreurs 429 (Too Many Requests)
L'erreur la plus fréquente lors de pics de trafic est le message "429 Too Many Requests". Cela signifie que votre application a dépassé les limites de vitesse partagées allouées aux comptes de développement Google AI Studio. Pour résoudre ce problème, les développeurs doivent intégrer un algorithme de "backoff exponentiel" avec gigue (jitter) dans leurs boucles de requête. Pour les opérations d'entreprise exigeant une capacité garantie, les ingénieurs peuvent passer à des accords de débit provisionné (PT) au sein de la plateforme Gemini Enterprise Agent, qui réserve une allocation matérielle dédiée pour garantir un débit constant.
Résolution des erreurs 400 (Invalid Argument) et 403 (Forbidden)
Une erreur 400 indique généralement que vos paramètres de vidéo ont des tailles incorrectes ou des ratios d'aspect non pris en charge. Le plan Lite est très strict et limite les sorties à une résolution 1K. Assurez-vous que votre ratio d'aspect correspond aux standards autorisés (1:1, 16:9, etc.).
À l'inverse, une erreur 403 signifie qu'il y a un problème avec la clé API ou un blocage de sécurité. Google utilise des filtres automatiques pour vérifier tout texte. Si votre prompt enfreint ces règles de sécurité, le système bloquera la génération. Vous devrez reformuler le texte pour qu'il soit conforme aux directives de la plateforme.
Réalités du développeur : Intégrer nativement des flux de travail économiques
Déployer un modèle optimisé pour le budget implique d'en accepter les limitations pratiques :
- Le plafond strict de résolution 1K signifie qu'il ne peut pas produire de graphiques natifs 4K prêts pour l'impression.
- De plus, lorsqu'il est confronté à des prompts très complexes, le modèle peut parfois présenter des variations mineures dans la cohérence des personnages entre les transitions de scènes.
Pour atténuer ces inconvénients sans gonfler vos coûts opérationnels, vous pouvez enchaîner votre pipeline de génération dans un flux de travail d'édition multi-tours.
Plutôt que d'essayer de générer une scène complexe parfaite dès le premier essai, écrivez votre logique d'application pour générer un brouillon de base rapide de 4 secondes. À partir de là, utilisez des requêtes d'édition d'image conversationnelles pour modifier, éclairer ou échanger des objets spécifiques au sein de l'actif.
Pour les applications multimédias avancées, cette sortie image 1K peut être directement injectée dans des pipelines de génération vidéo comme Gemini Omni Flash, qui traite les tâches d'édition vidéo à un tarif abordable de $0.10 par seconde.
Le Nano Banana 2 Lite est-il fait pour votre pile technologique ?
Voici une analyse pour déterminer si votre équipe bénéficiera du Nano Banana 2 Lite ou si vous devriez viser les niveaux premium standard.
À qui ce modèle est-il destiné ?
- Développeurs d'applications à haute concurrence : Si votre logiciel gère des milliers de requêtes par minute (avatars, publicités dynamiques, e-commerce), ce modèle est fait pour vous.
- Ingénieurs logiciels soucieux des coûts : Pour les flux de travail à micro-budget où les dépenses opérationnelles sont un indicateur de survie. Son tarif par lot de $0.0168 élimine le goulot d'étranglement fiscal habituel.
- Architectes d'applications interactives : Pour les produits exigeant une boucle synchrone où les utilisateurs demandent un retour quasi temps réel.
Qui devrait éviter ce modèle ?
- Graphistes haute fidélité : Si votre application nécessite du rendu pour impression grand format, des bannières 4K natives ou des supports marketing cinématographiques complexes, la limite 1K sera insuffisante.
- Marketeurs visuels orientés texte : Bien que le modèle supporte la typographie, les applications exigeant des paragraphes complexes intégrés nativement devraient utiliser le niveau Gemini 3 Pro Image pour une fidélité textuelle absolue.
- Constructeurs multimédias orientés audio : Les équipes dont les boucles multimodales reposent fortement sur la synchronisation audio ou la génération à partir de flux audio continus doivent chercher ailleurs, l'audio n'étant pas pris en charge par ce niveau Lite.
FAQ
Comment gemini-3.1-flash-lite-image réduit-il les coûts par rapport aux niveaux standard ?
Le modèle réduit les coûts de développement standard de 50 % par rapport au modèle gemini-3.1-flash-image. En optimisant l'empreinte des jetons à $0.25 par million d'entrées et $30.00 par million de jetons de sortie d'image, le prix d'une image 1K tombe à $0.0336. Pour les tâches d'arrière-plan non urgentes, l'utilisation de l'API par lots réduit ce tarif à $0.0168 par image.
Le Nano Banana 2 Lite peut-il gérer les charges d'application d'entreprise à haute concurrence ?
Oui, le modèle est conçu spécifiquement pour répondre à ces exigences. Si les niveaux de développeur standard partagent un pool d'infrastructure commun, les équipes d'entreprise peuvent sécuriser des performances dédiées et hautement fiables en déployant un débit provisionné via la plateforme Gemini Enterprise Agent.
L'API d'image Google la moins chère sacrifie-t-elle la sécurité ?
Non. Chaque image générée automatiquement inclut un filigrane natif SynthID intégré directement dans la matrice de pixels, ainsi que des informations d'identification C2PA. Cela permet aux plateformes d'entreprise de maintenir une traçabilité totale et de vérifier l'authenticité de tous les actifs générés par IA avant toute diffusion publique.






