Résumé
À la mi-mai 2026, Qwen3.7-Max et Qwen3.7-Plus sont apparus discrètement sur le LM Arena. @Alibaba_Qwen a défini les attentes de la communauté avec cette phrase : « Alibaba #6 en texte, #5 en vision ». Le 2 juin, l'équipe Tongyi Qianwen d'Alibaba Cloud a officiellement lancé ce modèle d'agent multimodal. Il est déjà disponible sur Alibaba Cloud Model Studio et Qwen Chat, avec un accès API sous alibaba/qwen3.7-plus et un prix catalogue d'environ $0.40 / $1.60 par million de jetons en entrée/sortie.
Le positionnement officiel est clair : Plus est le modèle multimodal rentable ; Max est le produit phare pour le texte.
Nous avons passé une après-midi à exécuter une suite de tests rigoureux sur Qwen3.6-plus, Qwen3.7-plus et Qwen3.7-Max : réparation automatique de 10 bugs réels, 15 problèmes de mathématiques du concours AIME 2025, ainsi qu'une comparaison plus large sur la multimodalité, la vitesse et le coût.
Les résultats doivent être interprétés comme 5 observations au niveau des tâches, et non comme un classement général des modèles :
- Exécution unique de BugFind-10 : Plus a réussi tous les tests pytest externes. Dans cette suite de 10 tâches, avec le cadre officiel Stirrup et une exécution unique, Plus a obtenu 10/10 tandis que Max et 3.6-Plus ont obtenu 9/10. Cela indique une bonne adéquation à la tâche dans ce contexte ; cela ne doit pas être extrapolé en un classement général de codage.
- Mathématiques : Plus avec le mode réflexion activé a atteint le même score qu'en exécution unique que Max. Sur 15 problèmes de mathématiques de concours, Plus et Max ont tous deux répondu correctement à 14 ; dans ce test, Qwen3.7-plus a pris beaucoup moins de temps que Qwen3.7-Max (113s contre 303s par problème).
- Un saut de vitesse générationnel : Sur les tâches d'agent, le débit de bout en bout pour Qwen3.7-plus a atteint 147,5 t/s, tandis que Qwen3.6-plus n'a atteint que 41,5 t/s, soit une amélioration de 3,55x. Les tâches mathématiques que la génération précédente ne pouvait pas terminer sont devenues faciles à compléter.
- La multimodalité comporte encore des défauts : Dans nos tests multimodaux contrôlés, Qwen3.7-plus a correctement répondu à des questions simples sur les images, mais l'image officielle fournie en exemple, dog_and_girl.jpeg, a été décrite comme « un train et une foule ».
- Certaines capacités étaient proches de celles de Max, avec un avantage de latence : Dans plusieurs tests de cette série, Qwen3.7-plus a obtenu des résultats proches de Qwen3.7-Max tout en présentant une latence plus faible. Il ne s'agit pas d'une affirmation de classement général.
Vous trouverez ci-dessous les données de test complètes, la méthodologie et les recommandations de sélection de modèles pour les responsables techniques. Toutes les comparaisons sont limitées à ce petit échantillon, à une exécution unique et à un cadre fixe.
0. Contexte des capacités du modèle et du classement
La gamme de produits Alibaba Qwen s'était déjà stabilisée selon un modèle avec la génération 3.6 : Max = produit phare texte, Plus = modèle multimodal à long contexte. La version 3.7 poursuit cette logique :
| Dimension | Qwen3.7-Max | Qwen3.7-Plus |
|---|---|---|
| Modalités d'entrée | Principalement texte | Texte + image |
| Argument de vente typique | Plafond de raisonnement, agents long horizon | 1M de contexte, vision, réflexion hybride, prix unitaire inférieur |
| Arena (05-2026) | Environ #13 au classement texte global | Environ #16 sur la vision |
| Prix passerelle (01-06) | $1.25 / $3.75 par M | $0.40 / $1.60 par M |
1. Comment l'histoire officielle positionne-t-elle Plus ?
Le message de lancement d'Alibaba Qwen résume le message en une phrase :
« Un seul modèle. Voit, pense, code, agit. »
Les principaux arguments de vente sont : un agent hybride multimodal interactif avec une interface GUI et CLI unifiée, un agent de codage polyvalent et une généralisation à travers les frameworks d'agents. Le développeur principal de Qwen, shuai bai_, a ajouté :
Notre objectif est de transformer l'IA multimodale de la simple légende d'image passive en un résolveur de problèmes actif : capable de voir, de raisonner, d'écrire du code, d'exploiter des interfaces et de vérifier les résultats. C'est un pas vers une intelligence multimodale véritablement agentique.
Les publications sur les performances dans le fil officiel donnent le positionnement clé :
- La performance en texte est « proche du niveau Max » (affirmation du fournisseur)
- Les améliorations multimodales se concentrent sur les capacités d'agent principales : compréhension visuelle complexe, raisonnement visuel, utilisation d'outils et exécution de code/GUI.
| Affirmation courante sur X | Source | Notre résultat | Conclusion |
|---|---|---|---|
| Le texte Plus est « proche de Max » | Officiel | AIME avec réflexion : même score, 14/15 ; Plus était 2,68x plus rapide | Même score mathématique en exécution unique ; latence plus faible dans ce test |
| Max est meilleur pour le codage / travail long horizon | Docs Vercel | BugFind : Plus 10/10, Max 9/10 ; Plus 147,5 t/s | Cette tâche ne permet pas d'appliquer cette hypothèse aveuglément |
| Le classement vision est fort | Arena | Exemple officiel échoué ; image contrôlée ✓ | Un score de classement élevé et un échec sur une image peuvent coexister |
2. Notre méthode d'évaluation : quatre types de tâches et une règle stricte
Pour que le test reste équitable, nous conservons une petite suite appelée BugFind-10 : 10 bugs réels couvrant le calcul de prix, les limites de tableaux, la gestion des chemins, la concurrence, JSON, SQL, le comportement du cache, Unicode, la configuration, etc. Chaque bug est accompagné de tests pytest. Le modèle doit s'exécuter à l'intérieur du framework d'agent officiel Stirrup avec des outils d'exécution de code locaux et terminer lui-même la boucle complète : « reproduire → localiser → modifier le code de production → exécuter les tests ».
Pourquoi créer notre propre suite de tests ?
Les classements publics présentent trois modes de défaillance courants :
- Mémorisation et fuite : les modèles phares sont déjà saturés sur les anciens problèmes. Nous avons sélectionné AIME 2025, un concours publié après les dates probables de coupure de l'entraînement des modèles.
- Les auto-évaluations des fournisseurs peuvent s'éloigner des tests indépendants : la même métrique peut changer de manière significative selon la version du jeu de données, l'activation de la réflexion et l'autorisation des outils.
- Les benchmarks d'agents dépendent de l'échafaudage : différents frameworks d'agents peuvent faire varier les scores de 2 à 3 points de pourcentage. Nous avons fixé le framework à Stirrup officiel et ajouté une vérification externe.
Les quatre tâches de test
| Tâche | Ce qu'elle mesure | Métrique principale |
|---|---|---|
| Vérification | Confirmation d'identité, support de réflexion, capacité de vision | Réussite / Échec |
| BugFind-10 | Réparation automatique de 10 bugs de code réels | Taux de réussite pytest externe, nombre d'appels, temps réel |
| AIME 2025 I | 15 problèmes de mathématiques de concours | Précision, temps par problème, ablation de réflexion |
| Évaluation rapide | 8 problèmes de mots de niveau école primaire | Ligne de base de vitesse, TTFT, bénéfice de réflexion |
Notre règle stricte : les scores de code ne comptent que sous pytest externe
C'est la base de toute cette analyse. Elle répond également directement à la préoccupation sur Hacker News selon laquelle un agent qui dit « les tests sont réussis » ne suffit pas.
Processus :
- L'agent modifie le code dans l'espace de travail, exécute lui-même pytest et rédige un CHANGELOG.
- Nous copions le code de production modifié dans un environnement isolé et exécutons pytest indépendamment.
- Nous publions uniquement le code de sortie et la pile d'échec de l'étape 2.
Une analogie : l'agent est le candidat à l'examen. Nous ne nous contentons pas de lire la réponse qu'il rend ; nous emmenons la réponse dans une autre salle et la corrigeons à nouveau, afin de ne pas nous fier aveuglément à sa propre évaluation de réussite.
3. Capacité de code et d'agent
Vue d'ensemble des trois modèles
| Modèle | Résultat pytest | Taux de réparation | Appels LLM | Temps réel | Débit de bout en bout |
|---|---|---|---|---|---|
| Qwen3.6-Plus | 1 échoué, 26 réussis | 9/10 | 63 | 334s | 41,5 |
| Qwen3.7-Plus | 27 réussis | 10/10 | 52 | 205s | 147,5 |
| Qwen3.7-Max | 1 échoué, 26 réussis | 9/10 | 20 | 249s | 51,8 |
Le fait que Plus obtienne le meilleur résultat BugFind en exécution unique était inattendu :
- Plus a été le seul test 10/10 dans cette évaluation.
- Max a utilisé le moins d'appels mais n'a pas obtenu la note maximale. 3.7-Max s'est arrêté après seulement 20 appels de modèle, le nombre le plus faible des trois. Il avait tendance à « réfléchir pendant longtemps et à faire un grand changement », avec moins d'itérations. En revanche, 3.7-Plus a utilisé 52 appels et était prêt à modifier, exécuter, inspecter les commentaires et modifier à nouveau.
- Plus a eu le temps réel le plus court et le débit le plus élevé. Pour l'expérience d'agent IDE, cela compte beaucoup plus que quelques points Elo sur un classement.
Une tâche, trois philosophies de réparation : plongée approfondie sur task05
Cette tâche teste la règle selon laquelle un JSON invalide ne doit pas être ignoré silencieusement. Lorsque l'analyse rencontre de mauvaises données, elle ne doit pas prétendre au succès et renvoyer un objet vide ; elle doit signaler l'erreur clairement. Le bug original :
plaintext1def safe_parse(data: str): 2 try: 3 return json.loads(data) 4 except Exception: 5 return {} # Bug: ignore l'exception
Les tests exigent :
- Pour une entrée comme "ce n'est pas du json {", la fonction ne doit pas renvoyer un dict vide {}.
- Pour une entrée invalide sans accolades, comme "mauvais", elle doit lever une exception.
L'approche de Max (test externe ✗) : lever une exception personnalisée JSONParseError.
Cela semble être une solution propre, mais pour "ce n'est pas du json {", elle a levé une exception immédiatement, donc le test a échoué avant même que la première assertion puisse s'exécuter. Pourtant, le CHANGELOG de Max indiquait avec confiance « 27 réussis ». C'est exactement pourquoi la vérification externe est obligatoire : l'auto-évaluation d'un agent et un audit externe divergent souvent.
3.6-Plus (externe ✗) : a échoué sur le même premier obstacle.
3.7-Plus (externe ✓) :
plaintext1if re.search(r'[\{\[\]\}]', data): 2 return {"error": str(e), "raw": data} 3raise ValueError(f"JSON invalide : {e}") from e
Pour une entrée mal formée contenant des accolades, il renvoie un objet d'erreur distinct de {}. Pour une entrée sans aucune accolade, il lève une exception. Il a répondu précisément aux deux côtés du contrat de test.
Pourquoi Max a-t-il raté la note maximale sur cette tâche ? Commençons par le nombre d'appels :

3.7-Max s'est arrêté après seulement 20 appels de modèle, le nombre le plus faible des trois. Il avait tendance à « réfléchir pendant longtemps et à faire un grand changement », avec moins d'itération. 3.7-Plus a utilisé 52 appels et était disposé à modifier, exécuter, inspecter les retours et modifier à nouveau. Dans les tâches de codage d'agent qui nécessitent une interaction répétée avec l'environnement, davantage d'itérations peuvent aider à couvrir les cas limites que Max a manqués lors de ce test. Cela souligne un fait souvent négligé : dans les tâches d'agent, un « raisonnement plus profond » ne signifie pas nécessairement une livraison plus stable. Bien utiliser les retours des outils est tout aussi important.
Sur la qualité de réparation, les trois modèles ont bien réussi la task03. Cette tâche concatène directement user_id dans un chemin de fichier, donc ".." peut créer une traversée de chemin et "user;rm -rf" peut comporter des métacaractères shell. La réparation a ajouté un désinfectant de liste blanche, identifiant un défaut de sécurité réel au lieu de corriger aveuglément pour obtenir des tests verts :
plaintext1user_id = re.sub(r'[^a-zA-Z0-9_-]', '', user_id) or "inconnu"
Points à retenir pour l'ingénierie :
- Pour les tâches d'agent, la volonté de se confronter à l'environnement (Plus a eu 52 tours de dialogue et 98 exécutions de code) compte plus qu'une itération minimale.
- Max s'est arrêté après 20 tours et a cru prématurément que la task05 était résolue.
- Dans la correction de bugs interactive, une solution propre de « lever une exception » n'est pas toujours plus utile que de renvoyer des données « sales » sous une forme identifiable.
4. Raisonnement et mathématiques : le mode réflexion est une décision de coût
La série Qwen3.7 met l'accent sur la « réflexion hybride », contrôlée par le commutateur enable_thinking. Ce commutateur vaut-il la peine d'être activé ? Nous avons effectué une ablation sur deux groupes de tâches de difficultés très différentes. Le groupe difficile était AIME 2025 I, un concours publié après les dates probables de coupure de l'entraînement des modèles et donc plus résistant à la contamination. Nous avons vérifié chaque problème et chaque réponse par rapport à deux sources indépendantes, AoPS et Areteem, puis noté automatiquement.
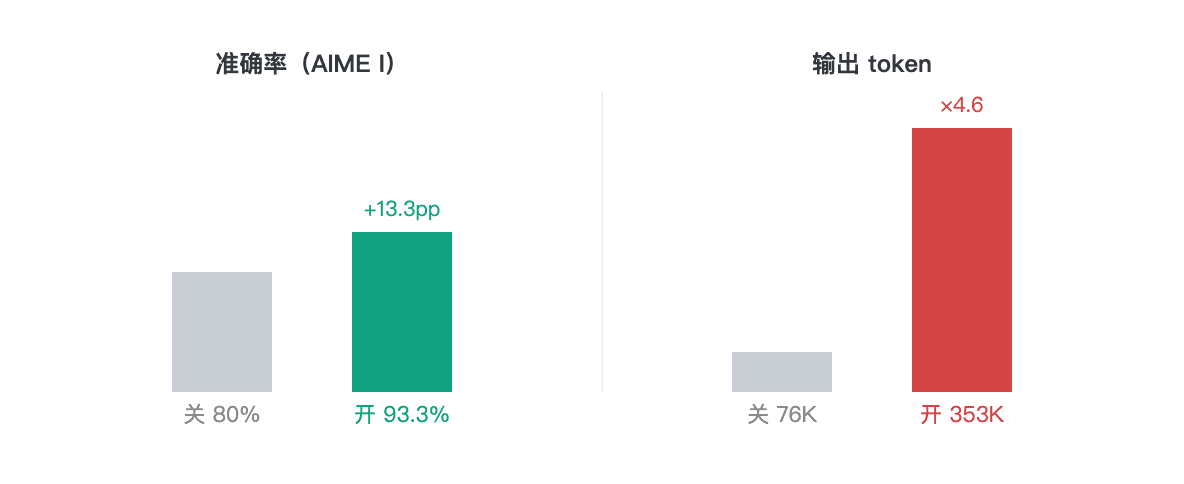
| Modèle / mode | Précision | Temps moyen/problème | Jetons de sortie |
|---|---|---|---|
| 3.7-Plus · réflexion désactivée | 12/15 (80%) | 24,7s | 76 502 |
| 3.7-Plus · réflexion activée | 14/15 (93,3%) | 113,4s | 353 424 |
| 3.7-Max · réflexion activée | 14/15 (93,3%) | 303,1s | 307 801 |
| 3.6-Plus · réflexion | 6 premiers problèmes : 6/6 | 464s | 25,7K/problème |
Comparaison des coûts :
| Configuration | Correct | Précision | Temps moyen/problème | Total jetons sortie | TPS moy | Coût indicatif |
|---|---|---|---|---|---|---|
| Plus réflexion désactivée | 12/15 | 80,0% | 24,7s | 76 502 | 204,0 | $0,15 |
| Plus réflexion activée | 14/15 | 93,3% | 113,4s | 353 424 | 205,4 | $0,69 |
| Max réflexion activée | 14/15 | 93,3% | 303,1s | 307 801 | 68,3 | $0,60 |
Remarque : la tarification indicative a été estimée avec 3.6-Plus à $0,325/$1,95 par M. Le prix officiel de la passerelle de $0,40/$1,60 est plus proche de la tarification de production.
Bénéfice marginal du commutateur de réflexion
Avec le raisonnement activé, Plus a atteint le même score AIME en exécution unique que Max. 3.7-Plus avec réflexion activée et 3.7-Max ont tous deux obtenu 14/15, mais Plus a pris 113 secondes par problème alors que Max en a pris 303. Dans ce test, la latence plus longue de Max n'a pas produit un score plus élevé ; cette exécution unique ne prouve toujours pas que Max n'a aucun avantage sur d'autres tâches mathématiques.
Sur 8 problèmes de mots de niveau école primaire, les deux modes étaient corrects à 100 %. L'activation de la réflexion n'a consommé que 24 % de jetons en plus. Si l'on combine les deux ensembles, la conclusion est claire :
Désactivez la réflexion pour les tâches simples afin d'économiser de l'argent ; activez-la pour les tâches difficiles afin d'acheter de la précision. Laisser le raisonnement globalement activé signifie payer continuellement plus de 4x plus cher sur des requêtes simples sans gain de précision. La valeur du commutateur est qu'il vous permet d'acheminer dynamiquement selon la difficulté de la tâche.
Max vs Plus : d'où vient la latence dans ce test ?
Max a également obtenu 14/15 et a également échoué à I-14 (prédit 69, réponse correcte 60). Même test, même problème manqué, même schéma d'échec, pas « Max était plus intelligent et a échoué sur un autre cas difficile ». Max a résolu I-15 alors que Plus l'a manqué, il y a donc une variance sur les problèmes très difficiles, et un seul test ne peut pas déclarer un modèle globalement plus fort.
Mais l'écart de vitesse était frappant. Sur le problème I-2, Max a pris 261 secondes ; Plus n'a pris que 108 secondes. Sur l'ensemble, Max a atteint en moyenne 68,3 tps tandis que Plus a atteint 205,4, soit environ 3x plus rapide.
Conclusion : une fois la réflexion activée, Plus a atteint le même score en exécution unique que Max sur cet ensemble de mathématiques de concours tout en conservant un avantage clair en termes de latence et de coût. Pour les scénarios interactifs en temps réel, cette différence compte.
Contrôle des tâches simples
Nous avons utilisé 8 problèmes de mots de niveau école primaire comme test de charge simple :
| Mode | Précision | Temps moyen | Total jetons sortie |
|---|---|---|---|
| réflexion désactivée | 8/8 | 2,17s | 2 314 |
| réflexion activée | 8/8 | 2,48s | 2 881 |
Activer la réflexion a consommé 24 % de jetons en plus sans gain de précision. La difficulté est le seul critère sensé pour activer le mode réflexion.
5. Vitesse, écart générationnel et une tâche que nous avons dû arrêter
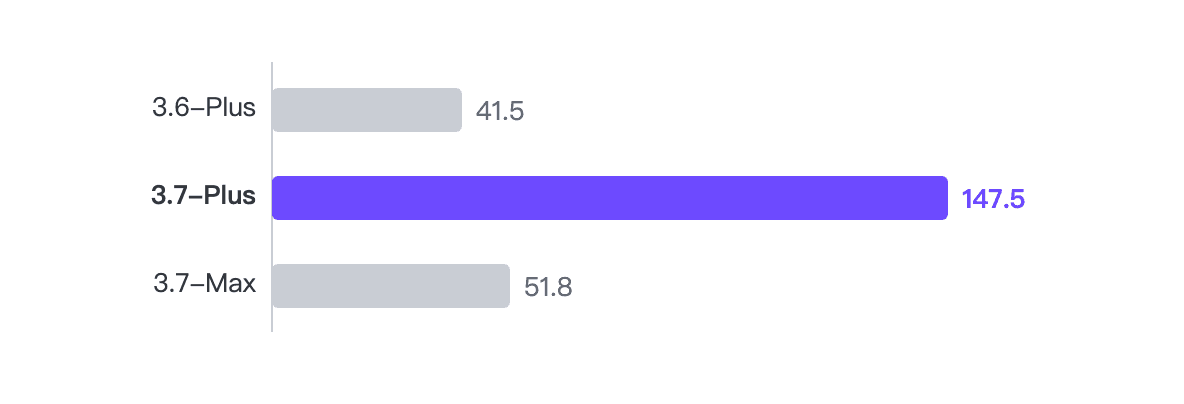
Comparaison du débit de l'agent
Vitesse réelle de bout en bout extraite de BugFind runner_summary.json :
- 3.7-Plus : 147,5 t/s (52 appels, 204,8s)
- 3.7-Max : 51,8 t/s (20 appels, 249,0s)
- 3.6-Plus : 41,5 t/s (63 appels, 334,5s)
L'amélioration générationnelle (3.6 → 3.7 Plus) était d'environ 3,55x. Plus vs Max de la même génération était d'environ 2,85x.
L'exemple le plus spectaculaire de l'écart générationnel provient de l'exécution des mathématiques sur 3.6-Plus. Nous voulions ajouter un résultat AIME pour lui aussi, mais il était trop lent pour terminer : le raisonnement a poussé jusqu'à la limite sur chaque problème, la sortie par problème a atteint 16K-52K jetons, et chaque problème a pris de 297 à 932 secondes. Les 6 premiers problèmes ont pris à eux seuls 46 minutes. Une exécution complète de 15 problèmes n'était pas faisable dans un budget de temps raisonnable, nous avons donc arrêté.
Nous avons essayé de « limiter le temps » en réduisant max_tokens de 16000 à 4096. Cela n'a pas fonctionné. C'est un piège d'ingénierie qui mérite d'être noté :
- En mode réflexion, les jetons de raisonnement ne sont pas contraints par max_tokens ; le modèle peut encore émettre des dizaines de milliers de jetons de raisonnement.
- Le délai d'expiration de la requête n'est pas suffisant non plus. Le délai d'expiration OpenAI/httpx est un « délai de lecture » entre les morceaux de données. Tant que la réponse en streaming continue d'émettre des jetons, ce délai ne se déclenche jamais.
Les deux voies de délai d'expiration étaient bloquées, nous avons donc tué le processus et rapporté les 6 premiers problèmes récupérés : 6/6 corrects. Cela signifie que la capacité mathématique de 3.6-Plus n'était pas le problème. Il pouvait résoudre les problèmes. Mais « peut résoudre » et « peut terminer dans un temps que les utilisateurs toléreront » sont des affirmations différentes. Pour un modèle de production qui doit répondre aux utilisateurs, la seconde est souvent plus importante. C'est exactement la dimension que les classements cachent souvent mais que l'expérience utilisateur expose.
Conseils pour les équipes d'ingénierie : pour les modèles de réflexion, les stratégies traditionnelles de délai d'expiration et de max_tokens peuvent échouer. Vous avez besoin d'un budget total de jetons, d'un plafond de temps réel total ou d'un plafond de jetons de raisonnement.
6. Quatrième conclusion principale : Multimodalité - Image contrôlée réussie, exemple officiel échoué
| Exemple de test | Entrée | Sortie du modèle | Jugement |
|---|---|---|---|
| Image contrôlée | PNG bloc rouge/bleu (local) | "bleu, orange" | ✓ correct |
| Exemple officiel | dog_and_girl.jpeg (OSS) | "un groupe de personnes debout à côté d'un train..." | ✗ complètement faux |
Arena Vision classe Plus autour du #16 (aperçu). Ce benchmark mesure le dialogue image-texte selon la préférence humaine. Notre test montre qu'un score de classement élevé et un échec sur une seule image peuvent coexister.
Conseils pour les sélecteurs de modèles : nous n'avons pas exécuté de benchmarks de vision standardisés tels que MMMU ou ChartQA, nous ne faisons donc pas d'affirmation générale sur la préparation à la production de la vision Plus. Mais la conclusion est claire : exécuter 20 à 50 images de votre propre domaine professionnel (OCR, graphiques, captures d'écran d'interface utilisateur, reçus) est bien plus fiable que de lire un classement.
Certains utilisateurs de Hacker News ont également testé le modèle et ont conclu que « la vision Qwen est plus forte que Gemma ». Ce retour d'utilisateur n'est pas contradictoire ; il s'agissait de tâches privées. L'échec de l'exemple d'image officiel est un rappel que le succès privé et l'échec officiel peuvent coexister. La sélection du modèle doit être guidée par vos propres données.
7. Coût : ce que toute cette série a coûté
Cet article lui-même est un échantillon de coût. Après avoir exécuté trois modèles sur quatre types de tâches, l'utilisation réelle de l'API Qwen était d'environ 2 millions de jetons (la partie 3.6-Plus arrêtée n'a pas été entièrement comptée), avec un coût indicatif d'environ 2-3 $.
Facture pour cette série de tests
| Élément | Échelle de jetons | Coût indicatif |
|---|---|---|
| AIME Plus activé | 353K sortie | ~$0,69 |
| AIME Plus désactivé | 76K sortie | ~$0,15 |
| AIME Max activé | 308K sortie | ~$0,60 |
| BugFind × trois modèles | Entrée cumulative très élevée | Inclus dans le total |
| Total | ~2 millions | 2-3 $ |
Insight 1 : une série d'évaluations sérieuse coûte environ le prix d'un repas. Les équipes devraient consacrer cet argent à relancer leurs propres tâches, pas à des textes marketing.
Insight 2 : le coût de l'agent ne réside pas principalement dans le prix unitaire. C'est le nombre de tours × la longueur de l'historique par tour. BugFind a utilisé 52-63 appels par modèle, et une entrée en un tour pouvait dépasser 11K jetons. L'optimisation doit cibler la compression de l'historique, la décomposition des sous-agents et la mise en cache, pas seulement une tarification de modèle moins chère.
Coût marginal de la réflexion (exemple AIME I)
- Réflexion désactivée : 0,15 $ / 15 problèmes ≈ 0,01 $/problème
- Réflexion activée : 0,69 $ / 15 problèmes ≈ 0,046 $/problème
Deux réponses correctes supplémentaires (I-9 et I-14) coûtent +0,54 $. Si votre entreprise exécute 10 000 problèmes de difficulté moyenne par jour, l'écart peut facilement atteindre des milliers de dollars par jour. La stratégie de routage (commencer sans réfléchir, puis activer la réflexion lorsque la confiance est faible) est obligatoire en production.
Comparaison des prix de la passerelle (01-06-2026)
| Modèle | Entrée / sortie par M |
|---|---|
| qwen3.7-plus | 0,40 $ / 1,60 $ |
| qwen3.7-max | 1,25 $ / 3,75 $ |
Max est environ 3x plus cher que Plus (environ 2,3x sur la sortie), alors que ce test a montré le même score AIME et un score BugFind inférieur d'un point. Le coût en temps est généralement plus onéreux que le coût en jetons : le temps d'attente des ingénieurs et les créneaux d'agent occupés sont aussi de l'argent.
8. Conseils de sélection de modèles pour les développeurs
| Scénario | Recommandation |
|---|---|
| Construction d'agents / codage / correction de bugs | Mettez 3.7-Plus dans l'ensemble de candidats par défaut. Ce test unique était 10/10, avec un débit élevé et plus d'itération ; gardez Max comme produit phare texte / repli de haute difficulté, et ne choisissez pas par la seule étiquette de produit phare. |
| Raisonnement ou maths de difficulté moyenne, avec sensibilité à la latence | 3.7-Plus avec réflexion activée. Dans ce test, il a égalé la précision de Max avec une latence plus faible. |
| Q&A simple / classification / extraction | 3.7-Plus avec réflexion désactivée. Économisez le coût de raisonnement supplémentaire. |
| Toujours en 3.6-Plus | Mettez à niveau. L'écart générationnel principal est la vitesse, et un débit 3,5x change l'expérience utilisateur. |
9. Limitations et divulgations honnêtes
Cet article est un instantané profond d'une après-midi, pas un article académique. Les limitations suivantes sont importantes :
- Exécution unique : ni BugFind ni AIME n'ont utilisé pass@k. Les cas à forte variance tels que task05 et I-15 nécessitent une validation répétée.
- Pas de comparaison horizontale avec les concurrents : Claude, GPT, Gemini et DeepSeek n'ont pas été testés. Cela décrit uniquement les différences internes au sein de la famille Qwen.
- 3.6-Plus n'a terminé que 6 problèmes AIME : sa précision ne peut pas être directement comparée aux tests Plus/Max sur 15 problèmes.
- Tarification utilisant des estimations indicatives : vérifiez la dernière tarification de la passerelle pour les chiffres officiels ; la tarification nationale DashScope peut avoir des réductions distinctes.
- Un seul framework d'agent a été utilisé (Stirrup) : passer à SWE-agent pourrait changer le classement.
- La taille de l'échantillon multimodal était n=2 : elle ne peut pas représenter une large capacité de vision.
- Le modèle testé était une version bêta sur invitation : la référence officielle (SKU) peut avoir des changements de comportement mineurs.
- Les données X étaient un instantané d'une journée : elles capturaient le sentiment de la communauté au moment de la rédaction et peuvent avoir changé après la publication.
Note finale
Dans le récit officiel de juin 2026, Qwen3.7-Plus est le niveau phare chinois sur le classement vision, le choix rentable sur la passerelle, et le nouveau membre de la famille Qwen que la communauté décrit comme se déplaçant à une vitesse d'itération effrayante.
Dans notre univers reproductible d'une après-midi, c'est :
- Le modèle qui a été le seul à obtenir 10/10 dans ce test de correction de bugs de code réel unique.
- Le modèle qui a atteint le même score que Max sur ce test de mathématiques de concours avec la réflexion activée, tout en montrant une latence plus faible.
- Le modèle qui a offert une amélioration du débit de 3,55x par rapport à la génération précédente, reléguant le « impossible à terminer » aux oubliettes.
- Le modèle qui a encore halluciné sur l'exemple d'image officiel tout en réussissant notre test d'image contrôlée, vous rappelant de ne pas choisir un modèle de vision à partir d'une seule capture d'écran.
Ces conclusions sont limitées à ce petit échantillon, à une exécution unique et à un cadre fixe. Elles justifient de mettre Plus dans l'ensemble de candidats par défaut de l'ingénierie ; elles ne justifient pas un classement général des modèles.
Pour les ingénieurs, le récit officiel est responsable de la vision ; le répertoire outputs/ est responsable des preuves. Si vous choisissez un modèle pour la production, lisez cette analyse avec la version de visualisation de données complémentaire ([13_Qwen3.7-Plus_Eval.html](13_Qwen3.7-Plus_Eval.html)) : faites d'abord confiance aux chiffres, puis lisez pourquoi nous sommes prêts à appeler cela une « évaluation » au lieu d'une republication.
Dans le déluge de modèles d'IA de 2026, seule une preuve reproductible de qualité d'audit est une monnaie forte pour les décisions techniques.






