Claude Code coûte environ 13 USD par développeur et par jour d'activité, et une automatisation intensive peut faire grimper cette facture entre 500 USD et 2 000 USD par ingénieur chaque mois (CloudZero, 2026). Pour une équipe de 50 personnes, il s'agit d'une dépense à cinq chiffres qui apparaît de nulle part. Si votre facture d'IA pour le codage a bondi le trimestre dernier et que personne ne peut expliquer pourquoi, vous n'êtes pas seul, et la solution est rarement « d'utiliser moins l'IA ».
Le vrai problème est que les outils de codage par agents consomment des jetons d'une manière fondamentalement différente d'une fenêtre de chat, et la plupart des équipes paient le prix fort pour des jetons qu'elles pourraient obtenir pour une fraction du coût. Ce guide passe en revue sept tactiques concrètes pour réduire le coût des jetons de codage par IA, avec les chiffres derrière chaque tactique et les changements de configuration exacts pour les mettre en œuvre.
Points clés
- Les outils de codage par agents consomment 10 à 100 fois plus de jetons que le chat, car le contexte complet est renvoyé à chaque appel d'outil (LeanOps, 2026).
- La mise en cache des invites (prompt caching) est le levier le plus efficace : les lectures en cache coûtent environ 10 % des jetons d'entrée standard, et une équipe a réduit ses dépenses totales en LLM de 59 % rien qu'avec cette méthode.
- Basculer le codage quotidien vers des modèles à poids ouverts comme GLM, Kimi et DeepSeek peut réduire le coût par jeton de 80 % ou plus par rapport aux modèles de pointe, avec un écart de qualité plus faible que ce que la plupart des gens pensent.
- Acheminer tous vos outils via une passerelle unique permet de maintenir un budget unique, une seule clé API et une tarification cohérente, au lieu de payer les prix de détail chez cinq fournisseurs différents.
Pourquoi le coût des jetons de codage par IA devient incontrôlable
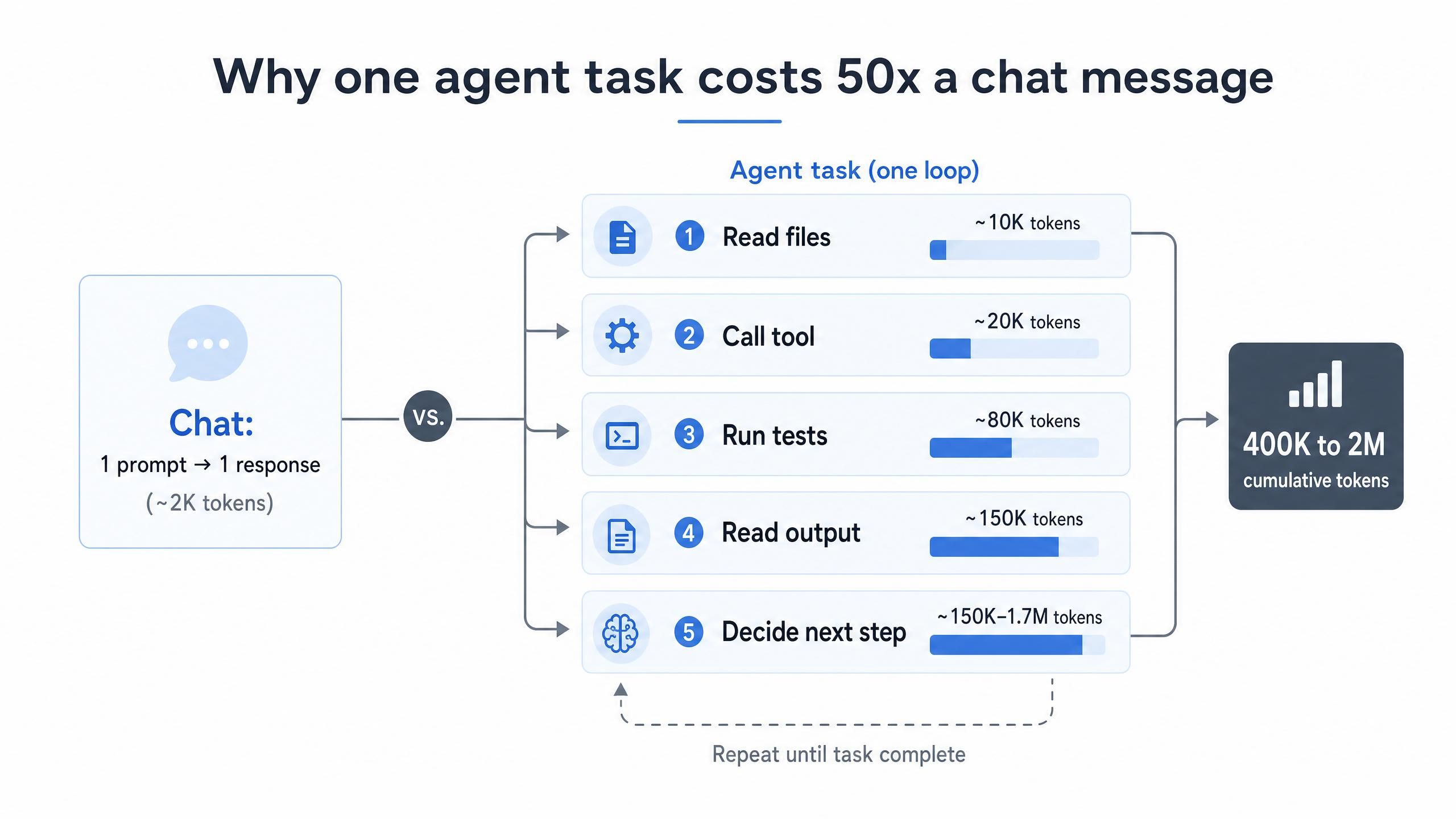
La raison fondamentale pour laquelle le coût des jetons de codage par IA est si élevé est structurelle, et non comportementale. Un échange par chat envoie une invite et reçoit une réponse. Un agent fait quelque chose de très différent : il lit des fichiers, appelle des outils, exécute des tests, lit la sortie et décide de l'action suivante. Chacune de ces étapes de raisonnement renvoie le contexte accumulé, de sorte que l'utilisation des jetons augmente à chaque boucle. Les agents IA consomment des jetons 10 à 100 fois plus vite que les chatbots pour cette raison précise (LeanOps, 2026).
Les chiffres deviennent rapidement importants. Une seule tâche d'agent non triviale peut envoyer 400 000 à 2 000 000 de jetons d'entrée cumulés via l'API à mesure que la fenêtre de contexte se remplit et se vide (Morph, 2026). Multipliez cela par des dizaines de tâches par jour au sein d'une équipe, et la facture mensuelle cesse d'être une erreur d'arrondi.
Ce n'est pas une préoccupation hypothétique pour les grandes organisations. Selon un rapport relayé par The Next Web, Microsoft a retiré la plupart de ses licences internes Claude Code en partie à cause des coûts, avec des factures par ingénieur grimpant dans la fourchette de 500 à 2 000 USD (The Next Web, 2026). Lorsque l'une des organisations d'ingénierie les mieux dotées au monde tressaille devant la facture, il est utile de comprendre où vont réellement les jetons avant d'essayer de les réduire.
Comment réduire le coût des jetons de codage par IA sans ralentir
La bonne nouvelle est qu'aucune de ces tactiques ne nécessite d'écrire moins de code ou de surveiller l'agent. Elles fonctionnent en éliminant le gaspillage, en reformulant la tarification du même travail et en faisant correspondre chaque tâche au modèle le moins cher capable de l'exécuter. Voici les sept tactiques les plus efficaces, classées approximativement par ordre d'effort/gain.
Tactique 1 : Utiliser la mise en cache des invites pour réduire le coût des jetons
La mise en cache des invites est le changement individuel le plus efficace. Lorsqu'un agent renvoie la même invite système, les mêmes définitions d'outils et le même contexte de fichier à chaque étape, la mise en cache permet au modèle de lire ce contenu répété depuis le cache plutôt que de le retraiter. Les lectures en cache sont facturées environ 0,10 fois le tarif d'entrée standard, soit une remise de 90 % sur la partie répétée de chaque requête (Finout, 2026).
À noter : les écritures en cache coûtent légèrement plus cher qu'un jeton d'entrée normal, environ 1,25 fois le tarif standard pour une fenêtre de cinq minutes. Le cache est donc rentable lorsque le contexte est réutilisé dans la fenêtre de durée de vie, ce qui correspond exactement au modèle produit par un agent. L'impact réel n'est pas théorique. L'équipe de ProjectDiscovery a documenté une réduction de 59 % du coût total en LLM après avoir implémenté la mise en cache des invites dans son pipeline (ProjectDiscovery, 2026).
Si vous utilisez Claude Code ou un agent compatible, vérifiez que la mise en cache est activée et que votre invite système ainsi que les contextes de fichiers volumineux sont placés dans des blocs pouvant être mis en cache. Ce simple changement entraîne souvent la plus forte baisse en pourcentage de la facture.
Tactique 2 : Faire correspondre le modèle à la tâche pour réduire les coûts
La plupart des équipes acheminent chaque requête vers leur modèle le plus puissant, ce qui revient à utiliser un semi-remorque pour aller faire ses courses. Le modèle le plus intelligent consiste à réserver le modèle de pointe coûteux au travail qui en a réellement besoin, et d'envoyer tout le reste vers un modèle moins cher.
Une répartition pratique ressemble à ceci :
- Raisonnement, architecture, débogage complexe : un modèle de premier plan où la qualité justifie le prix.
- Génération et édition de code quotidien : un modèle ouvert intermédiaire performant.
- Tâches de fond à gros volume, classification, code standard : le modèle le plus économique capable de faire le travail.
Les économies sont spectaculaires car l'écart de prix est énorme. À bas coût, DeepSeek V4 Flash coûte environ 0,14 USD par million de jetons d'entrée, tandis que les modèles de pointe coûtent beaucoup plus cher (Codersera, 2026). Consacrer 80 % de votre volume de jetons à un modèle qui coûte une fraction du prix, tout en conservant le modèle premium pour les 20 % restants, peut réduire les dépenses totales de plus de moitié sans baisse notable de la qualité de la production.
Tactique 3 : Garder la fenêtre de contexte légère
Comme chaque jeton dans le contexte est renvoyé à chaque étape de l'agent, une fenêtre de contexte surchargée est une taxe que vous payez à plusieurs reprises. Deux habitudes aident. Premièrement, définissez chaque tâche avec précision afin que l'agent ne charge que les fichiers nécessaires plutôt que le référentiel entier. Deuxièmement, lancez une nouvelle session lorsque vous changez de tâche au lieu de laisser une conversation accumuler des centaines de milliers de jetons obsolètes.
Un modèle mental utile : si vous ne copieriez pas un fichier dans une fenêtre de chat pour répondre à une question, ne le laissez pas dans le contexte de l'agent. Réduire une fenêtre de contexte de 200 000 jetons à 40 000 jetons ne permet pas seulement d'économiser une fois. Cela permet d'économiser à chaque appel d'outil pour le reste de cette tâche, là où la capitalisation joue en votre faveur.
Tactique 4 : Passer aux modèles à poids ouverts pour réduire le coût
C'est la tactique qui offre les économies les plus importantes et celle qui souffre le plus d'idées reçues. Les modèles de codage à poids ouverts disponibles en 2026 sont réellement performants. Sur SWE-Bench Pro, un modèle de pointe atteint un score d'environ 91, tandis que Kimi K2.6 atteint 76,8 et DeepSeek V4 Pro avoisine les 77 (Codersera, 2026). C'est un écart réel sur le benchmark le plus difficile, mais pour le travail de fonctionnalités de routine, les refactorisations et l'écriture de tests, la différence est bien moindre que l'écart de prix.
Et la différence de prix est le point crucial. Les modèles à poids ouverts comme GLM, MiniMax, Kimi et DeepSeek coûtent une fraction des prix des modèles de pointe par jeton. Pour la majorité du codage quotidien, un modèle ouvert gère le travail à une fraction du coût. La friction a historiquement été l'accès : jongler avec des comptes séparés, des clés séparées et une tarification incohérente entre les fournisseurs.
C'est là qu'une passerelle de codage unifiée change la donne. Une plateforme comme Atlas Cloud agrège les principaux modèles à poids ouverts derrière une API unique et un solde de crédits unique, afin que vous puissiez orienter Claude Code, Codex ou OpenClaw vers GLM-5.1 aujourd'hui et Kimi K2.6 demain sans rien reconfigurer. Atlas Cloud publie des multiplicateurs de crédits par modèle qui permettent d'économiser environ 45 % à 55 % par rapport à la tarification API officielle des modèles, et l'entreprise positionne son taux de crédit comme étant moins cher qu'OpenRouter pour les mêmes modèles.
Voici un aperçu de la manière dont ses multiplicateurs de crédits se traduisent pour les modèles de codage populaires :
| Modèle | Contexte | Multiplicateur entrée | Multiplicateur sortie | Économies approx. vs officiel |
|---|---|---|---|---|
| deepseek-ai/deepseek-v4-flash | 1M | 0,23 | 0,46 | ~50% |
| deepseek-ai/deepseek-v3.2 | 160K | 0,42 | 0,62 | ~55% |
| minimaxai/minimax-m2.5 | 200K | 0,65 | 2,18 | ~45% |
| moonshotai/kimi-k2.6 | 262K | 1,72 | 7,26 | ~45% |
| zai-org/glm-5.1 | 200K | 2,54 | 7,99 | ~45% |
Source : Règles de crédit Atlas Cloud Coding Plan. Coût en crédit = jetons d'entrée × multiplicateur d'entrée + jetons de sortie × multiplicateur de sortie.
Tactique 5 : Traitement par lots des tâches de fond
Tous les jetons n'ont pas besoin d'être dépensés aux tarifs interactifs en temps réel. Les évaluations nocturnes, les travaux de classification volumineux, les passes de documentation et les refactorisations en masse ne nécessitent pas qu'un humain les attende ; ils peuvent donc être exécutés via des voies de traitement par lots moins chères ou sur le modèle le moins coûteux disponible. Déplacer ce volume non urgent hors de votre modèle interactif premium est de l'argent gagné, car c'est un travail pour lequel vous payiez déjà le prix fort sans aucun avantage qualitatif lié à ce prix élevé.
Le principe est simple : séparez les jetons « j'attends ce résultat » des jetons « ceci peut être terminé pendant la nuit », et tarifez-les différemment. Pour la plupart des équipes, une part surprenante du volume total de jetons s'avère être du type nocturne.
Tactique 6 : Acheminer tous les outils via une passerelle de codage unique
La prolifération des outils augmente discrètement le coût des jetons de codage par IA. Un développeur typique peut utiliser Claude Code dans le terminal, Codex pour certaines tâches, Cursor dans l'éditeur et quelques agents à côté, chacun avec son propre abonnement, sa propre clé et sa propre facturation opaque. Vous perdez la capacité de voir les dépenses totales et vous payez le prix fort partout.
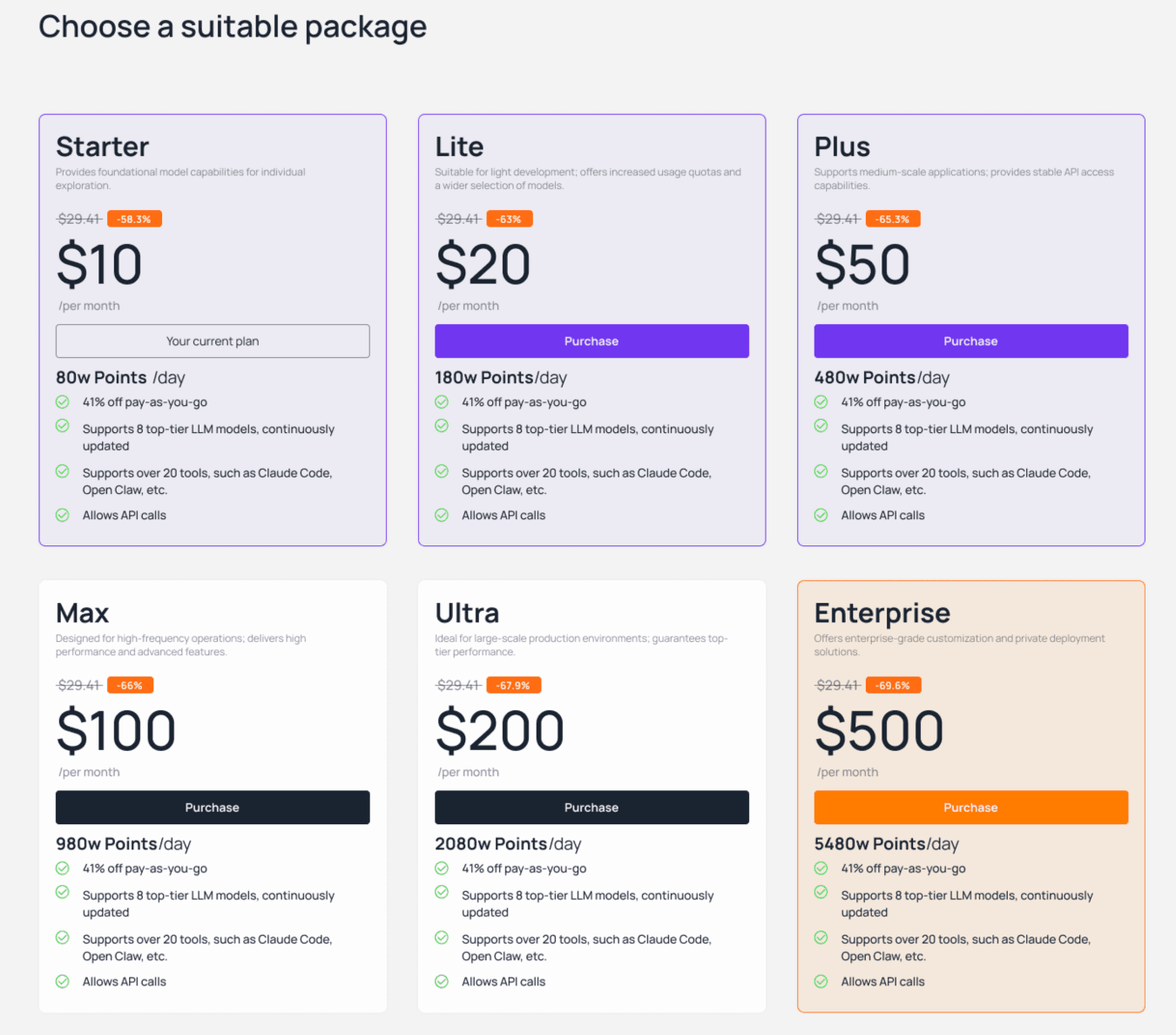
La consolidation sur un point de terminaison unique compatible OpenAI résout ces deux problèmes. Comme Atlas Cloud expose une URL de base unique et un pool de crédits qui fonctionne à travers Codex, Claude Code, OpenClaw, OpenCode, Cursor et les appels d'API directs, vous obtenez une facture unique, un budget unique et un seul endroit pour changer de modèle. Ses forfaits vont d'un niveau Starter à 10 USD par mois jusqu'à des niveaux supérieurs pour les équipes plus importantes, et les packs de paiement à l'usage offrent une réduction de 41 %. Vous pouvez ainsi ajuster l'engagement à l'utilisation réelle plutôt que de deviner.
Pointer Claude Code vers la passerelle se fait en un seul fichier de configuration. Sur macOS ou Linux, modifiez
1~/.claude/settings.jsonJSON1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "votre-cle-api-atlas", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "zai-org/glm-5.1", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "zai-org/glm-5.1", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "zai-org/glm-5.1", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
Pour les utilisateurs de Codex, l'équivalent se trouve dans
1~/.codex/config.toml1base_url1https://api.atlascloud.ai/v11~/.codex/auth.jsonTactique 7 : Fixer des budgets et surveiller le coût des jetons
Vous ne pouvez pas réduire ce que vous ne pouvez pas voir. Les équipes prises au dépourvu par d'énormes factures partageaient presque toutes un trait : aucun contrôle des dépenses et aucune visibilité par développeur. La solution consiste à plafonner la consommation avant le début du mois, et non après l'arrivée de la facture.
Un plan basé sur des crédits avec un quota quotidien permet de structurer cela. Au lieu d'un compteur illimité, un abonnement mensuel qui actualise une allocation de crédit fixe chaque jour à minuit limite le risque d'une boucle d'agent hors de contrôle, tandis que les packs de paiement à l'usage absorbent les pics occasionnels une fois l'allocation quotidienne épuisée. Lorsque vous devez augmenter votre capacité, les mises à niveau au prorata signifient que vous ne payez que la différence. Le flux de mise à niveau d'Atlas Cloud, par exemple, impute la valeur restante sur le nouveau niveau, de sorte qu'un changement en milieu de cycle peut ne coûter que quelques dollars plutôt qu'un nouveau forfait complet.
Une comparaison de coûts réelle : Le coût des jetons de codage par modèle
Pour rendre les économies concrètes, considérons un développeur qui envoie environ 1,5 million de jetons d'entrée et 300 000 jetons de sortie via son agent lors d'une journée chargée, un chiffre réaliste étant donné que des tâches uniques peuvent atteindre des millions de jetons d'entrée cumulés. Sur un modèle de pointe facturé environ 5 USD par million d'entrées et 25 USD par million de sorties, cela représente environ 7,50 USD en entrée et 7,50 USD en sortie, soit environ 15 USD pour une journée de développeur, ce qui correspond au chiffre largement cité de 13 USD par jour d'activité (CloudZero, 2026).
Exécutez le même volume via un modèle à poids ouverts tel que GLM ou Kimi via une passerelle à prix réduit, et la partie entrée seule chute de 70 % ou plus, la sortie suivant de près. Ajoutez la mise en cache des invites par-dessus, et le contexte répété qui domine les charges de travail des agents est facturé à un dixième du tarif. Cumulez les trois tactiques (mise en cache + modèle moins cher + contexte léger), et une journée de développeur à 15 USD peut réalistement se situer plus près de 3 à 5 USD sans changer la manière dont quiconque écrit du code.

Les chiffres exacts varieront selon votre charge de travail, mais la tendance est claire : la majeure partie du coût des jetons de codage par IA provient d'un contexte répété passant par un modèle surévalué, et ces deux problèmes sont corrigibles.
En résumé : Une configuration qui maintient le coût des jetons bas
Si vous souhaitez une configuration initiale qui capture la plupart des économies avec un minimum de complications, voici la marche à suivre. Utilisez un modèle à poids ouverts tel que GLM-5.1 ou Kimi K2.6 comme modèle de codage par défaut, gardez un modèle de pointe disponible pour le raisonnement complexe, activez la mise en cache des invites partout, définissez les tâches avec précision pour garder un contexte léger et acheminez chaque outil via un point de terminaison unique compatible OpenAI avec un budget quotidien fixe.
Cette combinaison résout chaque facteur de coût à la fois : elle reformule le prix des jetons, arrête de payer pour le contexte répété et plafonne les risques. Les équipes qui souhaitent centraliser cela sous une clé et un budget uniques peuvent le configurer via la console Atlas Cloud Coding Plan, qui prend en charge les principaux modèles à poids ouverts et les outils de codage courants dès la sortie de boîte. La configuration prend quelques minutes ; les économies se répètent chaque jour.
Foire aux questions sur le coût des jetons de codage par IA
Pourquoi le coût de mes jetons de codage par IA est-il bien plus élevé que mon utilisation du chat ?
Parce que les agents renvoient le contexte accumulé complet à chaque étape de raisonnement, tandis que le chat envoie chaque invite une fois. Cette différence structurelle signifie que les agents consomment 10 à 100 fois plus de jetons que le chat pour un travail comparable (LeanOps, 2026), de sorte que quelques dizaines de tâches d'agent peuvent éclipser un mois d'utilisation occasionnelle du chat.
Quel est le moyen le plus rapide de réduire le coût des jetons de codage ?
Activez la mise en cache des invites. Le contexte répété dans les charges de travail des agents est facturé à environ 10 % du tarif d'entrée standard une fois mis en cache (Finout, 2026), et au moins une équipe d'ingénierie a signalé une baisse de 59 % du coût total des LLM grâce au cache seul. Cela ne nécessite aucun changement dans votre façon de travailler, ce qui en fait le meilleur retour sur investissement pour un minimum d'effort.
Les modèles à poids ouverts moins chers sont-ils assez bons pour le vrai travail de codage ?
Pour la plupart des tâches quotidiennes, oui. Sur le benchmark le plus difficile, SWE-Bench Pro, les meilleurs modèles ouverts obtiennent des scores dans le haut des 70, contre environ 91 pour les modèles de pointe (Codersera, 2026), mais le travail de routine, les refactorisations et les tests ne sollicitent que rarement cet écart. Gardez un modèle de pointe en réserve pour le raisonnement vraiment complexe et envoyez le reste vers un modèle ouvert.
Combien puis-je économiser de manière réaliste sur le coût des jetons ?
En cumulant les principales tactiques (mise en cache, modèle par défaut moins cher et contexte léger), on réduit généralement une journée de développeur d'environ 15 USD à une fourchette de 3 à 5 USD, sur la base des tarifs publiés par jeton. Les économies se cumulent au sein d'une équipe, c'est pourquoi une facture mensuelle à cinq chiffres peut souvent être réduite de deux chiffres en pourcentage pour devenir raisonnable.
Dois-je changer d'outils pour réduire mon coût en jetons ?
Non. La plupart des économies proviennent de la manière dont les jetons sont tarifiés et réutilisés, et non de l'outil que vous utilisez. Pointer vos outils existants, qu'il s'agisse de Claude Code, Codex ou OpenClaw, vers un point de terminaison compatible OpenAI à prix réduit est un changement de configuration, pas une migration. Votre flux de travail reste donc le même tandis que la facture diminue.
Conclusion
Le coût des jetons de codage par IA semble mystérieux jusqu'à ce que vous en compreniez le mécanisme : les agents renvoient le même contexte encore et encore, et la plupart des équipes paient le prix fort pour la totalité de ce contenu. Corrigez ces deux éléments grâce à la mise en cache des invites, à un routage plus intelligent des modèles, à un contexte léger et à une passerelle unique à prix réduit, et la facture diminuera de moitié ou plus sans que personne n'ait à changer sa façon d'écrire du code. Commencez par la mise en cache cette semaine, auditez les tâches qui ont réellement besoin de votre modèle le plus coûteux et consolidez vos outils sur un budget unique. La configuration prend un après-midi ; les économies sont permanentes.






