
Au-delà de n8n : Pourquoi Rust est la seule réponse pour des workflows IA sans crash
Il est 2h00 du matin, et un nœud asynchrone JavaScript dans votre environnement n8n de production rencontre silencieusement une erreur de conversion de type implicite. Un webhook tiers a transformé un entier en chaîne de caractères. Comme Node.js évalue le code dynamiquement à l'exécution, le processus s'interrompt en plein milieu. Le workflow s'arrête, laissant des données partiellement traitées et votre équipe tentant désespérément de réparer une machine à états corrompue.
Pour les développeurs construisant des automatisations critiques et des pipelines multi-agents, la fragilité à l'exécution est une bombe à retardement. La solution consiste à abandonner totalement le paradigme de l'orchestration non typée et basée sur l'interprétation.
Voici flow-like, un moteur d'automatisation de workflow open-source de qualité entreprise, conçu entièrement en Rust. En troquant la souplesse dynamique de Node.js pour un écosystème rigide à typage fort à la compilation, flow-like change les règles du jeu pour les pipelines de production. Il transforme des comportements multi-agents imprévisibles en tâches fiables et déterministes, capables de s'exécuter sur un terminal unique ou un cluster Kubernetes sans aucune surprise à l'exécution.
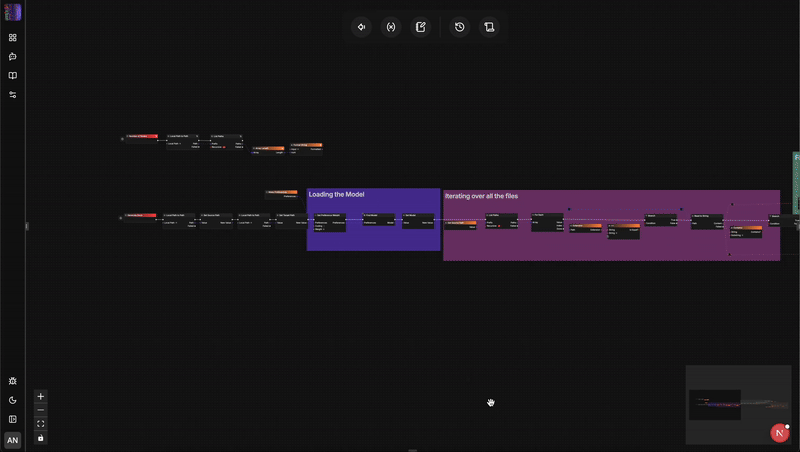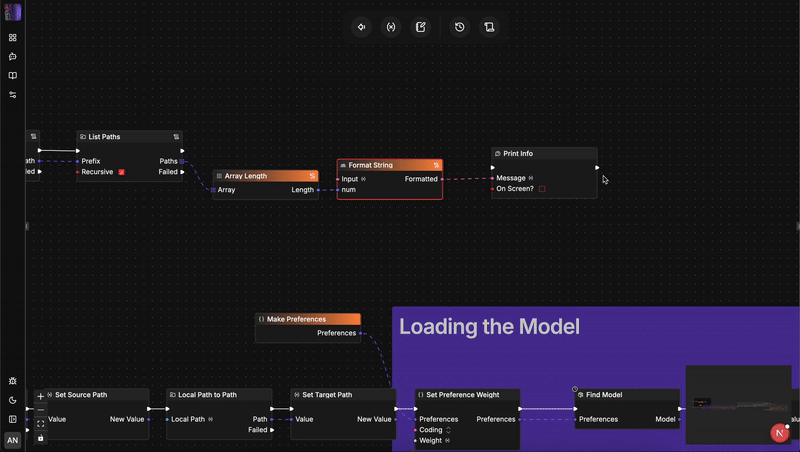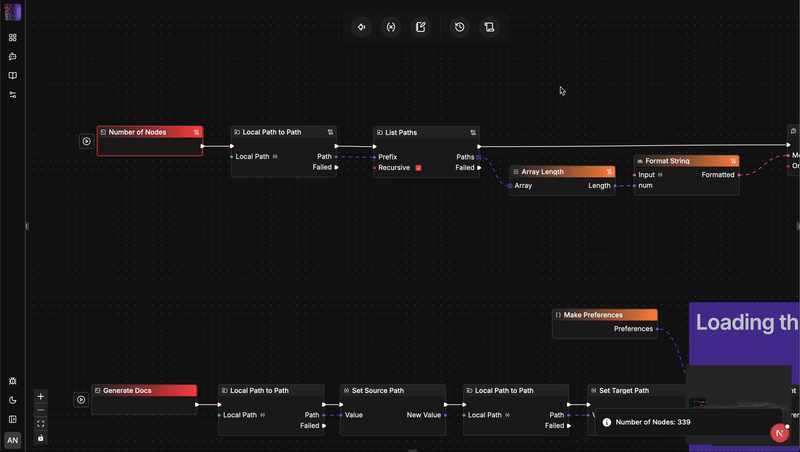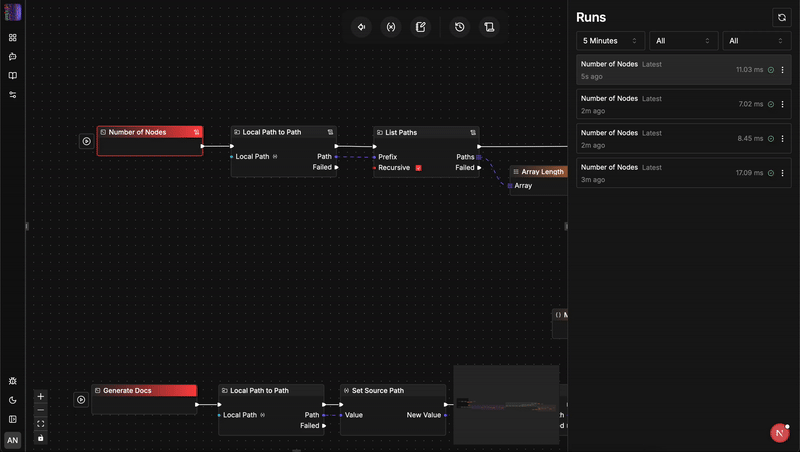
Duel architectural : flow-like vs. n8n
Comprendre pourquoi un changement de langage est crucial nécessite d'examiner de près comment ces deux moteurs gèrent l'état, la sécurité et la mise à l'échelle.
Typage fort vs. Chaos non typé
Le problème le plus visible dans n8n est sa dépendance totale à des charges utiles JSON lâches, transmises aveuglément entre les modules Node.js. Si un nœud génère un dictionnaire imbriqué là où un autre nœud attend un objet plat, le moteur ne découvre cette divergence qu'au moment où le trafic de production réel le traverse.
À l'inverse, flow-like fonctionne avec un modèle de "Contrat à typage fort" sur toutes les interfaces de données. Les variables sont explicitement déclarées en utilisant des structures de base comme VariableType::String, VariableType::Execution, ou des structs personnalisées. Si une charge utile de sortie ne correspond pas au contrat de schéma attendu par le port d'entrée, le moteur du pipeline l'intercepte immédiatement. Le pipeline d'exécution déclenche des blocs de validation déterministes avant de traiter des charges utiles corrompues ou inattendues.
Concurrence haute performance sans ramasse-miettes (Garbage Collection)
Node.js repose sur une boucle d'événements monothread pour gérer les entrées/sorties concurrentes. Lorsqu'un conteneur n8n analyse de gros fichiers ou traite des webhooks à haute fréquence, le moteur JavaScript V8 génère une surcharge mémoire importante et des pics de latence soudains dus aux pauses du Garbage Collection (GC).
flow-like exploite les abstractions à coût nul de Rust et la gestion manuelle de la mémoire. Construit avec des traits asynchrones et des utilitaires de hachage à faible surcharge comme blake3, flow-like passe facilement à l'échelle pour atteindre le chiffre stupéfiant de 244 000 workflows par seconde. Il traite des tableaux de données et des boucles imbriquées complexes avec une vitesse d'exécution interne moyenne d'environ 0,6 ms par nœud, ne nécessitant qu'une fraction infime de l'empreinte mémoire d'une instance Node.js.
Démonstration : Construire un pipeline de traitement IA multimodal sans fuite en 3 minutes
Voyons avec quelle facilité vous pouvez configurer et exécuter un workflow multi-agent typé qui traite des données d'entrée via des paramètres locaux et appelle un modèle cloud avancé pour le traitement.
Étape 1 : Configuration et compilation de l'environnement local
Comme flow-like est une application native pure sans dépendances d'exécution externes, sa compilation est simple. Clonez le projet et vérifiez la structure de build de l'espace de travail via Cargo :
Bash
plaintext1git clone https://github.com/Rheosoph/flow-like.git 2cd flow-like 3cargo build --release
Le processus de compilation regroupe tout — y compris les environnements d'exécution en bac à sable (sandboxing) WASM sous-jacents et les définitions de types — en un seul binaire exécutable.
Étape 2 : Connexion au cerveau Cloud via Atlas Cloud
Bien que flow-like s'exécute à la vitesse de l'éclair sur du matériel grand public local, le traitement de données non structurées ou la génération de schémas JSON précis nécessite des capacités d'inférence avancées. Plutôt que d'écrire du code API personnalisé ou de charger des milliers de lignes de bibliothèques wrapper spécifiques aux modèles, flow-like inclut un nœud natif BuildAtlasCloudNode dans son catalogue standard.
Le registre de mise en page sous-jacent configure le système pour cibler la plateforme :
Rust
plaintext1let mut node = Node::new( 2 "ai_generative_build_atlascloud", 3 "Atlas Cloud Model", 4 "Construit un modèle servi par Atlas Cloud, une plateforme d'inférence IA multimodale exposant une API compatible OpenAI...", 5 "AI/Generative/Provider" 6);
💡 Note du développeur : Cette approche élimine la friction traditionnelle liée à la gestion des clés API. J'utilise un jeton API unique fourni par Atlas Cloud au sein de ce nœud, ce qui me permet de lancer dynamiquement ou de basculer entre des modèles de raisonnement profond comme DeepSeek-V4-Pro, Qwen ou GLM à la volée, sans avoir à enregistrer manuellement des comptes ou à initialiser des packages clients séparés pour chaque modèle.
Voici un exemple de configuration mappant les propriétés de connexion :
JSON
plaintext1{ 2 "node_id": "ai_generative_build_atlascloud", 3 "inputs": { 4 "endpoint": "https://api.atlascloud.ai/v1", 5 "api_key": "ac_prod_secure_token_7721", 6 "model_id": "deepseek-ai/deepseek-v4-pro" 7 } 8}
Étape 3 : Déclenchement du pipeline et vérification des métriques
Lorsqu'un signal d'exécution atteint le port exec_in, le moteur active la logique de traitement :
Rust
plaintext1let mut hasher = blake3::Hasher::new(); 2hasher.update(b"atlascloud"); 3// Le système hache les paramètres et retourne une structure VLM Bit unique et réutilisable
Le moteur valide la structure, encapsule la logique d'authentification proprement à l'intérieur d'un fournisseur d'exécution compatible OpenAI (custom:openai), et transmet l'objet Bit structuré aux blocs d'extraction visuelle en aval via le port model.
Indicateurs de performance en production :
- Empreinte d'initialisation du moteur : ~24 Mo de RAM
- Latence interne du port du nœud : < 0,1 ms
- Échecs de typage : 0 (Interceptés dès l'étape de configuration)
Tableau comparatif : Spécifications techniques en un coup d'œil
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| Dimension architecturale | Moteur de workflow n8n | Architecture flow-like |
| Langage sous-jacent | Node.js (TypeScript / JavaScript) | Rust (Cœur natif pur) |
| Typage de l'interface | JSON lâche (Validation dynamique à l'exécution) | Contrats à typage fort (Les ports imposent les structures) |
| Débit concurrent max | ~220 tâches/sec (lié à la boucle d'événements V8) | ~244 000 workflows/sec (Exécution sans GC) |
| Bac à sable (Sandboxing) | VM2/Isolates (sujet à la pollution de prototype) | Isolation WebAssembly (WASM) |
| Architecture hors ligne | Environnements Docker lourds requis | Local-First natif (fonctionne sur Raspberry Pi) |
| Écosystème de modèles | Intégrations communautaires par fournisseur | Points de terminaison unifiés (via couche de nœud Atlas Cloud) |
FAQ : Lever le scepticisme derrière l'automatisation basée sur Rust
Un moteur basé sur Rust signifie-t-il que je dois écrire du code Rust brut pour créer un nœud ?
Non, vous n'avez pas besoin d'écrire du Rust pour étendre la plateforme. Bien que le cœur du moteur soit en Rust pur, flow-like utilise le sandboxing WebAssembly (WASM) pour prendre en charge la génération de nœuds personnalisés dans plus de 15 langages, dont TypeScript, Python et Go, sans compromettre la sécurité à l'exécution garantie par le moteur.
Comment le système à typage fort gère-t-il les charges utiles d'API dynamiques et arbitraires ?
Il mappe les entrées lâches dans un conteneur Struct bien défini au niveau du nœud d'ingestion. En imposant des limites strictes aux ports d'entrée, toute clé manquante ou mutation de format est détectée et traitée immédiatement au nœud frontal, garantissant que les étapes de logique interne ne rencontrent jamais de variables d'exécution indéfinies.
Quelle est la surcharge mémoire précise lors du traitement de boucles massives ?
La plateforme consomme en moyenne moins de 30 mégaoctets de mémoire vive sous des charges de travail typiquement lourdes. Comme Rust libère les registres des blocs de ressources dès que les données sortent du champ d'application, au lieu de mettre en file d'attente des ramassages de mémoire, les graphiques de consommation mémoire restent stables même lors du traitement de larges matrices d'itération.






