
Si vous écrivez des noyaux GPU (kernels), vous vous situez quelque part sur un spectre. À une extrémité se trouve Triton : rapide à écrire, mais le compilateur prend pour vous la plupart des décisions concernant la disposition (layout) et la mémoire partagée. À l'autre extrémité se trouve CUTLASS / CuTe : un contrôle total, au prix d'une machinerie de templates complexe. TileLang se situe au milieu. Vous écrivez en Python, mais vous spécifiez explicitement ce qui réside dans la mémoire partagée, comment le pipeline est structuré et comment les warps se répartissent le travail — et une passe d'inférence de layout complète le reste.
Dans cet article, nous aborderons le modèle mental, nous écrirons un GEMM, puis nous passerons à un véritable noyau de production : le décodage MLA de DeepSeek, où les décisions intéressantes prennent tout leur sens. L'objectif n'est pas d'être exhaustif. Il s'agit de montrer comment réfléchir par tuiles (tiles), et où TileLang prend discrètement en charge les parties complexes pour vous. Nous terminerons avec un cas d'usage typique en production : un noyau où le gain ne résidait pas du tout dans la vitesse.
Le modèle mental
Voici le concept en trois points clés :
- Une tuile (tile) est un objet de première classe. Un bloc de données structuré (ex: block_M × block_K) est détenu et manipulé par un bloc de threads, un warp ou un thread. Vous cessez de réfléchir uniquement au niveau du bloc de threads comme dans Triton, et vous n'avez plus à gérer manuellement chaque thread comme en CUDA.
- Vous placez vous-même les tampons dans la hiérarchie mémoire. Vous déclarez ce qui va en mémoire partagée (T.alloc_shared), ce qui va dans les registres (T.alloc_fragment) et ce qui est local au thread. C'est la différence majeure avec Triton, qui masque l'allocation et la mise en cache de la mémoire partagée au sein du compilateur.
- Le compilateur infère le mappage des threads. Une fois que vous avez défini où vit une tuile et quelle opération s'y applique (copie, gemm, réduction), une passe d' inférence de layout parallélise le tout entre les threads et détermine les dispositions des registres et de la mémoire partagée. Vous pouvez les surcharger si nécessaire, mais la plupart du temps, ce n'est pas requis. Cette passe est la fonctionnalité maîtresse — lorsque nous aborderons le MLA, vous comprendrez pourquoi.
Si vous venez de Triton, voici une correspondance rapide :
| Triton | TileLang | |
|---|---|---|
| Granularité | Bloc de threads + vectorisation implicite | Tuile (bloc / warp / thread) |
| Mémoire partagée | Gérée par le compilateur | Explicite avec alloc_shared + copy |
| Layout | Décidé par le compilateur | Inférez, mais annotable |
| Pipelining | tl.range + compilateur | Explicite via T.Pipelined(num_stages=) |
| Tensor Core | tl.dot | T.gemm avec politique de warp sélectionnable |
| Backends | NVIDIA (principalement) / AMD | NVIDIA / AMD / CPU / WebGPU / CuTeDSL, plus forks Ascend & MUSA |
En résumé : si vous souhaitez un contrôle précis sur le blocage, la profondeur du pipeline et le partitionnement des warps sans écrire du CUTLASS, TileLang est le point d'équilibre idéal. Pour des opérations élémentaires simples ou des fusions légères, Triton reste plus rapide à mettre en œuvre.
Installation
plaintext1conda create -n tilelang python=3.10 -y 2conda activate tilelang 3pip install tilelang # wheel préconstruit, le plus simple
Si vous devez modifier les passes du compilateur, construisez à partir des sources (vous aurez besoin d'une chaîne d'outils LLVM/CUDA locale) :
plaintext1git clone --recursive https://github.com/tile-ai/tilelang.git 2cd tilelang && pip install -r requirements-dev.txt 3pip install -e . -v --no-build-isolation
Écrivons un GEMM
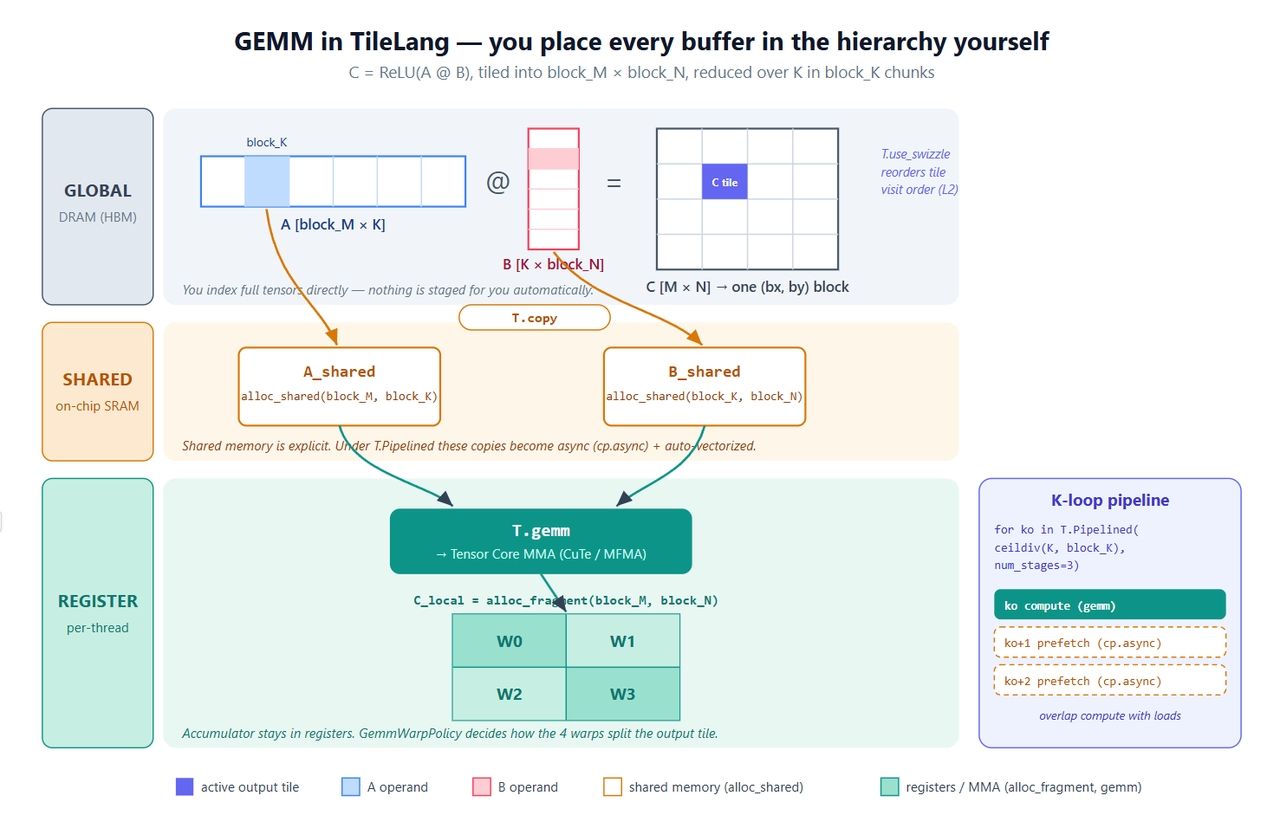
Commençons par le noyau classique : C = ReLU(A @ B). Il est simple, mais il utilise toutes les primitives essentielles : tampons explicites, copie parallèle, pipelining logiciel, appel aux Tensor Cores et swizzle L2.
python1import tilelang 2import tilelang.language as T 3import torch 4 5@tilelang.jit 6def matmul(M, N, K, block_M, block_N, block_K, 7 dtype="float16", accum_dtype="float"): 8 9 @T.prim_func 10 def matmul_relu_kernel( 11 A: T.Tensor((M, K), dtype), 12 B: T.Tensor((K, N), dtype), 13 C: T.Tensor((M, N), dtype), 14 ): 15 # grid dims: (#blocs sur N, #blocs sur M); 128 threads par bloc 16 with T.Kernel(T.ceildiv(N, block_N), T.ceildiv(M, block_M), 17 threads=128) as (bx, by): 18 19 # Déclaration explicite de l'emplacement des tuiles 20 A_shared = T.alloc_shared((block_M, block_K), dtype) # mémoire partagée 21 B_shared = T.alloc_shared((block_K, block_N), dtype) 22 C_local = T.alloc_fragment((block_M, block_N), accum_dtype) # accumulateur dans les registres 23 24 T.use_swizzle(panel_size=4, order="col") # optionnel : meilleure réutilisation L2 25 T.clear(C_local) # initialisation de l'accumulateur 26 27 for ko in T.Pipelined(T.ceildiv(K, block_K), num_stages=3): 28 T.copy(A[by * block_M, ko * block_K], A_shared) # global -> shared 29 T.copy(B[ko * block_K, bx * block_N], B_shared) 30 T.gemm(A_shared, B_shared, C_local) # MMA au niveau tuile 31 32 for i, j in T.Parallel(block_M, block_N): # ReLU fusionné 33 C_local[i, j] = T.max(C_local[i, j], 0) 34 35 T.copy(C_local, C[by * block_M, bx * block_N]) # écriture 36 37 return matmul_relu_kernel 38 39 40M = N = K = 1024 41kernel = matmul(M, N, K, block_M=128, block_N=128, block_K=64) 42a = torch.randn(M, K, device="cuda", dtype=torch.float16) 43b = torch.randn(K, N, device="cuda", dtype=torch.float16) 44c = torch.empty(M, N, device="cuda", dtype=torch.float16) 45kernel(a, b, c) 46 47torch.testing.assert_close(c, torch.relu(a @ b), rtol=1e-2, atol=1e-2) 48print("gemm ok")
Voici le rôle de chaque élément :
- Trois tampons, trois niveaux. A_shared et B_shared résident en mémoire partagée ; C_local réside dans les registres. L'accumulateur dans les registres et les opérandes transitant par la mémoire partagée — c'est la recette standard du GEMM, sauf qu'ici c'est vous qui l'écrivez. C'est toute la différence avec Triton.
- T.copy est une abstraction pour une copie parallèle. Elle se développe en un transfert de type T.Parallel, et le compilateur en déduit un transfert global→shared vectorisé et coalescé. Lorsqu'elle est placée dans T.Pipelined, elle devient automatiquement cp.async.
- T.Pipelined(extent, num_stages=N) est un pipeline logiciel. num_stages=3 signifie un triple buffering — pendant que vous calculez la tuile ko, les chargements pour ko+1 et ko+2 sont déjà en cours. Dans Triton, c'est un flag de compilation ; ici, c'est juste la boucle, plus facile à raisonner.
- T.gemm(A, B, C) est le matmul au niveau tuile. Il est abaissé vers CuTe/MMA sur NVIDIA et les intrinsèques équivalents sur AMD. Il accepte transpose_A / transpose_B et une politique=T.GemmWarpPolicy.* qui contrôle la répartition des warps sur la tuile de sortie. Gardez cet argument en tête — il est crucial pour le MLA.
- T.use_swizzle réorganise la planification des blocs de threads pour que les blocs adjacents dans le L2 s'exécutent de manière proche dans le temps. Cela libère généralement quelques pourcents de bande passante.
La figure ci-dessous illustre ce mappage sur le matériel.
Primitives utiles
Vous pouvez écrire la plupart des noyaux avec un vocabulaire restreint :
- Allocation : T.alloc_shared, T.alloc_fragment (registres), T.alloc_local.
- Déplacement et initialisation : T.copy(src, dst) entre n'importe quels niveaux ; T.clear, T.fill.
- Calcul : T.gemm(...); T.Parallel(d0, d1, ...) pour les boucles élémentaires (point d'entrée pour l'inférence de layout) ; T.reduce_max / T.reduce_sum ; mathématiques scalaires comme T.exp, T.exp2, T.max, T.infinity.
- Planification : T.Pipelined(extent, num_stages=), T.use_swizzle(...), T.annotate_layout(...) pour un layout spécifique (éviter les conflits de banques, swizzle personnalisé).
- Formes dynamiques : M = T.dynamic("m") pour éviter de recompiler à chaque forme (T.symbolic dans certaines versions).
Vérification du travail
Deux commandes sont essentielles. Pour voir ce que le compilateur a généré :
plaintext1print(kernel.get_kernel_source()) # CUDA / HIP généré
Et pour le mesurer :
plaintext1profiler = kernel.get_profiler(tensor_supply_type=tilelang.TensorSupplyType.Normal) 2print(f"latence : {profiler.do_bench()} ms")
T.print(buf) affiche une tuile depuis l'intérieur du noyau, et examples/plot_layout du dépôt permet de visualiser la disposition mémoire, utile pour résoudre les conflits de banques.
Le cas concret : décodage MLA
Le GEMM montre la mécanique. Voici pourquoi elle est importante. Analysons le noyau de décodage MLA (Multi-Head Latent Attention) de DeepSeek, car c'est l'exemple le plus clair de l'efficacité de TileLang. La référence TileLang atteint environ les performances FlashMLA sur H100 (benchmarké en batch 64/128 en fp16, devant Triton et FlashInfer) en 80 lignes de Python. La question est : comment ? Car la difficulté du MLA n'est pas mathématique, c'est la pression sur les registres.
Rappelons la boucle classique : pour chaque bloc de requête, vous streamez les blocs clé/valeur et maintenez un maximum et un dénominateur courants, afin que la matrice de scores complète ne tienne jamais entièrement en mémoire.
Pour le MLA, les dimensions de tête sont grandes : requête et clé font 576 (512 "nope" + 64 "rope"), et la valeur 512. L'accumulateur de sortie acc_o = [block_M, 512] doit rester dans les registres durant toute la boucle KV.
Sur Hopper, le chemin rapide est wgmma.mma_async, qui lie 4 warps (128 threads) en un groupe de warps (warpgroup) et requiert un M minimum de 64. Un warpgroup doit donc porter un accumulateur 64 × 512. C'est trop grand pour le fichier de registres d'un seul warpgroup, ce qui cause des débordements (spills) et fait chuter les performances.
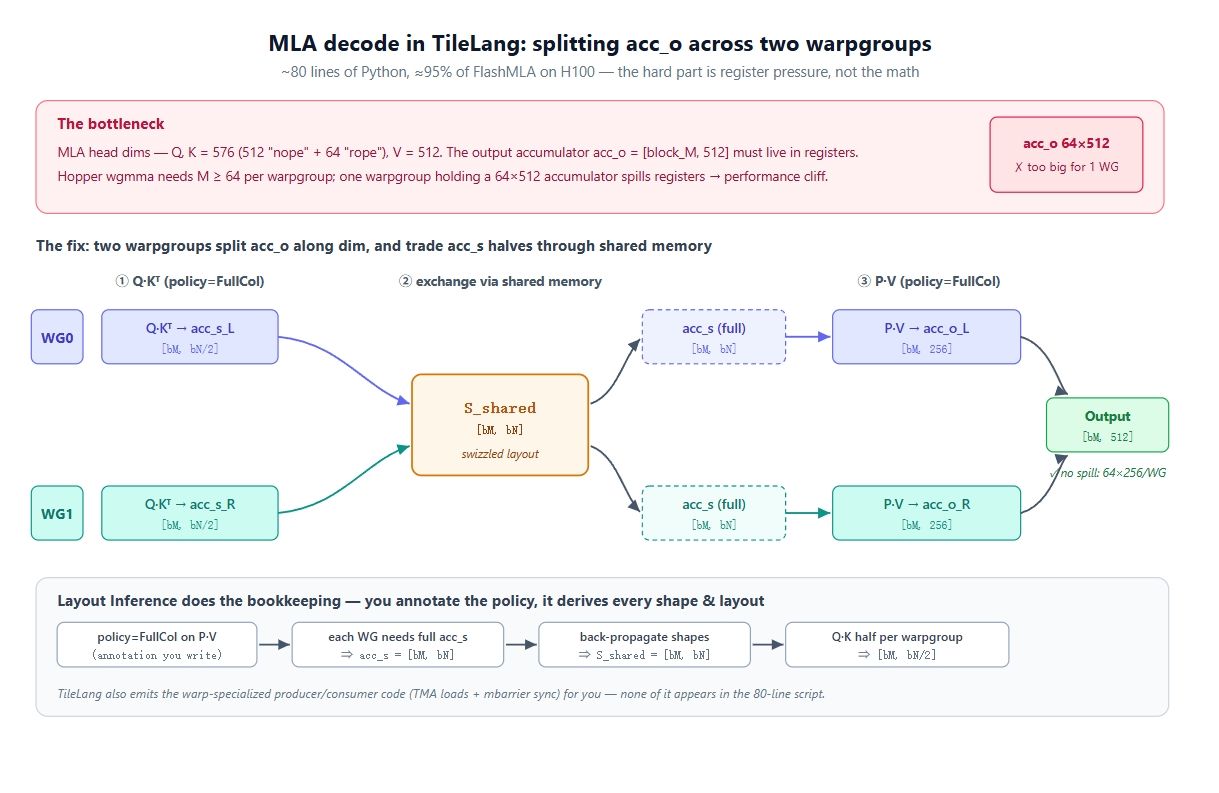
La solution consiste à diviser la sortie entre deux warpgroups. Comme on ne peut réduire M en dessous de 64, le seul axe disponible est la dimension (dim). Utilisez deux warpgroups : WG0 possède acc_o[:, :256], WG1 possède acc_o[:, 256:]. Chacun gère un accumulateur 64 × 256, ce qui tient dans les registres. Le problème suivant est que l'étape P @ V nécessite le score complet acc_s. La solution : un échange via la mémoire partagée. Pendant Q @ K, chaque warpgroup écrit sa moitié de acc_s en mémoire partagée et lit celle de l'autre, permettant à chacun de calculer sa partie de acc_o.
Dans CuTe, vous devriez écrire manuellement les layouts, les swizzles et les synchronisations. Ici, tout tient en 80 lignes grâce à l'inférence de layout.
Fonctionnement de l'inférence : vous annotez les appels T.gemm, et les contraintes se propagent :
- policy=FullCol sur P @ V signifie que chaque warpgroup a besoin du acc_s complet.
- Cela se propage au tampon de staging : S_shared devient aussi [block_M, block_N].
- Et vers Q @ K : avec FullCol, chaque tranche de score est [block_M, block_N/2].
Vous ne définissez aucune de ces formes. Vous choisissez la politique et écrivez les mathématiques ; le compilateur gère le reste.
Le noyau :
python1# acc_s = Q_nope @ KV^T + Q_rope @ K_pe^T 2T.gemm(Q_shared, KV_shared, acc_s, transpose_B=True, 3 policy=T.GemmWarpPolicy.FullCol, clear_accum=True) 4T.gemm(Q_pe_shared, K_pe_shared, acc_s, transpose_B=True, 5 policy=T.GemmWarpPolicy.FullCol) 6 7# online softmax... 8# ... 9# acc_o += P @ V 10T.copy(acc_s, acc_s_cast) 11T.gemm(acc_s_cast, KV_shared, acc_o, policy=T.GemmWarpPolicy.FullCol)
Les optimisations sont des lignes uniques :
- Swizzling de blocs de threads pour réutilisation L2 :
T.use_swizzle. - Swizzling mémoire partagée contre les conflits de banques :
T.annotate_layout. - Spécialisation de warps : le script est abaissé en un warpgroup producteur (TMA) et des consommateurs, avec synchronisation mbarrier générée automatiquement.
- Pipelining :
T.Pipelined.
Exemple interne : RMSNorm chez AtlasCloud
Dernier exemple : un noyau RMSNorm + SiLU fusionné pour le VAE de génération vidéo Wan sur H100/H200.
Le besoin. Nous avions un noyau manuel pour des dimensions {96, 192, 384}. Une nouvelle configuration nécessitait des largeurs comme {160, 256, 320, 512, 640, 1024}. Nous avons écrit un noyau TileLang en remplacement pour combler ce vide.
| Indicateur | Gain |
|---|---|
| Config précédemment non supportée | 0 → 1 (fonctionne désormais) |
| Attention-block RMSNorm vs PyTorch eager | 42 μs → 20 μs (~2× plus rapide) |
| VAE end-to-end (résolution prod) | ~1.79× encodage, ~1.78× décodage |
La première ligne est le point crucial : TileLang nous a permis de supporter une configuration modèle sans toucher aux noyaux manuels optimisés. Un seul ajout en Python, et un chemin complet du modèle est passé de "en erreur" à "en production".
Conclusion
Le génie de TileLang est que le raisonnement complexe reste dans votre tête, et non dans le code standard (boilerplate). Vous décidez de la répartition du travail, de l'emplacement des tampons et de la profondeur du pipeline — puis l'inférence de layout et la spécialisation des warps génèrent le code complexe que seraient des centaines de lignes de CuTe. Vous choisissez une politique et écrivez les mathématiques. C'est tout l'intérêt, et c'est pourquoi un noyau MLA de 80 lignes peut rivaliser avec un noyau CUTLASS optimisé à la main.






