Claude Code runs about $13 per developer per active day, and heavy automation can push that bill to between $500 and $2,000 per engineer every month (CloudZero, 2026). For a 50-person team, that is a five-figure line item appearing out of nowhere. If your AI coding bill jumped last quarter and nobody can explain why, you are not alone, and the fix is rarely "use the AI less."
The real problem is that agentic coding tools consume tokens in a fundamentally different way than a chat window does, and most teams are paying full price for tokens they could be getting at a fraction of the cost. This guide walks through seven concrete tactics to reduce AI coding token cost, with the numbers behind each one and the exact configuration changes that make them work.
Key Takeaways
- Agentic coding tools burn 10 to 100 times more tokens than chat, because the full context gets resent on every tool call (LeanOps, 2026).
- Prompt caching is the single highest-leverage change: cache reads cost roughly 10% of standard input tokens, and one team cut total LLM spend by 59% with it alone.
- Switching everyday coding to open-weight models like GLM, Kimi, and DeepSeek can cut per-token cost by 80% or more versus frontier models, with a smaller quality gap than most expect.
- Routing all of your tools through one gateway keeps a single budget, one API key, and consistent pricing instead of paying retail across five vendors.
Why AI Coding Token Cost Spirals Out of Control
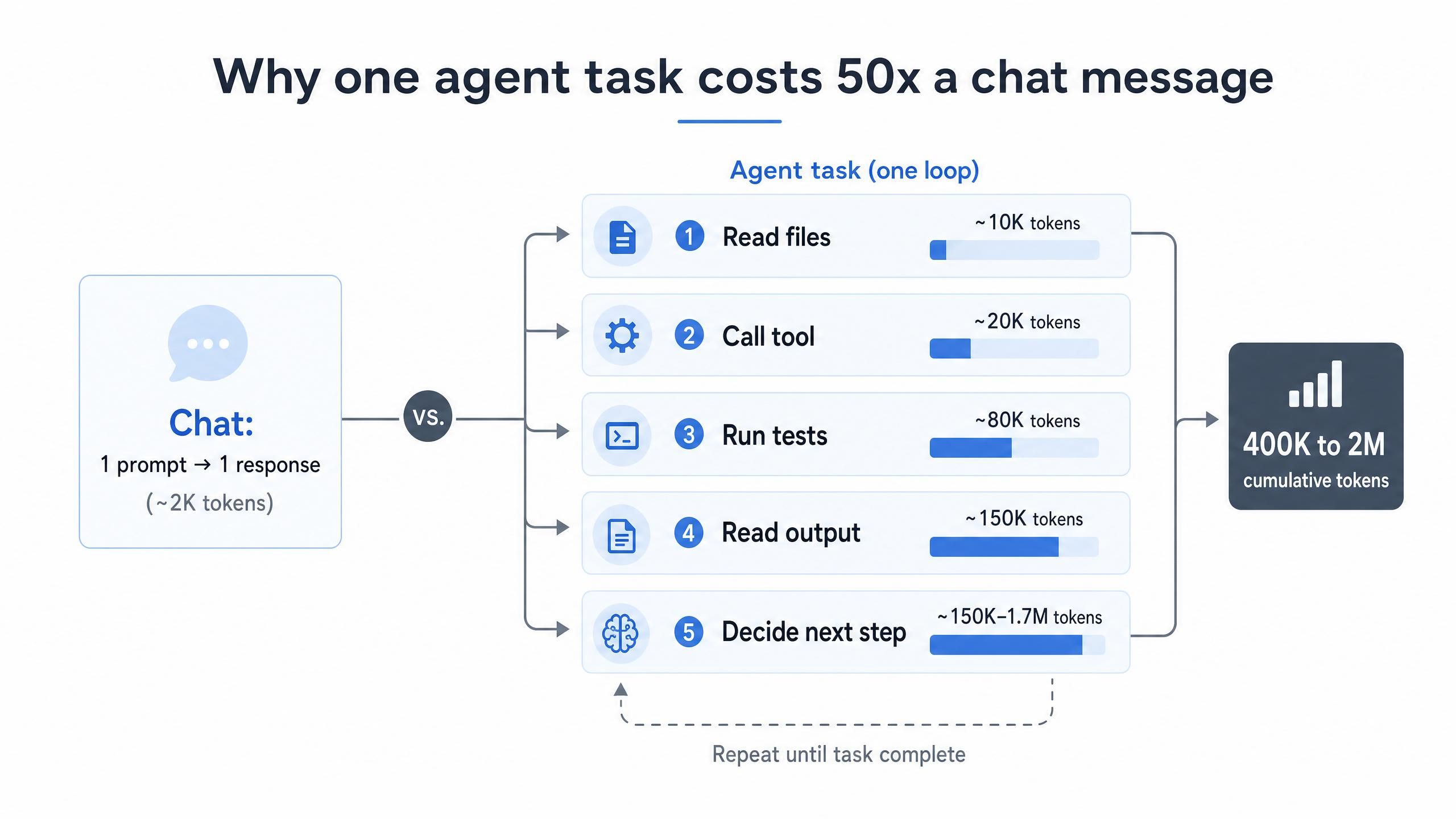
The core reason AI coding token cost runs so high is structural, not behavioral. A chat exchange sends a prompt and gets one answer. An agent does something very different: it reads files, calls tools, runs tests, reads the output, and decides on the next action. Each one of those reasoning steps re-sends the accumulated context, so token usage compounds with every loop. AI agents burn tokens 10 to 100 times faster than chatbots for exactly this reason (LeanOps, 2026).
The numbers get large quickly. A single non-trivial agent task can push 400,000 to 2,000,000 cumulative input tokens through the API as the context window fills and refills (Morph, 2026). Multiply that by dozens of tasks a day across a team, and the monthly invoice stops being a rounding error.
This is not a hypothetical concern for large organizations. According to a report covered by The Next Web, Microsoft pulled back most of its internal Claude Code licenses in part over cost, with per-engineer bills climbing into the $500 to $2,000 range (The Next Web, 2026). When one of the most resourced engineering organizations in the world flinches at the bill, it is worth understanding where the tokens actually go before you try to cut them.
How to Reduce AI Coding Token Cost Without Slowing Down
The good news is that almost none of these tactics require writing less code or babysitting the agent. They work by removing waste, repricing the same work, and matching each job to the cheapest model that can actually do it. Here are the seven that move the needle most, roughly in order of effort-to-payoff.
Tactic 1: Use Prompt Caching to Cut AI Coding Token Cost
Prompt caching is the highest-leverage single change you can make. When an agent resends the same system prompt, tool definitions, and file context on every step, caching lets the model read that repeated content from cache instead of reprocessing it. Cache reads are priced at roughly 0.10 times the standard input rate, a 90% discount on the repeated portion of every request (Finout, 2026).
The catch worth knowing: cache writes cost slightly more than a normal input token, about 1.25 times standard for a five-minute window. So caching pays off when context is reused within the time-to-live window, which is exactly the pattern an agent produces. The real-world impact is not theoretical. The team at ProjectDiscovery documented a 59% reduction in total LLM cost after implementing prompt caching across their pipeline (ProjectDiscovery, 2026).
If you run Claude Code or a compatible agent, confirm caching is enabled and that your system prompt and large file contexts sit in cacheable blocks. This one change often delivers the biggest percentage drop on the invoice.
Tactic 2: Match the Model to the Task to Lower Token Cost
Most teams route every request to their single most capable model, which is like taking a freight truck to buy groceries. The smarter pattern is to reserve the expensive frontier model for the work that genuinely needs it, and send everything else to a cheaper one.
A practical split looks like this:
- Reasoning, architecture, tricky debugging: a top-tier model where quality justifies the price.
- Everyday code generation and edits: a strong mid-tier open model.
- High-volume background jobs, classification, boilerplate: the cheapest capable model.
The savings are dramatic because the price spread is enormous. On the cheap end, DeepSeek V4 Flash runs around $0.14 per million input tokens, while frontier models cost many multiples of that (Codersera, 2026). Spending 80% of your token volume on a model that costs a fraction as much, while keeping the premium model for the 20% that needs it, can cut total spend by more than half without a noticeable drop in output quality.
Tactic 3: Keep the Context Window Lean
Because every token in context gets re-sent on every agent step, a bloated context window is a tax you pay repeatedly. Two habits help. First, scope each task tightly so the agent only loads the files it needs rather than the whole repository. Second, start a fresh session when you switch tasks instead of letting one conversation accumulate hundreds of thousands of stale tokens.
A useful mental model: if you would not paste a file into a chat to answer a question, do not leave it in the agent's context. Trimming a context window from 200,000 tokens to 40,000 tokens does not just save once. It saves on every single tool call for the rest of that task, which is where the compounding works in your favor for a change.
Tactic 4: Switch to Open-Weight Models to Reduce AI Coding Token Cost
This is the tactic with the largest headline savings and the most outdated assumptions attached to it. The open-weight coding models shipping in 2026 are genuinely good. On SWE-Bench Pro, a leading frontier model scores around 91, while Kimi K2.6 reaches 76.8 and DeepSeek V4 Pro lands near 77 (Codersera, 2026). That is a real gap on the hardest benchmark, but for routine feature work, refactors, and test writing, the difference is far smaller than the price difference.
And the price difference is the point. Open-weight models like GLM, MiniMax, Kimi, and DeepSeek cost a small fraction of frontier pricing per token. For the majority of day-to-day coding, an open model handles the job at a fraction of the cost. The friction has historically been access: juggling separate accounts, separate keys, and inconsistent pricing across providers.
This is where a unified coding gateway changes the math. A platform like Atlas Cloud aggregates the major open-weight models behind a single API and a single credit balance, so you can point Claude Code, Codex, or OpenClaw at GLM-5.1 today and Kimi K2.6 tomorrow without re-plumbing anything. Atlas Cloud publishes per-model credit multipliers that work out to roughly 45% to 55% savings versus the models' official API pricing, and the company positions its credit rate as cheaper than OpenRouter for the same models.
Here is a slice of how its credit multipliers translate across popular coding models:
| Model | Context | Input multiplier | Output multiplier | Approx. savings vs official |
|---|---|---|---|---|
| deepseek-ai/deepseek-v4-flash | 1M | 0.23 | 0.46 | ~50% |
| deepseek-ai/deepseek-v3.2 | 160K | 0.42 | 0.62 | ~55% |
| minimaxai/minimax-m2.5 | 200K | 0.65 | 2.18 | ~45% |
| moonshotai/kimi-k2.6 | 262K | 1.72 | 7.26 | ~45% |
| zai-org/glm-5.1 | 200K | 2.54 | 7.99 | ~45% |
Source: Atlas Cloud Coding Plan credit rules. Credit cost = input tokens × input multiplier + output tokens × output multiplier.
Tactic 5: Batch Background Work to Reduce AI Coding Token Cost
Not every token needs to be spent at interactive, real-time prices. Nightly evals, large classification jobs, documentation passes, and bulk refactors do not need a human waiting on them, which means they can run through cheaper batch lanes or on the lowest-cost model available. Moving this non-urgent volume off your premium interactive model is found money, because it is work you were already paying full retail for with no quality benefit from the higher price.
The principle is simple: separate "I am waiting for this" tokens from "this can finish overnight" tokens, and price them differently. For most teams, a surprising share of total token volume turns out to be the overnight kind.
Tactic 6: Route Every Tool Through One Coding Gateway
Tool sprawl quietly inflates AI coding token cost. A typical developer might use Claude Code in the terminal, Codex for some tasks, Cursor in the editor, and a couple of agents on the side, each with its own subscription, its own key, and its own opaque billing. You lose the ability to see total spend, and you pay retail everywhere.
Consolidating onto a single OpenAI-compatible endpoint solves both problems. Because Atlas Cloud exposes one base URL and one credit pool that works across Codex, Claude Code, OpenClaw, OpenCode, Cursor, and direct API calls, you get one bill, one budget, and one place to swap models. Its plans run from a $10 per month Starter tier up to higher tiers for heavier teams, and pay-as-you-go packs carry a 41% discount, so you can size the commitment to actual usage rather than guessing.
Pointing Claude Code at the gateway is a single config file. On macOS or Linux, edit ~/.claude/settings.json:
JSON1{ 2 "env": { 3 "ANTHROPIC_AUTH_TOKEN": "your-atlas-api-key", 4 "ANTHROPIC_BASE_URL": "https://api.atlascloud.ai", 5 "ANTHROPIC_MODEL": "zai-org/glm-5.1", 6 "ANTHROPIC_DEFAULT_HAIKU_MODEL": "zai-org/glm-5.1", 7 "ANTHROPIC_DEFAULT_SONNET_MODEL": "zai-org/glm-5.1", 8 "CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS": "1" 9 } 10}
For Codex users, the equivalent lives in ~/.codex/config.toml, pointing base_url at https://api.atlascloud.ai/v1 with your key in ~/.codex/auth.json. The same base URL works for OpenClaw, OpenCode, Cursor, and Copilot-style clients, so the whole team can standardize on one endpoint.
Tactic 7: Set Budgets and Monitor AI Coding Token Cost
You cannot reduce what you cannot see. The teams that got blindsided by huge bills almost always shared one trait: no spending controls and no per-developer visibility. The fix is to put a ceiling on consumption before the month starts, not after the invoice arrives.
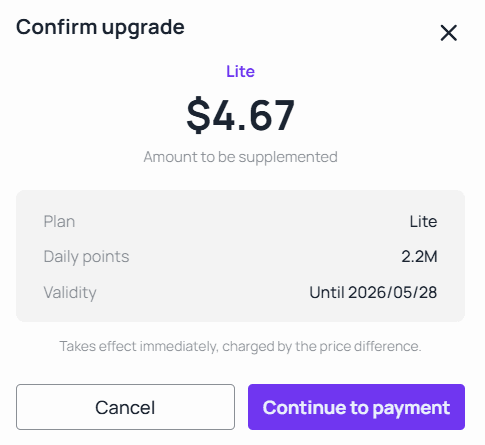
A credit-based plan with a daily quota does this structurally. Instead of an open-ended meter, a monthly subscription that refreshes a fixed credit allowance each day at midnight caps the blast radius of a runaway agent loop, while pay-as-you-go packs absorb occasional spikes once the daily allowance is used. When you do need to scale up, prorated upgrades mean you only pay the difference. Atlas Cloud's upgrade flow, for example, charges the remaining value against the new tier, so a mid-cycle move can cost as little as a few dollars rather than a full new plan.
A Real Cost Comparison: AI Coding Token Cost Across Models
To make the savings concrete, consider a developer who pushes roughly 1.5 million input tokens and 300,000 output tokens through their agent on a busy day, a realistic figure given that single tasks can hit seven figures of cumulative input. On a frontier model priced near $5 per million input and $25 per million output, that is about $7.50 in input plus $7.50 in output, or roughly $15 for one developer-day, which lines up with the widely cited $13 per active day figure (CloudZero, 2026).
Run the same volume through an open-weight model such as GLM or Kimi via a discounted gateway, and the input portion alone drops by 70% or more, with output following close behind. Layer prompt caching on top, and the repeated context that dominates agent workloads gets billed at a tenth of the rate. Stack the three tactics together, caching plus a cheaper model plus a lean context, and a $15 developer-day can realistically land closer to $3 to $5 without changing how anyone writes code.

The exact numbers will vary with your workload, but the shape holds: the bulk of AI coding token cost is repeated context running through an overpriced model, and both of those are fixable.
Putting It Together: A Setup That Keeps AI Coding Token Cost Low
If you want a starting configuration that captures most of the savings with minimal fuss, it looks like this. Use an open-weight model such as GLM-5.1 or Kimi K2.6 as your default coding model, keep a frontier model available for hard reasoning, enable prompt caching everywhere, scope tasks tightly to keep context lean, and route every tool through a single OpenAI-compatible endpoint with a fixed daily budget.
That combination addresses each cost driver at once: it reprices the tokens, it stops paying for repeated context, and it caps the downside. Teams that want this consolidated under one key and one budget can spin it up through the Atlas Cloud Coding Plan console, which supports the major open-weight models and the common coding tools out of the box. The setup takes a few minutes; the savings recur every single day.
Frequently Asked Questions About AI Coding Token Cost
Why is my AI coding token cost so much higher than my chat usage?
Because agents resend the full accumulated context on every reasoning step, while chat sends each prompt once. That structural difference means agents burn 10 to 100 times more tokens than chat for comparable work (LeanOps, 2026), so a few dozen agent tasks can dwarf a month of casual chat usage.
What is the single fastest way to reduce AI coding token cost?
Enable prompt caching. Repeated context in agent workloads gets billed at roughly 10% of the standard input rate once cached (Finout, 2026), and at least one engineering team reported a 59% drop in total LLM cost from caching alone. It requires no change to how you work, which makes it the highest payoff for the least effort.
Are cheaper open-weight models good enough for real coding work?
For most everyday tasks, yes. On the hardest benchmark, SWE-Bench Pro, top open models score in the high 70s versus around 91 for frontier models (Codersera, 2026), but routine feature work, refactors, and tests rarely stress that gap. Keep a frontier model on standby for genuinely hard reasoning and send the rest to an open model.
How much can I realistically save on AI coding token cost?
Stacking the main tactics, prompt caching, a cheaper default model, and a lean context, commonly cuts a developer-day from around $15 to the $3 to $5 range based on published per-token rates. The savings compound across a team, which is why a five-figure monthly bill is often a two-figure-percent reduction away from being reasonable.
Do I have to change tools to lower my token cost?
No. Most savings come from how tokens are priced and reused, not which client you use. Pointing your existing tools, whether Claude Code, Codex, or OpenClaw, at a discounted OpenAI-compatible endpoint is a config change, not a migration, so your workflow stays the same while the bill drops.
Conclusion
AI coding token cost feels mysterious until you see the mechanism: agents resend the same context over and over, and most teams pay frontier prices for all of it. Fix those two things, with prompt caching, smarter model routing, lean context, and a single discounted gateway, and the bill comes down by half or more without anyone writing a line of code differently. Start with caching this week, audit which tasks actually need your most expensive model, and consolidate your tools onto one budget. The setup is an afternoon; the savings are permanent.






