概要: GLM-5-Turbo は、Zhipu AI (Z.ai) が開発した OpenClaw ユースケース向けの大型言語モデルであり、同社初のクローズドソースリリース(以前はコードネーム Pony-Alpha-2 としてテスト)です。まもなく Atlas Cloud でリリースされる予定です。
このモデルは、ツール使用、命令実行、マルチステップワークフロー、および長時間のタスク処理において大幅な改善を実現しており、最大 200K トークンのコンテキストウィンドウをサポートしています。データ分析能力は Claude Opus 4.6 に匹敵し、自動化や情報処理タスクにおいて GLM-5 を凌駕します。Atlas Cloud の統合 API とマルチモデルエコシステムを活用することで、GLM-5-Turbo は複雑なビジネス自動化、長文ドキュメント分析、ソフトウェア開発全般で効率的なデプロイを可能にし、開発者や企業にコスト効率が高く統合が容易な AI ソリューションを提供します。
GLM-5-Turbo が Atlas Cloud に登場することをお知らせいたします!
- GLM-5-Turbo とは:Zhipu AI (Z.ai) が開発した GLM-5-Turbo は、OpenClaw ユースケースに最適化された大型言語モデルです。同チーム初のクローズドソースリリースであり、GLM-5 よりも高い実行効率と低いコール単価を実現しています。これに先立ち、Zhipu AI は次世代モデルをコードネーム Pony-Alpha-2 として非公開でテストしていました。
- 主な機能:GLM-5-Turbo は、ツール使用、命令追従、マルチステップワークフロー、および継続的なタスク実行において大幅な改善を実現しました。シナリオに応じた動的な推論モード、リアルタイムストリーミング出力、強化されたツール統合、最大 200K トークンの長文コンテキスト処理をサポートしています。
- リリース日:2026年3月24日。
GLM-5 は以前、Artificial Analysis Intelligence Index で Gemini 3 Pro を上回る最高性能のオープンソースモデルとして注目を集めました。その後継モデルである GLM-5-Turbo は、以下の通り一連の反復アップグレードが導入されています。
コアポジショニング:ClawBench に最適化されたモデル
強力なベンチマーク性能
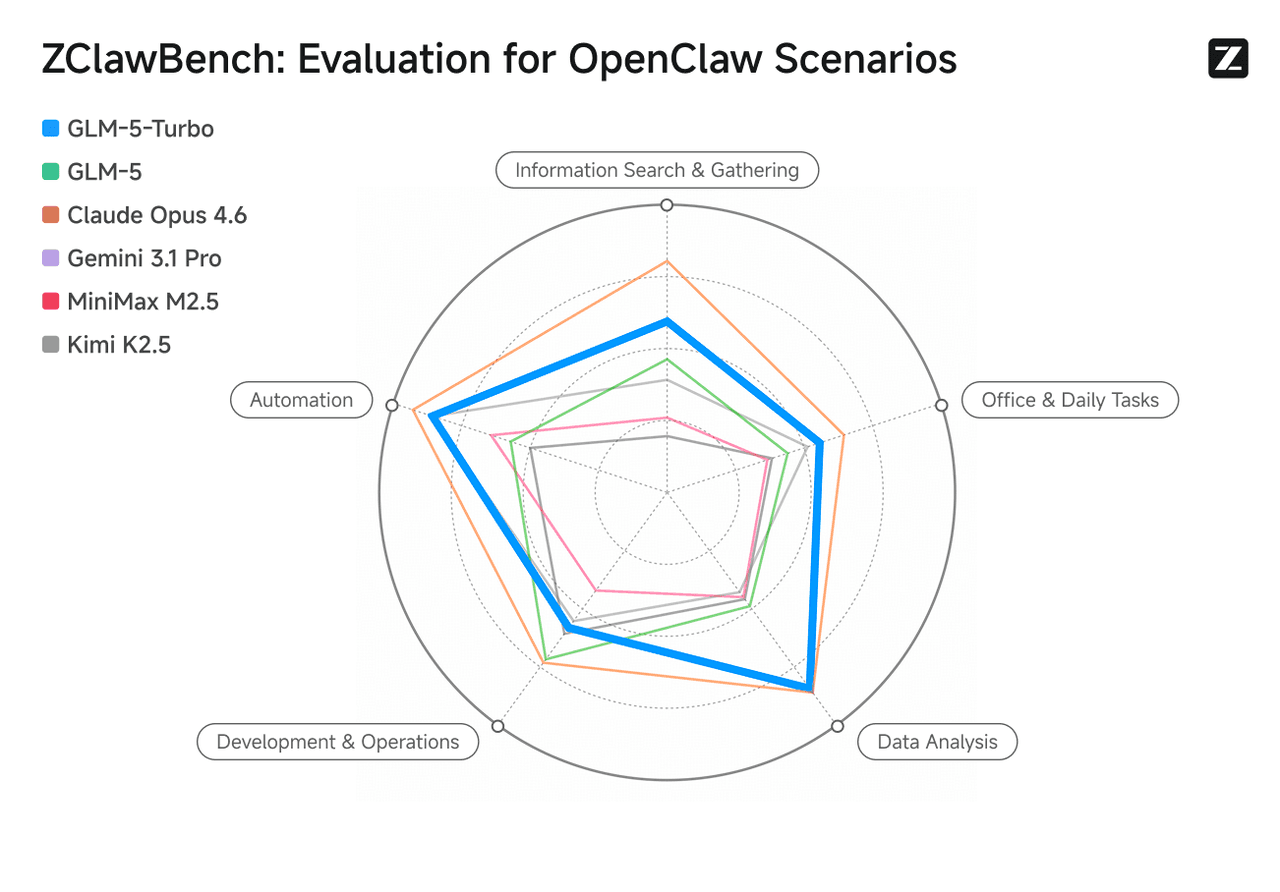
OpenClaw シナリオ向けに最適化された GLM-5-Turbo は、ツール呼び出し、命令実行、複雑なタスクのオーケストレーションにおける能力を大幅に強化しました。そのデータ分析性能は Claude Opus 4.6 と同等であり、自動化、情報検索、オフィス生産性、および分析タスクにおいて GLM-5 を上回ります。
画像ソース:Zhipu AI (Z.ai) 公式サイト。
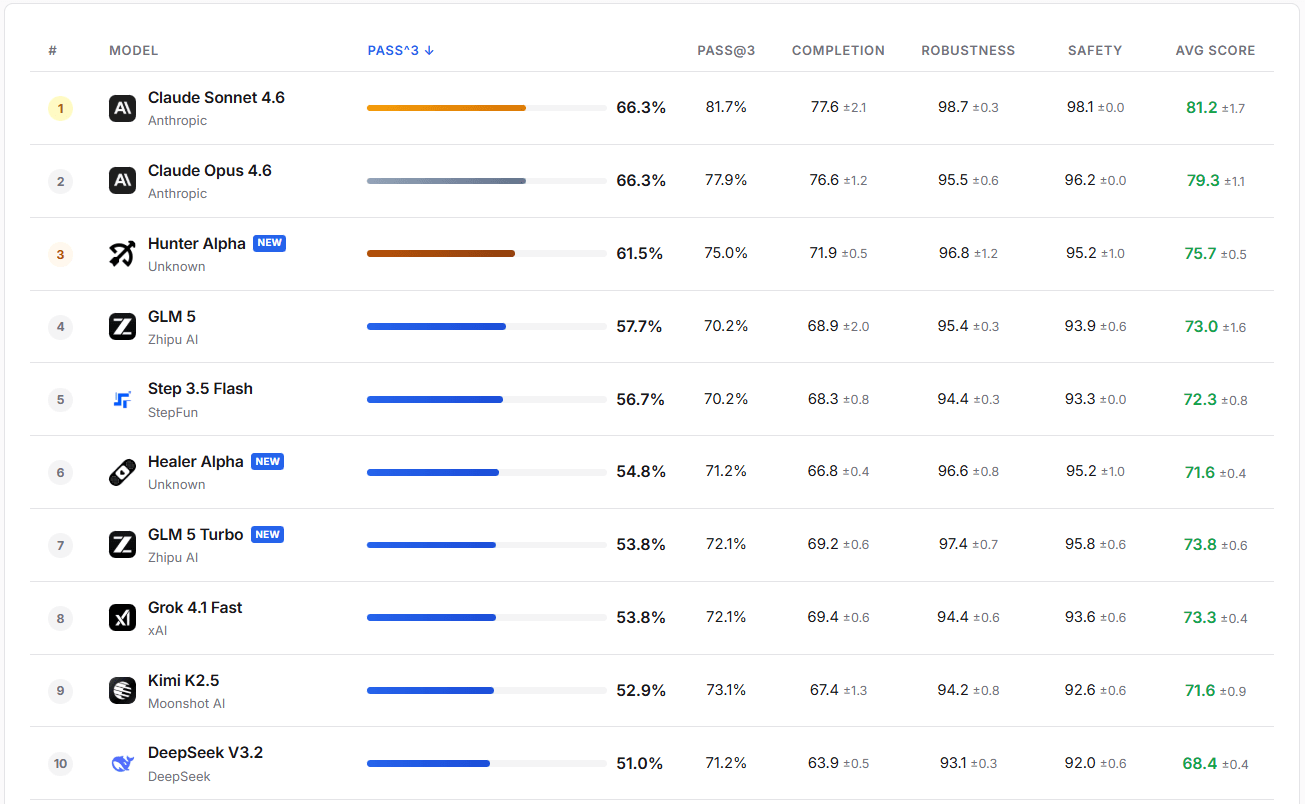
実用的な評価において、GLM-5-Turbo は高い堅牢性と安全性を発揮します。PASS@3 の成功率は GLM-5、Step 3.5 Flash、および Kimi K2.5 を上回っています。
画像ソース:https://claw-eval.github.io/
ツール使用と外部統合の強化
Z.ai は学習中に GLM-5-Turbo のエージェント機能を強化し、外部ツールとのシームレスな対話を可能にしました。この実行優先の姿勢にはトレードオフもあり、ロールプレイングシナリオでは GLM-5 と比較してやや機械的な口調であるとのユーザー報告もあります。
モデルごとの強みを活かすため、Atlas Cloud は複数のモデルを同時にクエリし、比較検討して選択できる統合インターフェースを提供しています。
さらに、ユーザーはカスタムスキルを定義したり、GLM-5-Turbo に自律的にスキルを発見・インストールさせたりすることが可能です。
画像ソース:Atlas Cloud

長期間の自律実行
GLM-5-Turbo は、スケジュールトリガーや長時間の実行時間を必要とするタスクに最適化されています。継続的かつマルチステージで、時間軸を跨ぐワークフローにおいても強力なタスク継続性を発揮します。
このモデルは、タスクの複雑さに基づいて実行戦略をプロアクティブに提案します。コード最適化の比較テストでは、GLM-5-Turbo が生成した推奨事項が約 10% のケースで競合モデルを上回りました。
200K トークンのコンテキストウィンドウ
最大 200K トークン(英語で約 133,000 ワード相当)をサポートする GLM-5-Turbo は、単一のセッション内で広範なコンテキストを保持および利用できます。これにより、会話の後半段階でも以前の情報を正確に取得することが可能です。
画像ソース:Jim Allen Wallace (Redis)
ユースケース
複雑なワークフローの自動化
OpenClaw 機能の強化により、GLM-5-Turbo は複雑なビジネスプロセスを分解し、基礎となるロジックを特定し、タスク実行に必要なスキルを自律的に検索または生成できます。
例えば、ショート動画制作において、ライティング、画像生成、動画制作ツールを検索・インストールし、ワークフロー全体をエンドツーエンドで計画・実行することができます。
長文ドキュメントの QA と詳細分析
このモデルは、1 つのセッション内で長いドキュメント全体にわたってコンテキストを維持できるため、正確なマルチターン対話が可能です。高いトークン効率により、計算コストを抑えながら高速なレスポンスを実現します。
大規模なコードベースにおいて、GLM-5-Turbo はアーキテクチャ設計を分析し、コンポーネント間の依存関係をマッピングし、低レベルなコード変更による波及効果を特定できます。
「Vibe Coding」
ソフトウェア開発ライフサイクルにおいて、GLM-5-Turbo は複雑なワークフローに組み込まれたフルスタックエンジニアのような役割を果たします。開発者はハイレベルなロジックの概要を伝えるだけで、モデルがリアルタイムでアプリケーションアーキテクチャを段階的に構築します。
マルチモーダルスキルと組み合わせれば、UI 画像、画面録画、またはスケッチをアップロードするだけで、モデルがそれを直接機能的なフロントエンドコンポーネントに変換することも可能です。
Atlas Cloud で GLM-5-Turbo を利用する理由
Atlas Cloud はオールモーダルな AI インフラプラットフォームとして、ユーザーに統合 API インターフェースを提供します。接続が完了すれば、テキスト、画像、動画生成、またはマルチモーダルモデルなど、300 以上の高度な AI モデルを簡単に利用できます。
ターゲット層
- 個人開発者: さまざまな AI モデルを呼び出すための、低コストでシンプルなソリューションを求める方。
- 企業: 中核事業を支えるための安定性、セキュリティ、スケーラビリティを備えたインフラを必要とする方。
- 開発チーム: プロジェクトに複数のクロスモーダルモデルを効率的に統合したい方。
- ワークフロー利用者: ツールチェーンの互換性を重視し、ComfyUI や n8n を使用している方。
製品の特徴
- 統合の大幅な簡素化: OpenAI 互換の API を提供し、開発者の作業負荷を即座に軽減します。複数のベンダーキーを管理したり、プラットフォームごとの維持費に頭を悩ませたりする必要はありません。
- コスト上の優位性: 競合他社と比較して、Atlas Cloud はデプロイコストが低く抑えられています。Nano Banana 2 は USD0.056/画像(競合:USD0.07/画像)、Veo 3.1 は USD0.09/秒(競合:USD0.1/秒)です。また、Playground インターフェースでは価格の透明性が高く、「実行」ボタンを押すだけで画像や動画 1 秒あたりの控除額が明確に表示されます。
- エンタープライズグレードの安定性とサポート: Atlas Cloud は、厳格なプライバシー基準を満たすデータ保護を確保しており、機密情報を取り扱うことが可能です。
- プラグアンドプレイ対応: ComfyUI や n8n などのツールと簡単に連携できるように構築されており、乗り換えコストを削減し、すぐに業務を開始できます。
類似製品との比較
- Fal.ai: 一部のモデルは提供していますが、Atlas Cloud はより広範な選択肢(300以上)と競争力のある価格を提供しており、新規登録ユーザーには USD1 のトライアルクレジットが付与されます。
- Wavespeed: 価格が大幅に高くなっています。Atlas Cloud は、Wavespeed が強調していないエンタープライズコンプライアンスサポートや専門的な技術指導を提供しています。
- Kie.ai: 不透明なクレジットシステムを採用しています。Atlas Cloud は、実行ごとの正確なコストをインターフェース上に直接表示します。モデル数も Kie.ai より多くなっています。
- Replicate: モデルのホスティングに焦点を当てています。Atlas Cloud の強みは、API の統合性、モデルデプロイの速度、そして開発者にとってより親しみやすいサポートポリシーにあります。
- OpenAI または Google: これらのベンダーは自社モデルしか提供していません。クロスモーダルなニーズがある場合、通常は複数のサービスを統合する必要があります。Atlas Cloud は独自モデルとオープンソースモデルを 1 つの API 下に統合しており、システム構成を簡素化できます。
Atlas Cloud で GLM-5-Turbo を利用するには?
方法 1:プラットフォーム上で直接使用する
方法 2:API 統合を通じて使用する
ステップ 1: API キーを取得します。 コンソール で API キーを作成して貼り付けます:


ステップ 2: API ドキュメント を参照します。リクエストパラメータや認証方法などを確認してください。
ステップ 3: 最初の最初のリクエストを実行します(Python の例)
GLM-5 を例にします。
plaintext1{ 2 "model": "zai-org/glm-5", 3 "messages": [ 4 { 5 "role": "user", 6 "content": "Hello" 7 } 8 ], 9 "max_tokens": 1024, 10 "temperature": 0.7, 11 "stream": false 12}
FAQ
GLM-5-Turbo と GLM-5 の違いは何ですか? GLM-5-Turbo はより高速かつコスト効率が高く、トークン効率が大幅に改善されています。報告によると GLM-5 の最大 3 倍に達します。また、OpenClaw シナリオ専用に最適化されています。
GLM-5-Turbo は MiniMax M2.7 と比べてどうですか? どちらのモデルもエージェント的なツール使用に最適化されており、GLM-5 よりも高いトークン効率を備えています。それぞれ約 200K トークンのコンテキストウィンドウをサポートしています(MiniMax M2.7 は 196,608 トークンをサポート)。詳細な比較評価ブログを準備中です。続報をお待ちください!
OpenClaw デプロイにはどの GLM モデルが推奨されますか? OpenClaw シナリオに最適化されており、Claude Opus 4.6 に匹敵するデータ分析性能を実現している GLM-5-Turbo を推奨します。






