Gemini Omniは、従来のAIシステムからの大きな転換点です。これは、最初から情報を自然に処理するオールインワン型AIモデルとして機能します。異なるメディアタイプのために複数のツールを繋ぎ合わせるのではなく、単一のユニバーサルニューラルエンジン上で完全に実行されます。テキスト、画像、音声、ビデオを単一のクロスモーダルなベクトル空間内で処理することで、レガシーなデータサイロや通信のボトルネックを完全に取り除きます。
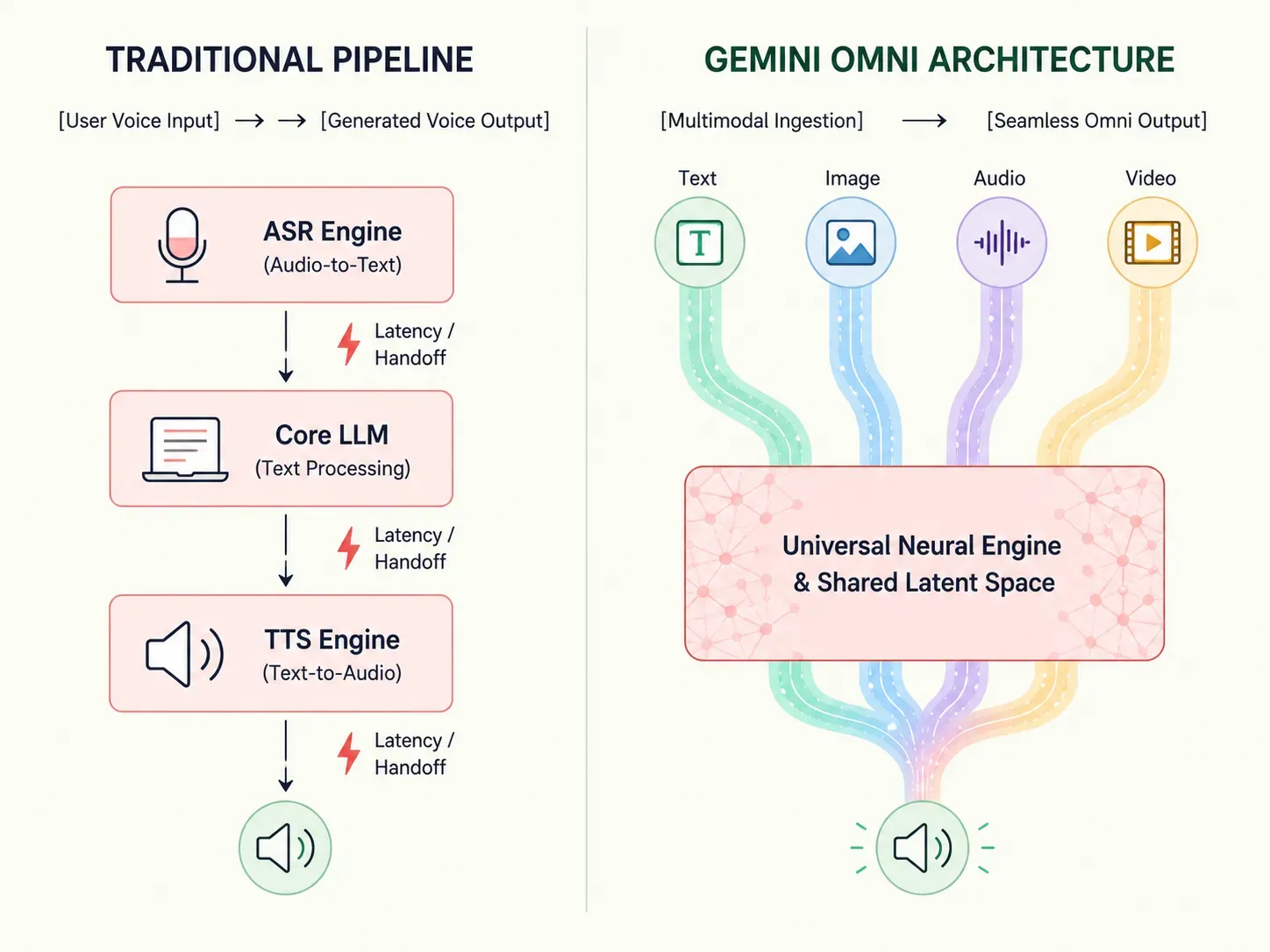
従来の人工知能は、言語モデルが回答の処理を開始する前に、音声をテキストに変換するといった段階的なパイプラインに依存していました。Gemini Omniは、このワークフローを根本的に再定義します。
- ネイティブインジェスト: システムはテキストトークン、画像ピクセル、音声周波数、ビデオフレームをすべて同時に処理します。
- コンテキストの保持: エンドツーエンドのデータ処理により、繊細な感情、視覚的な手がかり、細かい詳細が異なる層の間で失われるのを防ぎます。
この構造的なシフトは、処理効率を向上させ、遅延を人間に近い応答時間まで短縮します。開発者や企業は、複雑なマルチモデル構成をスキップし、真のマルチセンサリーコンピューティングのために構築された堅牢な単一システムを利用できるようになりました。
単一モデルがいかにして4つのモダリティを同時に計算するか
Gemini Omniの機能がどのようにしてテキスト、画像、音声、ビデオを同時に処理するかを理解するには、その中核となるデータレイヤーを直接見る必要があります。従来のシステムは、異なるファイルタイプを個別の孤立したサブモデルにルーティングしていましたが、Gemini Omniはこの断片的な手法を完全にバイパスします。すべての入力をAIコアが理解できる単一の言語にネイティブ変換する、統合トークン化フレームワークを実装しています。
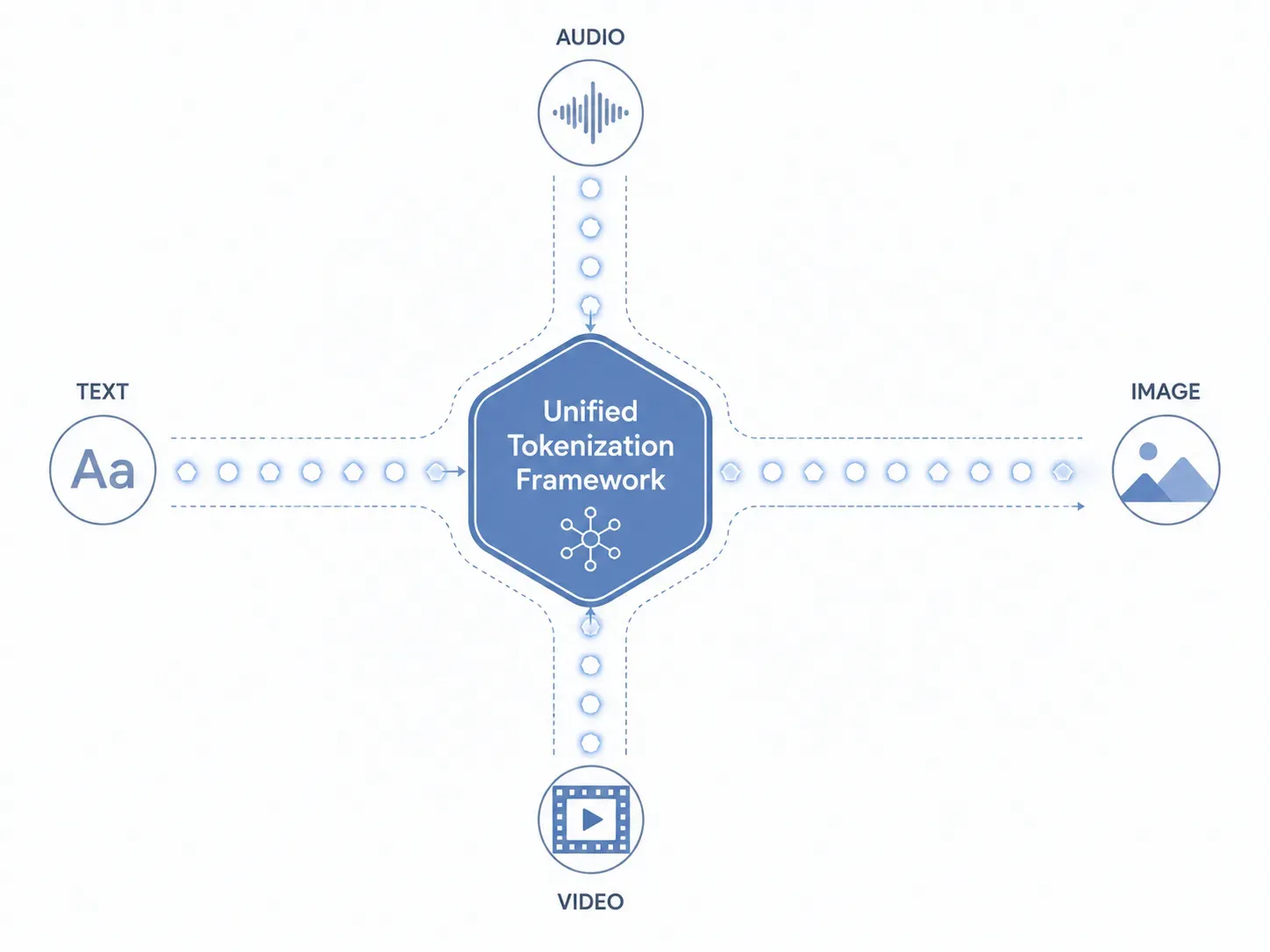
統合トークン化のメカニズム
Gemini Omniは、個別のサブモデルなしでどのように異なるファイルタイプを処理するのでしょうか?その答えは、推論が始まる前にデータがどのように取り込まれ、分解されるかにあります。
- テキスト: 英数字は標準的なセマンティック・テキストトークンに変換されます。
- 画像: 視覚要素は小さなピクセルのパッチにスライスされ、ビジュアルトークンとしてマッピングされます。
- 音声: 連続的な音波がサンプリングされ、周波数とトーンがキャプチャされて音響トークンに変換されます。
- ビデオ: 動画は連続する時間フレームのシーケンスとして扱われ、時空間トークンが確立されます。
共有ウェイトとネイティブテンソル処理
この多様なマルチモーダルデータインジェストが完了すると、すべてのデータ型は共有ウェイトアーキテクチャに入ります。遅延を引き起こすブリッジを介してデータをやり取りする個別の専門化されたエンコーダーを使用する代わりに、単一のコアニューラルネットワークがすべてのトークンを一様に処理します。
ネイティブテンソル処理を使用して、モデルはテキスト、音声、ビジュアルトークンの数学的計算を同じ行列層内で実行します。すべてが同じ計算空間を共有しているため、ネットワークは翻訳ステップを一つも挟むことなく、話し言葉、書き言葉、画像ピクセル、ビデオフレーム間の関係を直接理解します。
これらのエンジニアリング原則とネイティブトークン化が現実世界のシナリオでどのように大規模展開されているかを確認するには、MITメディアラボの「Research Vision Presentation」をご覧ください。このプレゼンテーションでは、AIモデルを物理的かつマルチセンサリーな世界の豊かな信号スペクトルに直接接続するという、業界の長期的なシフトの概要を説明しています。
コアモダリティの柱:クロスメディア処理マップ
Gemini Omniの力を真に把握するには、単なるデータインジェストを超えて考える必要があります。このモデルは、テキスト、画像、音声、ビデオが共有された潜在空間マッピング内に存在する統合アーキテクチャを利用しています。あるモダリティで入力が変化すると、それは単に孤立した反応を引き起こすだけでなく、他の3つの形式の数学的パラメータを同時に動的に変化させます。
マルチモーダル相互依存マトリックス
このリアルタイムのクロスメディア推論は、相互依存するデータストリームに依存しています。データを逐次ブロックで処理するのではなく、モデルは4つの柱すべてを継続的に同期させ、完璧なマルチモーダルアライメントを実現します。
以下の処理マップは、これらのライブ入力がユニバーサルニューラルネットワーク内でどのように互いに影響し合っているかを示しています。
| 主なメディア入力 | 共同処理モダリティ | システム操作 | 深い技術的意図 |
| 音響波形 | テキスト + ビデオフレーム | 音声の調子を追跡して時系列ビデオシーケンスをインデックス化 | リアルタイムの感覚アライメント |
| 静止画像 | 生オーディオ + テキスト | 視覚的な色スペクトルを一致する文脈的音響に変換 | クロスモーダル合成 |
| 英数字コード | ビデオ配列 + テキスト | プログラミングロジックを介してビデオの構造変数を直接変更 | 生成コード実行 |
| 時系列ビデオシーケンス | 音声トラック + コード | 多層データトラック全体で時空間的な更新を計算 | 統合ビデオ・音声解析 |
リアルタイムパラメータ同期の実際
Gemini Omniがライブビデオフィードを処理する際、視覚情報とバックグラウンドトラックを分離することはありません。音声入力で叫び声などの急激な周波数スパイクが検知されると、モデルは即座にビジュアルトークンの期待値を更新します。ビデオフレームが発生する前に、急激な物理的移動やフレームの変化を予測します。
この深い相互影響により、コンテキストのずれ(ドリフト)を防ぎます。ネットワーク全体がこれらの変数を同時にバランスさせているため、モデルが同期されたビデオサマリーを生成する場合でも、ライブのマルチセンサリーストリームをオンザフライで翻訳する場合でも、出力は完璧に整合性を保ちます。
遅延とコンテキストドリフトの排除:統合ウェイトの利点
Gemini Omniの速度を理解するには、従来の「継ぎ接ぎ」AIパイプラインの数学的な非効率性に注目するのが有益です。これまで、音声やビデオに対応したアシスタントを構築するには、単一目的のソフトウェアレイヤーを別々に繋ぎ合わせる必要がありました。
plaintext1[ユーザーの音声入力] 2 │ 3 ▼ 4 1. ASRエンジン (音声からテキストへの書き起こし) 5 │ 6 ▼ 7 2. コアLLMレイヤー (テキスト生成処理) 8 │ 9 ▼ 10 3. TTSエンジン (テキストから音声への合成) 11 │ 12 ▼ 13[生成された音声出力]
この多段階のオーケストレーションは、データを連続したソフトウェアブリッジ間で移動させる必要があり、実行遅延を増大させます。個別のテキスト読み上げエンジンは、元の音声録音を聞くことができません。これにより、メディアタイプ間で膨大なデータ損失が発生します。ユーザーの皮肉なトーン、ためらい、精神的な苦痛といった重要な声の手がかりは、すべてがプレーンテキストに平坦化されると完全に消えてしまいます。
真のパイプライン遅延の削減
Gemini Omniは、統合されたニューラルウェイトで動作することで、これらの境界を回避します。単一のニューラルネットワークがテキスト、音声、ピクセルを一つの数学的屋根の下でネイティブに評価するため、実行速度が劇的に向上します。このレイアウトは、強力なパイプライン遅延の削減をもたらします。
Google DeepMindのベンチマークレポートによると、ライブ音声ストリームを実行するネイティブマルチモーダルアーキテクチャでは、エンドツーエンドの応答時間が150ミリ秒以下に短縮されます。このシフトは、リアルタイムの人間同士の会話の自然なテンポに実質的に匹敵します。
コンテキスト保持の最適化
純粋な速度に加えて、統合された実行は高度なコンテキスト保持の最適化を保証します。モデルに話しかけると、ウェイトがあなたの音声周波数とテキスト定義を同時に処理します。
- イントネーション処理: ネットワークは声の変調を直接捉え、適切な共感や緊急性を持って応答します。
- 視覚同期: ビデオフレーム内の微妙な表情の微細な動きや空間的な動きが、解析エラーなしで会話出力に直接反映されます。
中間の翻訳ステップを削除することで、Gemini Omniは細部が消えてしまうのを防ぎます。これにより、人間と機械の間で、感覚を超えたスムーズで自然な相互作用のための強固な基盤が構築されます。
Omni-Channel AIシステムによるエンタープライズワークフローの構築
このネイティブマルチモーダルへのシフトは、企業がデジタルツールを構築・拡張する方法を変えます。オールインワンのAI設定を使用することで、企業は煩雑で別々のソフトウェアパーツを統合ワークフローに置き換えることができます。これにより、インタラクティブで混合メディアのシステムを大規模に簡単に実行できるようになります。
シングルAPIアーキテクチャ
開発者は、音声認識、テキスト分析、画像処理のためにバラバラなクラウド機能を調整する必要はもうありません。Atlas Cloud AIモデルAPIのように、アプリケーションレイヤーをコアネットワークに直接接続する、単一の統合API統合を使用するだけです。この合理化されたパスにより、チームは単一のリクエストフレームワークで高度なクロスメディアパイプラインを構築できます。
plaintext1 ┌─────────────────────────────────┐ 2 │ Unified Gemini API │ 3 └────────────────┬────────────────┘ 4 │ 5 ┌─────────────────────────┼─────────────────────────┐ 6 ▼ ▼ ▼ 7┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐ 8│ リアルタイムコード │ │ 混合メディアデータ │ │ マルチセンサリー │ 9│ & アセット同期 │ │ 自動化レイヤー │ │ ダッシュボード │ 10└──────────────────┘ └──────────────────┘ └──────────────────┘
例えば、企業の研修プラットフォームであれば、ライブビデオストリームの処理、話者の音声リズムの追跡、対話の翻訳、視覚データダッシュボードの動的な更新をすべて同時に行うことができ、これらすべてが単一のバックエンドシステムによって駆動されます。
戦略的導入の利点
オールインワンモデルアーキテクチャに切り替えることの導入上の利点は何ですか?
古いマルチモデル構成から単一のニューラルネットワークに切り替えることで、企業のITシステムに即座かつ確実なメリットがもたらされます。
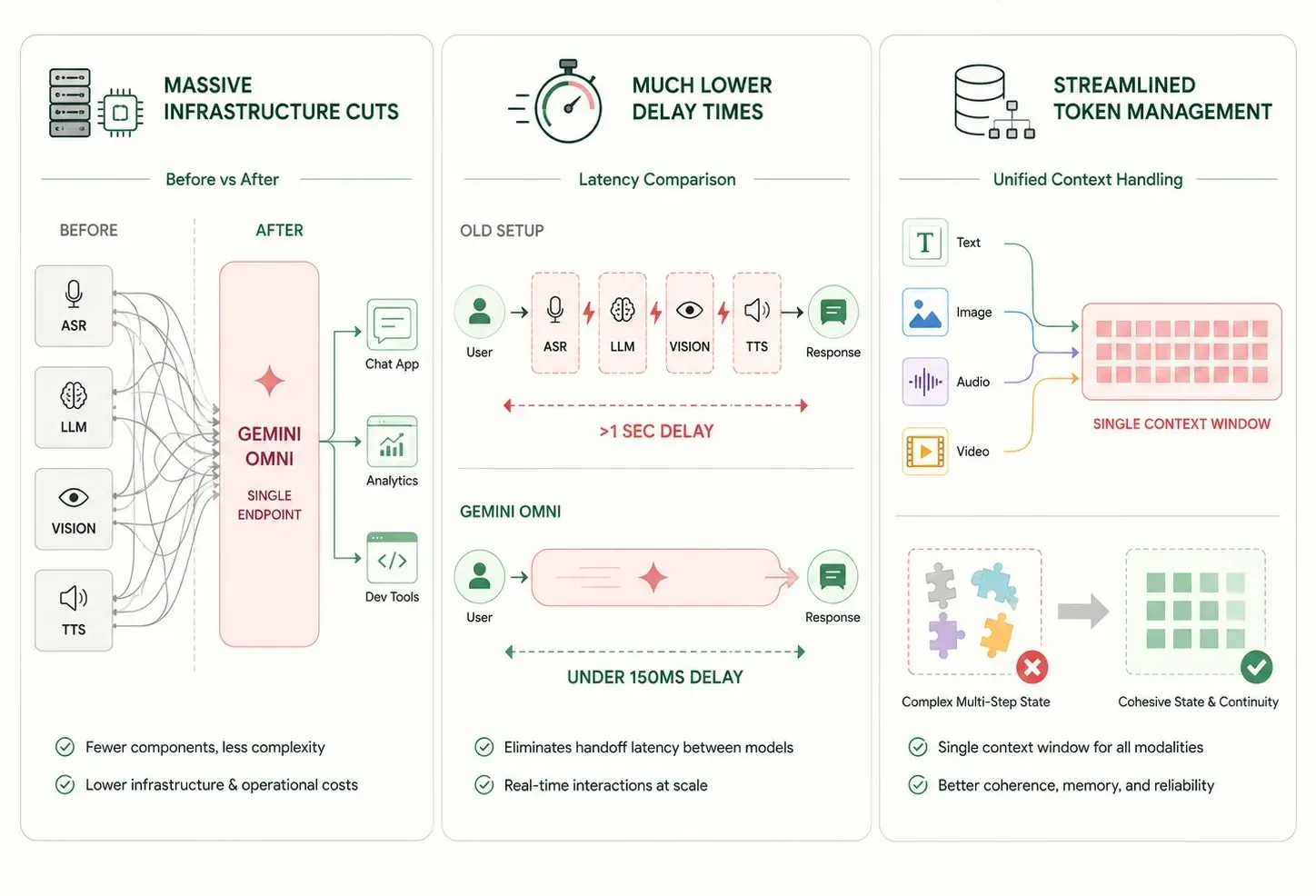
- 大幅なインフラストラクチャ削減: テキスト、視覚、音声タスクを1つのモデルに集約することで、個別のソフトウェアエンドポイントの数が減ります。これにより、長期的なメンテナンスが大幅に容易になります。
- 遅延時間の劇的な短縮: 小さな専門ツール間の追加ネットワークステップをスキップすることで、応答時間を1秒以下に短縮します。これにより、真にリアルタイムなユーザー体験が可能になります。
- 合理化されたトークン管理: すべてのモダリティを一様に追跡する単一のコンテキストウィンドウにより、多段階プロセス全体での複雑な状態管理の問題が軽減されます。
スケーラブルなマルチモーダル展開の実現
Gemini Enterprise Agent Platformのようなフレームワークを通じて運用することで、企業は自律型サブエージェントのネットワークをシームレスに調整できます。この単一システムにより、大規模なマルチメディアプロジェクトを簡単に実行できます。バックグラウンドのコンテキストやユーザーIDを数日間にわたるワークフロー全体で追跡する管理環境を使用しています。異なる入力を一つの安全な空間に保持することで、企業はデータを失ったり主要なトピックを見失ったりすることなく、メディア間でタスクを最初から最後まで自動化できます。
コンピューティング制約とグローバルAI推論のためのハードウェア最適化
統合ネットワークアーキテクチャ下で4つの別々のデータストリームを処理することは、シームレスなクロスメディアワークフローを可能にする一方で、現代のハードウェアインフラストラクチャに前例のない要求を突きつけます。この環境をナビゲートするには、グローバル規模での同時マルチセンサリー処理に関連する極端な物理的ペナルティを克服するための、細心のコンピューティングリソース管理が必要です。
マルチモーダルトークン化のオーバーヘッド
最大のエンジニアリングの課題は、マルチモーダルトークンオーバーヘッドに起因します。標準的な英数字テキストデータセットとは異なり、高解像度画像、生音声周波数、シーケンシャルビデオファイルは膨大な数値データを生成します。
- テキスト処理: 1ページの文章は約1,000個の濃密で意味のあるトークンになります。
- 視覚処理: 1分間の生ビデオ映像は、安定したフレームステップとピクセルブロックにカットされると、数十万のビジュアルトークンに分解されます。
単一のモデルコアがこれらのメディアタイプを一緒に処理すると、コンテキストウィンドウの密度が指数関数的に急増します。システムのAttention(注意)メカニズムは、すべてのトークンが他のすべてのトークンとどのように関連しているかを評価しなければならず、オンチップの広帯域メモリ(HBM)を圧倒し、処理層を飽和させる恐れがあります。
TPUクラスターのスケーリングによるワークロードの加速
このボトルネックに対抗するために、エンタープライズインフラストラクチャはマルチセンサリーコンピューティング専用に設計されたハードウェアプラットフォームに依存しています。Googleの最新アーキテクチャは、TPUクラスターのスケーリングを利用して、これらの集中的な統合トークンワークロードを多層データセンター環境全体に分散します。
plaintext1 ┌─────────────────────────┐ 2 │ 統合Geminiトークン │ 3 └────────────┬────────────┘ 4 │ 5 ┌───────────────────────┴───────────────────────┐ 6 ▼ ▼ 7┌─────────────────────────────────┐ ┌─────────────────────────────────┐ 8│ TensorCore配列 │ │ TensorCore配列 │ 9│ (並列行列算術演算) │ │ (並列行列算術演算) │ 10└────────────────┬────────────────┘ └────────────────┬────────────────┘ 11 │ │ 12 └───────────────┬───────────────────────┘ 13 ▼ 14 ┌─────────────────────────┐ 15 │ 光インターコネクト │ 16 │ (超低遅延ICI) │ 17 └─────────────────────────┘
Trillium TPU v6eプラットフォームのようなハードウェア設定は、古いハードウェア世代と比較してチップあたりのピークコンピューティングパフォーマンスで4.7倍という驚異的な向上を実現しています。この特殊なアーキテクチャは、最適化された行列実行ユニットと深い物理インフラストラクチャレイアウトを組み合わせることで、これらの膨大な要求を処理します。
| ハードウェアエンジンレイヤー | アーキテクチャ仕様 | コアシステム機能 |
| 拡張TensorCore配列 | 行列乗算ユニット(MXU)面積を2倍 | 密度の高いビデオテンソルに対する集中的な並列算術演算を実行。 |
| 広帯域HBM | チップあたり最大32 GB HBM | メモリボトルネックを防ぐため、膨大なトークン配列を完全にシリコン上に保持。 |
| 次世代チップ間インターコネクト | 800 GBps双方向帯域幅 | ラグなしで数万のチップ間でパラメータ変数を同期。 |
これらの深いメモリ構成とカスタム光ネットワーキングファブリックを利用することで、クラウドインフラストラクチャは数百万のトークン入力パラメータを処理するために動的にスケーリングできます。これにより、企業はメモリの停滞やシステムランタイムの障害のリスクなしに、高度なリアルタイムAIエージェントをグローバルに展開できます。
本番環境向けビデオ生成のための単一統合API
GoogleがGeminiアプリやGoogle Flow内でGemini Omni Flashを展開する一方で、同じマルチモーダルビデオエンジンを自身のワークフローに組み込みたい開発者や製品チームには、安定した予測可能なAPIレイヤーが必要です。
Atlas Cloudは、Gemini Omni Flashを統合されたOpenAI互換APIを通じて提供し、300以上の画像、ビデオ、LLMモデルと並んで利用可能です。これにより、個別のベンダーアカウント、請求ポータル、SDKを使い分けることなく、Googleのネイティブマルチモーダルモデルを統合できます。
Gemini Omni Flashの両バリエーションはAtlas Cloudで利用可能です。
| バリエーション | 最適な用途 | 入力 | 解像度 | 長さ | 開始価格 |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Developer) | プロンプト主導の映画的生成 | テキスト (最大20,000文字) | 720p / 1080p / 4K | 4, 6, 8, 10秒 | USD0.2 + USD0.1/秒 |
| Gemini Omni Flash Image-to-Video (Developer) | 実在の参照画像に基づく対象の一貫性を保ったビデオ | テキスト + 参照画像最大7枚 | 720p / 1080p / 4K | 4, 6, 8, 10秒 | USD0.2 + USD0.1/秒 |
クイックスタート — Gemini Omni Flashビデオを5行で生成:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
APIは即座に予測IDを返します。レンダリングされたMP4 URLについては、/api/v1/model/prediction/{id}をポーリングしてください。完全なスキーマ、7言語のコードサンプル、およびノーコードのプレイグラウンドは、上記のリンク先のモデルページで確認できます。
結論:統合されたマシンインテリジェンスのための将来への備え
Gemini Omniの登場は、開発者の設計パラダイムを根本的に変え、業界を個別のツールを繋ぎ合わせる段階から、統合された単一レイヤーソリューションを展開する段階へとシフトさせます。孤立したAPI間の複雑な統合ブリッジを管理する代わりに、技術者は一つの数学的屋根の下で相互依存するデータストリームを自然に処理する次世代の機械学習フレームワークに頼ることができるようになりました。
plaintext1[レガシーなソフトウェアパイプライン] 2個別のテキストAPI ──┐ 3個別の音声API ───┼──► 手動パイプラインブリッジ ──► 壊れやすい本番環境 4個別のビデオAPI ──┘ 5 6[統合されたOmniアーキテクチャ] 7ユニバーサルトークン ──► ネイティブ単一層モデル ──► シームレスな自動化
この構造的なシフトは、私たちがデジタル製品を構築する方法の完全な見直しを必要とします。競争力を維持するために、技術チームは静的なデータサイロから脱却し、標準的なソフトウェアエコシステムをネイティブなマルチセンサリーシステムに向けて準備する必要があります。
Google Cloud AIインフラストラクチャのような高度に最適化されたクラウドバックボーン上で直接運用することで、企業はシステム的なコンテキストドリフトや遅延ペナルティのリスクを冒すことなく、これらの集中的なトークンワークロードを拡張できます。究極的に、開発パイプラインの将来を保証することは、物理世界を全体論的に理解するために構築された、まとまりのある単一エンジンを中心にソリューションを設計することを意味します。






