RSpqXx0wq8Q
2026年5月19日、Google I/Oにて、DeepMindはGemini Omniを発表しました。同日、Gemini Omni プロンプトガイドがDeepMindのドキュメントサイトに公開されました。Omni FlashのモデルカードとAPIノートの間にひっそりと配置されていたため、多くの人は基調講演のデモに目を奪われ、このドキュメントはほとんど読まれることがありませんでした。
まずはクイックファクトから。Gemini OmniはDeepMindの新しいマルチモーダル生成モデルです。最初のプロダクトであるGemini Omni Flashは、テキスト、画像、音声、動画のあらゆる組み合わせから最大10秒の動画を生成します。すべての出力にはSynthID透かしが含まれます。AI Plus、AI Pro、AI Ultraのサブスクライバーは即時利用が可能となり、YouTube ShortsおよびYouTube Createアプリのユーザーも今週から順次無料で利用可能となります(Gagadget報道)。Googleによると、APIの提供は「数週間以内」とのことです。
プロンプトガイドに戻りましょう。Google DeepMindのプロンプトガイドは、「世界理解(World understanding)」のセクションで、そのアプローチの変化を端的に説明しています。
Veoでは、最良の結果を得るために正確な指示が必要でした。しかし、Gemini Omniでは、プロンプトにそこまで細かく指定する必要はありません。代わりに、作りたいものをOmniに伝えるだけで、モデルの推論能力と世界の知識が詳細に命を吹き込んでくれます。
つまり、「書く量を減らす」ということです。
この指針を、ByteDanceやKuaishouが自社の動画モデル向けに公開しているプロンプトガイドと見比べてみてください。表現は異なりますが、目指す方向は同じです。
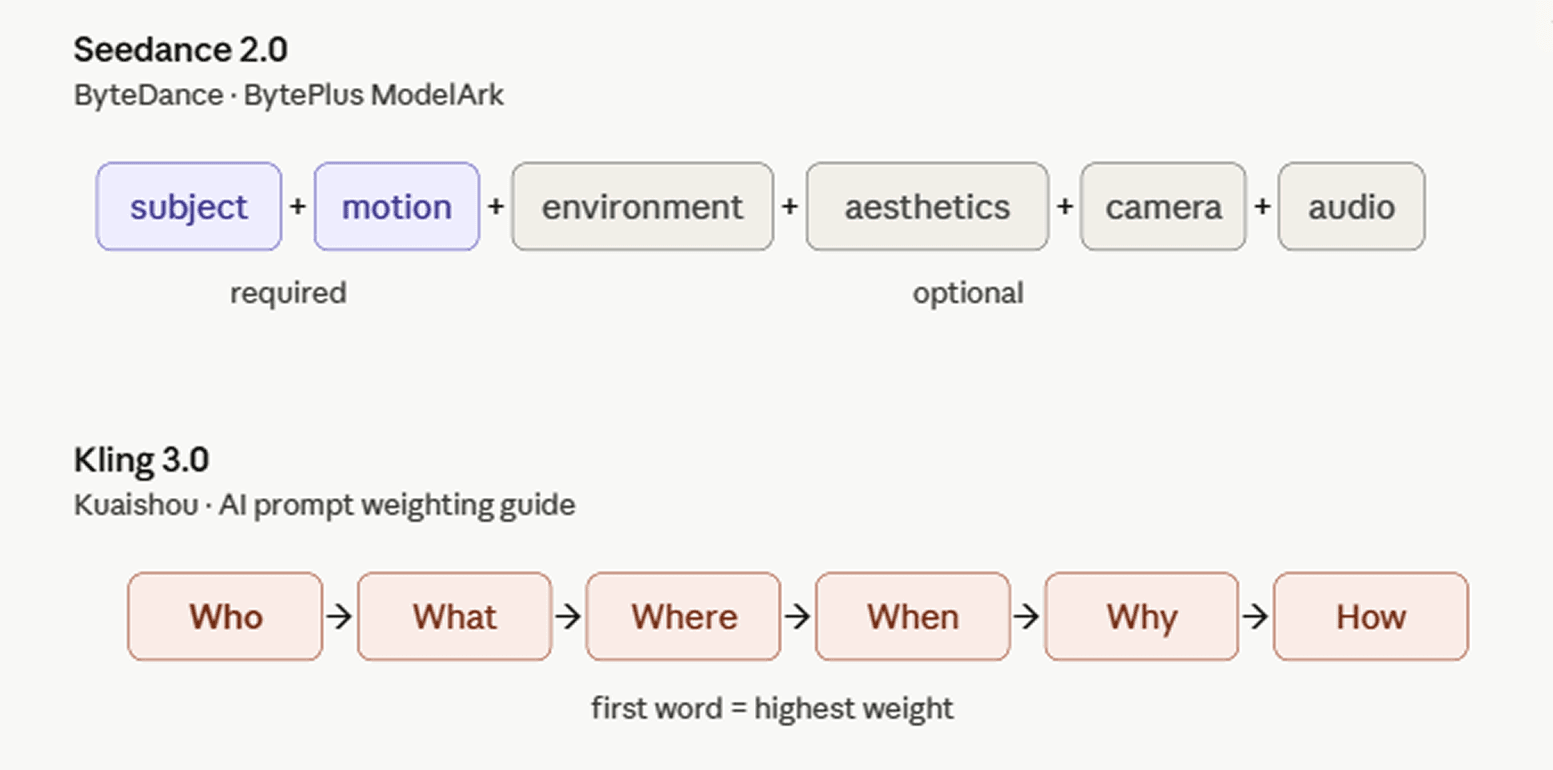
ByteDanceは、同社の国際開発者プラットフォーム上でSeedance 2.0のドキュメントを公開しており、BytePlus ModelArk プロンプトガイドにおいて推奨される構造は、被写体 + 動作 (+ 環境 + 美学 + カメラの動き/カット + 音声) となっています。すべての要素が必要なわけではなく、ショットに合うものを選べばよいという考え方です。
KuaishouのAIプロンプト重み付けガイドでは、5W1Hの公式(誰が・何を・どこで・いつ・なぜ・どのように)でフレームワークを構築しています。「誰が(Who)」――つまり被写体――は通常最も高い優先順位を持ち、プロンプトの冒頭に配置されます。Kling 3.0では単語の位置が重み付けに影響するため、最初に来る言葉が最も計算上の注目を集めるからです。画風や視点などのスタイルの選択は最後に配置するのが最適で、すでに確立されたシーンに対してフィルターをかける役割を果たします。ガイドでは、要素を無闇に積み重ねないよう警告しています。矛盾するキーワードが多すぎると品質が低下するためです。
これら3社がそれぞれ独自にこのアドバイスに辿り着いた事実は、各社のモデルがほぼ同時期に同等の能力レベルに到達したことを示唆しています。Googleは「少なく書く」ことを推奨し、ByteDanceはほとんどのコンポーネントをオプション扱いとし、Kuaishouは分量よりも語順を強調しています。細かな表現の差異はあれど、3つの研究所すべてがクリエイターに対し、より緩やかで自然なプロンプトを使うよう導いています。
では、Gemini Omniのプロンプトガイドが実際どのように機能するのかを見てみましょう。
Gemini Omniのプロンプト構造:Google DeepMindが使う5つの次元
ガイドの冒頭には、以下のような完全な例が示されています。
広角のトラッキングショットが静かな湖の上を滑るように移動し、そこには巨大で反射するクロームのような豆型の物体が浮かんでいる。ゆっくりと回転しながら、雄大な崖や、下の澄んだ紺碧の水面に一部沈んだ同様の小さな物体を反射させる。浮かぶ異常体の背後からまばゆい太陽が昇り、シーン全体が鮮やかな青と緑の色調を帯びた、爽やかで神秘的な日光に包まれる。異世界の広大さと謎を強調する荘厳で幻想的なオーケストラ演奏が、このシーンに映画のような畏敬の念を抱かせる雰囲気を添え、浮遊物体からはかすかで低いハミング音が響いている。
_SpuwEI0tIU
90語以上あります。これを分解すると、5つの次元が見えてきます。
- ショットのフレーミングと動き:広角、ミディアム、クローズアップか?カメラは滑らかに動くべきか、それとも素早く動くべきか?動詞ひとつで出力が著しく変わるため、適切な動きの感覚を追求するには何度か試行錯誤する価値があります。
- スタイル:リアルか、映画的か、幻想的か、荘厳か?この次元には細かい説明は不要です。モデルに感情的なトーンを伝えるだけで十分です。
- ライティング:光はどこから来るのか?太陽か、街灯か、オンカメラかオフスクリーンか?爽やかさ、暖かさ、幻想的な雰囲気?
- シーン:ガイドの中の「Omniはあなたの全体的な意図を汲み取るため、すべての小さな詳細を説明する必要はありません」という一文は注目に値します。これはSeedanceやKlingの公式ドキュメントの内容と合致しています。
- アクションとインタラクション:シーンの中に誰が(何が)いて、どう動き、どう相互作用するのか。
Gemini Omniの会話型編集 vs Veoのプロンプト書き換え
OmniとVeoは同等の生成品質を誇ります。しかし、本当の差は動画生成後に何ができるかという点にあります。
以前は、1つの詳細を変更するためにプロンプト全体を書き直し、再生成し、フレーム間の整合性が保たれることを祈る必要がありました。Omniは、この手順を「会話」に置き換えます。
公式ガイドにはいくつかの例があります。
小さな男の子のストップモーション風動画。最初の編集指示:「蝶をハチに変えて」。次:「そのハチを小さなホタルの群れに変えて」。1ターンごとに1つの要素が変化し、他のフレームは自動的に保持されます。
5zDLZZccPTY
カメラの扱いも同様です。バイオリニストの動画に対し、順次3つのコマンドを与えます。「バイオリニストを画像内の環境へ移動させて」「バイオリンを見えなくして」「カメラアングルをバイオリニストの肩越しに変えて」。環境の入れ替え、オブジェクトの削除、カメラの位置変更が、すべて自然言語で行われます。
jXnbo0gBMHQ
ここで注意すべき点があります。サードパーティのレビューによると、編集指示が曖昧すぎると、Omniは編集しすぎてしまい、本来維持したかった要素まで変えてしまう傾向があるようです。Googleの推奨事項は、1ターンにつき1つの変数を変更し、維持すべき要素を明示することです。
クロスモーダル同期の例はさらに興味深いものです。アパートの建物の夜景動画に対し、「音楽に合わせてアパートの明かりが点滅するように」と指示します。モデルはサウンドトラックのビートを分析し、窓の明かりをそれに同期させます。After Effectsでこれを行うには、タイムラインとメトロノーム、そしてフレームごとの手動キーフレーム設定が必要です。
93oo4Yvghl8
Gemini Omniの4つの高度な能力:世界知識、テキストレンダリング、アクションリファレンス、マルチ入力
ガイドの後半では、4つの能力について解説されています。
適用された世界知識
プロンプト例:通常のコンピューティングと量子コンピューティングの違いを説明せよ。この概念を、ミニマルなベクター形状と豊かなオーガニックテクスチャを融合させた現代的なフラットメディアスタイルで視覚化せよ。美学は、深い紺色の背景に対するネオンピンク、シアン、ライムといった高コントラストの「エレクトリック」なカラーパレットで定義される。このスタイルの特徴は、ドットシェーディングと粒状のグラデーションの使用であり、シンプルな幾何学図形にリソグラフのような手触り感を加える。鋭いエッジと柔らかく斑点状のグラデーションを組み合わせることで、遊び心のある編集的な雰囲気を実現せよ。
モデルは量子重ね合わせとは何か、そしてそれを比較ショットを通じてどう伝えるべきかをすでに知っています。ユーザーは量子力学を説明する必要はなく、視覚的なトーンを指定するだけです。
3b29A-7qHvE
これが機能するのは、Omniが最先端の推論モデル上で動作しているためです。これは生成専用の動画モデルには真似できません。Alphabet傘下の自動運転部門であるWaymoは、予測不可能な状況に対処するための「想像力」を車に与えるべく、すでに同様の世界モデルをテストしていると、Demis HassabisはI/O後のSemaforのインタビューで語っています。動画生成は、そのアーキテクチャの最も可視化された応用に過ぎません。
テキストレンダリング
プロンプト例:言葉を一つずつ、画面に順番に表示せよ。各単語は異なるアニメーションスタイルで、リズムに合わせて完璧なタイミングで表示される sizzle reel(紹介動画)。
_NV7lrxo6Ik
複雑なアクションリファレンス
プロンプト例:これまでの要素をすべて維持しつつ、スケートボードからアニメーション化されたモーションエフェクトを追加せよ。
b94aat8s22c
マルチ入力リファレンス
プロンプト例:動画の鳥たちが、画像に基づいた鳥の不完全な形を緩やかに形成し、音声に合わせて動き、飛び去る際に散らばるようにせよ。
3jdeP-az3oQ
スタイル転送
プロンプト例:動画参照に基づき、4段階のスタイルの進化を作成せよ。最初は、豊かなワックス状のテクスチャのストロークと、粗い紙を背景にした手描きのキャラクターデザインが特徴の、鮮やかなクレヨン画風から始める。次に、ざらついた紙に描かれたグラファイト鉛筆スケッチにシームレスに移行し、クロスハッチング、線の太さの変化、手描き感を強調する12fpsの「ラインボイリング」エフェクトを使用せよ。次に、ミニマルなスタジオ設定の中で、複雑な光の屈折やコースティクス模様、柔らかな内部発光を特徴とする、超リアルな3D半透明ガラススタイルに変形せよ。最後は、レトロで機械的な仕上げのために、限られた3色パレット、粒状のハーフトーンテクスチャ、意図的な版ズレを適用したリソグラフプリント風で締めくくれ。
n9TesZsfVNw
ストーリーボード参照
プロンプト:このストーリーを見せて。左上から順番にストーリーに正確に従え。全体を10秒で。シネマティック。
uT937Ptk9fg
クロスショット整合性
RSpqXx0wq8Q
Gemini Omni、ByteDance Seedance、Kuaishou Klingのプロンプトのアドバイスが収束する理由
冒頭の観察に戻りましょう。Seedance、Kling、Omniのプロンプトのアドバイスが似通っているのは、相互に模倣した結果ではありません。より妥当なのは、この世代のモデルがそれぞれ独自に同様の能力レベルに達したということです。
モデルがシーンレベルで自然言語を処理し、世界知識で詳細を補完し、ユーザーの意図を推論できるようになると、過度な指定がボトルネックとなります。構造をどれだけ残すべきかについて3社の意見は分かれていますが、「とにかく書く量を増やす」ことが答えではないという点では一致しています。
これは、大規模言語モデルと共同学習された拡散モデルの2年間の成果です。Omniはその結果を比較的完成された状態へと押し上げました。
Atlas Cloud経由でGemini Omniを呼び出す:Seedance、Kling、Veoの統合API
Gemini OmniはAtlas Cloudに導入されます。Atlas Cloudは、テキスト、画像、動画、音声にわたる300以上のAIモデルを集約しています。主要な動画モデルであるSeedance 2.0、Kling 3.0、Wan 2.7、Veoなどはすでにプラットフォーム上で動作しています。サイドバイサイドでの比較については、Atlas CloudのWan 2.7 vs Seedance 2.0 vs Kling 3.0の徹底比較をご覧ください。
1つのアカウントですべてのパイプラインを実行可能です。複数の地域プラットフォーム間で登録、支払い、APIキーの管理を行う必要はありません。Playgroundはインタラクティブなデバッグをサポートしており、OpenAI互換の統合APIで既存のワークフローにプラグインできます。
Atlas Cloudのプロンプトライブラリには、アニメ、SF、ミステリー、グルメ、Vlog形式など、20以上のカテゴリで使えるプロンプトが用意されています。各プロンプトには動画例とパラメータの注釈が付属しており、コピーして少し言葉を入れ替えるだけで実行できます。
プロダクション動画生成のための統合API
GoogleがGeminiアプリやGoogle Flow内でGemini Omni Flashをエンドユーザー向けに展開する一方で、同じマルチモーダル動画エンジンを自社のワークフローに組み込みたい開発者やプロダクトチームには、安定した予測可能なAPIレイヤーが必要です。
Atlas Cloudは、Gemini Omni FlashをOpenAI互換の統合APIを通じて提供し、他にも300以上の画像、動画、LLMモデルを利用可能です。個別のベンダーアカウント、請求ポータル、SDKを管理することなく、Googleのネイティブなマルチモーダルモデルを統合できます。
Gemini Omni Flashの2つのバリエーションがAtlas Cloudで利用可能です:
td {white-space:nowrap;border:0.5pt solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;}
| バリエーション | 最適な用途 | 入力 | 解像度 | 長さ | 開始価格 |
|---|---|---|---|---|---|
| Gemini Omni Flash Text-to-Video (Developer) | プロンプト主導のシネマティック生成 | テキスト (最大20,000文字) | 720p / 1080p / 4K | 4, 6, 8, 10秒 | $0.2 + $0.1/秒 |
| Gemini Omni Flash Image-to-Video (Developer) | リアルな参照画像による一貫した動画 | テキスト + 参照画像最大7枚 | 720p / 1080p / 4K | 4, 6, 8, 10秒 | $0.2 + $0.1/秒 |
クイックスタート — 5行でGemini Omni Flash動画を生成:
plaintext1curl -X POST https://api.atlascloud.ai/api/v1/model/generateVideo \ 2 -H "Authorization: Bearer $ATLASCLOUD_API_KEY" \ 3 -H "Content-Type: application/json" \ 4 -d '{ 5 "model": "google/gemini-omni-flash/text-to-video-developer", 6 "input": { 7 "prompt": "A misty forest at golden hour, cinematic dolly shot", 8 "resolution": "1080p", 9 "duration": 8, 10 "aspect_ratio": "16:9" 11 } 12 }'
APIは予測IDを即座に返します。/api/v1/model/prediction/{id} をポーリングしてレンダリングされたMP4 URLを取得してください。完全なスキーマ、7つのプログラミング言語によるコードサンプル、コード不要のPlaygroundが、上記のモデルリンク先に用意されています。






