AI 비디오 생성 API는 변덕스럽기로 유명하며, 그럴 만한 이유가 있습니다. 텍스트 완성 API는 문제가 생기면 즉시 400 에러를 반환하지만, 비디오 렌더링은 훨씬 복잡하고 예측 불가능합니다. 작업이 경고도 없이 GPU 대기열에서 영원히 멈춰 있거나, 요청한 클립의 절반만 반환되는 경우도 있습니다. 때로는 렌더링이 완벽하게 끝난 것 같아도 최종 비디오가 물리적으로 불가능하거나 왜곡된 상태일 때도 있습니다.
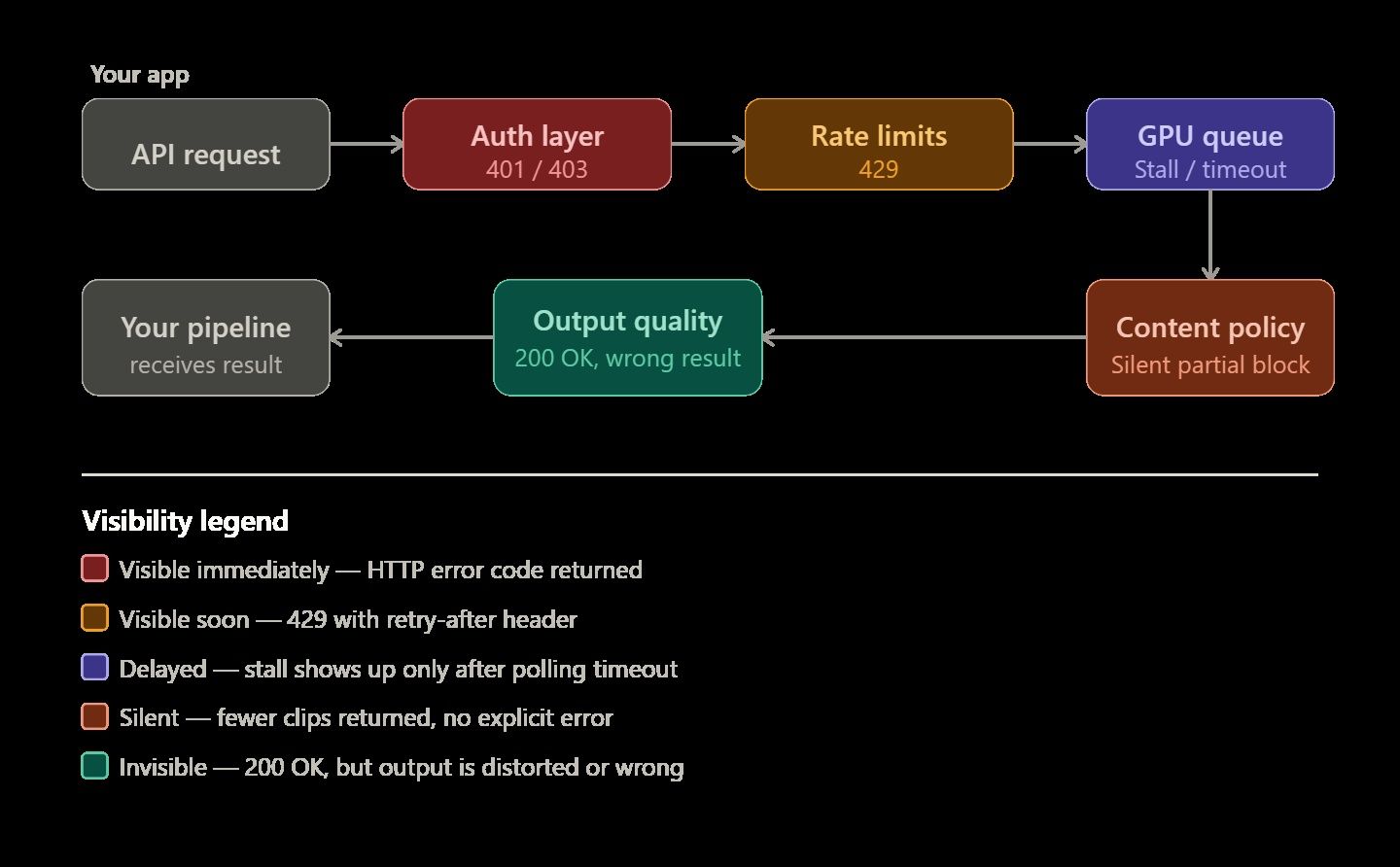
신뢰할 수 있는 시스템을 구축하려면 이러한 특정 에러가 왜 발생하는지 알아야 합니다. 이 지식이야말로 단순한 데모와 실제 사용자를 위한 비디오 파이프라인을 구분 짓는 핵심 차이입니다.
이 가이드에서는 가장 흔한 실패 유형, API 응답을 정확하게 읽는 법, 그리고 비용을 절감하면서 에러를 줄이는 비디오 렌더링 파이프라인 구축 전략을 다룹니다. 코드 예제는 단일 엔드포인트로 300개 이상의 비디오 및 멀티모달 모델에 접근할 수 있는 통합 추론 플랫폼인 Atlas Cloud API를 사용하며, 이는 멀티 모델 패턴을 익히는 데 유용한 참고 자료가 됩니다.
AI 비디오 API 에러의 5가지 범주
AI 비디오 파이프라인 에러는 보통 5가지 그룹으로 나뉩니다. 올바른 범주를 파악하면 코드 수정, 프롬프트 재작성, 또는 단순 대기 중 어떤 조치를 취해야 할지 더 빠르게 결정할 수 있습니다.
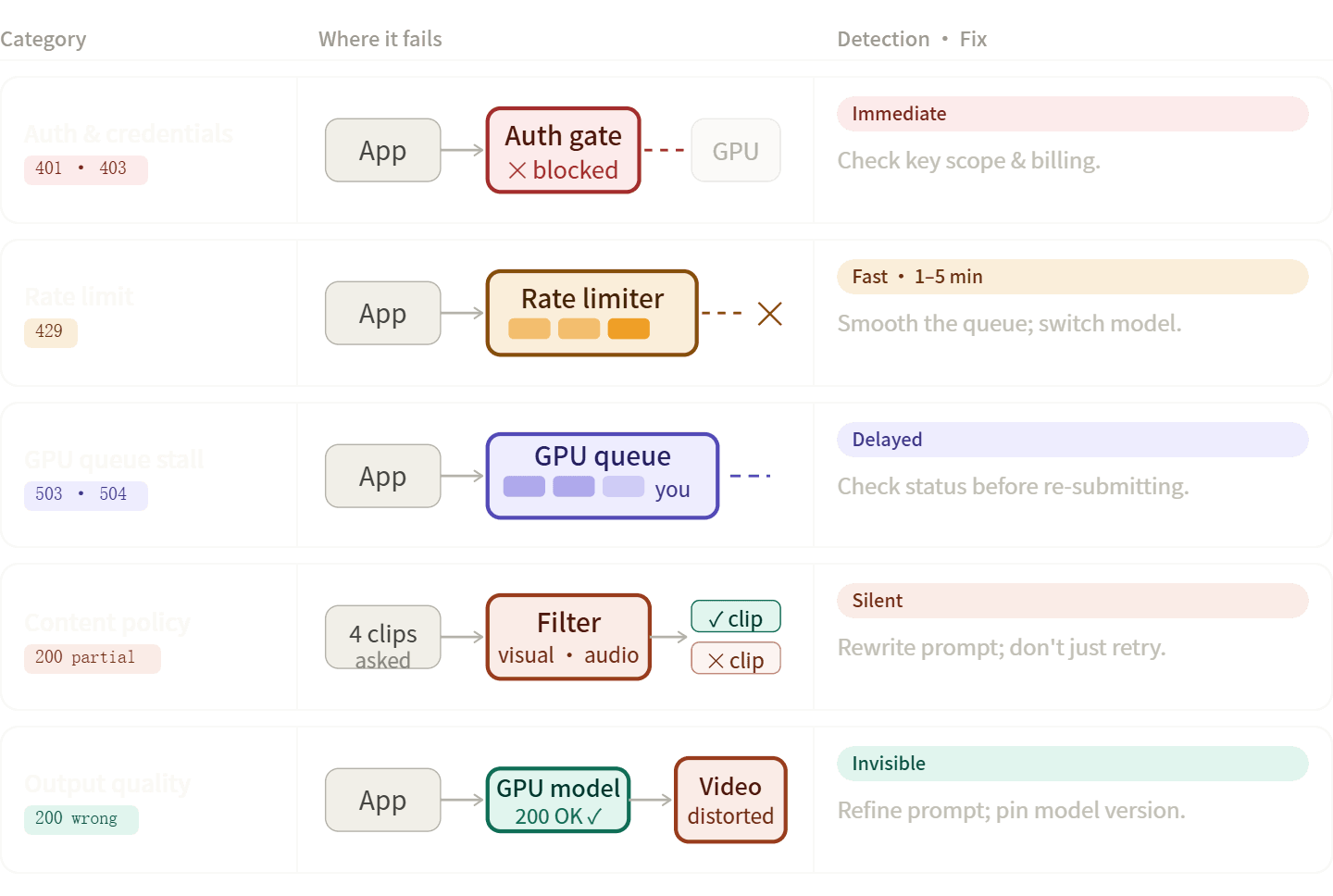
인증 및 자격 증명 에러 (401, 403)
| 구분 | 일반적인 원인 | 해결 방법 |
|---|---|---|
| 401 Unauthorized | Authorization: Bearer 헤더 누락 또는 형식 오류 | 키를 하드코딩하지 말고 환경 변수에서 불러오는지 확인 |
| 403 Forbidden (할당량) | API 크레딧 소진 | 결제 정보 추가 또는 플랜 업그레이드 |
| 403 Forbidden (권한) | 요청한 모델에 대한 키 권한 부족 | 올바른 권한으로 키를 다시 생성 |
이 부분에서 많은 혼란이 발생합니다. 할당량 초과에 의한 403과 권한 거부에 의한 403은 같은 코드이지만 해결책은 다릅니다. 상태 코드만 보지 말고, 항상 응답 본문의 전체 에러 메시지를 읽어 무엇이 잘못되었는지 확인해야 합니다.
Atlas Cloud와 같은 플랫폼은 하나의 API 키로 모든 모델을 커버하므로, A 공급업체의 키는 작동하지만 B 공급업체의 키는 만료되는 등의 '인증 드리프트(auth drift)' 현상이 발생하지 않습니다.
속도 제한 에러 (429)
비디오 API의 속도 제한은 텍스트 API보다 훨씬 엄격합니다. 각 요청이 30~90초 동안 GPU 슬롯을 점유하기 때문입니다. 소수의 동시 요청만으로도 겉보기엔 넉넉해 보이는 제한을 금방 채울 수 있습니다.
먼저 확인해야 할 주요 구분점:
- RPM (분당 요청 수): Google의 Veo 3.1 API 프로덕션 모델은 50 RPM을 허용하며, 프리뷰 모델은 프로젝트당 최대 10개의 동시 요청과 함께 10 RPM으로 제한됩니다.
- 동시 요청 제한: RPM 예산 내에 있더라도 동시성 제한을 초과하면 429 에러가 발생합니다.
- TPM (분당 토큰 수): 비디오에서는 덜 일반적이지만, 통합 빌링 플랫폼에서는 관련이 있을 수 있습니다.
실질적인 대응 전략:
| 방법 | 유효한 경우 | 유효하지 않은 경우 |
|---|---|---|
| 지수 백오프(Exponential back-off) + 재시도 | 일시적인 급증으로 인한 429 | 동시성이 실제 제한인 경우 |
| 버스트 스무딩 / 요청 대기열 | 대량 배치 파이프라인 | 대화형, 지연 시간에 민감한 UX |
| 비수기 스케줄링 (심야 배치) | 콘텐츠 사전 생성 워크플로우 | 실시간 생성 |
| 부하가 적은 모델로 경로 재지정 | 여러 동일 모델을 제공하는 통합 플랫폼 | 단일 공급업체 설정 |
콘텐츠 정책 및 안전 필터 거부
이는 진단하기 까다로울 수 있습니다. API 응답이 항상 명확한 에러가 아니라, 단순히 요청한 것보다 적은 수의 클립을 반환하는 방식으로 나타날 수 있기 때문입니다. Google의 Veo 문서는 요청한 것보다 적은 비디오가 반환될 경우, 전체 요청 실패가 아니라 안전 필터에 의해 일부 출력이 차단되었을 수 있음을 명시합니다.
두 가지 별도 트리거 영역:
- 시각적 프롬프트: 소재, 장면 문맥, 암시적 폭력성 또는 선정적인 콘텐츠.
- 오디오/대화 프롬프트: 음성 콘텐츠, 노래 요청, 밀도 높은 사운드스케이프는 별도의 필터 스택을 트리거합니다.
프롬프트에 오디오를 포함했을 때만 클립 생성에 실패한다면 오디오를 시각적 장면과 분리하여 디버깅하세요. 정책에 의해 차단된 프롬프트를 재시도하는 것은 거의 효과가 없으며, 프롬프트 자체를 수정해야 합니다.
전송 및 인프라 에러 (500, 503, 504)
| 코드 | 일반적인 해결 시간 | 조치 방법 |
|---|---|---|
| 429 RESOURCE_EXHAUSTED | 1~5분 | 백오프 및 재시도 |
| 503 Service Unavailable | 30~120분 | 대기 및 상태 대시보드 확인 |
| 504 Gateway Timeout | 가변적 | 재제출 전 렌더링 진행 여부 확인 |
| 500 Internal Server Error | 상황에 따라 다름 | 예측 ID 기록; 상태 확인 없이 자동 재시도 금지 |
500/504 에러의 핵심 규칙: 재제출 전 렌더링이 여전히 처리 중인지 확인하세요. 504 에러에 대해 무조건 재시도를 하면 중복 렌더링이 발생하여 비용이 두 배로 청구될 수 있습니다.
출력 품질 문제
이는 HTTP 에러가 아닙니다. API는 200을 반환하지만 결과물이 잘못된 경우입니다. 일반적인 형태는 다음과 같습니다.
- 시각적 아티팩트 또는 기하학적 부정확성: AI 비디오는 물리적으로 계산하는 것이 아니라 확률적으로 해석합니다.
- 오디오 지원 모델의 오디오 누락: 보통 인프라 실패가 아니라 프롬프트나 매개변수 문제입니다.
- 잘못된 지속 시간 또는 해상도: 모든 모델이 모든 조합을 지원하지 않기 때문에 발생합니다.
- 조용한 파이프라인 드롭: 특정 인코딩 파이프라인에서 형식에 맞지 않는 비디오를 조용히 삭제하여 QA 단계에서만 발견되는 경우입니다.
비동기 응답 읽기: 예측 ID 및 상태 폴링
AI 비디오 생성은 기본적으로 비동기 방식입니다. 요청-응답 주기는 두 단계로 나뉩니다.
- POST 생성 엔드포인트 →
prediction_id수신 - GET 결과 엔드포인트에 해당 ID로 요청 → 완료 상태가 될 때까지 폴링
Atlas Cloud의 응답 스키마는 완료된 예측이 어떤 모습인지 보여줍니다.
plaintext1{ 2 "id": "pred_abc123", 3 "status": "completed", 4 "model": "bytedance/seedance-2.0/text-to-video", 5 "outputs": ["https://storage.atlascloud.ai/outputs/result.mp4"], 6 "metrics": { "predict_time": 45.2 }, 7 "created_at": "2025-01-01T00:00:00Z", 8 "completed_at": "2025-01-01T00:00:45Z" 9}
세 가지 최종 상태:
| 상태 | 의미 | 조치 |
|---|---|---|
| completed | 렌더링 성공; 출력물 확인 가능 | 만료 기간 내에 다운로드 |
| failed | 렌더링 실패; 에러 필드 확인 | 에러 메시지 기록; 재시도 여부 결정 |
| expired | 출력물 확인 불가 | 필요 시 재제출 |
가장 흔한 폴링 실수
개발자들은 습관적으로 상태가 failed인지만 확인하고 그 뒤에 따라오는 error 필드를 읽지 않습니다. 이 필드에 실질적인 정보가 담겨 있습니다. 이 정보가 없으면 렌더링이 실패했다는 사실만 알 뿐, 프롬프트를 수정해야 할지, 할당량을 확인해야 할지, 아니면 인프라 문제를 기다려야 할지 알 수 없습니다.
프로덕션 환경용 폴링 패턴
plaintext1import time 2import requests 3 4def poll_prediction(prediction_id: str, api_key: str, max_wait: int = 600) -> dict: 5 url = f"https://api.atlascloud.ai/api/v1/model/prediction/{prediction_id}" 6 headers = {"Authorization": f"Bearer {api_key}"} 7 terminal_states = {"completed", "failed", "expired"} 8 wait = 5 9 10 for _ in range(max_wait // wait): 11 resp = requests.get(url, headers=headers).json() 12 status = resp.get("status") 13 14 if status in terminal_states: 15 if status == "failed": 16 print(f"Render failed: {resp.get('error')}") 17 return resp 18 19 time.sleep(wait) 20 wait = min(wait * 1.5, 60) # 백오프 최대 60초 21 22 raise TimeoutError(f"Prediction {prediction_id} did not complete within {max_wait}s")
모든 완료된 렌더링에 대해 metrics.predict_time을 기록하세요. 이 값이 급증하는 것은 인프라 저하의 선행 지표이므로, 완전한 장애가 발생하기 전에 미리 감지할 수 있습니다.
복원력 있는 렌더링 파이프라인 구조화
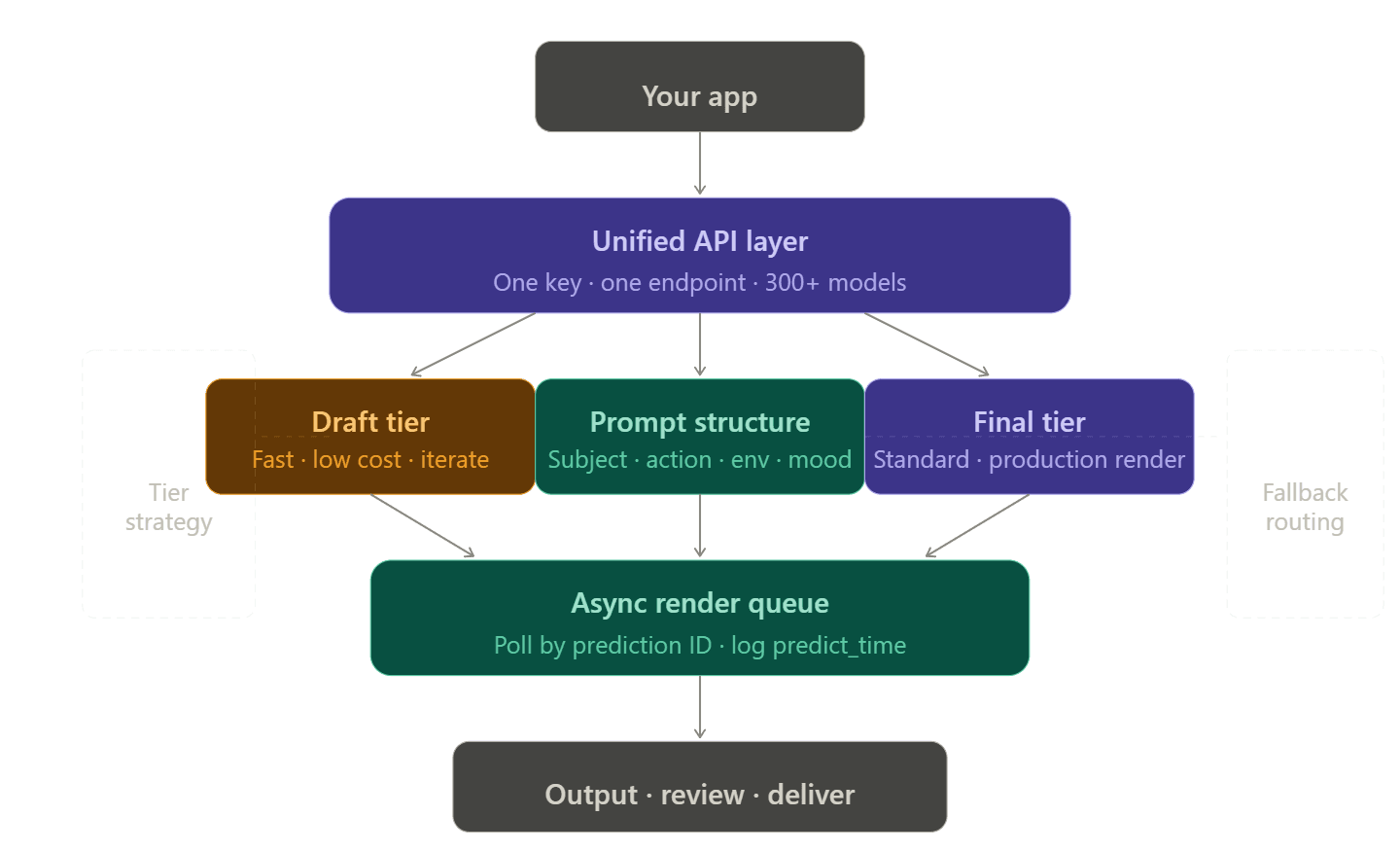
단일 공급업체 vs. 통합 API 아키텍처
모든 비디오 제공업체마다 여러 계정, 토큰, 결제 페이지를 관리하는 것은 매우 번거롭습니다. 개발자들은 이를 '통합 세(integration tax)'라고 부릅니다. 특정 모델이 제한에 도달하면 백업 모델이 필요하고, 그 백업 모델에도 자체 API 키와 빌링 설정, 에러 처리 코드가 필요하게 됩니다.
통합 API 플랫폼은 여러 공급업체를 단일 엔드포인트로 라우팅하여 이를 제거합니다. Atlas Cloud에서는 openai/sora-2/text-to-video에서 bytedance/seedance-2.0/text-to-video로 전환할 때 문자열 하나만 바꾸면 되며, 헤더, 인증, 빌링은 동일하게 유지됩니다.
단계별 렌더링 (초안-최종)
비용과 신뢰성을 향상하는 가장 좋은 방법은 워크플로우 단계에 맞는 올바른 모델 등급을 선택하는 것입니다.
| 단계 | 권장 등급 | 이유 |
|---|---|---|
| 프롬프트 탐색 / 컨셉 테스트 | Fast / 저가형 | 표준 모델 대비 78% 이상 비용 절감; 에러 조기 발견 |
| 내부 검토용 초안 | Fast 등급 | 이해관계자 검토용으로 충분 |
| 최종 프로덕션 렌더링 | Standard / Pro 등급 | 품질 차이가 비용을 정당화 |
| 배치 콘텐츠 (SNS, 마케팅) | Fast 등급 | 물량이 많아 비용 차이가 큼 |
Atlas Cloud에서 Seedance 2.0의 Fast 등급은 초당 $0.081로 Standard($0.10/sec)보다 저렴하며, 대규모 작업 시 상당한 비용 절감 효과가 있습니다. 매달 10초짜리 클립 200개를 생성한다면, 같은 프롬프트 세트에 대해 Fast 등급을 사용할 경우 $162, Standard는 $200가 소요됩니다.
에러 방지를 위한 프롬프트 엔지니어링
모호한 프롬프트는 파이프라인 실패의 주요 원인입니다. "걷고 있는 사람"과 같은 프롬프트는 모델이 너무 많은 자의적인 선택을 하게 만들어 일관성 없는 출력을 생성하고 재시도를 유발합니다.
안정적인 4가지 요소 프롬프트 구조:
plaintext1[주제 + 세부 사항] + [행동 + 움직임 스타일] + [환경 + 조명] + [카메라 + 분위기] 2 3예시: 4"빨간 코트를 입고 밤에 비에 젖은 도쿄 거리를 빠르게 걷는 여성, 5젖은 보도에 비친 네온사인, 중간 트래킹 샷, 영화적이고 긴장감 넘치는 분위기"
멀티모달 입력을 지원하는 모델(Seedance 2.0은 이미지, 비디오, 오디오 등 최대 12개의 참조 파일 수용)을 사용할 경우, 시각적 참조를 제공하면 모호함이 줄어들어 품질 관련 실패를 최소화할 수 있습니다.
올바른 모델 선택하기
모든 AI 비디오 도구가 같은 이유로 실패하는 것은 아닙니다. 각기 다른 목적을 위해 만들어졌기 때문입니다. 특정 작업에 맞지 않는 모델을 사용하는 것은 기술적 버그처럼 보이지만 실제로는 모델이 그 일을 하도록 설계되지 않은 것일 수 있습니다.
모델 성능 참조
| 모델 | 강점 | 주의사항 | 가격 (Atlas Cloud) |
|---|---|---|---|
| wan 2.7 | 물리 시뮬레이션, 사실적인 객체 상호작용 | 단일 이미지 참조만 가능; 높은 비용 | $0.1/sec |
| Kling 3.0 | 고해상도 출력; 네이티브 립싱크; 무료 등급(매일 66 크레딧) | 최대 해상도에서 긴 생성 시간 | $0.071~0.143/sec |
| Veo 3.1 | 영화 같은 품질; 강력한 안전 준수 | 프리뷰 모델 속도 제한 (10 RPM) | $0.05~0.20/sec |
| Seedance 2.0 | 다중 참조 입력 제어; 네이티브 오디오 | 더 세심한 프롬프트 작성 필요 | $0.081~0.10/sec |
| Wan 2.6 | 최저 비용; 대량 콘텐츠 | 네이티브 오디오 없음; 최대 1080p | $0.018~0.07/sec |
가격은 2026년 4월 기준 Atlas Cloud 문서를 참고했습니다. 특정 가격은 공식 웹사이트를 확인하세요.
모델을 교체해야 할 때 vs. 프롬프트를 수정해야 할 때
다음 경우 모델을 교체하세요:
- 프롬프트에 오디오나 대화가 포함될 때만 클립이 지속적으로 실패하는 경우 (모델이 오디오 기능을 지원하지 않을 수 있음)
- 프롬프트 문제가 아니라 물리 법칙이나 객체 상호작용 품질이 문제인 경우
- 프리뷰 모델을 사용하여 프로덕션 모델로는 겪지 않을 속도 제한에 도달한 경우
다음 경우 프롬프트를 수정하세요:
- 스타일은 어긋나지만 구조적으로는 정확한 경우
- 특정 언어에서 안전 필터가 작동하는 경우
- 지속 시간이나 해상도 매개변수가 거부되는 경우
특정 버전 문자열을 고정하세요 (예: kling-latest 대신 kling-v3.0-std 사용). 무음 업데이트(silent updates)는 품질 저하를 유발할 수 있으며, 버전을 고정하지 않으면 디버깅이 거의 불가능합니다.
디버깅 툴킷
모든 단계에서 기록해야 할 로그
로깅은 디버깅 시간을 절반으로 단축하는 가장 빠른 방법입니다. 최소한으로 기록해야 할 항목은 다음과 같습니다.
요청 시:
- 모델 ID 및 버전
- 전체 프롬프트가 아닌 프롬프트 해시 (로그 용량 유지)
- 지속 시간, 해상도 및 모드 매개변수
- 타임스탬프
응답 시:
- 예측 ID
- 초기 상태
- 즉각적인 에러 메시지
폴링 완료 시:
- 최종 상태
- 메트릭의
predict_time - 에러 필드 내용 (실패 시)
- 출력 URL (완료 시)
인프라 에러와 애플리케이션 에러 구별하기
생성 실패 시 다음 진단 순서를 따르면 시간을 절약할 수 있습니다.
- API 상태 대시보드 먼저 확인 — 플랫폼 자체가 저하된 상태라면 엉뚱한 곳을 디버깅하는 것입니다.
x-deny-reason응답 헤더 확인 — 이 헤더가 없으면 프록시 거부가 모델 에러로 오인될 수 있습니다.- CORS 에러 확인 — 프론트엔드에서 호출하는 경우, 브라우저 개발자 도구에서 인증 실패와 같은 증상을 보입니다.
- 파일 제한 확인 — 대부분의 플랫폼은 최대 입력 파일 크기(보통 16MB)와 제한된 파일 형식만 허용합니다.
Atlas Cloud의 모니터링 패널은 자동 확장 상태와 요청별 사용 데이터를 표시하여 인프라 문제와 프롬프트/코드 문제를 구별하는 데 도움을 줍니다.
비용 최적화
세 가지 레버
렌더링 비용은 세 가지 변수의 곱입니다. 단순히 저렴한 모델을 선택하는 것이 아니라, 다음 세 가지를 동시에 최적화해야 가장 큰 비용 절감 효과를 얻을 수 있습니다.
| 레버 | 저비용 선택 | 고비용 선택 | 일반적인 배수 |
|---|---|---|---|
| 모델 등급 | Fast | Standard/Pro | 3~5배 |
| 지속 시간 | 4~5초 | 12~15초 | 3배 |
| 해상도 | 720p | 4K | 2~4배 |
8초짜리 4K Standard 렌더링은 같은 시간의 Fast 720p 렌더링보다 6~8배 더 비쌀 수 있습니다. 배포 채널이 SNS나 웹이라면 720p나 1080p는 사용자 입장에서 큰 차이가 없습니다.
사용량 기반 빌링 vs. 구독 빌링
Google AI Pro($19.99/월)나 AI Ultra($249.99/월) 같은 일반 소비자용 AI 플랜은 인터페이스를 통해 제한된 비디오 생성을 제공하지만 API 접근은 포함하지 않습니다. 이는 일반 소비자용 도구에서 프로덕션 파이프라인으로 전환하는 팀들이 자주 하는 예산 계획 실수입니다.
Atlas Cloud는 실제 구축한 만큼만 비용을 지불하는 사용량 기반 빌링을 사용합니다. 이는 프로젝트 요구 사항이 주 단위로 변할 때 가장 효과적입니다. 완성된 비디오의 초당 비용을 추적하세요. 이는 다양한 모델과 가격 등급을 공정하게 비교하는 최고의 방법입니다.
참조 에셋 재사용
같은 캐릭터, 장면, 스타일 참조를 반복적으로 사용하는 클립을 생성한다면 에셋을 사전 등록하세요.
- 참조 이미지나 비디오를 한 번 업로드하고 반환된 에셋 ID를 저장합니다.
- 이후 요청에서는 재업로드하는 대신
asset://<ark_asset_id>를 사용합니다. - 대부분의 플랫폼에서 참조 파일 업로드는 과금되지 않으며, 생성된 출력물의 지속 시간에 대해서만 비용이 발생합니다.
프로덕션 준비 체크리스트
비디오 생성 파이프라인을 배포하기 전에 다음을 확인하세요.
인증
- API 키가 하드코딩되지 않고 환경 변수에서 로드됨
- 모든 사용 중인 모델에 대해 올바른 범위(scope)를 가진 키 사용
- 키 순환 정책 적용
속도 제한 및 동시성
- 각 모델 등급에 대한 RPM 및 동시 요청 제한 확인
- 배치 워크플로우를 위한 버스트 스무딩 또는 대기열 적용
- 속도 제한 상황을 위한 폴백(fallback) 모델 구성
에러 처리
- 모든 최종 상태(completed, failed, expired) 처리 완료
- 실패 상태 발생 시
error필드 캡처 및 기록 - 긴 렌더링을 위해 서브프로세스/요청 타임아웃을 10분 이상으로 설정
- 상태 확인 없이 500/504 에러에 대해 무조건 재시도하지 않도록 설정
콘텐츠 및 프롬프트
- 플랫폼 콘텐츠 가이드라인에 따라 프롬프트 사전 검토
- 테스트 시 오디오 및 시각적 트리거 분리
- 4가지 요소 프롬프트 구조를 팀 표준으로 채택
모델 구성
- 특정 버전 문자열 고정 (latest 제외)
- 워크플로우 단계와 모델 등급 매칭 (초안은 Fast, 최종은 Standard)
- 모델별 필수 매개변수 확인 (지속 시간, 해상도, 오디오)
비용 제어
- 사용량 기반 빌링 대시보드 알림 설정
- 최종 결과물을 제외한 모든 렌더링에 Fast 등급 기본값 적용
- 반복 사용되는 에셋에 참조 에셋 ID 사용
관측성(Observability)
- 모든 렌더링에 대해 예측 ID, 상태,
predict_time기록 - 디버깅 전 API 상태 대시보드 확인
-
predict_time급증 시 알림 구성
에러를 처리하는 비디오 파이프라인은 그렇지 않은 파이프라인보다 구축하기 훨씬 어렵지 않습니다. 각 단계에서 실패를 어떻게 다룰지 현명하게 결정하기만 하면 됩니다. 로그를 확실히 남기고 특정 모델 버전을 고수하세요. 다른 것을 걱정하기 전에, 빠른 초안에서 최종 결과물까지 이어지는 파이프라인을 먼저 설정하세요. 나머지는 자연스럽게 해결될 것입니다.
자주 묻는 질문(FAQ)
프리미엄 플랜에서 발생하는 429 Resource Exhausted 에러의 원인은 무엇인가요?
429 에러는 속도 제한에 도달했다는 의미입니다. 시스템이 원활하게 유지되도록 공급업체는 요청 수와 토큰 수를 제한합니다.
- 해결 방법: 코드에 **지수 백오프(exponential backoff)**를 추가하세요. 시스템이 스스로 대기하고 재시도하도록 돕습니다. 대시보드에서 "사용량 등급(Usage Tier)"도 확인하세요. 더 빠른 속도를 해제하려면 비용을 더 지불해야 합니다.
"콘텐츠 검토" 오탐(false positives)을 방지하려면 어떻게 해야 하나요?
안전 필터는 기술적인 프롬프트를 정책 위반으로 오인하는 경우가 많습니다.
- 해결 방법: 모호한 단어를 기술적인 단어로 바꾸어 프롬프트를 수정하세요. "혼란스러운 에너지(chaotic energy)" 대신 "고속 카메라 움직임(high-speed camera movement)"이라고 표현하세요. LLM을 사용하여 프롬프트를 정리할 수도 있습니다. 기계가 이해할 수 있는 명확한 설명으로 변환하면 실수를 줄일 수 있습니다.
렌더링 파이프라인의 지연 시간을 줄이려면 어떻게 해야 하나요?
지연 시간은 보통 잘못된 폴링 방식이나 대형 모델 크기로 인해 발생합니다. 수동 폴링 대신 **웹훅(Webhooks)**을 사용하여 완료 데이터를 수신하세요. 직접 호스팅하는 경우 **FP8 양자화(Quantization)**를 적용하여 추론 속도를 높이세요. API 사용자라면 순차적인 처리가 아닌 **비동기 처리(Asynchronous Processing)**로 전환하여 여러 생성을 병렬로 처리하세요.






