
Grok Imagine Video Generation은 xAI의 최첨단 멀티모달 AI 비디오 시스템으로, 단일 API 호출만으로 크리에이터들이 기대할 수 있는 수준을 재정의했습니다. xAI Aurora 엔진을 기반으로 구축된 이 모델은 자기회귀(autoregressive) 혼합 전문가(MoE, Mixture-of-Experts) 네트워크를 사용합니다. 텍스트, 이미지, 비디오, 오디오 토큰을 통합 처리하는 이 접근 방식은 Sora나 Veo와 같은 시스템에서 사용되는 디퓨전 트랜스포머(diffusion-transformer) 방식을 완전히 대체합니다.
가장 큰 장점은 단일 생성 단계에서 자연스러운 오디오 및 비디오 싱크가 이루어진다는 점입니다. 이후 별도의 더빙 도구가 필요하지 않습니다.
한눈에 보는 핵심 사양
| 항목 | 상세 |
| 길이 | 1–15초 |
| 프레임 속도 | 24 FPS |
| 해상도 | 480p / 720p |
| 오디오 | 네이티브 립싱크, SFX, 대사, 배경 음악 |
| 리더보드 | Artificial Analysis Video Arena 1위 (Elo 1404 ±6) |
2026년 5월 말 출시된 Grok Imagine Video Generation은 Artificial Analysis Video Arena의 이미지-비디오(Image-to-Video) 리더보드에 1위로 데뷔하며 ByteDance의 Seedance 2.0을 밀어냈습니다. 사운드가 내장된 빠르고 완성도 높은 비디오를 요구하는 현대의 디지털 워크플로우에서, 이 모델은 반드시 넘어야 할 벤치마크가 되었습니다.
xAI Grok Imagine Video Generation 아키텍처 이해하기
Grok의 기능을 온전히 활용하려면 먼저 내부 구조를 살펴봐야 합니다. 사운드와 영상을 나중에 결합하는 기존 비디오 모델과 달리, Grok은 이를 하나의 개체로 취급합니다. 이러한 핵심 변화를 이해하면 시장의 다른 대안들과 비교해 프롬프트 반응성과 렌더링 속도가 왜 그렇게 크게 다른지 알 수 있습니다.
Grok Imagine은 무엇이며 어떻게 작동하는가?
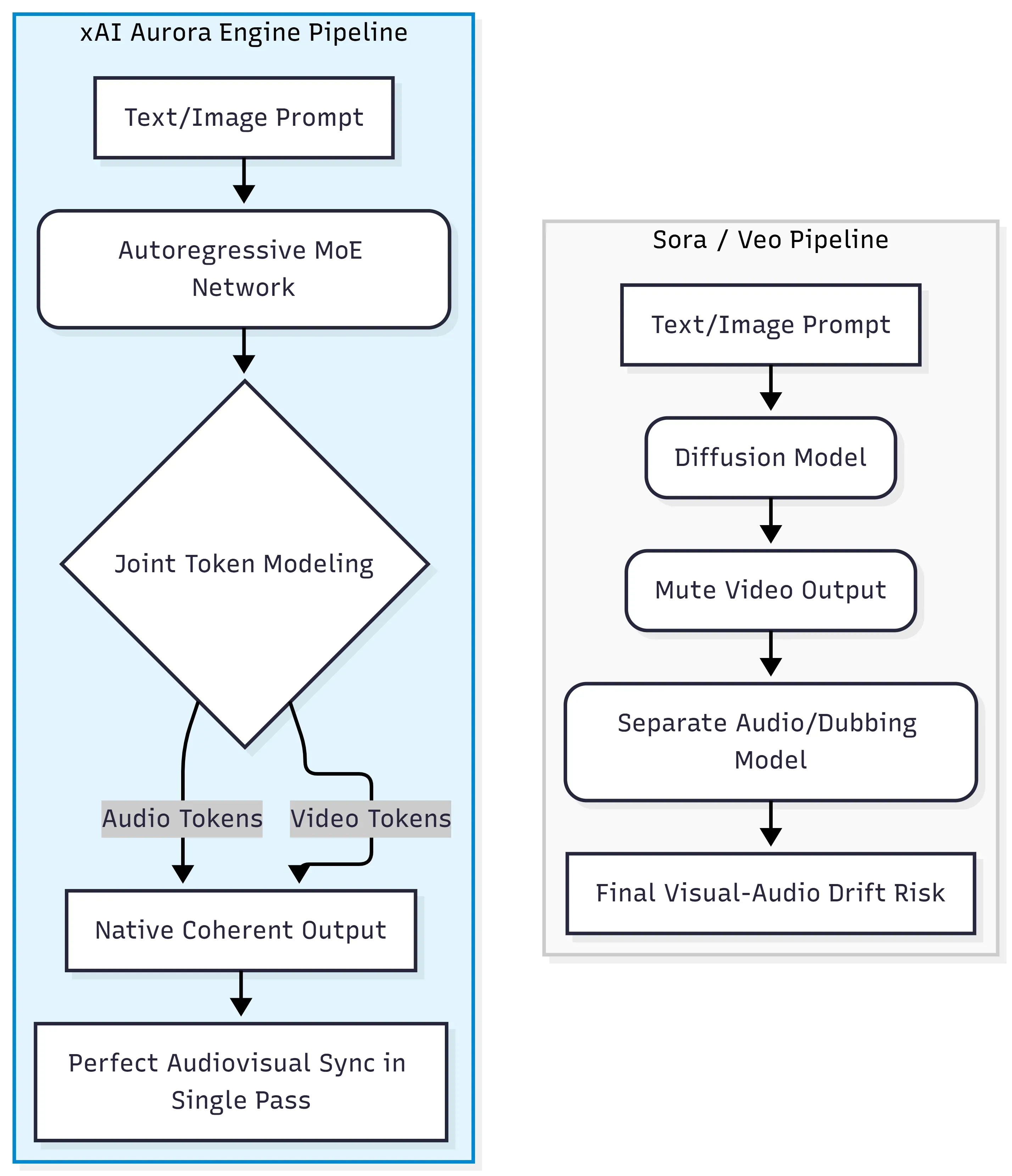
Grok Imagine Video Generation의 핵심은 xAI Aurora 엔진입니다. 이는 텍스트, 이미지, 비디오, 오디오 데이터의 통합 스트림 전반에서 다음 토큰을 예측하는 **자기회귀 혼합 전문가(MoE 네트워크)**입니다. 이는 OpenAI의 Sora나 Google의 Veo가 사용하는 디퓨전 트랜스포머 패러다임과는 아키텍처적으로 구별되며, 후자의 경우 비디오와 오디오가 일반적으로 별도의 단계에서 생성되거나 정렬됩니다.
디퓨전 트랜스포머에서 벗어난 변화
전통적인 디퓨전 모델은 무작위 노이즈를 점진적으로 제거하여 일관된 프레임을 만드는 방식으로 작동합니다. 시각적 품질은 뛰어나지만 오디오는 부차적으로 취급하여, 사운드를 추가하려면 외부 도구나 후반 작업 파이프라인이 필요합니다. Aurora는 완전히 다른 길을 택했습니다.
| 접근 방식 | 아키텍처 | 오디오 방식 |
| Sora / Veo | 디퓨전 트랜스포머 | 후반 작업 / 별도 모델 |
| Grok Imagine Video | 자기회귀 MoE | 네이티브 단일 패스 생성 |
인터리브 멀티모달 토큰 처리
Aurora는 모달리티를 순차적으로 처리하는 대신 인터리브(interleaved) 멀티모달 데이터를 처리합니다. 즉, 시청각 토큰(대사, 효과음, 배경 음악)이 동일한 포워드 패스 내에서 비디오 프레임과 함께 생성됩니다. 이러한 공동 토큰 모델링 덕분에 별도의 정렬 시스템 없이도 모델 자체에서 립싱크와 이벤트에 맞는 사운드 효과가 생성됩니다.
Aurora의 단일 패스 실행을 보여주는 프로덕션 샘플로, 엔진의 가속도와 타이어 마찰 물리에 맞춰 엔진 굉음의 음향 주파수가 완벽하게 동기화됩니다.
대규모 학습: Colossus
이 모델은 xAI의 Colossus 슈퍼컴퓨터에서 훈련되었습니다. 이 거대한 시설은 약 555,000개의 NVIDIA GPU를 사용하며 약 2기가와트의 전력을 소비합니다. 이는 세계 최대 규모의 단일 사이트 AI 학습 클러스터입니다. 이러한 방대한 설정이 품질 저하 없이 네 가지 미디어 유형을 결합하는 Aurora의 비결입니다.
핵심 기능: 이미지-비디오 변환, 포맷 설정 및 품질 모드
Grok은 텍스트-비디오 생성을 지원하지만, 진정한 기업용 활용 가치는 이미지-비디오(I2V) 워크플로우에서 빛을 발합니다. 정적 참조 이미지를 모델에 입력함으로써 캐릭터의 특징을 즉시 고정할 수 있으며, 복잡한 묘사 대신 정밀한 기계적 제어를 통해 작업을 수행할 수 있습니다. 스타일 모드를 살펴보기 전에 핵심 파이프라인 제약 조건을 구성해야 합니다.
Grok Imagine의 비디오 제한, 화면 비율 및 해상도는?
이미지를 비디오로 바꾸는 것은 Grok Imagine의 가장 유용한 기능 중 하나입니다. 정지 사진을 업로드하고 움직임을 설명하는 간단한 프롬프트만 입력하면 됩니다. 그러면 모델이 이미지를 애니메이션화하고 동시에 일치하는 오디오를 추가합니다. 길이, 프레임 속도, 해상도, 형태라는 네 가지 설정을 사용하여 최종 포맷을 완벽하게 제어할 수 있습니다.
길이 및 프레임 속도
세밀한 길이 제어를 통해 1에서 15초 사이의 정수 초를 요청할 수 있습니다. 이는 이전의 10초 제한을 50% 확장한 것이며, 더 긴 윈도우에서도 시간적 일관성을 유지합니다. 모든 출력은 24 FPS를 기준으로 렌더링됩니다.
해상도 옵션
| 해상도 | 품질 | 처리 속도 |
| 480p | 표준 정의 | 빠름 (기본값) |
| 720p | HD (720p 해상도) | 느림 |
최종 결과물이나 소셜 미디어 배포용으로는 720p가 실용적입니다. 빠른 반복 작업 및 프롬프트 테스트에는 480p를 사용하세요.
화면 비율 변형
7가지의 화면 비율 변형을 지원합니다:
| 비율 | 최적 사용 사례 |
| 16:09 | 와이드스크린 / YouTube (기본값) |
| 9:16 | TikTok / Instagram 릴스 / 스토리 |
| 1:01 | 소셜 썸네일 |
| 4:3 / 3:4 | 프레젠테이션 / 인물 사진 |
| 3:2 / 2:3 | 사진 포맷 |
이미지-비디오 생성의 경우, 별도로 지정하지 않으면 입력 이미지의 원본 화면 비율이 기본값으로 사용됩니다.
시네마틱 모션과 제로샷 정체성 유지를 위한 프롬프트 가이드라인
xAI Aurora 엔진은 공동 토큰 모델링에 의존하므로 프롬프트 전략을 수정해야 합니다. 더 이상 캐릭터의 외형을 묘사하는 데 토큰을 낭비할 필요가 없습니다. 입력 이미지가 제로샷 정체성 보존을 통해 이를 처리하기 때문입니다. 대신, 프롬프트는 방향성 있는 모션, 카메라 동작, 그리고 엔진이 함께 생성해야 할 음향 환경에 집중해야 합니다.
Grok Imagine Video에서 최상의 결과를 얻는 프롬프트 작성법
가장 중요한 원칙: Grok Imagine은 제로샷 정체성 보존을 지원하므로 모델이 입력 이미지에서 피사체의 외형을 직접 가져옵니다. 머리 색깔, 의상, 얼굴 특징을 다시 묘사할 필요가 없습니다. 모든 단어를 모션 다이내믹스, 환경, 카메라 방향에 투자하세요.
최적의 프롬프트 구문
이 최적화된 토큰 블록들을 조합하여 고도로 제어된 시네마틱 환경을 구축하세요:
| 액션 & 모션 | 카메라 다이내믹스 | 음향 & 환경 |
| ...코트를 휘날리며 자신 있게 앞으로 전진 | 달리 줌이 천천히 뒤로 당겨짐 | ...젖은 바닥에 반사되는 네온 불빛. SFX: 아스팔트에 떨어지는 빗소리 |
| ...뒤를 돌아보며 군중 속을 질주 | 로우 앵글 트래킹 샷, 빠른 페이싱 | ...깜빡이는 형광등 아래. SFX: 웅성거리는 군중 소리와 가쁜 숨소리 |
| ...천천히 몸을 돌려 눈을 뜸 | 왼쪽에서 오른쪽으로 매크로 팬 트래킹 | ...얕은 피사계 심도, 떠다니는 먼지. SFX: 웅장한 시네마틱 베이스 드롭 |
시나리오 A: 사이버펑크 추격 시퀀스 (고동적, 강력한 오디오 싱크)
프롬프트:
액션 & 피사체: 남자가 네온사인 아래 젖은 골목길을 빠르게 달린다.
카메라 다이내믹스: 카메라는 낮은 위치에서 그를 밀착 추격한다. 배경은 빠르게 지나가고 밝은 빛이 화면을 가로지른다.
SFX: 빠른 전자 음악이 웅덩이를 밟는 소리, 멀리서 들리는 사이렌과 섞인다. 비트가 깜빡이는 네온 불빛에 완벽하게 일치한다.
테스트 목표: Aurora 엔진이 빠른 움직임 속에서 형태를 얼마나 잘 처리하는지 확인합니다. 또한 엔진이 시각적 요소(깜빡이는 네온)와 사운드(신스 비트)를 얼마나 완벽하게 동기화하는지 평가합니다.
성공 요인 (Grok의 강점):
- 제로샷 정체성 유지: 정적 시드 이미지로부터의 전환이 완벽합니다. 트렌치코트의 가죽 질감과 캐릭터의 헝클어진 어두운 머리카락이 인물 변형 없이 안정적으로 유지됩니다.
- 물리적 일관성: Grok은 빠른 속도의 질주 상황에서도 팔다리 중복이나 의상 클리핑 없이 처리해냅니다. 이는 디퓨전 모델의 고질적인 실패 지점입니다.
- 동적 조명 물리: 젖은 바닥에 비친 분홍색과 파란색 네온 반사가 카메라의 전진 트래킹 각도에 맞춰 정확하게 이동합니다.
한계 요인 (병목 현상):
- 오디오 토큰 편향: 네이티브 단일 패스 오디오 싱크는 인상적이지만, 엔진이 "신스웨이브 음악" 토큰에 크게 우선순위를 두어 현장감 있는 "웅덩이 튀는 소리" SFX가 다소 묻혔습니다.
- 모션 압축: 720p에서 빠른 카메라 움직임은 배경의 먼 텍스트(예: "MIDNIGHT DINER") 주변에 미세한 가장자리 번짐과 디지털 아티팩트를 발생시킵니다.
시나리오 B: 시네마틱 대화 & 감정 폭발
프롬프트:
액션 & 피사체: 그녀가 "오늘 밤으로 끝이야"라고 속삭이며 긴장감 넘치는 대사를 전달한다.
카메라 다이내믹스: 날카로운 바람이 머리카락을 흩뜨리는 순간, 카메라가 얼굴을 천천히 클로즈업한다.
SFX: 입 모양에 정확히 맞춘 차분한 목소리, 마이크로 불어오는 돌풍 소리와 옷감이 스치는 소리가 섞임.
테스트 목표: xAI Aurora 엔진의 멀티 토큰 통합을 위한 최종 스트레스 테스트입니다. 이 모델은 완벽한 네이티브 립싱크와 미세한 안면 근육 역학을 실행하는 동시에, 머리카락/의상의 복잡한 물리적 상호작용과 사실적인 환경 사운드를 단일 추론 패스에서 계산해내야 합니다.
성공 요인 (Grok의 강점):
- 완벽한 네이티브 립싱크: "It ends tonight"이라는 대사가 캐릭터의 입술 및 턱 움직임과 정확히 일치합니다. 별도의 편집 없이 자연스럽게 이루어집니다.
- 미세 표정 유지: 얼굴의 주근깨, 미세한 눈 깜빡임, 날카로운 시선이 제자리를 지킵니다. 이는 엔진이 클로즈업 샷에서도 정체성을 안정적으로 유지함을 보여줍니다.
- 바람 물리 시뮬레이션: 대사가 끝나는 순간 갑작스러운 바람이 머리카락 사이로 붑니다. 머리카락 한 올 한 올이 현실적으로 움직이며 자연스러운 볼륨감을 유지합니다.
한계 요인 (병목 현상):
- 오디오 아티팩트: 생성된 목소리는 타이밍은 좋으나 약간 압축된 듯한 기계적인 질감이 느껴지며, 프롬프트에서 요청한 거칠고 숨소리가 섞인 질감은 다소 부족합니다.
- 시간적 미세 변형: 바람이 부는 시퀀스 동안 귀와 헤어라인 주변에서 머리카락을 정적 피부 배경과 구분하는 과정에서 약간의 질감 혼합 현상이 발생합니다.
함정 회피: 카운터 예시 매트릭스
현재 공개 엔드포인트에는 전용 네거티브 프롬프트 매개변수가 없으므로, 파이프라인 엔지니어는 기존 디퓨전 기반 프롬프트 휴리스틱에서 벗어나야 합니다.
- ❌ 잘못된 접근 (디퓨전 사고방식): "A man running, highly detailed, 4k, no blur, no distortion, cinematic lighting."
- 분석: 이 방식은 컨텍스트 윈도우를 불필요한 토큰으로 채우고 "no blur"와 같은 부정적 문구를 추가합니다. Aurora 같은 자기회귀 MoE 네트워크는 이러한 용어를 의미론적 닻으로 잘못 해석하여, 오히려 피하고 싶었던 왜곡을 생성할 수 있습니다.
- ✅ 올바른 접근 (Aurora 네이티브 사고방식): "Strides forward dynamically. Sharp focus throughout, pristine cinematic textures, volumetric god rays piercing through dust."
- 분석: 배제어 대신 확정적이고 물리적인 묘사를 사용하여, 엔진의 토큰 예측 경로를 선명한 렌더링으로 명확하게 지시합니다.
프로 팁:
시간적 일관성은 "줌인"과 "오른쪽으로 팬"처럼 서로 충돌하는 공간 명령을 동시에 프롬프트에 넣을 때 저하됩니다. 카메라 움직임은 단일하고 방향성 있게 유지하세요. 8초 이상의 클립은 여러 장면을 컷하기보다 하나의 연속적인 모션 아크를 중심으로 프롬프트를 고정하세요.
Grok Imagine Video Generation API 연동: Python 및 REST 퀵 스타트
창의적인 구상에서 프로덕션 확장으로 전환하려면 이 파라미터들을 공식 xAI API 게이트웨이를 통해 실행해야 합니다. 현재 인프라와 선호하는 방식(자동화된 백그라운드 작업 또는 경량 커스텀 루프)에 따라 xAI는 두 가지 구현 경로를 제공합니다.
Grok Imagine API 호출 방법
Grok Imagine API 호출을 위한 두 가지 지원 경로가 있습니다. 네이티브 xai_sdk Client(자동 폴링 처리)와 https://api.x.ai/v1을 통한 OpenAI 호환 base_url REST 방식입니다. 둘 다 환경 변수로 설정된 API 키 인증이 필요합니다.
사전 요구 사항
코드를 작성하기 전에 다음 단계를 완료하세요:
- console.x.ai에서 API 키 생성
- 셸에서 내보내기: export XAI_API_KEY="your-key-here"
- SDK 설치: pip install xai-sdk
경로 1: 네이티브 xai_sdk (권장)
xai_sdk Client는 내부적으로 비동기 폴링 루프를 래핑하므로, video.generate 엔드포인트 호출 한 번으로 완료된 비디오 객체를 받을 수 있습니다.
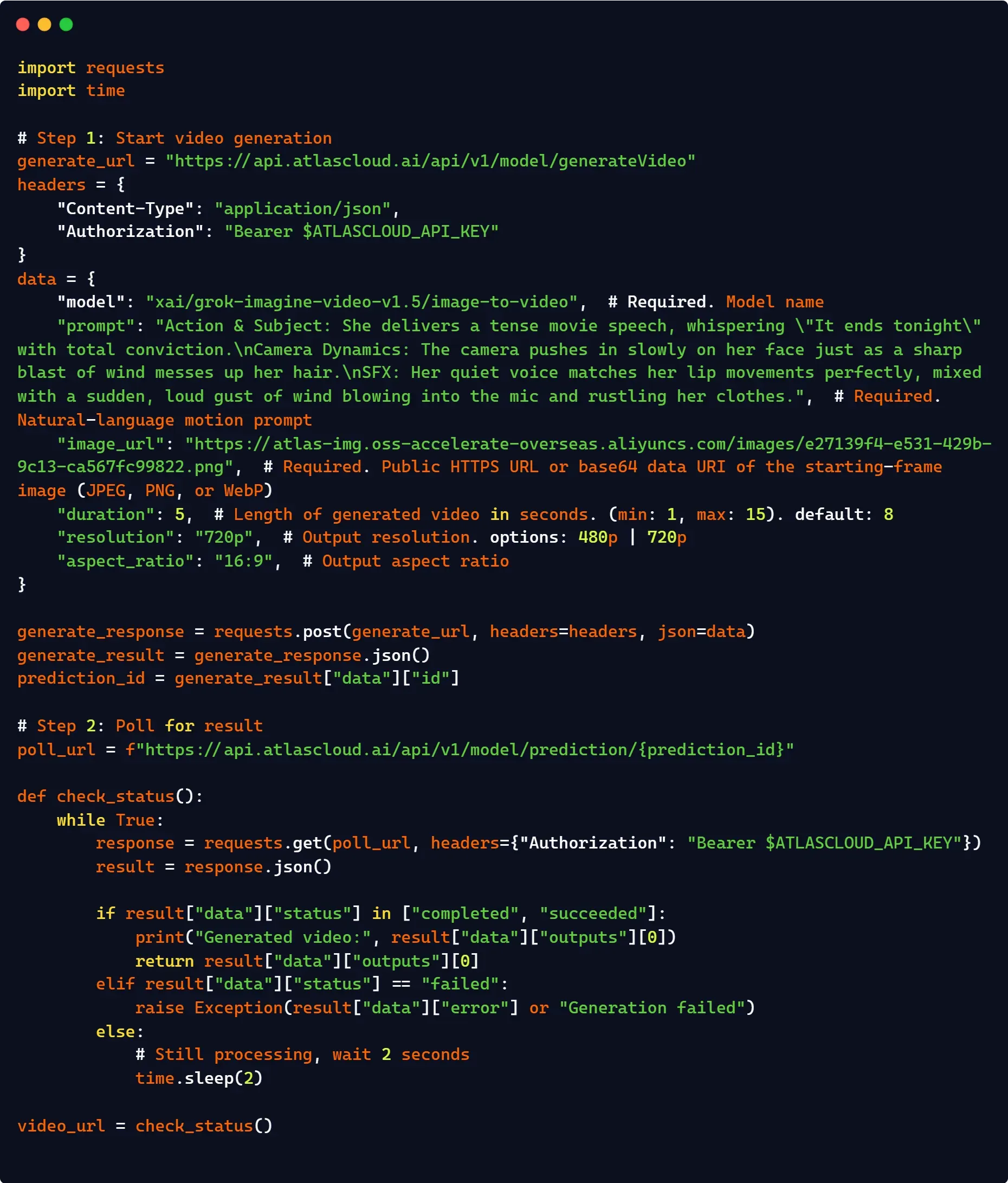
python1import os 2import xai_sdk 3 4client = xai_sdk.Client(api_key=os.getenv("XAI_API_KEY")) 5 6# 이미지-비디오 워크플로우를 위해 참조 이미지를 전달하세요 7response = client.video.generate( 8 model="grok-imagine-video", 9 image="your image", # 필수 URL 또는 base64 10 prompt="your prompt", 11 duration=5, 12 aspect_ratio="16:9", 13 resolution="720p", 14) 15 16# 수정됨: 표준 xai_sdk 응답 스키마와 일치 17print(f"생성 완료. 비디오 URL: {response.video.url}")
수동 폴링이 필요 없습니다. SDK가 요청을 제출하고 완료될 때까지 기다린 후 URL을 반환합니다.
경로 2: 표준 REST API (커스텀 비동기 루프)
네이티브 SDK를 사용할 수 없는 환경에서는 기본 HTTP 엔드포인트를 사용하세요. 비디오 생성은 비동기 작업이므로, 실행 상태를 추적하기 위해 수동으로 폴링 시퀀스를 구현해야 합니다.
python1import os 2import time 3import requests 4 5headers = { 6 "Authorization": f"Bearer {os.environ['XAI_API_KEY']}", 7 "Content-Type": "application/json", 8} 9 10payload = { 11 "model": "grok-imagine-video", 12 "image": "your image", 13 "prompt": "prompt", 14 "duration": 5, 15 "aspect_ratio": "16:9", 16 "resolution": "720p" 17} 18 19# 1. 비디오 생성 요청 제출 20res = requests.post("https://api.x.ai/v1/videos/generations", headers=headers, json=payload) 21res.raise_for_status() 22request_id = res.json()["request_id"] 23 24# 2. 완료될 때까지 상태 엔드포인트 폴링 25while True: 26 poll = requests.get(f"https://api.x.ai/v1/videos/{request_id}", headers=headers) 27 data = poll.json() 28 29 if data["status"] == "done": 30 # 수정됨: 공식 xAI JSON 스키마 반환값과 일치 31 print(f"성공! 에셋 위치: {data['video']['url']}") 32 break 33 elif data["status"] in ["expired", "failed"]: 34 print(f"생성 실패. 상태: {data['status']}") 35 break 36 37 time.sleep(5) # 안전한 속도 제한 간격
상태 폴링 참조
API는 생성 중 다음 네 가지 상태 값 중 하나를 반환합니다:
| 상태 | 의미 |
| pending | 처리 중 |
| done | 비디오 준비 완료, URL 제공 |
| expired | 요청 시간 초과 |
| failed | 생성 오류 |
합리적인 속도 제한을 유지하기 위해 5초 간격으로 폴링하세요. SDK는 기본적으로 100ms 간격을 사용하지만, 프로덕션 워크플로우에서는 5초가 적절합니다.
프로덕션 대안: Atlas Cloud API 게이트웨이를 통한 간소화
고급 동시성, 통합 빌링 또는 고가용성 라우팅이 필요한 기업용 파이프라인의 경우, Atlas Cloud와 같은 타사 관리형 게이트웨이를 통해 연동하는 것이 실용적인 대안입니다. 로컬에서 복잡한 비동기 폴링 루프와 상태 확인을 관리하는 대신, Atlas Cloud의 통합 래퍼가 서버 측 대기열과 상태 유지를 자동으로 처리합니다.
또한, 통합 기본 URL을 통해 요청을 라우팅하여 코드 변경을 최소화하면서도 일반적인 xAI 공개 계층 임계값을 초과하는 엔터프라이즈급 속도 제한을 해제할 수 있습니다.
벤치마크 성능: 비용, 지연 시간 및 경쟁사 비교
고충실도 시청각 결과물은 엄격한 컴퓨팅 예산 및 지연 시간 요구 사항과 일치할 때만 기업 파이프라인에서 실행 가능합니다. Grok이 시장에서 어느 위치에 있는지 확인하기 위해 타사 스트레스 테스트는 생성 속도와 초당 비용을 업계 주요 기업들과 직접 비교합니다.
Grok Imagine Video는 다른 AI 비디오 도구보다 빠르고 저렴한가요?
독립적인 벤치마크에 따르면 대체로 그렇습니다. Grok Imagine Video는 Artificial Analysis Video Arena 이미지-비디오 리더보드에 1404 ±6의 Elo 점수로 1위에 데뷔하며 ByteDance의 Seedance 2.0을 제쳤습니다.
경쟁사 비교
| 모델 | 개발사 | 최대 길이 | 최대 해상도 | 네이티브 오디오 |
| Grok Imagine V1.5 | xAI | 15s | 720p | 예 |
| Seedance 2.0 비교 | ByteDance | 4–12s | 720p | 예 |
| Veo 3.1 | 8s | 1080p | 예 | |
| Sora 2 | OpenAI | 20s | 1080p | 예 |
| Runway Gen-4 | Runway | 10s | 1080p | 일부 |
추론 속도 및 지연 시간
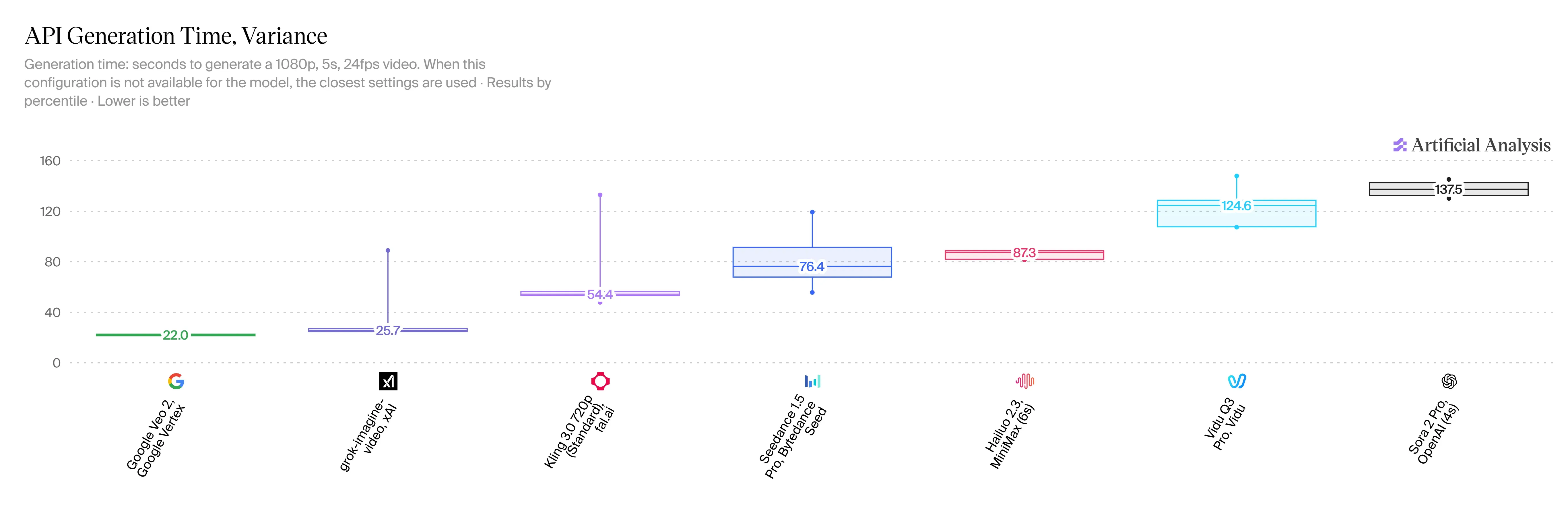
V1.5는 매우 빠르며, 이는 사용자들에게 엄청난 이점입니다. 5초 분량의 720p 클립을 단 2030초 만에 만들 수 있습니다. HappyHorse 2.3과 비교하면 대기 시간이 23배 단축된 것입니다. Veo 3.1에 대한 공식 속도 통계는 아직 없지만, 온라인상에서는 유사한 클립을 만드는 데 1분 이상 걸린다는 평가가 많습니다.
가격 구조
Atlas Cloud와 같은 타사 API 게이트웨이를 통한 초당 가격 구조는 생성된 비디오 1초당 약 $0.096부터 시작합니다. 이 요율로 10초 클립은 약 $0.96이며, 독립적인 크리에이터와 소규모 팀이 최종 프로덕션에 들어가기 전 여러 변형을 반복 테스트하기에 매우 경제적입니다.
엔터프라이즈 보안, 데이터 개인정보 보호 및 콘텐츠 준수
독점적인 미디어 자산이나 고객 대상 콘텐츠를 클라우드 기반 AI 시스템에 배포하는 것은 법적인 질문을 수반합니다. 상업적인 프로덕션 하우스라면, 생성 입력값이 어디로 가고 어떻게 격리되는지 아는 것은 최종 출력 품질만큼이나 중요합니다.
xAI는 나의 API 데이터나 생성된 비디오를 모델 학습에 사용하나요?
이는 엔터프라이즈 도입 기업들이 가장 많이 묻는 질문 중 하나이며, 직접적인 답변이 필요합니다. xAI의 개발자 약관에 따르면 플랫폼을 통해 처리된 API 입력 및 출력은 안전 필터링을 위한 콘텐츠 정책 검토 대상이 되지만, 추론 데이터를 공개 학습 파이프라인과 분리하는 설계에 의한 데이터 개인정보 보호(Data Privacy by Design) 원칙에 따라 처리됩니다.
준수 프레임워크 개요
Grok Imagine에 대한 액세스를 제공하는 타사 API 게이트웨이 제공업체(예: Atlas Cloud)는 다음과 같이 자체 독립적인 준수 인증을 게시합니다:
| 준수 표준 | 상태 |
| SOC 2 Type II 준수 | 인증 완료 |
| GDPR 데이터 거주지 | 조정 완료 |
| HIPAA | 적격 |
전문 사용자를 위한 주요 개인정보 보호 경계
상업적 워크플로우에 Grok Imagine을 도입하려는 전문가는 다음 사항을 주의해야 합니다:
- 생성된 비디오 출력물은 임시 호스팅 URL로 반환되며 기본적으로 영구 저장되지 않습니다.
- 콘텐츠 정책 검토가 전달 전 안전 위반 사항을 필터링하지만, 재사용을 위해 콘텐츠를 보관하지는 않습니다.
- 모델 학습 제외가 API 사용자에게 적용됩니다: 귀하의 프롬프트와 생성된 미디어는 공개 모델 학습 루프로 다시 피드백되지 않습니다.
- GDPR 데이터 거주지 정렬은 관할 구역 전반에서 운영되는 팀을 위해 데이터 처리 관행이 유럽의 처리 표준을 충족함을 의미합니다.
공식적인 데이터 처리 계약이나 사용자 정의 보존 정책이 필요한 기업 배포의 경우, x.ai를 통해 xAI 기업 팀에 직접 문의하는 것이 좋습니다.






