
MiniMax가 1M 토큰에서 15.6배의 디코딩 속도 향상을 예고했습니다. 만약 이 수치가 유지된다면, 100만 토큰 컨텍스트를 운영하는 비용은 거의 10배 가까이 절감될 것이며, 생성 속도 또한 느려지기는커녕 오히려 더 빨라질 것입니다.
이 모델들을 기반으로 서비스를 구축하는 개발자들에게 이는 무엇이 경제적인지에 대한 기준을 재정립합니다. 지금까지는 타당성이 없었던 작업들, 예를 들어 전체 코드베이스를 파편화하지 않고 통째로 코딩 에이전트에게 전달하는 것, 방대한 기록이 쌓이는 수 시간 동안의 에이전트 실행, 파편화된 스니펫이 아닌 전체 문서 집합을 대상으로 하는 검색 등이 비로소 가능해집니다. 모든 팀이 씨름하던 고민, 즉 *"비용이나 지연 시간 때문에 제품이 망가지기 전까지 컨텍스트 윈도우에 얼마나 많은 데이터를 넣을 수 있을까?"*에 대한 상한선이 훨씬 높아진 것입니다.
이 기술의 핵심은 **희소 어텐션(Sparse Attention)**이며, MiniMax만 이 길을 가는 것은 아닙니다. 이미 DeepSeek가 세 개의 모델 라인에 이를 도입했고, Qwen도 자체 버전을 보유하고 있습니다. 이제 방향은 정해졌습니다. 변하는 것은 그 결과입니다. 모든 프런티어 모델이 저렴하게 긴 컨텍스트를 처리할 수 있게 되면, 모델 그 자체는 더 이상 경쟁 우위(moat)가 되지 못합니다. 바로 그 점이 여러분이 주목해야 할 부분이며, 이에 대해서는 마지막에 다시 다루겠습니다.
먼저 실무 도입을 고려하는 분들을 위해 두 가지 솔직한 주의 사항을 말씀드립니다.
- 이 수치는 MiniMax가 미출시 모델에 대해 단 하나의 티저 다이어그램을 통해 밝힌 자체 데이터이며, 자사 환경에서 측정된 것입니다. 방향성을 보여주는 강력한 신호일 뿐, 제3자 벤치마크는 아닙니다. 일단 "MiniMax의 주장"으로 받아들이고, 실제 가중치가 공개되면 자신의 워크로드에서 다시 테스트해보시기 바랍니다.
- M3는 아직 공개되지 않았습니다. 저희는 M3가 출시되는 즉시 Atlas Cloud에서 Day-0 액세스를 제공할 예정입니다. 자세한 내용은 마지막에 확인해 주세요.
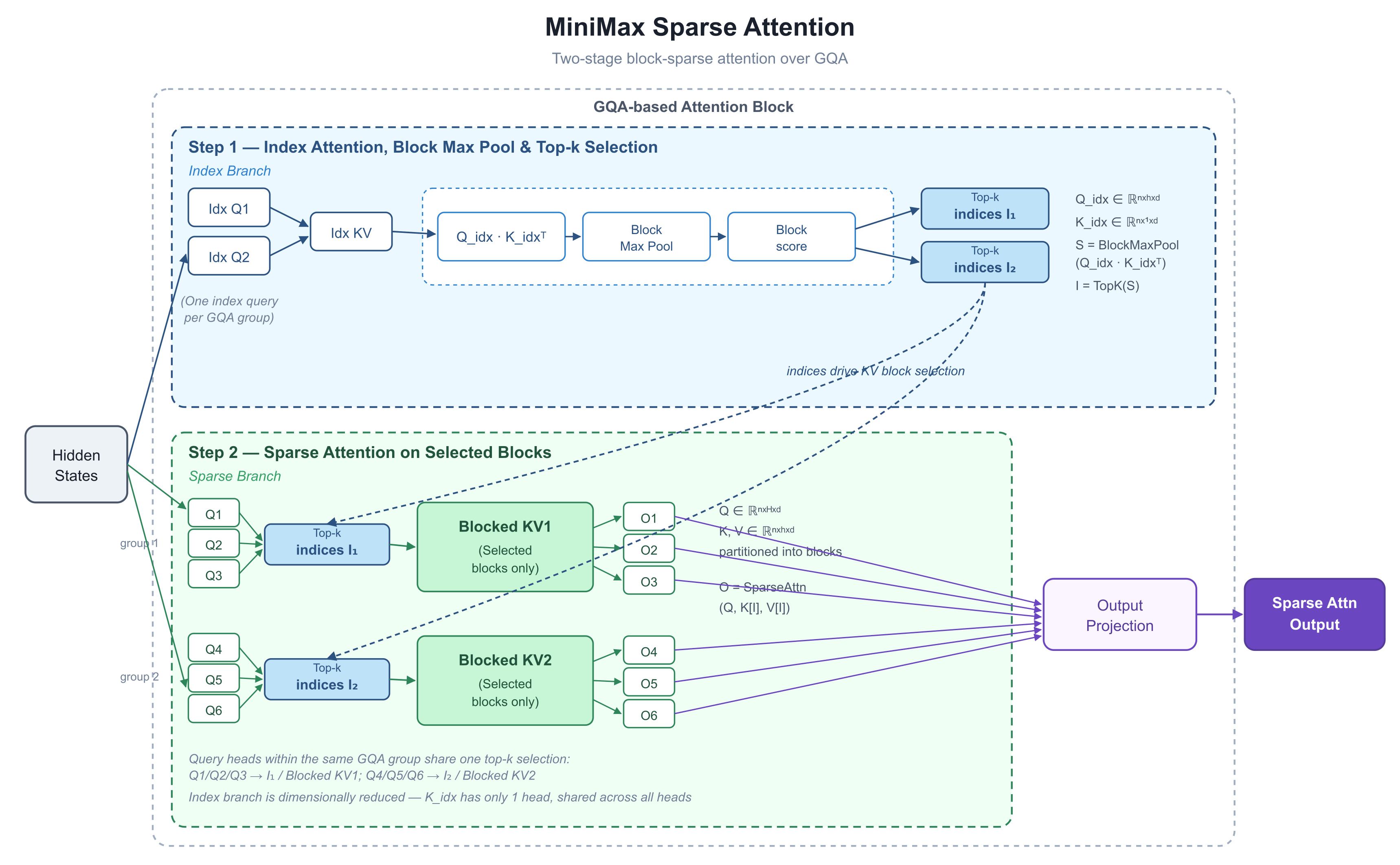
MiniMax는 어떻게 이런 성능을 구현했을까요? 5월 26일, MiniMax R&D 리드 Skyler Miao는 X에 절제된 색감으로 많은 정보를 담은 다이어그램 하나를 게시했습니다. MiniMax Sparse Attention이라는 제목의 이 다이어그램에는 모두가 주목한 두 개의 곡선이 그려져 있습니다. **1M 토큰에서 9.7배 더 빠른 프리필(Prefill), 15.6배 더 빠른 디코드(Decode)**가 그것입니다. 커뮤니티는 이를 M3 티저로 거의 만장일치로 해석했습니다. 저희는 이 수치 뒤에 숨겨진 아키텍처를 분석해 보았습니다.
분석에 앞서 세 가지 용어를 정의하겠습니다.
- *프리필(Prefill)*은 모델이 입력을 한 번에 읽는 단계입니다.
- *디코드(Decode)*는 토큰을 하나씩 생성하는 더 느린 단계입니다. 긴 컨텍스트에서 디코딩은 매번 새로운 토큰이 이전의 모든 데이터를 참조해야 하기 때문에 병목의 원인이 됩니다.
- *희소 어텐션(Sparse Attention)*은 이를 해결합니다. 모든 토큰이 다른 모든 토큰을 참조(기본값, 시퀀스 길이의 제곱에 비례하여 비용 증가)하는 대신, 신중하게 선택된 부분 집합만 참조하여 연산 효율을 높이는 방식입니다. 이 부분 집합을 어떻게 선택하느냐가 각 연구소의 차별점입니다.
이 티저가 무게감을 갖는 이유는 지난 10월 MiniMax가 게시한 *"왜 M2는 풀 어텐션(Full Attention) 모델로 끝났는가?"*라는 글 때문입니다. M1의 효율적인 "라이트닝 어텐션"을 M2에서 건너뛴 이유는 당시 기술이 실운용 수준에 도달하지 못했기 때문이라고 솔직하게 밝혔었습니다. 6개월 후, M3가 희소 어텐션을 전면에 내세우며 등장했습니다. 이 글의 행간은 명확합니다. 이번에는 준비가 되었다는 뜻입니다.
1. 다이어그램이 보여주는 것: 연산 전 선택하는 두 단계
다이어그램은 단일 어텐션 블록의 내부 동작을 보여줍니다. 핵심은 *"어떤 토큰을 볼 것인가"*와 *"어떻게 어텐션을 연산할 것인가"*를 두 단계로 명확히 분리한 점입니다.
기반 기술에 대해 한 가지 짚고 넘어가겠습니다. M3는 **GQA(Grouped-Query Attention)**를 기반으로 합니다. 표준 어텐션 레이어에서는 모든 "쿼리 헤드"가 각각의 키와 값을 가지는데, 이는 표현력은 좋지만 KV 캐시(이전 토큰의 키와 값을 저장하는 공간)를 비대하게 만듭니다. GQA는 쿼리 헤드를 그룹으로 나누고, 각 그룹이 하나의 키-값 세트를 공유합니다. 이는 오늘날 대부분의 상용 모델이 사용하는 메모리 절약 방식입니다. 이 설계가 전체 구조의 기초라는 점을 기억해 주세요.
1단계: 인덱스 브랜치(Index Branch) — 모든 것을 저렴하게 점수 매기기
다이어그램 상단은 인덱스 브랜치입니다. 주 경로와 별도로 작동하며, 블록 내에서 어떤 토큰 블록을 살펴볼 가치가 있는지 결정하는 유일한 임무를 수행합니다.
각 GQA 그룹은 하나의 인덱스 쿼리를 공유합니다. 이 브랜치의 키 측면은 의도적으로 단순화되었습니다.

K_idx는 단 하나의 헤드만 가지고 있습니다. 즉, 모든 헤드가 동일한 인덱스 키를 공유합니다. 덕분에 점수 산정 단계(Q_idx · K_idxᵀ)의 비용은 거의 제로에 가깝습니다.
**블록 최대 풀링(Block Max Pool)**은 토큰 단위 점수를 블록 단위 점수로 압축합니다(시퀀스를 고정 크기 블록으로 나누고 각 블록의 최고 점수를 유지합니다).

마지막으로 TopK 연산이 이 레이어와 그룹에서 살아남을 KV 블록을 결정합니다. 결과물은 I₁, I₂와 같은 짧은 인덱스 리스트입니다.
2단계: 희소 브랜치(Sparse Branch) — 실제 어텐션 연산
하단은 실제 연산입니다. 쿼리, 키, 값은 여전히 표준 GQA 형태입니다. 1단계에서 얻은 I₁과 I₂를 사용하여 전체 키와 값 중에서 선택된 부분 집합만 추출하여 어텐션을 실행합니다.

가장 중요한 설계 선택: 그룹 내 모든 쿼리 헤드는 하나의 Top-K 선택을 공유합니다. 다이어그램에서 Q1/Q2/Q3는 모두 I₁을 사용하고, Q4/Q5/Q6는 I₂를 사용합니다. 이는 DeepSeek의 NSA 논문에서 강조하는 하드웨어 정렬 원칙입니다. 한 그룹의 쿼리가 한 세트의 KV 블록을 로드하고, 그 세트가 SRAM(GPU의 초고속 온칩 메모리)에 한 번에 들어가며, 표준 FlashAttention 방식의 커널을 수정 없이 재사용할 수 있게 됩니다.
2. DeepSeek 시리즈 대비 세 가지 의도적인 차이점
커뮤니티는 즉시 이를 DeepSeek의 세 가지 희소 어텐션 설계와 비교했습니다.
- NSA (Native Sparse Attention): 사전 학습부터 희소성을 내재화한 방식.
- DSA (DeepSeek Sparse Attention): DeepSeek V3.2에 탑재된 방식. 매우 가벼운 인덱서를 사용한 토큰 단위 선택.
- CSA: DeepSeek V4와 관련된 블록 단위 방식(커뮤니티 약칭).
커뮤니티의 중론은 이렇습니다. M3는 MLA 대신 GQA를 사용하고, CSA의 정신을 이어받은 블록 단위 선택을 하지만, 어텐션 연산은 실제 키와 값에 대해 수행한다.
| 항목 | DeepSeek V3.2 DSA | DeepSeek NSA | DeepSeek V4 CSA | MiniMax M3 (추정) |
|---|---|---|---|---|
| KV 기반 | MLA (Latent) | GQA | MLA | GQA |
| 선택 단위 | 토큰 단위 | 블록 단위 | 블록 단위 | 블록 단위 |
| 연산 위치 | 실제 K/V | 3방향 퓨전 | 압축된 KV | 실제 K/V |
첫 번째 차이: MLA 대신 GQA 사용. M3는 일반적인 GQA를 유지하기 때문에 vLLM, SGLang 같은 표준 서빙 스택과 FlashAttention이 수정 없이 바로 작동합니다. "생산성 준비 완료"를 지향하는 입장에서 가장 리스크가 적은 경로입니다. 즉, MiniMax는 누구나 이미 가지고 있는 하드웨어와 소프트웨어에서 바로 돌아가는 방식을 선택했습니다.
두 번째 차이: 블록 단위 선택, 실제 키-값 연산. 압축된 KV로 어텐션을 수행하는 CSA와 달리, M3는 표준 소프트맥스 어텐션의 표현력을 그대로 유지합니다. 비용은 KV 캐시가 희소화와 함께 줄어들지 않는다는 점이지만, 품질 보존을 위해 메모리를 조금 더 쓰는 것은 합리적인 거래입니다.
세 번째 차이: NSA의 복잡한 구조 제거. NSA는 세 개의 병렬 경로와 학습된 게이트를 가졌지만, M3는 선택 기능만 남겼습니다. 하드웨어 효율을 최우선으로 고려한 "엔지니어링 중심"의 설계입니다.
3. 수치 해석하기
| 단계 | 1M 토큰에서의 속도 향상 | 의미 |
|---|---|---|
| 프리필 | 9.7배 | 1M 토큰 입력을 한 번에 처리 |
| 디코드 | 15.6배 | 토큰 단위 생성 속도 |
디코딩에서 더 큰 향상이 나타나는 이유는 자연스럽습니다. 디코딩 시 각 토큰은 선택된 KV 블록과만 상호작용하므로, KV 캐시의 메모리 대역폭 압박이 크게 줄어들기 때문입니다. 이는 디코딩 비용이 발생하는 지점과 정확히 일치합니다.
4. M3의 미래
- MoE(Mixture of Experts) 백본 유지. M2가 보여준 고효율 라우팅 방식은 유지될 가능성이 높습니다.
- 전체 어텐션 스택이 블록 희소 GQA로 대체. M1의 라이트닝 어텐션으로 돌아가는 대신 품질을 유지하며 서브 쿼드러틱(Sub-quadratic) 비용을 달성하는 경로를 택했습니다.
- 사전 학습 단계부터 내재화된 희소성. NSA 논문의 핵심 교훈을 따라, 희소 패턴은 사전 학습 단계부터 포함되었을 것입니다.
5. 2026년 설계 공간 속의 M3
MiniMax M3의 설계 서브텍스트는 명확합니다. 이론적으로 최적인 어텐션을 쫓지 말고, 당장 빠르고 안정적으로 돌아가며 기존 커널을 재사용할 수 있는 방식을 택하라는 것입니다.
6. AI 앱을 만드는 분들을 위한 시사점
이제 모든 프런티어 모델이 긴 컨텍스트를 저렴하게 처리할 수 있게 되면, 모델 그 자체가 경쟁 우위가 될 수 없습니다. 차별화는 그 위의 레이어, 즉 특정 워크로드에 어떤 모델을 쓸지, 어떻게 모델 간 라우팅을 최적화할지, 그리고 새로운 모델이 나올 때마다 얼마나 빠르게 대응할지로 이동하게 됩니다.
단순히 가장 싼 엔드포인트를 찾는 전략은 더 이상 승리하는 전략이 아닙니다. 변경될 때마다 재통합할 필요 없이 모델을 선택, 라우팅, 교체할 수 있는 유연한 레이어 위에서 제품을 구축하는 팀이 승리할 것입니다.
저희 Atlas Cloud가 바로 그 역할을 합니다. LLM, 비디오, 이미지, 오디오를 아우르는 300개 이상의 모델을 단일 API로 연결하고, 지능형 라우팅과 신규 모델에 대한 Day-0 액세스를 제공합니다. M3가 공개되면 즉시 Atlas에 도입하여, 사용자들이 출시 당일부터 바로 이용할 수 있도록 할 예정입니다.
기술적 변화의 속도가 그 어느 때보다 빠릅니다. 2026년 하반기에는 1M 컨텍스트가 선택 사항이 아닌 기본 사양이 될 것입니다. 이제는 어떤 모델을 쓰느냐보다, 그 모델들을 어떻게 유연하게 운용하여 제품 가치를 극대화할지가 핵심입니다.






